概述
随着制造业数字化转型的深入推进,企业在电商平台和官方网站上的商品展示越来越依赖于丰富的视觉内容。然而,商品详情页中的广告图片往往包含大量的营销文案和广告词,这些内容需要经过严格的法务审核以确保合规性,避免虚假宣传、夸大功效等法律风险。企业的法务将会面临以下挑战:
- 审核工作量大:每个商品详情页可能包含数十张广告图片,每张图片中的广告词都需要逐一审核
- 审核效率低:传统人工审核方式耗时长,容易出现遗漏,影响商品上架速度
- 一致性难保证:不同审核人员的标准可能存在差异,影响审核质量
为了提升商品详情页广告图内容审核的效率和准确性,在保证合规的前提下加速产品上架流程。本文介绍一种开发商品广告图审查Agent的方案,帮助制造业客户实现自动化、高效率的内容合规审核。
整体方案架构
本解决方案基于Strands Agents SDK的灵活开发框架和Amazon Bedrock AgentCore构建、部署和运行高性能Agent的能力,构建了一个端到端的智能审核系统,具有以下主要能力:
- 图像文字提取:利用大语言模型的多模态能力自动识别商品详情图中的文字内容
- 智能内容分析:通过大语言模型结合法务知识库分析广告词的合规性,识别潜在风险点
本文以下内容通过一个多Agent模式的原型Demo来展示如何构建这个智能审核Agent,该Agent主要用于厨房家电产品广告图的审核。由于篇幅限制,本文只专注于Agent部分的核心代码和部署方式,其余部分可参考源码链接。
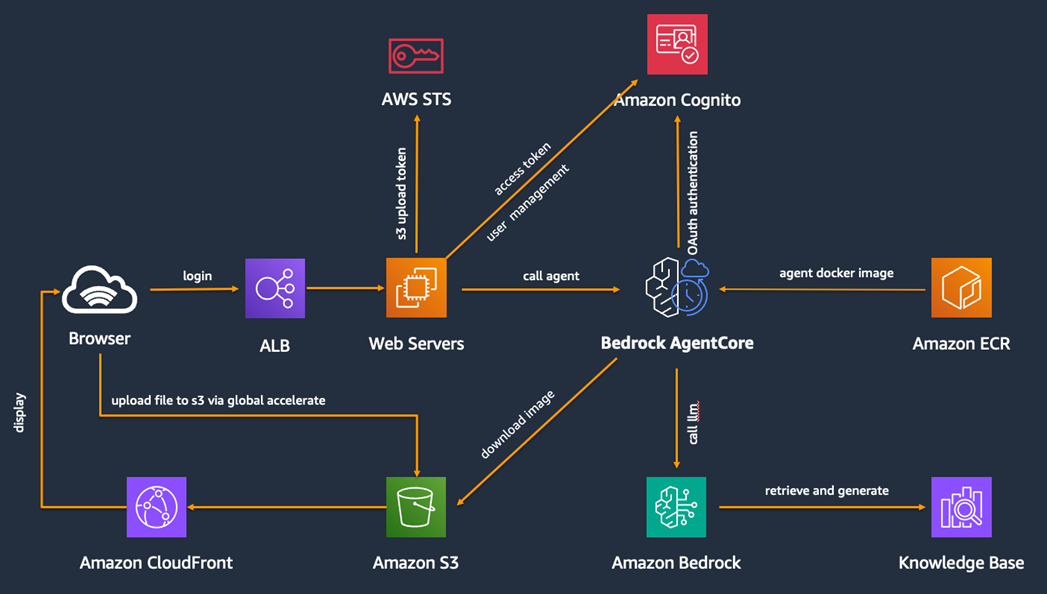
本方案整体架构及用到的AWS服务如下:
- ECR作为容器镜像仓库,存储Agent代码容器化打包后的镜像
- Bedrock AgentCore Runtime用于部署和运行Agent
- Bedrock中的大模型供Agent调用
- 知识库中存储广告法或其它一些法规,可以使用OpenSearch或者S3 Vector
- 使用Cognito来进行用户管理和调用Agent时的JWT鉴权
- 通过STS获取临时凭证,支持浏览器直接上传图片到S3
- S3 存储图片,通过CloudFront生成图片地址用于前端展示
- Web Servers用于部署前后端服务,ALB作为负载均衡器
核心工作流程:浏览器通过用户名密码登录,调用后端服务:1.调用Cognito获取bearer token用于后续以JWT鉴权方式调用Agent;2.调用AWS STS获取S3上传token 3.获取上传策略,包括允许的文件类型和大小限制等;4.浏览器通过全球加速终端节点直接上传图片到S3;5.图片上传完成之后,后端服务会调用Agent进行审核工作。
Agent开发
本方案的Agent采用Strands Agents SDK中的Agents as Tools多Agent模式进行开发。Strands Agents 是一个简单而强大的Python SDK,采用模型驱动的方法来构建和运行AI Agents。从简单的对话助手到复杂的自主工作流,从本地开发到生产部署,Strands Agents 可以根据需求进行扩展,它的目的是帮助开发人员能够快速地构建生产就绪的多Agent 系统。Agents as Tools是AI系统中的一种架构模式,其中专业的AI agents被封装为可调用的函数(工具),可以供其它Agents使用。这种模式创建了一个层级结构,其中:
- 一个主要的协调者Agent处理用户交互并决定调用哪个专业Agent
- 专业的工具Agent在被协调者调用时执行特定领域的任务
这种方法模仿了人类团队的动态,其中一个管理者协调专家,每个专家都具有独特的专业知识来解决复杂问题。与单一Agent尝试处理所有事情不同,任务被委派给最合适的专业Agent。
本方案的Agent包含一个manager agent和两个sub agent,其中text extraction agent完成广告图OCR的功能,review agent完成广告词的审核功能。以下示例代码演示如何创建这些agent:
manager agent
DEFAULT_VISION_MODEL = "us.anthropic.claude-sonnet-4-20250514-v1:0"
DEFAULT_TEXT_MODEL = "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
DEFAULT_KB_MODEL= "us.anthropic.claude-3-5-sonnet-20241022-v2:0"
DEFAULT_REGION = "us-east-1"
def get_model_config() -> Dict[str, Any]:
"""
Get Bedrock model configuration from environment variables
Returns:
Dictionary with model configuration
"""
return {
"vision_model": os.getenv("BEDROCK_VISION_MODEL", DEFAULT_VISION_MODEL),
"text_model": os.getenv("BEDROCK_TEXT_MODEL", DEFAULT_TEXT_MODEL),
"kb_model": os.getenv("BEDROCK_KB_MODEL", DEFAULT_KB_MODEL),
"temperature": float(os.getenv("BEDROCK_TEMPERATURE", str(DEFAULT_TEMPERATURE))),
"top_p": float(os.getenv("BEDROCK_TOP_P", str(DEFAULT_TOP_P))),
"max_tokens": int(os.getenv("BEDROCK_MAX_TOKENS", str(DEFAULT_MAX_TOKENS)))
}
# Create Bedrock model instance for vision tasks
model_config = get_model_config()
model = model_config["text_model"]
bedrock_model = BedrockModel(
model_id=model
)
# Initialize Strands agent with BedrockModel instance
manager_agent = Agent(
model=bedrock_model,
tools=[run_text_extraction, review_advertisement_text],
system_prompt="""
您是由Claude Sonnet 3.7 驱动的商品图广告词审核经理, 负责协调一个专家团队。
您的团队中有二位可以作为工具使用的专家:
1.run_text_extraction: 图片广告词提取专家, 具有图片下载, 广告词提取的能力
2.review_advertisement_text: 广告词审核专家, 具有根据知识库中的法规对广告词进行审核的能力
当面对根据复杂的图片广告词审核任务时:
1.将其分解为适当的子任务
2.将子任务委派给最合适的专家
始终有效协调工作, 最后结果的输出按以下格式:包含每一条广告语及对它的审核内容和建议, 每条广告词一行, 按顺序输出, 不要再进行额外的总结和分析. 格式为: - text: suggestion, 参考如下示例:
- "SUPOR 苏泊尔": 品牌名称展示,符合规范
- "想吃柴火饭": 表达消费者需求,无违规内容
- "全新球釜IH电饭煲SF40HC0028": 产品信息描述准确
- "来个不如球釜": 表述存在歧义,"不如"可能被理解为贬低性表述,不够准确和专业,建议修改为: "选择球釜", "体验球釜技术",或其他更准确的正面表述
"""
)
text extraction agent
system_prompt = """
你是一个专业的OCR文字识别专家,专门从家用电器商品图片中精确提取广告营销文案。
**核心任务:**
从商品详情图上准确识别广告营销文字,确保识别结果的高精度和完整性。
**识别范围:**
- 文字类型:简体中文、英文缩写、阿拉伯数字、常见度量单位
- 字体类型:标准字体、艺术字、装饰字、渐变字、立体字、描边字等各种特效字体
- 商品类别:厨房锅具、电饭煲、餐饮具(水杯等)、破壁机、吸拖一体机等家用电器
**提取目标(广告营销文字):**
- 功能特色描述(如"智能预约"、"一键清洗"、"恒温保温")
- 材质卖点(如"食品级材质"、"304不锈钢"、"陶瓷内胆")
- 营销口号(如"健康生活"、"轻松烹饪"、"品质保证")
- 品牌宣传语和产品标语
- 新品、促销等营销标识
**严格排除:**
- 商品本体的功能按键文字、刻度标识
- 价格信息(¥、元、折扣数字等)
- 条形码、二维码、生产编号
- 认证标志文字(3C、CE等)
**精度要求:**
1. 逐字仔细识别,确保汉字、英文字母、数字的准确性
2. 保持词语的完整性,避免断词或漏字
3. 对模糊、变形字体进行多角度分析
4. 识别重叠、透明、阴影等特殊效果文字
5. 区分相似字符(如0与O、1与l、6与G等)
**输出格式:**
请按序号列出所有识别到的广告语:
请以JSON格式输出结果:
{
"text_blocks": [
{
"id": "ad_1",
"text": "提取的广告语文字内容",
"confidence": 0.95,
"position": "top",
"type": "title",
"bounding_box": {
"x": 100,
"y": 50,
"width": 200,
"height": 30
}
}
]
}
如某些文字不够清晰但可以推断,请标注:[广告词(推测)]
如完全无法识别,请回复:"未识别到清晰的广告词"
请仔细分析图片,确保识别结果的准确性和完整性。
你只需要输出结果,不需要进行分析和总结。
"""
class TextExtractionAgent:
"""
Agent for extracting text from advertisement images using AWS Bedrock
Following Strands SDK patterns
"""
def __init__(self):
# Get model configuration
model_config = get_model_config()
self.default_model = model_config["vision_model"]
# Create Bedrock model instance for vision tasks
bedrock_model = BedrockModel(
model_id=self.default_model
)
# Initialize Strands agent with BedrockModel instance
self.agent = Agent(
model=bedrock_model,
system_prompt=(system_prompt)
)
log_info(
"TextExtractionAgent initialized",
default_model=self.default_model
)
async def extract_text_from_image(
self,
image_url: str,
image_metadata: Dict[str, Any],
extraction_options: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""
Extract text from an advertisement image
Args:
image_url: URL of the image to process
image_metadata: Metadata about the image (filename, size, etc.)
extraction_options: Options for text extraction
Returns:
Dictionary with extracted text blocks and metadata
"""
options = extraction_options or {}
start_time = time.time()
try:
# Download and process image
image_data = await self._download_image(image_url)
# Detect image format
image_format = self._detect_image_format(image_data)
# Create multimodal message for the agent
multimodal_message = [
{
"image": {
"format": image_format,
"source": {"bytes": image_data}
}
},
{
"text": "这是广告图: "
}
]
# Send the multimodal message to the agent
raw_result = self.agent(multimodal_message)
# Parse and process results
log_info(f"Raw result type: {type(raw_result)}")
text_blocks = self._parse_extraction_result(raw_result) # 不要转换为字符串
processed_blocks = self._post_process_text_blocks(text_blocks, options)
processing_time = time.time() - start_time
result = {
"text_blocks": [self._text_block_to_dict(block) for block in processed_blocks],
"metadata": {
"processing_time": processing_time,
"model_used": self.default_model,
"total_blocks": len(processed_blocks),
"image_metadata": image_metadata
}
}
log_info(
"Text extraction completed",
processing_time=processing_time,
blocks_found=len(processed_blocks),
model_used=self.default_model
)
return result
except Exception as e:
log_error("Text extraction failed", error=str(e), image_url=image_url)
raise
async def run_text_extraction_async(
image_url: str,
image_metadata: Dict[str, Any] = None
) -> Dict[str, Any]:
"""
Run text extraction on an image (async version)
Args:
image_url: URL of the image to process
image_metadata: Optional metadata about the image
Returns:
Dictionary with extraction results
"""
if image_metadata is None:
image_metadata = {
"filename": image_url.split("/")[-1],
"source": "api_request"
}
# Initialize extraction agent with Bedrock configuration
extraction_agent = TextExtractionAgent()
# Extract text
result = await extraction_agent.extract_text_from_image(
image_url=image_url,
image_metadata=image_metadata,
extraction_options={
"languages": ["中文", "英文"],
"confidence_threshold": 0.7
}
)
return result
@tool
def run_text_extraction(
image_url: str,
image_metadata: Dict[str, Any] = None
) -> Dict[str, Any]:
"""
Run text extraction on an image (sync wrapper)
Args:
image_url: URL of the image to process
image_metadata: Optional metadata about the image
Returns:
Dictionary with extraction results
"""
return asyncio.run(run_text_extraction_async(image_url, image_metadata))
review agent
# System prompt for analyzing advertisement text compliance
COMPLIANCE_ANALYSIS_PROMPT = """
你是一个专业的广告合规审核专家。请分析提供的广告文本是否符合中国广告法规定。
我会给你一段广告文本,文本中包含多条广告语记录,每条广告语以分号;分隔。每条记录的格式是"ad_id:广告语正文"。
请你基于提供的知识库信息和广告文本,对每条广告语进行详细的合规分析。
分析要求:
1. 识别所有可能的违规内容
2. 评估违规严重程度(high/medium/low)
3. 提供具体的修改建议
返回JSON格式结果:
{
"review_results": [
{
"id": "ad_id",
"text": "广告语原文",
"rule_type": "违规类型",
"severity": "严重程度",
"explanation": "违规说明",
"suggestion": "修改建议",
"confidence": 0.9
}
]
}
只返回JSON格式结果,不要包含其他文字,不输出分析过程。
"""
class ReviewAgent:
"""Advertisement Review Agent using Strands SDK"""
def __init__(self):
model_config = get_model_config()
self.model = model_config["kb_model"]
self.bedrock_model = BedrockModel(model_id=self.model)
# Initialize Strands agent with tools for knowledge base access
self.agent = Agent(
model=self.bedrock_model,
tools=[memory, use_agent]
)
log_info(f"ReviewAgent initialized with model: {self.model}")
# Global instance for reuse
_review_agent_instance = None
def get_review_agent():
"""Get or create review agent instance"""
global _review_agent_instance
if _review_agent_instance is None:
_review_agent_instance = ReviewAgent()
return _review_agent_instance
@tool
def review_advertisement_text(
text_blocks: List[Dict[str, Any]],
product_category: str = "general",
strictness_level: str = "medium"
) -> Dict[str, Any]:
"""
Review advertisement text for compliance using Strands agent
Args:
text_blocks: List of text blocks to review
product_category: Product category for context
strictness_level: Review strictness (low/medium/high)
Returns:
Dictionary with review results and violations
"""
start_time = time.time()
log_info(f"Reviewing {len(text_blocks)} text blocks for product category: {product_category}")
if not text_blocks:
return {
"violations": [],
"metadata": {
"blocks_reviewed": 0,
"rules_applied": 0
}
}
try:
# Combine all text for analysis
combined_text = combine_text_blocks(text_blocks)
# Get reusable agent instance
review_agent = get_review_agent()
# Query knowledge base for relevant rules and context
query = f"""
请根据以下广告文字内容和产品类别,查找相关的广告法规和敏感词规则:
产品类别:{product_category}
广告文字:{combined_text}
请提供:
1. 适用的广告法规条款
2. 相关的敏感词和禁用词
3. 该产品类别的特殊规定
4. 违规风险评估
"""
try:
# Use memory tool to query knowledge base
kb_response = review_agent.agent.tool.memory(
action="retrieve",
query=query,
min_score=0.4,
max_results=10
)
except Exception as e:
log_error(f"Knowledge base query failed: {str(e)}")
return "知识库查询失败,将使用默认规则进行审核。"
middle_time = time.time()
log_info(f"Knowledge base query retrieve time: {middle_time-start_time}")
# Build comprehensive analysis prompt
analysis_prompt = f"""
用户查询: "请审核以下广告文本的合规性"
广告文字:{combined_text}
产品类别:{product_category}
审核严格程度:{strictness_level}
知识库信息:
{kb_response}
请基于知识库信息和广告文字进行详细的合规分析。
"""
# Use LLM for comprehensive compliance analysis
analysis_result = review_agent.agent.tool.use_agent(
prompt=analysis_prompt,
system_prompt=COMPLIANCE_ANALYSIS_PROMPT,
model_provider="bedrock",
model_settings=review_agent.bedrock_model
)
end_time = time.time()
log_info(f"Knowledge base analysis time: {end_time - middle_time}")
# Parse analysis result
# log_warning(f"Analysis result type: {type(analysis_result)}")
# log_warning(f"Analysis result content: {analysis_result}")
result = parse_analysis_result(analysis_result) # 不要转换为字符串
# Apply strictness level filtering
result = apply_strictness_filter(result, strictness_level)
# Add metadata
result["metadata"] = {
"blocks_reviewed": len(text_blocks),
"product_category": product_category,
"strictness_level": strictness_level,
"has_knowledge_base": KB_ID != DEFAULT_KB_ID
}
return result
except Exception as e:
log_error(f"Advertisement review failed: {str(e)}")
return {
"violations": [],
"metadata": {
"blocks_reviewed": len(text_blocks),
"rules_applied": 0,
"error": str(e)
}
}
AgentCore Runtime集成
HTTP接口实现
Agent部署在AgentCore Runtime中,AgentCore支持HTTP/MCP/A2A通信协议,在本方案中,我们使用HTTP协议,后端服务通过REST API调用Agent,我们的Agent必须:
1.部署为满足以下规范的容器化应用程序:
Host: 0.0.0.0
Port: 8080 - Standard port for HTTP-based agent communication
Platform: ARM64 container
2.实现2个接口
/invocations – POST
主要的调用接口,接收来自用户或应用程序的传入请求,并通过Agent的业务逻辑处理它们,以JSON格式 输入,JSON/SSE(Server-Sent Events)格式 输出
/ping – GET
健康检查,验证Agent是否正常运行并准备好处理请求
响应格式
Content-Type: application/json
HTTP Status Code: 200 for healthy, appropriate error codes for unhealthy states
3.FastAPI示例
我们可以通过starter toolkit实现,也可以不使用starter toolkit。以下示例使用FastAPI和Docker自行实现:
app = FastAPI(title="Strands Agent Server", version="1.0.0")
class InvocationRequest(BaseModel):
input: Dict[str, Any]
class InvocationResponse(BaseModel):
output: Dict[str, Any]
@app.post("/invocations", response_model=InvocationResponse)
async def invoke_agent(request: InvocationRequest):
try:
image = request.input.get("image", "")
if not image:
raise HTTPException(
status_code=400,
detail="No image found in input. Please provide a 'image' key in the input."
)
category = request.input.get("category", "general")
strictness = request.input.get("strictness", "medium")
# Run the workflow
print(f"\nStarting workflow for: {image}")
print(f"Product category: {category}")
print(f"Strictness level: {strictness}")
complex_task = f"""
根据以下产品图片, 审核图片上的广告词, 给出评估和建议
图片链接: {image}
产品类别: {category}
审核严格程度: {strictness}
"""
result = manager_agent(complex_task)
response = {
"message": result.message,
"timestamp": datetime.now(timezone.utc).isoformat(),
"model": "strands-agent",
}
return InvocationResponse(output=response)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Agent processing failed: {str(e)}")
@app.get("/ping")
async def ping():
return PingStatus.HEALTHY
本地运行
uv run uvicorn src.strands_manager_agent:app --host 0.0.0.0 --port 8080
接口测试
curl -X POST http://localhost:8080/invocations \
-H "Content-Type: application/json" \
-d '{
"input": {
"image": "s3://bucket-name/ad-images/test1/image_2025-09-04_09-59-40.png",
"category": "home_appliance",
"strictness": "medium"
}
}'
curl http://localhost:8080/ping
Dockerfile
# Use uv's ARM64 Python base image
FROM --platform=linux/arm64 ghcr.io/astral-sh/uv:python3.11-bookworm-slim
# Set working directory
WORKDIR /app
# Copy uv files
COPY pyproject.toml uv.lock ./
# Copy source code
COPY src/ ./src/
# Install Python dependencies
RUN uv sync --frozen --no-cache
# Expose port
EXPOSE 8080
# Run application
CMD ["uv", "run", "uvicorn", "src.strands_manager_agent:app", "--host", "0.0.0.0", "--port", "8080"]
在ARM环境构建镜像
docker build -t ad-review-agent. --no-cache
运行
docker run --platform linux/arm64 -p 8080:8080 \
-e AWS_ACCESS_KEY_ID="$AWS_ACCESS_KEY_ID" \
-e AWS_SECRET_ACCESS_KEY="$AWS_SECRET_ACCESS_KEY" \
-e STRANDS_KNOWLEDGE_BASE_ID="$STRANDS_KNOWLEDGE_BASE_ID" \
-e AWS_REGION="$AWS_REGION" \
ad-review-agent
测试成功后推送镜像到ECR
Agent部署
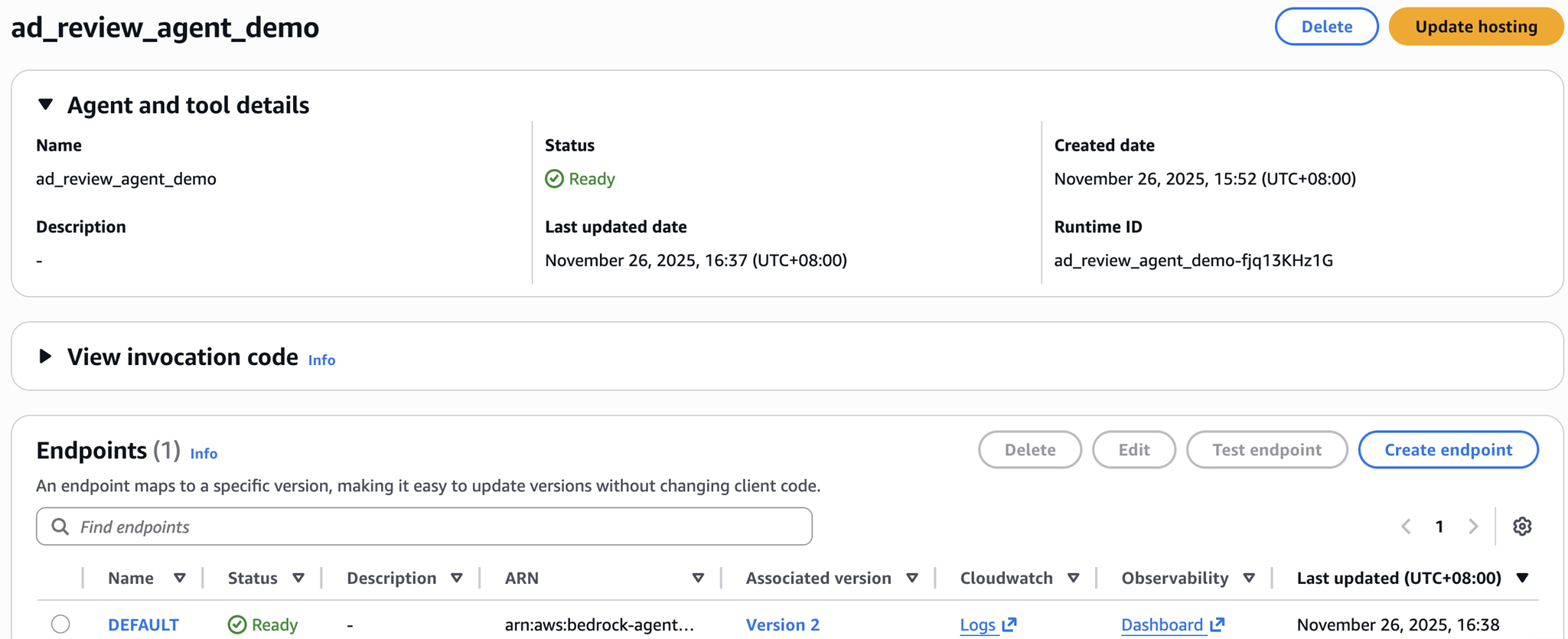
在AgentCore Runtime中进行部署
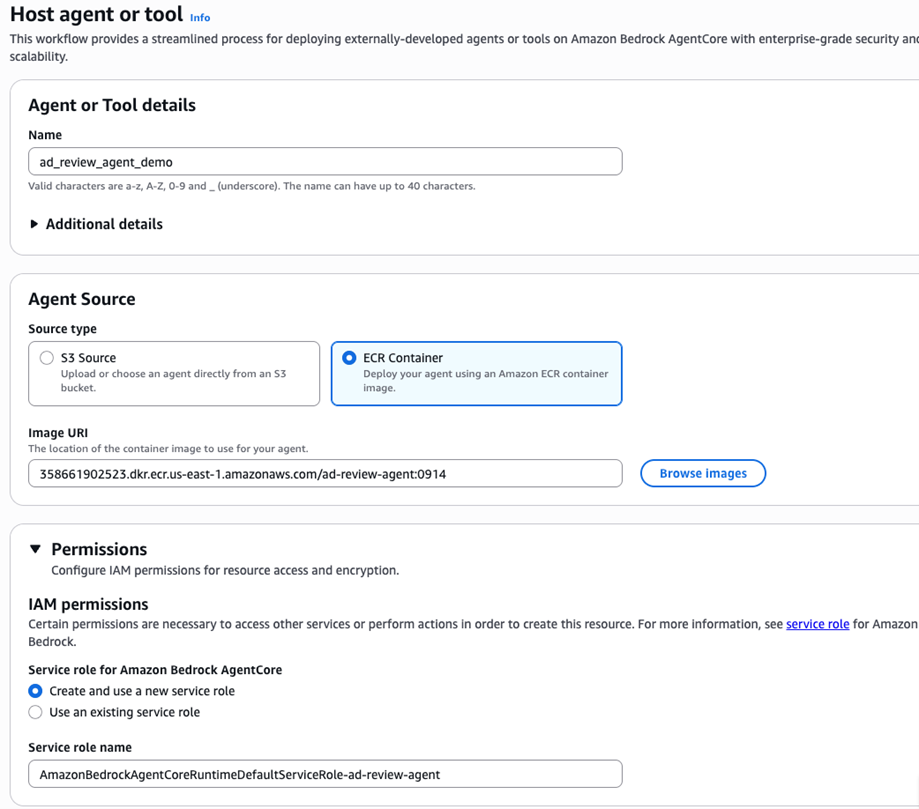
输入名称,选择ECR中的镜像,IAM权限选择Create and use a new service role:
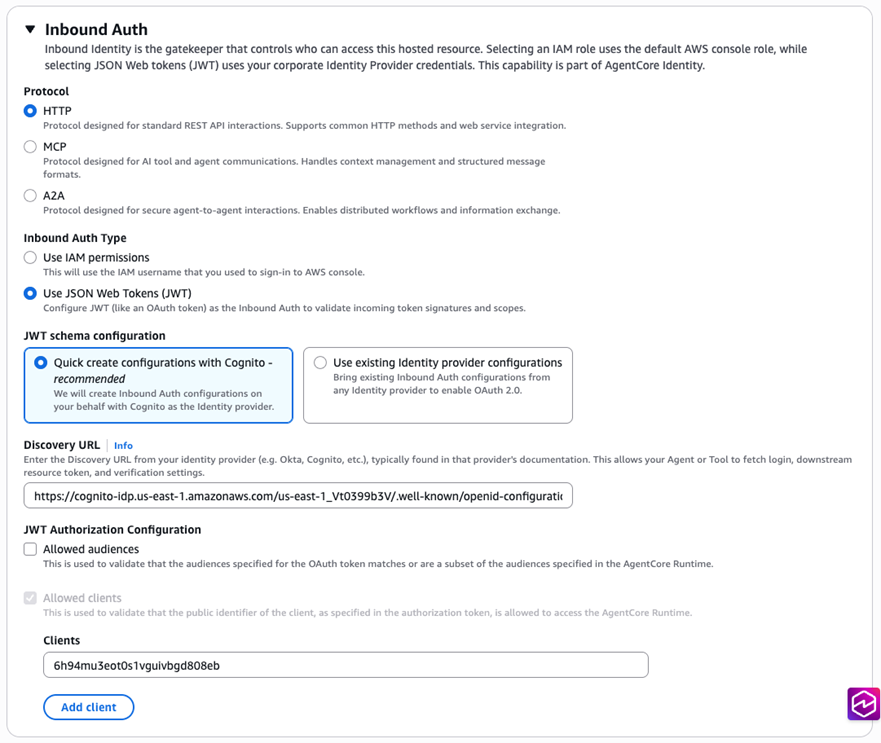
入站协议选择HTTP,身份验证类型选择JWT。JWT schema配置,如果没有现成的,可以选择让系统创建一个Cognito user pool,会自动填写好Discovery URL和Client ID。
如果有现成的Cognito 用户池,可以参考以下脚本创建应用程序客户端,并生成Discovery URL和Client ID
export REGION=us-east-1 // set your desired Region
export USERNAME=USER NAME
export PASSWORD=PASSWORD
# Create App Client and capture Client ID directly
export CLIENT_ID=$(aws cognito-idp create-user-pool-client \
--user-pool-id $POOL_ID \
--client-name "MyClient" \
--no-generate-secret \
--explicit-auth-flows "ALLOW_USER_PASSWORD_AUTH" "ALLOW_REFRESH_TOKEN_AUTH" \
--region $REGION | jq -r '.UserPoolClient.ClientId')
# Output the required values
echo "Discovery URL: https://cognito-idp.$REGION.amazonaws.com/$POOL_ID/.well-known/openid-configuration"
echo "Client ID: $CLIENT_ID"
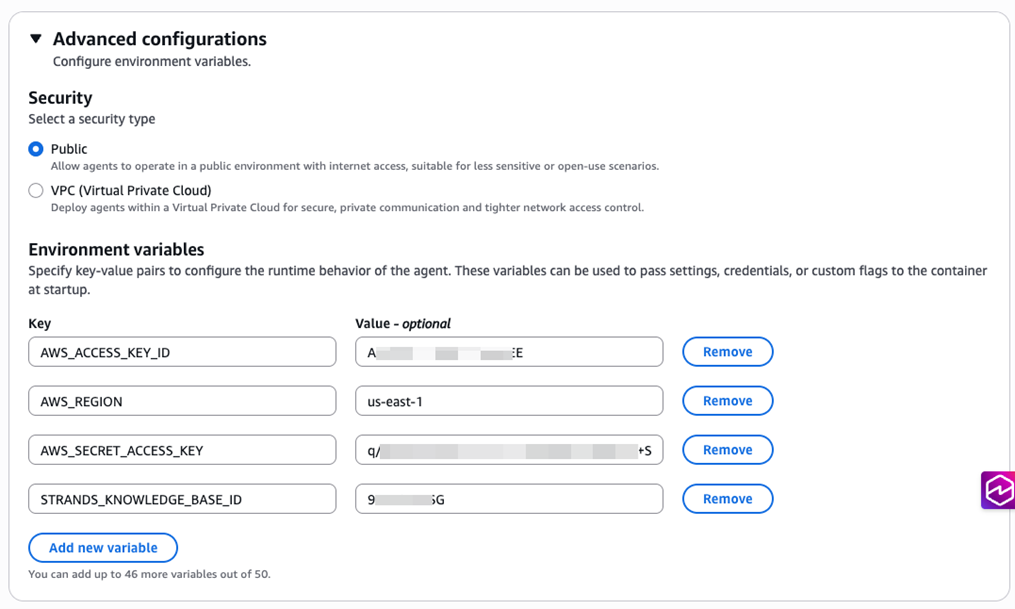
高级设置,安全根据需要选择是Public还是仅VPC内部可以访问,并填入容器运行需要的环境变量
部署完成
部署成功之后进行测试,首先参考以下脚本获取bearer token:
# Create User
aws cognito-idp admin-create-user \
--user-pool-id $POOL_ID \
--username $USERNAME \
--region $REGION \
--message-action SUPPRESS > /dev/null
# Set Permanent Password
aws cognito-idp admin-set-user-password \
--user-pool-id $POOL_ID \
--username $USERNAME \
--password $PASSWORD \
--region $REGION \
--permanent > /dev/null
# Authenticate User and capture Access Token
export BEARER_TOKEN=$(aws cognito-idp initiate-auth \
--client-id "$CLIENT_ID" \
--auth-flow USER_PASSWORD_AUTH \
--auth-parameters USERNAME=$USERNAME,PASSWORD=$PASSWORD \
--region $REGION | jq -r '.AuthenticationResult.AccessToken')
echo "Bearer Token: $BEARER_TOKEN"
获取到bearer token后,参考以下命令格式调用agent:
// Invoke with OAuth token
export PAYLOAD='{"prompt": "hello what is 1+1?"}'
export BEDROCK_AGENT_CORE_ENDPOINT_URL="https://bedrock-agentcore.us-east-1.amazonaws.com"
curl -v -X POST "${BEDROCK_AGENT_CORE_ENDPOINT_URL}/runtimes/${ESCAPED_AGENT_ARN}/invocations?qualifier=DEFAULT" \
-H "Authorization: Bearer ${TOKEN}" \
-H "X-Amzn-Trace-Id: your-trace-id" \
-H "Content-Type: application/json" \
-H "X-Amzn-Bedrock-AgentCore-Ruxcccntime-Session-Id: your-session-id" \
-d ${PAYLOAD}
如下示例,123456789012替换为你的AWS账号ID:
curl -v "https://bedrock-agentcore.us-east-1.amazonaws.com/runtimes/arn%3Aaws%3Abedrock-agentcore%3Aus-east-1%3A123456789012%3Aruntime%2Fad_review_agent_demo-fjq13KHz1G/invocations?qualifier=DEFAULT" \
-H "Authorization: Bearer eyJraWQiOiJEMmplXC94eUF2dVZhVWEzNm9cL1k5WXEyUFhlajhnbDRJcE5WWkRVRFF2S289IiwiYWxnIjoiUlMyNTYifQ.eyJzdWIiOiIxNDc4YTQxOC01MDIxLTcwNGQtN2NmOS0zNDMxOGVjMjlmYjYiLCJpc3MiOiJodHRwczpcL1wvY29nbml0by1pZHAudXMtZWFzdC0xLmFtYXpvbmF3cy5jb21cL3VzLWVhc3QtMV9qY1hxZk9Ha2kiLCJjbGllbnRfaWQiOiI1OWhqaDJsZzdib3FiYWVnODZzdGM4M2pqYiIsIm9yaWdpbl9qdGkiOiIyNzcxNDBhYS0yZTRjLTQzOWEtYTA5Yy1jNWYzOGZjZDZlYjUiLCJldmVudF9pZCI6IjMwZTk1YjJjLWJhYmEtNGVjNy1hNWM3LTk4YTExNjFiZWM0NiIsInRva2VuX3VzZSI6ImFjY2VzcyIsInNjb3BlIjoiYXdzLmNvZ25pdG8uc2lnbmliOiI5N2E3YzI4YS1jYmRjLTQzMGEtOWRjMy1lMzIyMjllY2RlODQiLCJ1c2VybmFtZSI6ImZpeGVkdGVzdF8xMDQ1NTMifQ.awJtgJc-tlvmYSA5BR5KZnCai1mAyNC8VBrd687BNmMmm7_RDB-H1y67DdWO-qqZm64_KJfKAJjWIhIN2tX8KlgE9Qzd7n967ohtgr4In3nc04zczpss7wfBA8Mm3NDm-UXMu8qDe5MaDRz2JtPdrciykQCGA4nY0Thwe73e_H6wsknc45q5SQ-qn50f35B5McuwHZz_0KoynG98JRl8d7Ye9GjmdWplZNQNeqR6nfY2hJJs9eK7JUlFLMDlAKC0WrZQIfJrDatmubGZUd8ylm_NnX3oOzR66NEhJtlzfWm8c9A1_IGHgIcDlnPyGcrApSHkW3ttVDoVKiYTxT7sYw" \
-H "X-Amzn-Trace-Id: ad-review-agent" \
-H "Content-Type: application/json" \
-H "X-Amzn-Bedrock-AgentCore-Runtime-Session-Id: dfmeoagmreaklgmrkleafremoigrmtesogmtrskhmtkrlshma" \
-d '{
"input": {
"image": "s3://bucket-name/ad-images/test1/test-image.png",
"category": "home_appliance",
"strictness": "medium"
}
}'
返回值
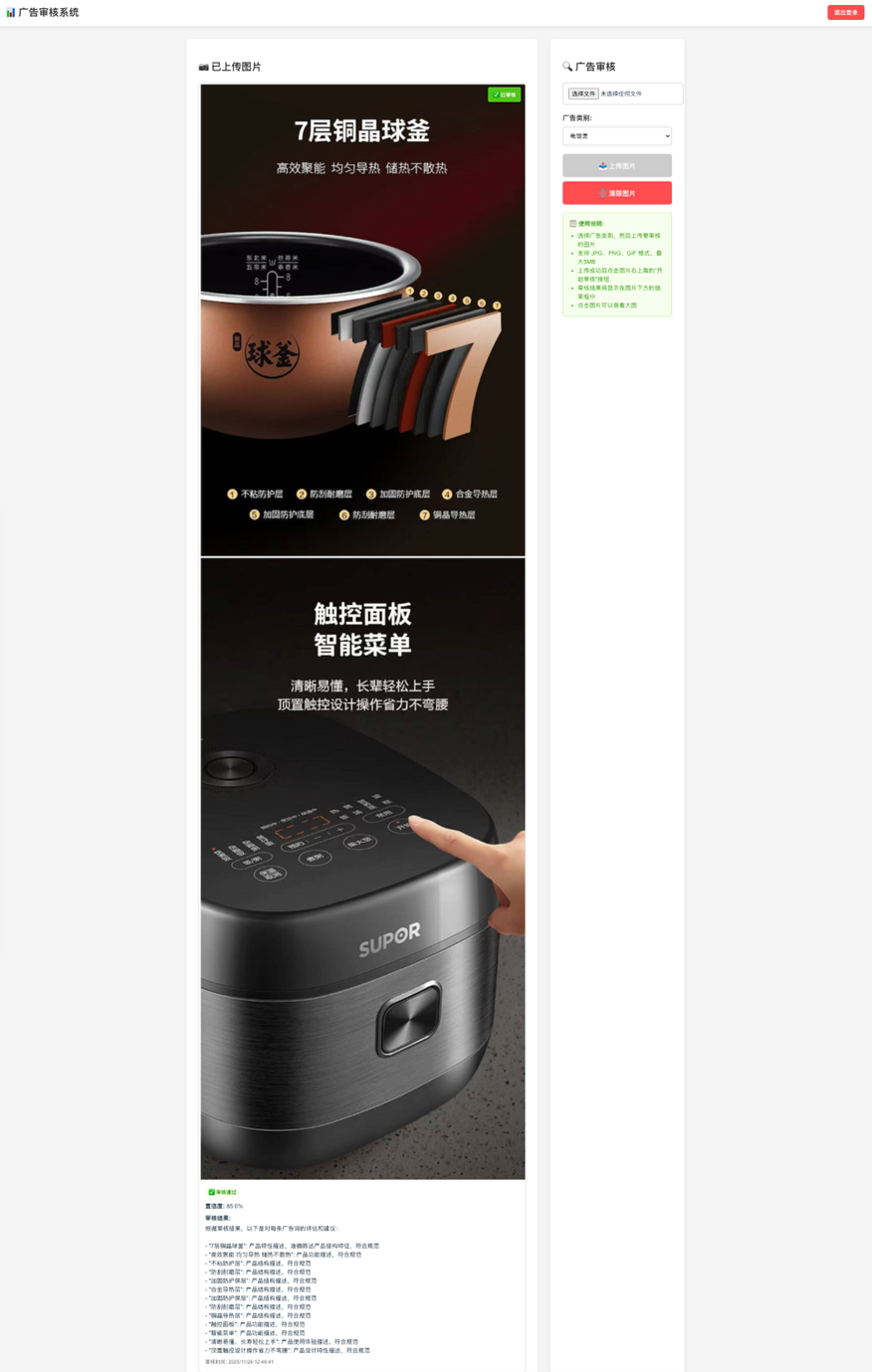
{"output":{"message":{"role":"assistant","content":[{"text":"审核结果:\n\n- \"7层铜晶球釜\": 产品特点描述准确,符合规范\n- \"高效聚能 均匀导热 储热不散热\": 产品性能描述客观,无夸大宣传\n- \"不粘防护层\": 产品材质描述准确,符合规范\n- \"防刮耐磨层\": 产品特性描述准确,符合规范\n- \"加固防护层\": 产品结构描述准确,符合规范\n- \"合金导热层\": 产品材质描述准确,符合规范\n- \"加固防护层\": 产品结构描述准确,符合规范\n- \"防刮耐磨层\": 产品特性描述准确,符合规范\n- \"铜晶导热层\": 产品材质描述准确,符合规范\n- \"触控面板\": 产品功能描述准确,符合规范\n- \"智能菜单\": 产品功能描述准确,符合规范\n- \"清晰易懂,长辈轻松上手\": 产品使用体验描述合理,无违规内容\n- \"顶置触控设计操作省力不弯腰\": 产品设计特点描述准确,无违规内容"}]}
测试通过,Agent部署成功。
前后端集成Demo
Agent开发部署完成之后,我们使用Agentic IDE KIRO快速开发了后端服务和一个简单的前端页面用于演示:
总结和改进
本文介绍了一种基于Strands Agents SDK和 Amazon Bedrock AgentCore 开发部署多Agent应用的方案。Strands Agents提供了简化的开发、原生的AWS集成和内置的安全性,AgentCore提供了大规模地安全构建、部署和运行Agent的平台,两者结合使开发者能够高效地上线生产就绪的AI系统。需要注意的是,本文提供的是一个原型,主要用于展示多Agent的开发模式,在实际的项目中,还有许多工程化的工作要做,例如:在实际的相对固定的使用场景中,可能会采用其它的多Agent模式(如Workflow模式)来降低响应时间。在本原型方案中,text extraction agent提取的文字直接提供给review agent进行了审核。实际上,提取的文字可能有误,需要进行人工纠错,这种情况下可以使用多个独立的Agent来进行这个工作。
参考文档
- Strands Agents
- Agents as Tools with Strands Agents SDK
- Knowledge Base Agent
- AgentCore Runtime HTTP 协议
- AgentCore Runtime入门
- 身份验证和授权
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |