亚马逊AWS官方博客
使用Amazon Bedrock + 自建ECS Docker Sandbox实现Agent 程序化工具调用Programmatic Tool Calling
本文深入解析 Agent领域最新的 Programmatic Tool Calling (PTC) 技术,并介绍如何通过亚马逊云科技 ECS自托管 Docker Sandbox 方案实现完全兼容的 PTC 功能,让Amazon Bedrock上任意大模型都能享受这一革命性的工具调用范式。
一、背景:传统 Tool Use 的瓶颈
在构建 AI Agent 时,工具调用(Tool Use / Function Calling)是连接模型与外部世界的桥梁。然而,传统的工具调用模式存在明显的效率瓶颈:
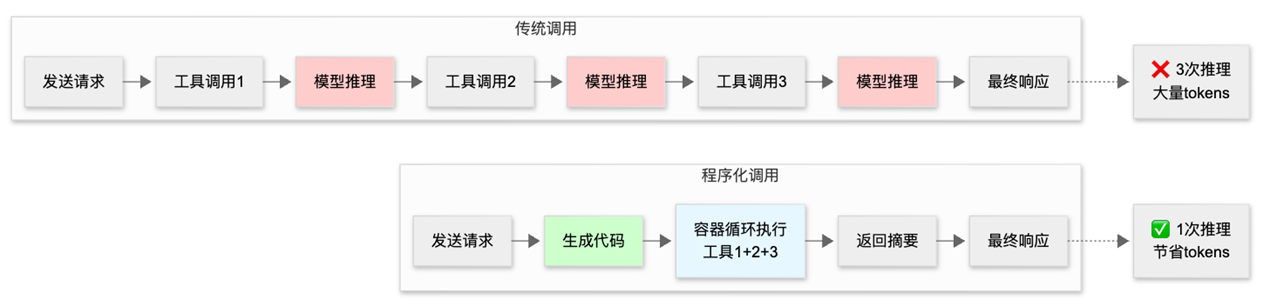 |
图1. 传统工具调用VS 程序化调用示意图
以一个典型的业务场景为例:“查询工程团队哪些成员的 Q3 差旅费用超标?“
传统方式需要(假设不考虑function calling的并行调用):
- 获取团队成员列表 → 20 人
- 为每人获取费用记录 → 20 次工具调用,每次返回 50-100 条明细
- 获取预算标准 → 多次调用
- 所有 2000+ 条费用明细都进入模型上下文
- 模型手动汇总、比对、筛选
这种方式导致:
- Token 消耗巨大:中间数据全部进入上下文
- 延迟累积:每次工具调用都需要一次完整的模型推理
- 准确性下降:模型需要在自然语言中处理大量数据,容易出错
二、Programmatic Tool Calling:代码编排工具调用
2025 年 11 月,业内发布了 Programmatic Tool Calling (PTC) 功能,从根本上改变了工具调用的范式。这不仅仅是一个优化,而是一次架构层面的革新。这个新特性目前在Claude Sonnet/Opus 4.5 上以API方式提供使用。
2.1 核心思想
PTC 的核心思想是:让模型生成 Python 代码来编排工具调用过程,而不是逐个请求工具。
这个思路的巧妙之处在于:代码天然擅长数据处理。循环遍历、条件判断、数值计算、数据聚合—这些操作用 Python代码表达比用自然语言精确100倍,执行效率也高出无数倍。
如下流程图2所示:
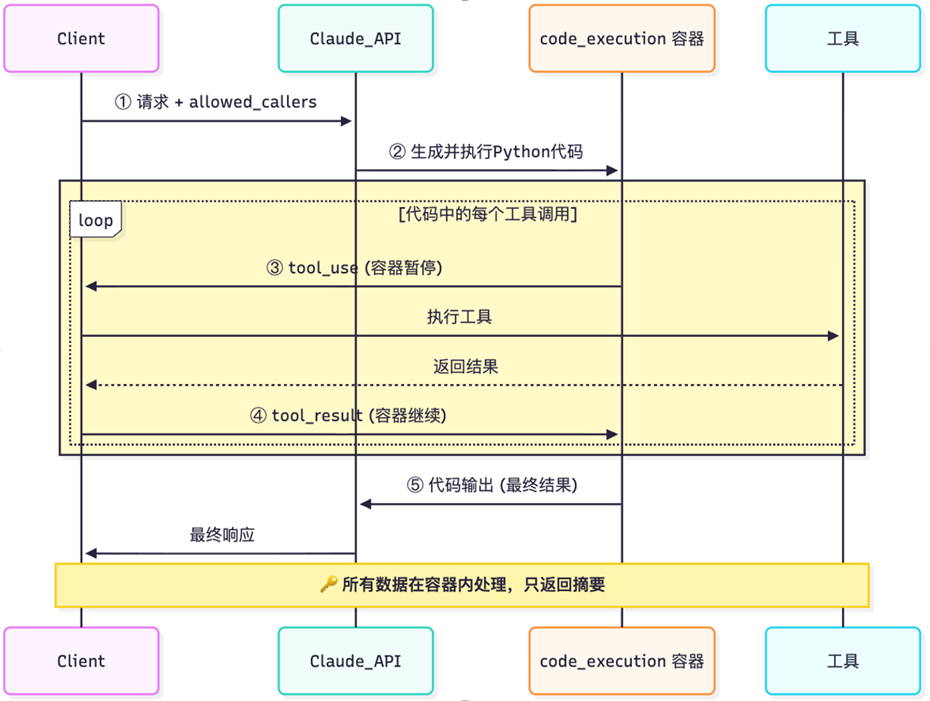 |
图2. PTC调用流程图
- 初始请求阶段
客户端向Claude API发送请求,并携带allowed_callers参数,告知AI可以使用哪些工具。
- 代码生成阶段
Claude API分析需求后,生成并执行Python代码来调用相应的工具。
- 循环执行阶段(核心)
这是流程中的关键部分,用黄色区域标注:
tool_use(容器暂停):代码执行容器检测到工具调用需求后暂停等待,并把tool_use给到客户端(Agent)
执行工具:实际的工具仍然跟传统Agent工作模式一样,由客户端去调用执行
返回结果:客户端执行工具,并将结果返回模型API,API服务会透传给容器,不计入模型上下文
tool_result(容器继续):容器接收结果并继续执行
这个循环可能执行多次,直到完成所有工具调用。
- 结果输出阶段
代码执行容器将最终结果输出给Claude API,再由API返回给客户端。
其中关键安全设计
所有数据在容器内处理,只返回最后的结果摘要给模型,确保了中间过程中数据安全性和隐私保护。
2.2 官方 API 使用方式
根据官方文档,启用 PTC 需要:
- 添加
code_execution工具:这是一个特殊的系统工具,提供代码执行能力及沙盒环境 - 设置
allowed_callers:标记哪些工具可以从代码执行环境中被调用
# 配置工具列表
tools = [
# 1. 添加代码执行工具(系统提供)
{
"type": "code_execution_20250825",
"name": "code_execution"
},
# 2. 业务工具 - 标记可被代码环境调用
{
"name": "get_team_members",
"description": "获取部门团队成员列表",
"input_schema": {...},
"allowed_callers": ["code_execution_20250825"] # 关键配置!
},
{
"name": "get_expenses",
"description": "获取员工费用记录",
"input_schema": {...},
"allowed_callers": ["code_execution_20250825"]
}
]
# 使用 beta API 调用
response = client.beta.messages.create(
model="claude-sonnet-4-5-20250929",
betas=["advanced-tool-use-2025-11-20"], # 启用 beta 功能
tools=tools,
messages=[{"role": "user", "content": "分析 Q3 费用超标情况"}]
)
2.3 模型生成的代码示例
当启用 PTC 后,Claude 会生成类似这样的代码来完成任务:
import asyncio
import json
# 步骤 1: 获取团队成员
team_json = await get_team_members(department="engineering")
team = json.loads(team_json)
print(f"团队共 {len(team)} 人")
# 步骤 2: 并行获取所有成员的费用数据(关键优化!)
expense_tasks = [
get_expenses(employee_id=m["id"], quarter="Q3")
for m in team
]
expenses_results = await asyncio.gather(*expense_tasks)
# 步骤 3: 分析超标情况
exceeded = []
for member, exp_json in zip(team, expenses_results):
expenses = json.loads(exp_json)
# 只计算已批准的差旅费用
total_travel = sum(
e["amount"] for e in expenses
if e["category"] == "travel" and e["status"] == "approved"
)
# 超过标准预算的,检查自定义预算
if total_travel > 5000:
budget_json = await get_custom_budget(user_id=member["id"])
budget = json.loads(budget_json)
limit = budget["travel_budget"]
if total_travel > limit:
exceeded.append({
"name": member["name"],
"spent": total_travel,
"limit": limit,
"exceeded_by": total_travel - limit
})
# 步骤 4: 只输出超标人员摘要(这是唯一进入上下文的内容!)
print(f"超标人员共 {len(exceeded)} 人:")
print(json.dumps(exceeded, indent=2, ensure_ascii=False))
? 关键点:注意代码中使用了 asyncio.gather() 来并行获取所有员工的费用数据。这意味着 20 个工具调用几乎同时发出,而不是串行等待。最终只有 print() 的内容(几行摘要)返回给模型,而不是 2000+ 条费用明细。
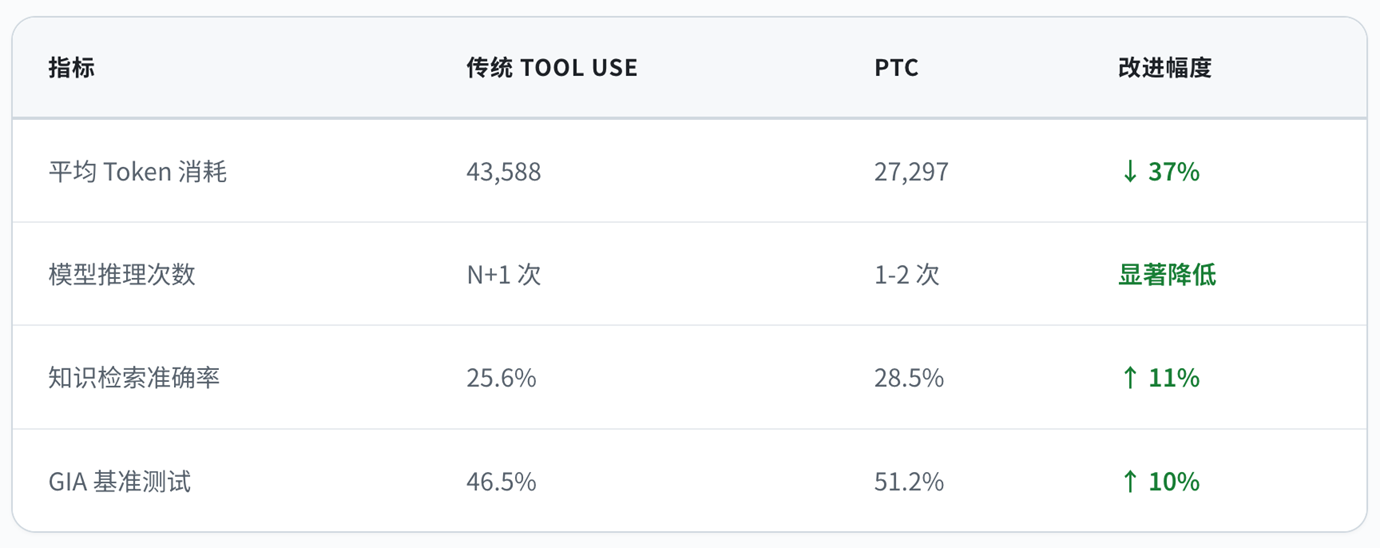
2.4 效率提升数据
根据官方测试数据,PTC 带来了显著的效率提升:
 |
三、基于亚马逊云科技Bedrock的自托管方案:Docker Sandbox 实现
官方 PTC 使用第三方托管的沙箱环境,但在某些场景下我们需要:
- 完全的控制权和自定义能力
- 支持非 Claude 模型
- 私有化部署
- 自定义依赖包
为此,我们实现了一个完全兼容官方 PTC 机制的自托管 Docker Sandbox 方案。使用Bedrock
3.1 整体架构
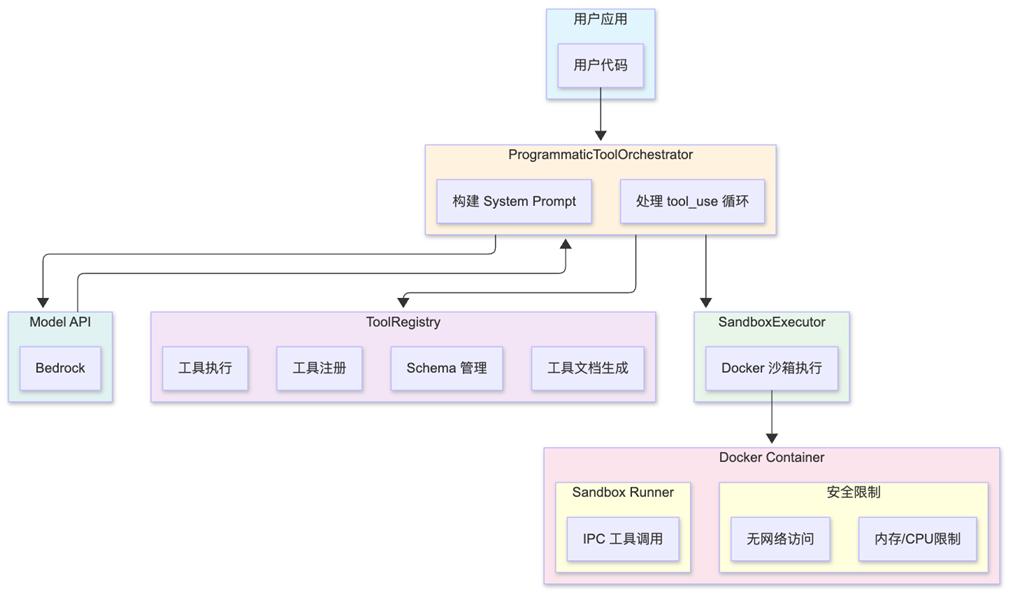 |
3.2 流程图解
以下是完整的系统交互流程图,展示了从用户请求到最终响应的全过程,
核心思路是,将原本放到tool_config中的工具定义,追加到system提示词中提示模型根据工具定义写python代码编排这些tools,然后放入到一个docker沙盒环境中执行,而宿主进程作为控制平面,通过IPC通信,处理沙盒内部的工具调用拦截,实现在代码执行时遇到外部工具调用,可以将沙盒进程挂起,等待用户执行工具后,将结果注入回沙盒。
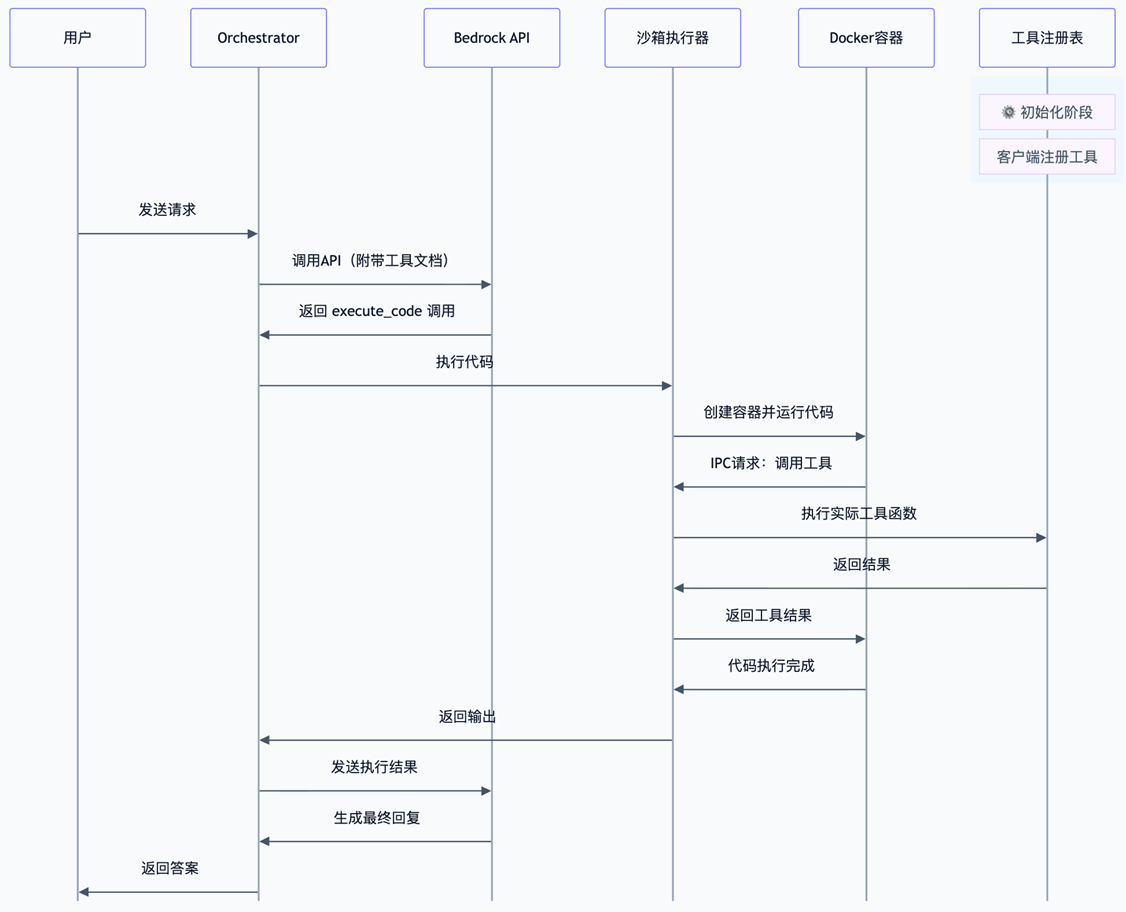 |
3.2.1 系统提示词
将原本放到tool_config中的工具定义,追加到system提示词中,提示模型写python代码编排这些工具,以下是简化版的系统提示词示例,其中会提示模型工具描述,基本语法,最佳实践,执行环境等信息。
3.3 核心组件
3.3.1 SandboxExecutor – Docker 沙箱执行器
SandboxExecutor 是核心组件,用于在隔离环境中安全执行用户代码,同时支持通过 IPC(进程间通信)调用外部工具。整个系统采用双进程架构,通过标准输入输出进行消息传递。
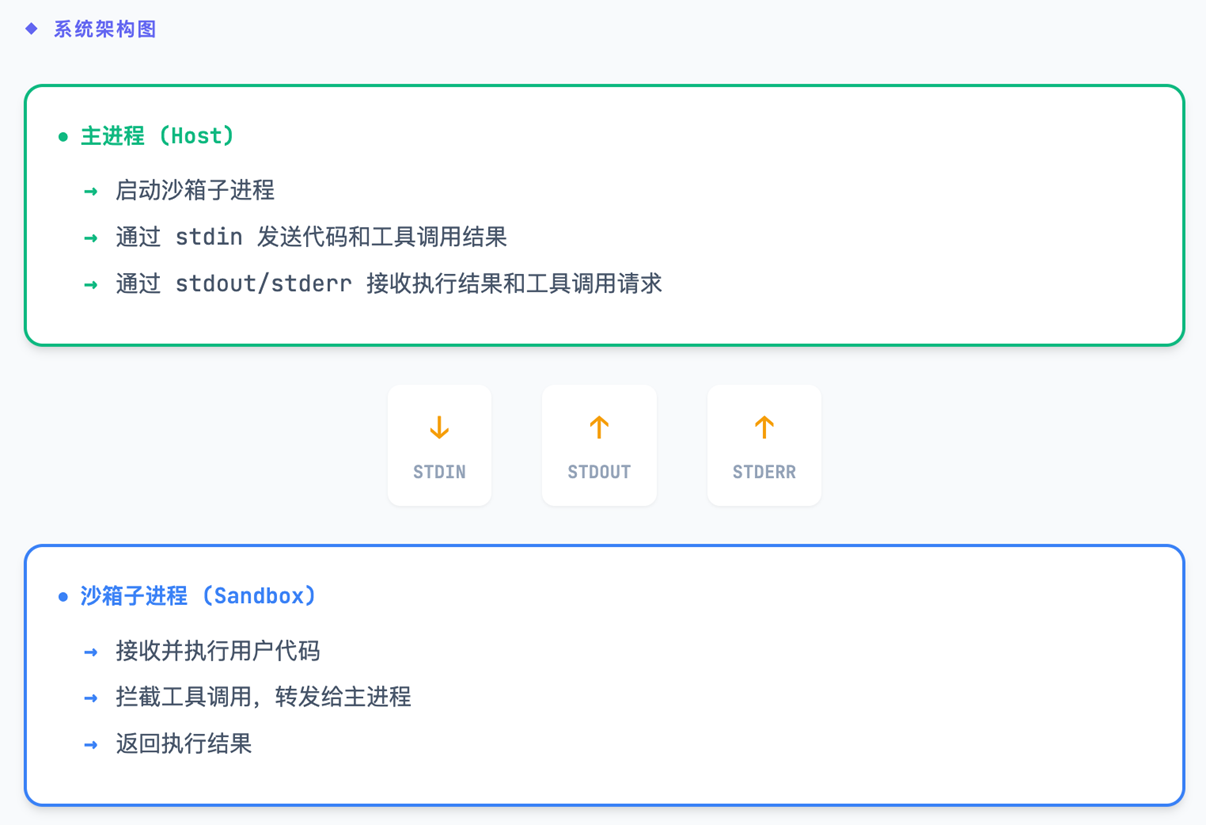 |
3.3.2 沙箱脚本
Runner Script 是沙箱执行的核心脚本,由主进程动态生成并注入到 Docker 容器中。它负责接收用户代码、拦截工具调用、与主进程通信。
1) 脚本生成机制
Runner 脚本是一个模板文件,在实际使用时,主进程会将 {tools_info} 占位符替换为真正的工具定义:
2) 脚本结构总览
完整的 Runner Script 包含以下核心组件:
代码执行层
- 代码包装
- 输出捕获
- 异常处理
IPC 协议层
- 协议标记常量
- 消息编解码
- 边界检测
工具调用层
- 动态函数生成
- 异步执行器
- 结果协调
I/O 管理层
- 无缓冲读取
- 共享缓冲区
- 线程锁同步
3) 脚本执行模式
Runner Script 支持两种执行模式:单次执行模式和循环执行模式:
单次执行模式 (Single Mode):执行一次代码后退出,适用于无状态的简单场景:
循环执行模式 (Loop Mode):容器保持运行,可执行多段代码,支持会话复用和状态保持:
会话超时
循环模式下,会话默认在 4.5 分钟后超时(与 Anthropic API 一致)。主进程会发送 __EXIT_SESSION__ 信号或直接关闭容器来终止会话。
3.3.3 IPC协议标记
为了在文本流中准确分隔不同类型的消息,系统定义了一组消息边界标记。这些标记确保主进程和沙箱子进程能够正确识别和解析消息。
IPC_TOOL_CALL_START = “__PTC_TOOL_CALL__”
IPC_TOOL_CALL_END = “__PTC_END_CALL__”
IPC_TOOL_RESULT_START = “__PTC_TOOL_RESULT__”
IPC_TOOL_RESULT_END = “__PTC_END_RESULT__”
IPC_CODE_OUTPUT_START = “__PTC_OUTPUT__”
IPC_CODE_OUTPUT_END = “__PTC_END_OUTPUT__”
 |
3.3.4 工具调用机制
1)发送工具调用请求
当沙箱中的代码需要调用外部工具时,会通过 stderr 发送请求。使用 stderr 而非 stdout 是为了避免与用户代码的 print() 输出混淆。
2)接收工具调用结果
发送请求后,沙箱会阻塞等待主进程通过 stdin 返回结果。通过 call_id 确保请求和响应的正确匹配。
3.3.4动态创建工具函数
系统根据 TOOLS_INFO 配置动态生成工具函数。每个工具函数都是一个异步函数,使用闭包捕获工具名称,并通过 run_in_executor 将阻塞的 stdin 读取放到线程池中执行。
关键设计要点
使用闭包捕获 tool_name,run_in_executor 将阻塞的 stdin 读取放到线程池,避免阻塞 asyncio 事件循环。这样可以支持并行工具调用(如 asyncio.gather)。
3.3.5完整通信流程
下图展示了一次完整的代码执行流程,包括工具调用的请求-响应过程:
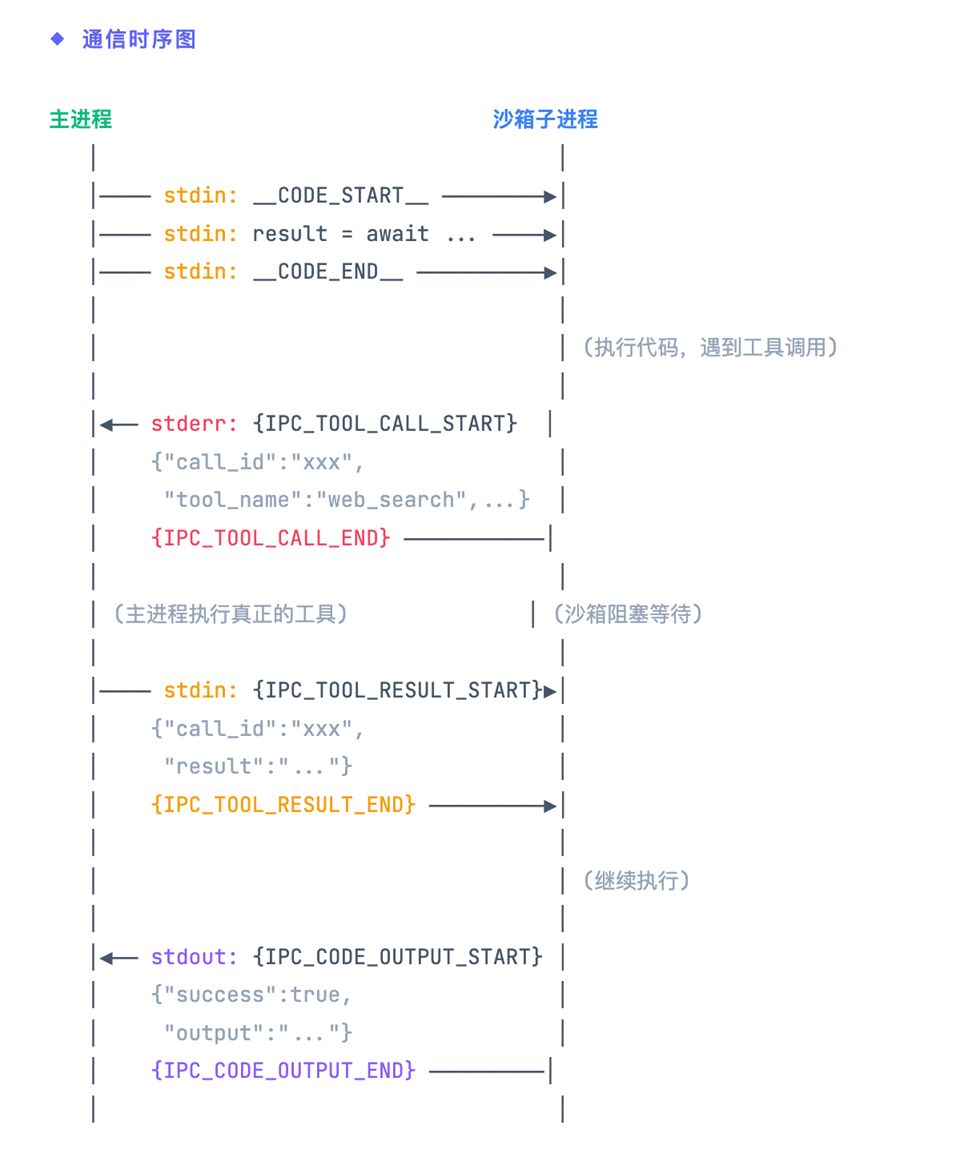 |
阶段一:代码传输
主进程通过 stdin 将用户代码发送给沙箱,使用 __CODE_START__ 和 __CODE_END__ 标记边界
阶段二:工具调用
沙箱执行代码时遇到工具调用,通过 stderr 发送请求,然后阻塞等待结果
阶段三:结果返回
代码执行完毕后,沙箱通过 stdout 返回最终结果(包含输出和错误信息)
3.3.6 安全设计
沙箱执行器实现了多层安全防护,确保用户代码无法影响主系统:
Docker 容器运行时应用多层安全限制:
3.4 与官方 PTC 的对比
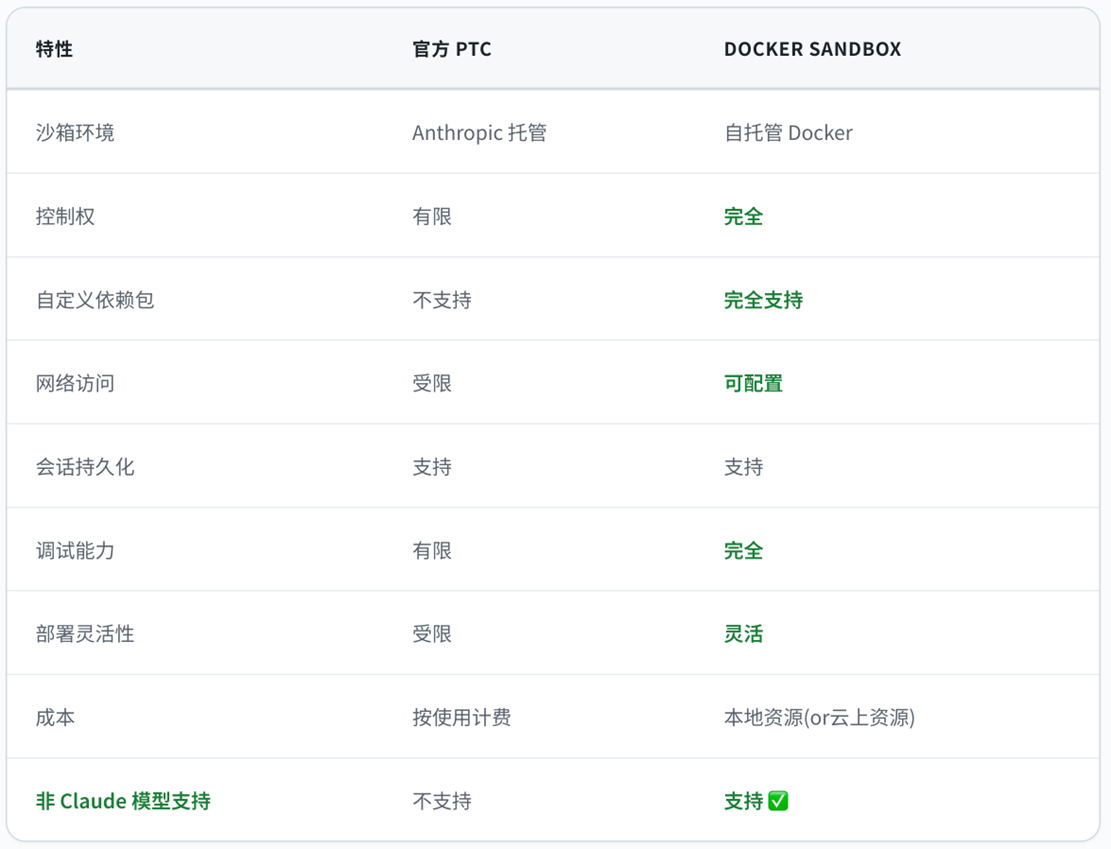 |
四、实战演示:多模型 PTC 效果
4.1 测试场景
我们使用 Claude 官方PTC Cookbook 中的示例来演示 PTC 在不同模型上的效果。
4.1 测试场景:企业差旅费用审计
业务背景
我们模拟了一个企业费用管理系统,包含以下 Mock API 工具:
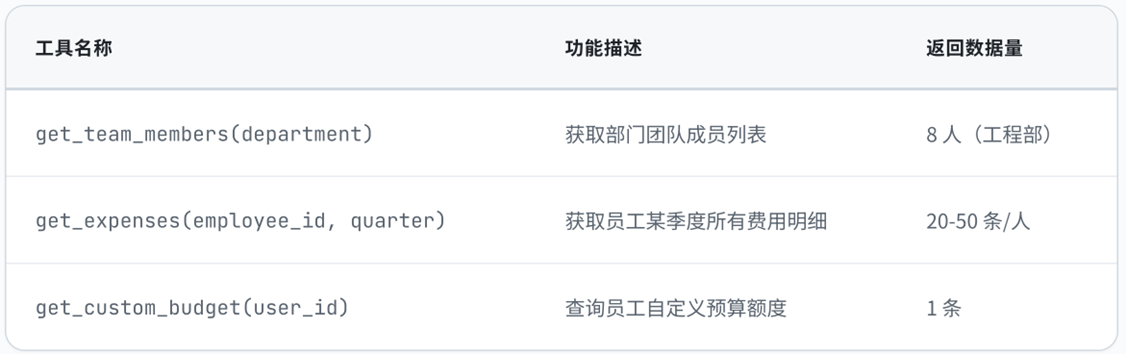 |
数据特点
团队成员数据:工程部门有 8 名成员,涵盖 junior、mid、senior、staff、principal 五个级别。
费用明细数据:每位员工每季度有 20-50 条费用记录,每条记录包含丰富的元数据:
- 基础信息:expense_id、date、amount、currency、status
- 分类信息:category(travel/lodging/meals/software/equipment/conference/office/internet)
- 审计信息:approved_by、receipt_url、payment_method、project_code、notes
- 商户信息:store_name、store_location
预算规则:
- 标准差旅预算:$5,000/季度
- 部分员工有自定义预算例外(如 Staff Engineer $8,000、Principal Engineer $12,000)
- 关键规则:只有 status=”approved” 的费用才计入预算
测试任务
测试问题:
“Which engineering team members exceeded their Q3 travel budget? Standard quarterly travel budget is $5,000. However, some employees have custom budget limits. For anyone who exceeded the $5,000 standard budget, check if they have a custom budget exception.”
“哪些工程团队成员超出了他们的第三季度差旅预算?标准的季度差旅预算是5,000美元。但是,有些员工有自定义的预算限额。对于任何超出5,000美元标准预算的人,请检查他们是否有自定义预算例外。”
该测试用例足够复杂,非常考验模型的逻辑推理和计算能力
- 多步骤工具调用:需要先获取团队成员 → 逐个获取费用明细 → 对超标者查询自定义预算
- 大量中间数据:8 人 × 20-50 条费用 = 160-400 条费用记录,传统模式下全部进入上下文
- 复杂过滤逻辑:只统计 approved 状态、travel/lodging 类别的费用
- 条件分支判断:先与 $5,000 比较,超标再查自定义预算,再次比较
- 数据聚合输出:最终只需输出超标人员名单,而非全部明细
4.2 测试代码
我们沿用前面提到的使用官方API的测试代码,只需要替换api_key和base_url为我们实现的PTC方案(见文末项目仓库)提供的proxy url和api key接口.
# 通过代理服务调用(支持多种模型)
client = anthropic.Anthropic(
api_key=os.environ.get('API_KEY'),
base_url=os.environ.get('BASE_URL') # 代理服务地址
)
response = client.beta.messages.create(
model=model_id, # 可以是 Claude、Qwen、MiniMax 等
betas=["advanced-tool-use-2025-11-20"],
tools=ptc_tools,
messages=[{"role": "user", "content": query}]
)
关键配置说明
base_url– PTC方案提供的anthropic兼容接口apiapi_key– PTC方案提供的anthropic兼容接口api keytype: "code_execution_20250825"– 启用代码执行沙箱allowed_callers: ["code_execution_20250825"]– 指定工具只能从沙箱代码中调用betas: ["advanced-tool-use-2025-11-20"]– 启用 PTC beta 功能
4.3 多模型测试结果
我们在以下模型上测试了相同的 PTC 任务:
该任务的正确答案如下, 如果人名或者数字金额不对,都判断为❌ 不准确,只有人名和数字金额全部正确才判为✅ 准确
1. Alice Chen
- Budget: $5,000.00 | Actual: $9,876.54 | +$4,876.54 over
2.Emma Johnson
- Budget: $5,000.00 | Actual: $5,266.02 | +$266.02 over
3.Grace Taylor
- Budget: $5,000.00 | Actual: $6,474.46 | +$1,474.46 over
PTC 模式测试
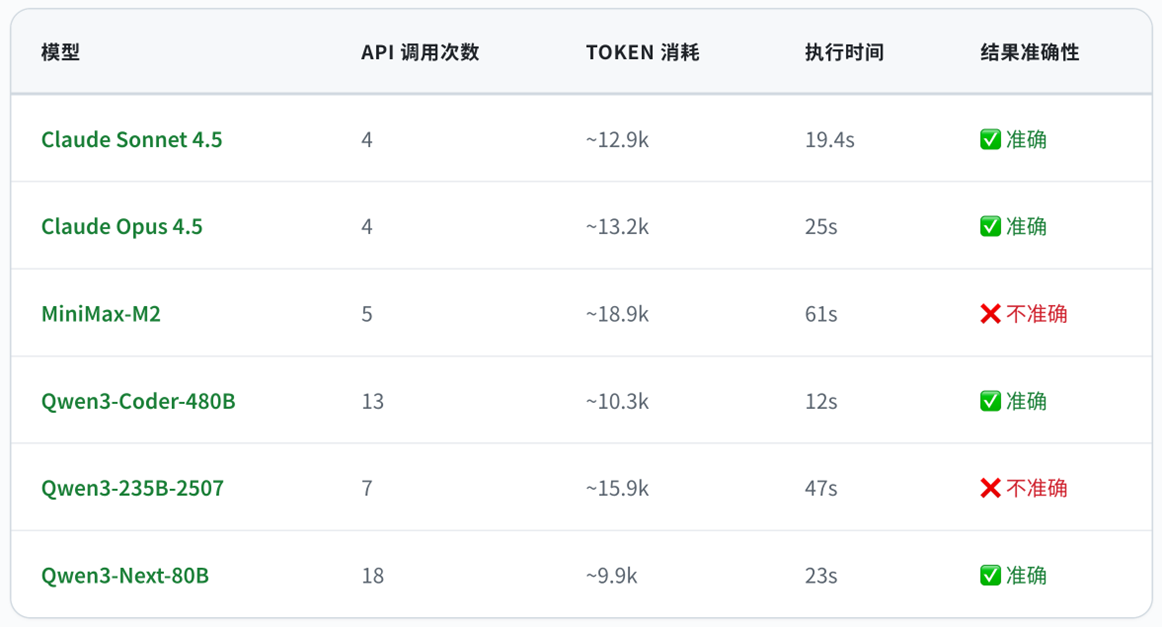 |
注:Qwen3-Coder-480B和Qwen3-Next-80B的API调用次数偏多,是因为没有按照系统指令生成并行执行代码,而是串行调用。
在非PTC模式下也做了同样测试:
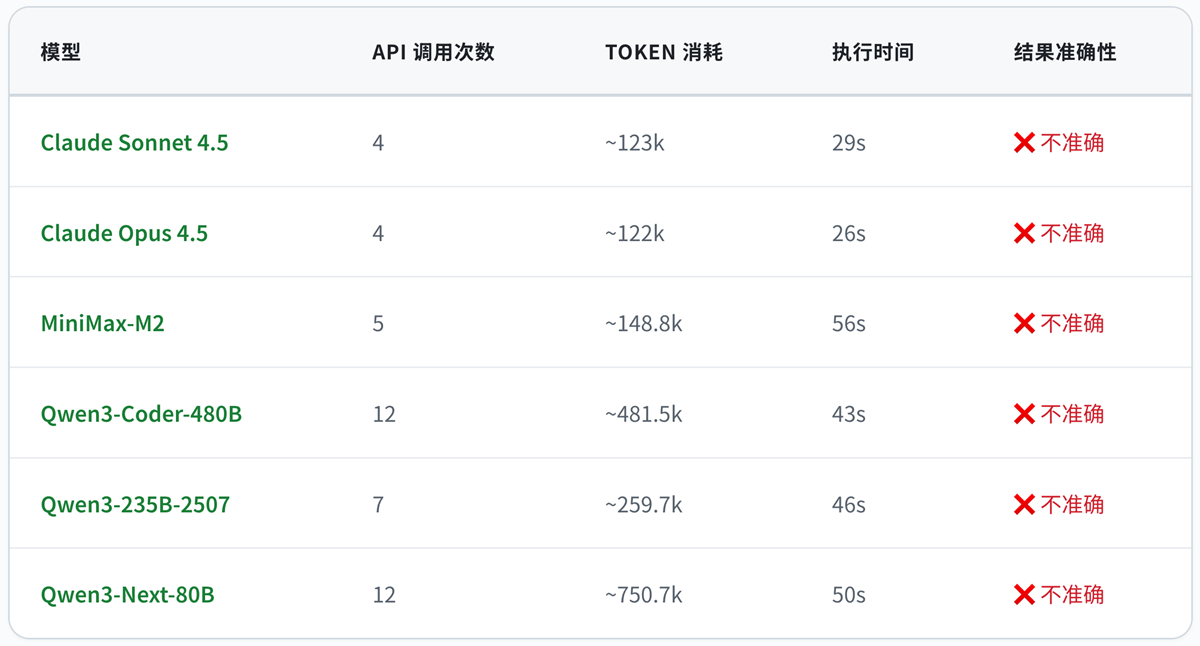 |
PTC vs 非 PTC 模式对比分析
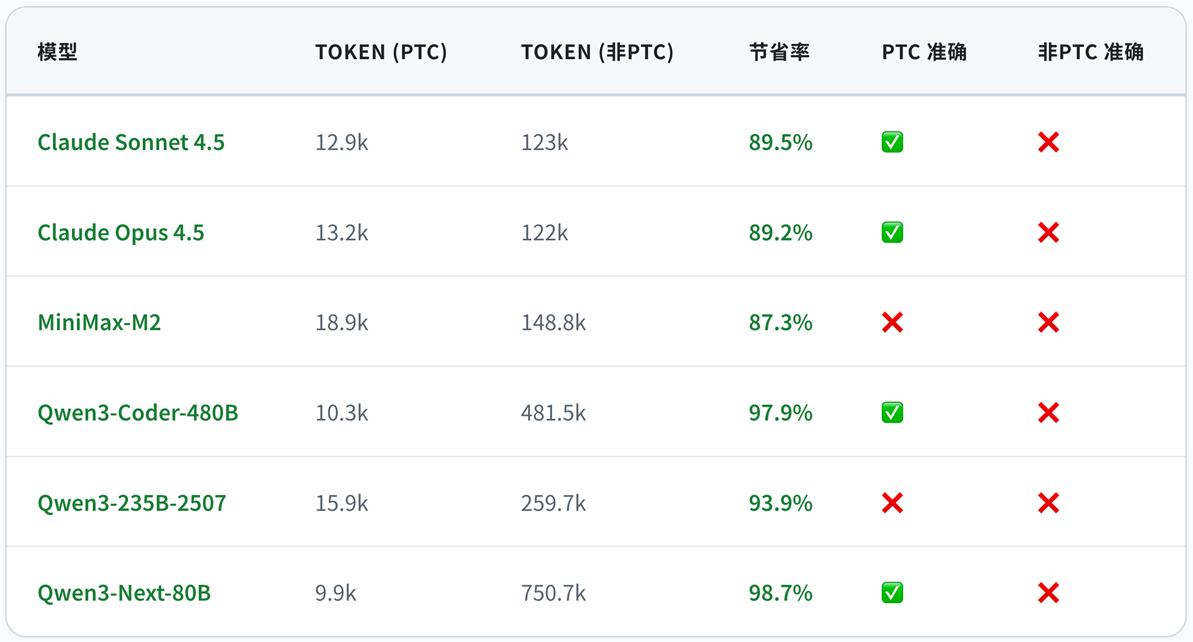 |
核心发现:
- Token 消耗大幅降低:所有模型在 PTC 模式下 Token 消耗均降低 87%-99%,平均节省约 93%
- PTC 模式准确率更高:在 PTC 模式下有 4 个模型给出正确答案,而非 PTC 模式所有模型都无法给出100%正确答案
- Qwen3 系列表现亮眼:Qwen3-Coder-480B 和 Qwen3-Next-80B 在 PTC 模式下表现优异,Token 节省率分别达9% 和 98.7%
- PTC 提升推理质量:通过代码编排工具调用,模型可以更精确地处理数据过滤、聚合逻辑,减少在自然语言中处理大量数据导致的错误
关键发现:通过我们的自托管 PTC 方案,Qwen、MiniMax 等非 Claude 模型也能使用 PTC 范式,显著降低 Token 消耗并提升结果准确性。PTC 的高效工具调用模式不再是 Claude 的专属能力。
五、PTC 方案的核心价值
5.1 验证了PTC 范式是一种可以被复用的Agent工程方案
通过我们的实践,验证了PTC 范式不再是官方API专属,通过 Docker Sandbox + API 代理的组合,理论上任何支持 Tool Use 的大模型都可以使用 PTC(*根据任务难度,实际准确性有所不同)。我们提供的Anthropic-Bedrock API Proxy参考方案中,可以支持Bedrock上的:
# Anthropic Claude 系列
“claude-sonnet-4-5-20250929”,
“claude-opus-4-5-20251101”,
# Qwen 系列
“qwen.qwen3-coder-480b-a35b-v1:0”,
“qwen.qwen3-next-80b-a3b”,
# 其他模型
“minimax.minimax-m2”
以及其他任何支持 tool_use 的模型
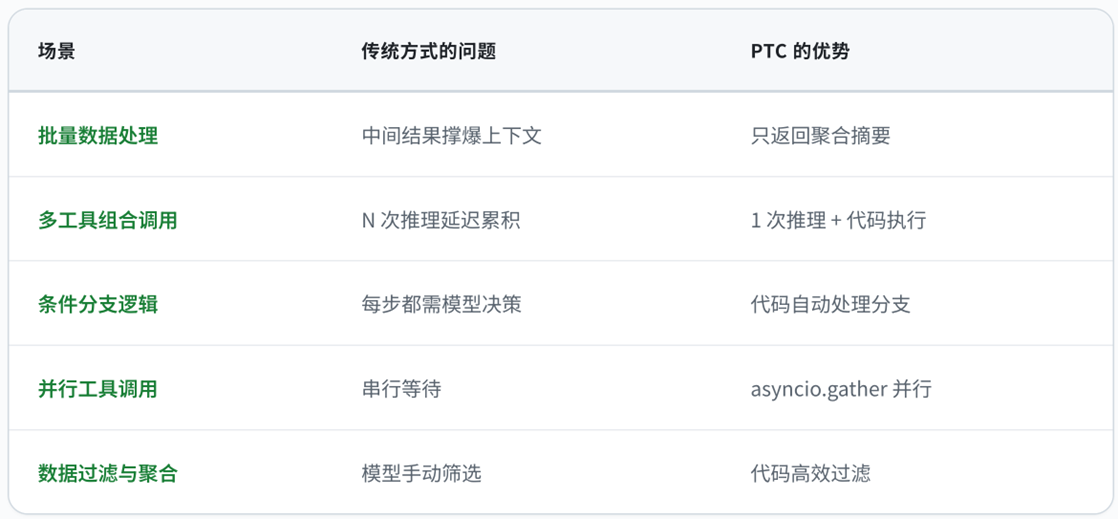
5.2 适用场景
PTC 特别适合以下场景:
 |
5.3 成本对比示例(基于实际测试)
以本文示例中的企业差旅费用审计测试为例:
任务:分析 8 名工程团队成员的 Q3 差旅费用是否超标
数据规模:
- 8 人 × 20-50 条费用明细 = 160-400 条费用记录
- 每条记录包含 15+ 个字段(expense_id、date、amount、category、status、..)
实际测试数据对比(以 Claude Sonnet 4.5 为例)
 |
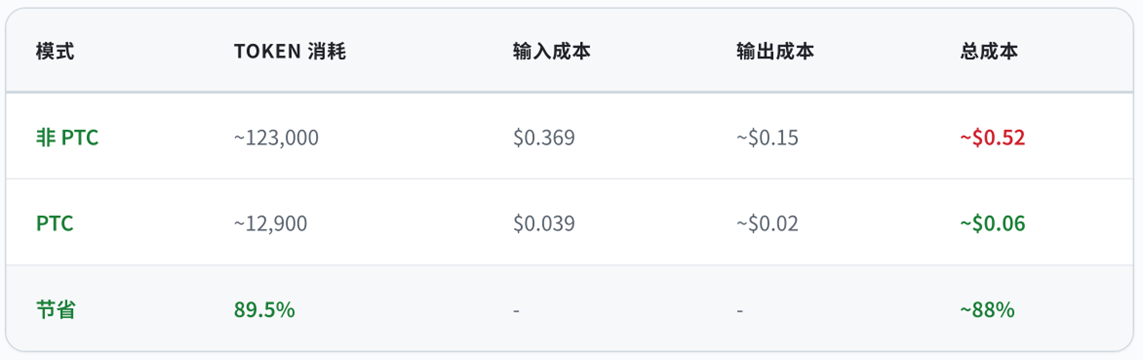
成本估算(以 Claude Sonnet 定价 $3/$15 per 1M tokens)
 |
如果是生产环境每天执行 1000 次类似查询:
- 非 PTC:$520/天 → $15,600/月
- PTC:$60/天 → $1,800/月
- 月节省:$13,800(88%)
六、在 Amazon Bedrock 上使用完全兼容 Anthropic API PTC服务
Amazon Bedrock 是亚马逊云科技的一项全托管的大模型服务,旨在帮助开发者轻松构建和扩展生成式 AI 的应用程序。客户可以通过统一的API为客户提供来自全球领先AI公司和亚马逊的基础模型进行访问和使用,而不需要管理任何服务器、GPU 或基础设施。除了基础模型外,Amazon Bedrock 还提供包括全球范围推理 (Global Cross Region Inference),知识库(Knowledge Bases),安全护栏(Guardrails),智能体(Agents)等多种功能,帮助客户构建具备安全性、负责任AI的生成式AI应用。
相较于官方平台提供的Claude API,Amazon Bedrock Claude API还具备如下优势:
- 定价与计费
- 按需付费定价,灵活的按使用量计费模式,无预付费用,无采购延迟
- 成本控制与可观测性,监控跨团队和项目的使用情况,成本随组织规模灵活扩展
- 数据安全与隐私
- 完整的数据主权,客户的所有数据和交互均保留在亚马逊云科技环境中,数据永不离开,也不会用于模型训练
- 完整的数据主权,您的所有数据和交互均保留在您的亚马逊云科技环境中,数据永不离开
- 合规与审计
- 增强的合规能力,可获得 FedRAMP High、DoD impact level 4/5、HIPAA 及其他政府级认证
- 完整可见性,在 CloudTrail 中追踪所有模型交互,提供完整的审计追踪以满足合规要求
- 可用性与服务保障
- 智能流量路由,通过跨区域推理和全球端点提高可用性
- SLA 保障,享受亚马逊云科技企业级服务等级协议和正常运行时间承诺
6.1 项目简介
如果你希望在 Amazon Bedrock 上使用完全兼容 Anthropic API 的服务(包括 PTC),可以使用开源项目 anthropic_api_converter。
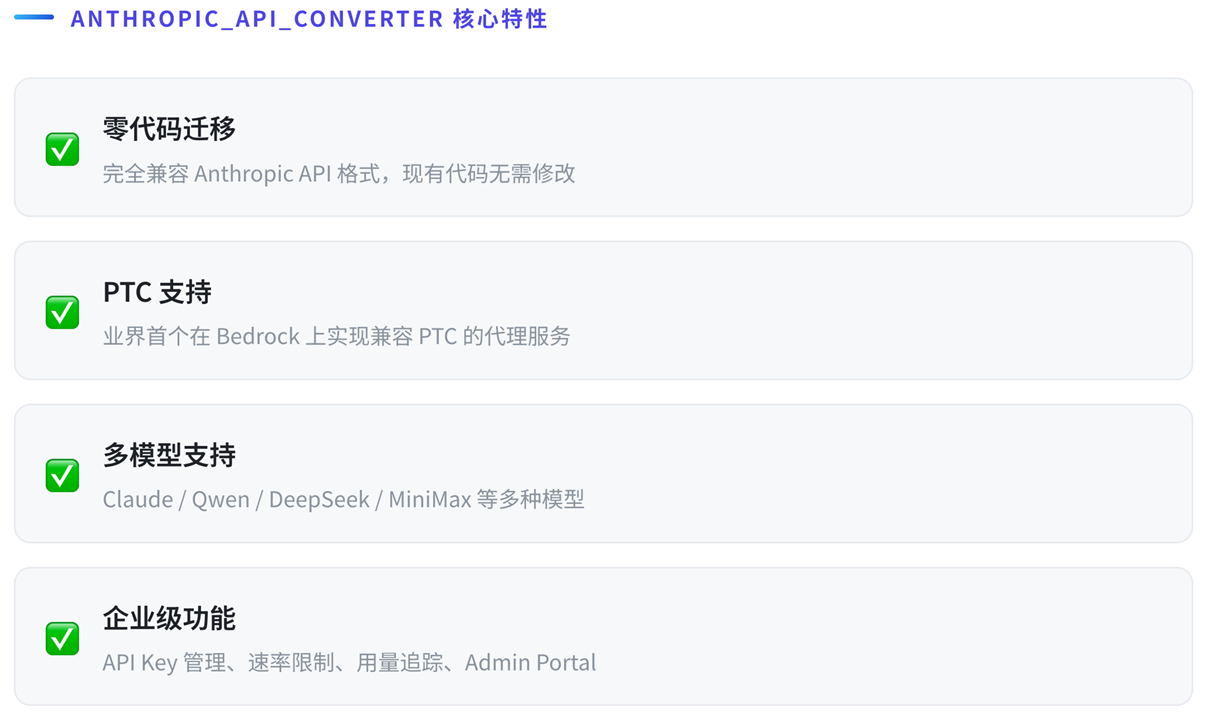
这是一个轻量级 API 转换代理服务,让你无需修改代码即可:
- 在 Claude Code 中使用 Bedrock 上的 Qwen/MiniMax 等模型
- 在 Claude Agent SDK 中混合使用不同模型
- 完整支持 Programmatic Tool Calling API
- 支持Bedrock Service Tier服务等级定义
6.2 核心特性
 |
6.3 CDK一键部署
Fargate 部署(默认,适合不需要 PTC 的场景):
# ⚠️ -p 参数需要根据当前的编译平台更改成 amd64 或 arm64
# ARM64(AWS Graviton、Apple Silicon)
./cdk/scripts/deploy.sh -e prod -r us-west-2 -p arm64
EC2 部署(启用 PTC 功能):
# 使用 -l ec2 参数启用 EC2 启动类型,自动启用 PTC
./cdk/scripts/deploy.sh -e prod -r us-west-2 -p arm64 -l ec2
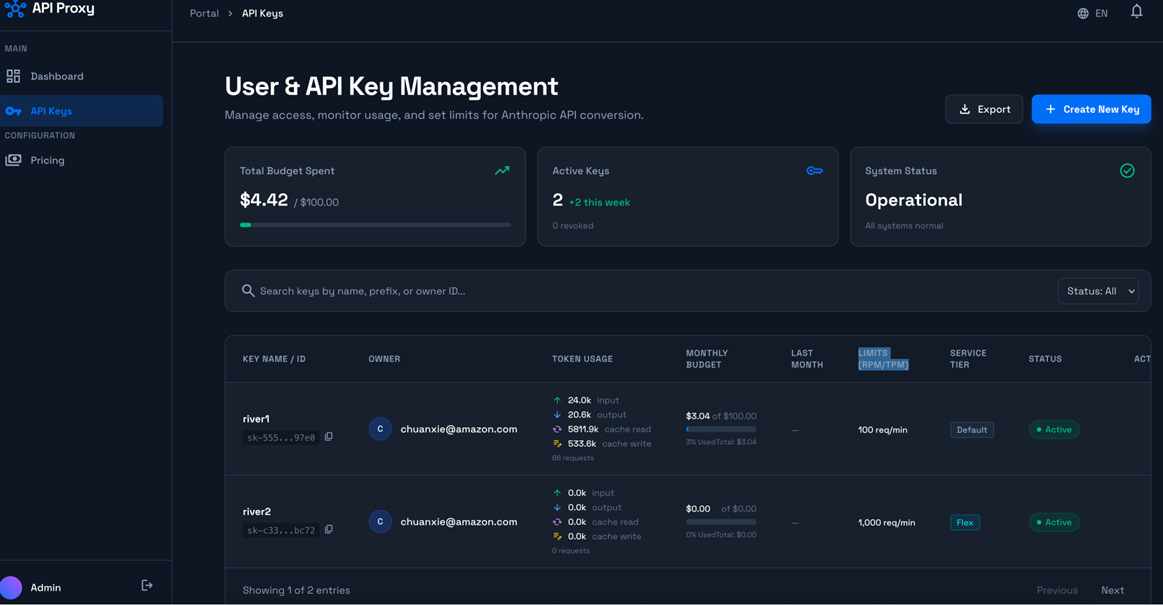
自带管理界面,提供api key管理,用量监控,预算控制等管理功能
 |
6.4 快速使用
七、总结与展望
Programmatic Tool Calling 代表了 AI Agent 工具调用的新范式:
- 效率革命:从 N 次推理降至 1-2 次,Token 消耗降低 37%+
- 代码编排:用 Python 表达复杂逻辑,比自然语言更精确
- 上下文隔离:中间数据不进入模型上下文,只保留关键输出
- 并行执行:通过gather 实现真正的并行工具调用
通过我们基于亚马逊云科技 ECS Docker Sandbox 以及Amazon Bedrock自托管方案,验证了PTC范式是一种可以被复用的Agent 工程方案:
- ✅ 完全兼容官方 PTC 协议
- ✅ 支持任意大模型(Qwen、DeepSeek、..)
- ✅ 沙盒私有化部署,数据安全可控
这是 Agent 工具调用从“对话式“向“程序化“演进的重要一步。
参考资料
- Anthropic 官方文档
- Introducing advanced tool use on the Claude Developer Platform
- Programmatic Tool Calling Documentation
- PTC Cookbook
- 本文配套的开源项目
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
