亚马逊AWS官方博客
使用Amazon SageMaker Ground Truth为机器学习工作流构建实时数据标记管道
原文链接:
使用Amazon SageMaker Ground Truth为机器学习工作流构建实时数据标记管道
高质量的机器学习(ML)模型取决于准确标记的高质量训练、验证与测试数据。随着机器学习与深度学习模型越来越多的集成到生产环境中,建立一套可自定义实时数据标记管道以持续接收并处理未标记数据,变得比以往任何时候都更重要。
例如,大家可能需要创建一款面向消费者的应用程序,此应用程序定期收集新的数据对象并将其发送至数据标记管道,由数据标记管道生成标签并构建出用于模型训练或再训练的数据集。这条管道将建立起一条完整的正反馈回路,由此生成更准确、更复杂的模型。
Amazon SageMaker Ground Truth流式标记作业 提供基础设施与资源,可供您创建持续运行的标记作业。此作业可按需接收新的数据对象并将其发送至工作人员进行标记。您可以将多个流式标记作业链接起来,由此创建出更复杂、更完善的数据标记管道。
在本博客中,我们将共同了解如何设置并自定义Ground Truth流式标记作业。
演练概述
除了讨论使用流式标记作业的好处(例如消除延迟、强制幂等以及自定义输入数据源)之外,本文还将提供两份Jupyter notebook。您可以使用它们设置流式标记作业,或者按照本文中的控制台操作说明使用您所指定的、受支持的特定语言AWS软件开发套件(SDK)创建流式标记作业。
第一份notebook将展示如何创建Ground Truth流式标记作业。此notebook支持多种内置与自定义任务类型,可供您快速为各种数据类型(例如图像、文本、视频、视频帧以及3D点云等)创建数据标记管道。本次演练主要讲解如何使用Amazon Simple Notification Service (Amazon SNS)将实时消息安全发送至流式标记作业,借此将新的数据对象交付给工作人员进行标记。您还将了解如何在工作人员完成对数据对象的标记之后,设置通知以实时接收来自标记任务的输出结果。
在创建流式标记作业时,您可以将作业的输出数据路由至另一流式标记作业,借此建立起更为复杂的数据标记管道,借此完成数据标记验证与调整。这被称为链式标记作业。您可以在本文中使用第二份notebook,学习如何将两项流式标记作业链接在一起。
您可以在默认模式下运行这两份notebook,全程几乎不需要额外输入。默认模式将创建图像对象检测(边界框)标记作业,并演示如何将数据对象发送至这些标记作业。如果您要使用自己的数据对象,可以关闭默认模式。
首先,请完成本文中的“先决条件”与“启动notebook实例并设置演示notebook”部分的内容,以收集完成本教程所需要的各类资源。您也可以选择在虚拟桌面中设置Jupyter notebook ground_truth_create_streaming_labeling_job.ipynb 与 ground_truth_create_chained_streaming_labeling_job.ipynb。
下图所示,为这套解决方案的基本架构。

流式标记作业的优势
第一份notebook将向您展示如何创建Ground Truth流式标记作业。
实时输入通道
您可以实时持续将对象输送至标记作业。Amazon SNS允许您配置主题,进而将对象实时馈送至运行中的标记作业内。
长期运行的工作流
您可以启动标记作业,并通过持续馈送对象使其长期保持运行。流式作业在设计上考虑到工作流的长期运行需求,除非您明确要求停止,否则其将一直保持运行。
Ground Truth会在长时间闲置后停止运行。如果Ground Truth在一定天数内未检测到任何等待进行标记的对象,则会将作业定义为闲置。例如,如果Ground Truth没有从SNS输入主题处接收到新的数据对象,而且所有已馈送至系统内的对象均已标记完成,则将启动闲置计时器。如果闲置计时器达到一定数值,则Ground Truth将停止标记作业。
简而言之,如果对象以有规律的方式持续流经系统,则可实现长期运行工作流。关于配置闲置计时器的更多详细信息,请参阅停止流式标记作业。
消除延迟
使用流式标记作业,对象可以更快流经数据标记管道。流式作业以滑动窗口方式运作。只要插槽仍然可用,Ground Truth就会不断发送对象以进行标记。插槽由MaxConcurrentTaskCount参数进行定义,此参数将定义能够发往标记作业的最大对象容纳(插槽)数量。当达到MaxConcurrentTaskCount上限时,您可以查看在Amazon Simple Queue Services (Amazon SQS)中排队的数据对象的数量。
例如,如果MaxConcurrentTaskCount 为10,而且通过输入SNS主题发送了25个对象,则Ground Truth一次最多会将10个对象发送至工作人员,并在Amazon Simple Queue Service (Amazon SQS)队列中最多保留15个剩余对象。如果工作人员继续工作并将处理完毕其中2个对象,则意味着空出2个可用插槽,接下来队列中的15个对象将把2个对象发送至这些插槽。通过这种方式,工作人员即可从输入中不断获取对象,最多为10个。批处理对象不会造成任何延迟。当工作人员处理对象时,新对象将被不断泵入,保证您快速完成数据标记。
速率限制
您也可以限制并控制将数据交付给工作人员的方式与时间。在将对象提供至输入的SNS主题时,它们会被收集至您账户内名为GroundTruth–<labeling-job-name>的SQS队列当中。如果发送至标记作业的对象多于MaxConcurrentTaskCount,则其将被保留在SQS队列当中。否则,它们将被直接发送至工作人员进行标记。SQS队列内的对象最多驻留14天。
例如,如果MaxConcurrentTaskCount为 1000,而且通过SNS主题将2500个对象发送至流式标记作业,那么Ground Truth一次最多会将1000个对象发送给工作人员,SQS队列中的初始保留对象数量则为1500个。工作人员的速度决定了队列中这1500个对象发送至标记作业的速度。如果这些对象在队列中驻留的时间比预期更长,则表明您发送的对象数量超过了特定时段之内工作人员所能处理的上限。在这种情况下,您可以调整输入,确保以较慢的速度将对象馈送至Amazon SNS。您还可以变更MaxConcurrentTaskCount以匹配工作人员的标记速度。
要监控向流式标记作业中SQS队列内馈送数据对象的速度与数量,您可以使用Amazon CloudWatch为队列设置警报。关于更多详细信息,请参阅用于Amazon SQS的CloudWatch指标。例如,您可以在ApproximateAgeOfOldestMessage指标上设置一项警报,借此查看最早数据对象还有多久达到14天的驻留期限。触发此警报之后,您可以采取适当的处理措施,例如将对象重新发送至输入的SNS主题,或者提醒工作人员如不及时处理则部分任务即将过期。
输出通知
添加一个新的SNS通道,作为您标记作业的输出通道。当工作人员在Ground Truth流式标记作业中完成标记工作时,Ground Truth将使用您的输出主题将输出结果发布至您所指定的一个或者多个端点。要在工作人员完成标记任务时接收通知,则必须使用端点订阅SNS输出主题。例如,您可以设置电子邮件、AWS Lambda函数或者SQS队列以订阅标记作业的SNS输出主题,这样通过Ground Truth标记完成的任何对象都将在处理结束后实时显示。
除了SNS输出主题之外,您也可以在Amazon S3输出路径中使用频繁的输出文件更新。所有标签都将被添加至Amazon S3中的输出manifest文件中。例如,如果错过了实时输出通知,则可以引用此文件达到相同的效果。如果对S3存储桶进行版本控制,您还可以查看并访问输出manifest文件的不同版本。
幂等
您可以使用唯一标识符来区分输入标记作业的对象,并在输出结果中进行跟踪。您可以使用自己的唯一标识符,或者直接使用Ground Truth自动生成的标识符。
使用Amazon SNS消息将数据对象发送至流式标记作业时,您可以指定重复数据删除密钥与重复数据删除ID。唯一标识符可以确保发送至标签的每个对象都是唯一的。如果您发送两个具有相同唯一标识符的对象,则后者将被视为重复对象。这样可以防止您意外注入不想要的对象,并在生成标签时提供ID以跟踪输出数据。关于更多详细信息,请参阅重复消息处理。
将对象放入Amazon S3
您可以将S3存储桶设置为接收到数据对象时,自动向SNS输入主题发布数据标记请求。使用这样的设置,您可以将对象放入S3存储桶,而后自动将其发送至您的流式标记作业。
关于设置S3存储桶与通知的更多详细信息,请参阅使用S3存储桶将数据对象发送至标记作业。
解决方案概述
要完成本用例,您需要使用 Amazon SageMaker示例 GitHub repo中的notebook ground_truth_create_streaming_labeling_job.ipynb。
在完成前期准备之后,您可以通过以下操作启动本次演练:
- 启动notebook实例并设置演示notebook。
- 启动一项流式作业。
- 监控该作业。
- 将对象发送至运行中的作业。
- 停止标记作业。
使用支持的特定语言AWS SDK中的Ground Truth API操作CreateLabelingJob启动流式标记作业。
先决条件
如果您是第一次使用Ground Truth流式标记作业,建议您在开始本轮演练之前首先阅读Ground Truth流式标记作业。
要完成本轮演练,请完成以下步骤:
- AWS账户。
- 与您流式标记作业处于同一AWS区域内的S3存储桶。如果您使用的是演示notebook,则该存储桶还必须与Amazon SageMaker notebook实例位于同一区域。您可以在notebook变量BUCKET当中指定此存储桶,或者使用您创建notebook实例所在的区域内的默认存储桶。关于更多详细信息,请参阅如何创建S3存储桶。
- 具备必要权限的AWS身份与访问管理(IAM)执行角色。这里的notebook将自动使用此角色以创建notebook实例(详见下一条)。请向此IAM角色添加以下权限:
- 添加托管策略 AmazonSageMakerGroundTruthExecution。以下GIF图演示了如何将此策略附加至IAM控制台上的角色。

-
- 在创建角色时,您需要指定Amazon S3权限。您可以允许该角色访问Amazon S3中的所有资源,也可以指定特定存储桶。请确保您的IAM角色有权访问演练所使用的S3存储桶。该存储桶必须与您的notebook实例处于同一区域。
- 工作小组。所谓工作小组,是指您指定的负责标记数据的一组工作人员。您可以在Amazon Mechanical Turk外聘人员、供应商外包人员或者内部员工当中做出选择。无论选择哪种选项,Ground Truth都会将任务发送至相应工作人员。要预览工作人员界面,请使用内部工作人员并将您自己添加至notebook所使用的工作小组中。
- 要使用内部或供应商外包人员,请记录下您所使用工作小组的Amazon资源名称(ARN),以供后续在随附的Jupyter notebook中使用。以下GIF演示了如何在Amazon SageMaker控制台上快速创建内部工作小组。
-
- 如果您未指定内部或供应商外包人员,则notebook会自动使用Mechanical Turk外聘人员。在创建标记作业时,您可以指定按标记数据对象向单一工作人员支付的总薪酬额度。要了解更多详细信息,请参阅Amazon SageMaker Ground Truth费率标准。
- 如果您不打算使用notebook中的默认模式,则必须提供HTML工作人员任务模板。此模板用于向工作人员提供用于完成标记任务的任务UI。您可以将模板直接复制到notebook当中,借此提供将模板写入Amazon S3的逻辑,也可以将模板添加至S3存储桶内并记录下模板的Amazon S3 URI。关于使用示例模板的更多详细信息,请参阅内置任务类型。关于自定义标记工作流的更多详细信息,请参阅步骤2:创建自定义标记任务模板。
- 标签类型列表。Notebook将使用此列表创建一个标签类别配置文件,并将其上传至Amazon S3。如果您使用notebook中的默认模式,则无需额外提交此列表。
- 如果您不使用notebook,则需要两项Lambda函数分别对输入数据(PreHumanTaskLambdaArn)与输出数据(AnnotationConsolidationLambdaArn)进行预处理。如果您选择使用内置任务类型,则Ground Truth将自动提供这些函数。
启动notebook实例并设置演示notebook
要使用notebook,您需要启动Amazon SageMaker notebook实例。关于更多详细信息,请参阅创建notebook实例。在您的notebook实例处于活动状态时,请完成以下步骤以使用此notebook:
- 在Amazon SageMaker上的Notebook instances当中,找到您的notebook实例。
- 选择Open Jupyter 或者 Open Jupyter Lab。
- 在Jupyter中的Jupyter Lab内 选择SageMaker Examples, 而后选择Amazon SageMaker图标以查看示例notebook列表。
- 在 Ground Truth Labeling Jobs部分,从以下notebook选项其一以完成本轮演练。在Jupyter中选择notebook旁边的Use开始使用该notebook。在Jupyter Lab中选定该notebook,而后选择Create Copy。
启动流式作业
流式标记作业与非流式标记作业使用相同的API操作CreateLabelingJob创建而成。要创建流式标记作业,请指定输入主题作为输入数据源,并指定输出主题作为输出数据源。新数据对象通过输入主题持续发送至您的标记作业。一旦有工作人员完成标记任务,输出数据就会被发送至输出主题。您可以配置输出主题,保证在收到输出数据时立即发送通知或触发特定事件。
在创建流式标记作业时,输入manifest文件是可选项。
您可以使用Amazon SNS API操作CreateTopic 以创建自己的输入与输出主题,也可以使用Amazon SNS控制台。对CreateTopic的成功请求的响应结果包含主题ARN。您可通过参数在CreateLabelingJob中指定您的输入与输出的主题ARN。
如果主题名称中包含 GroundTruth(不区分大小写)或者SageMaker(不区分大小写),则策略 AmazonSageMakerGroundTruthExecution会授予必要权限,以将消息发送至您的标记作业。如果不包含,请确保授予您的IAM角色必要权限,从而针对SNS主题执行 sns:Publish 与sns:Subscribe操作。
使用 Amazon Python (Boto3) SDK创建SNS主题
Notebook ground_truth_create_streaming_labeling_job.ipynb 会使用AWS Python (Boto3)SDK创建SNS主题。在以下代码中,将LABELING_JOB_NAM部分替换为您的标记作业名称:
sns = boto3.client('sns')
# 创建输入主题
input_response = sns.create_topic(Name= LABELING_JOB_NAME + '-Input')
INPUT_SNS_TOPIC_ARN = input_response['TopicArn']
# 创建输出主题
output_response = sns.create_topic(Name= LABELING_JOB_NAME + '-Output')
OUTPUT_SNS_TOPIC_ARN = output_response['TopicArn']
在Amazon SNS控制台上创建SNS主题
要在Amazon SNS控制台上创建SNS主题,请完成以下操作步骤:
-
- 在Amazon SNS控制台上,选择Topics。
- 选择Create topic。

- 在Name部分,输入名称。
- 在Display name部分,输入显示名称(可选)。
- 如果必要,请为您的主题添加其他配置,例如Encryption, Access policy, Delivery retry policy, Delivery status logging。
在主题创建完成之后,将输入主题ARN馈送至 LabelingJobSnsDataSource.SnsTopicArn ,再将输出主题ARN馈送至 OutputConfig.SnsTopicArn。
使用CreateLabelingJob创建流式标记作业
我们需要使用Amazon SageMaker API操作CreateLabelingJob以创建Ground Truth流式标记作业。
ground_truth_create_streaming_labeling_job.ipynb notebook将引导您创建所需资源并配置请求。
如果您不使用此notebook,则可使用CreateLabelingJob支持的AWS SDK。关于使用API请求创建流式标记作业的更多详细信息,请参阅示例:使用SageMaker API创建流式标记作业。如果您刚刚接触Ground Truth,本文建议您使用基于图像或基于文本的内置任务类型之一来熟悉Ground Truth流式标记作业的使用方式。
填写请求的必要的参数之后,提交请求以创建标记作业。具体请参阅ground_truth_create_streaming_labeling_job.ipynb notebook中的“使用CreateLabelingJob API创建流式标记作业”部分。您也可以使用AWS命令行界面(AWS CLI)或者AWS SDK。关于更多详细信息,请参阅示例:使用SageMaker API创建流式标记作业。
监控作业状态
在作业创建完成之后,您可以调用DescribeLabelingJob 。具体请参阅ground_truth_create_streaming_labeling_job.ipynb notebook中的“使用DescribeLabelingJob API描述流式标记作业”部分。
在通过SNS通道馈送对象时,请首先确保 LabelingJobStatus 为 InProgress。以下示例代码,为您演示了如何使用 DescribeLabelingJob (使用AWS Python (Boto3) SDK)检索标记作业状态:
sagemaker = boto3.client('sagemaker')
sagemaker.describe_labeling_job(LabelingJobName=LABELING_JOB_NAME)['LabelingJobStatus']
如果您在CreateLabelingJob 请求中指定了可选字段S3DataSource.ManifestS3Uri,则在标记作业开始之后,Amazon S3文件中的对象会自动发送至工作人员。DescribeLabelingJob请求响应结果中的LabelCounters元素最初会将这些对象显示为Unlabeled,然后在完成标记并由工作人员提交标记结果之后将其显示为HumanLabeled。
Amazon SQS提供一套安全、持久且高度可用的托管队列。流式标记作业会在您的账户中创建一个SQS队列。您可以使用GroundTruth-LABELING_JOB_NAME名称检查此队列。以下示例代码,为您演示了如何使用 GetQueueUrl (使用AWS Python (Boto3) SDK)检索标记作业状态:
sqs = boto3.client('sqs')response = sqs.get_queue_url(QueueName='GroundTruth-' + LABELING_JOB_NAME.lower())
将对象发送至运行中的作业
在标记作业开始之后,您可以通过控制台或Amazon SNS API将数据对象馈送至其中。关于更多详细信息,请参阅使用Amazon SNS发送数据对象。我们用于发送数据的SNS消息格式与增强manifest格式相同。
例如,要将一个新的图像对象发送至图像分类标记作业,您的消息将类似于以下形式:
{"source-ref": "s3://awsexamplebucket/example-image.jpg"}
如果您创建的是基于文本的标记作业,则请求应类似于以下形式:
{"source": "Lorem ipsum dolor sit amet"}
在Amazon SNS控制台上发布请求
要在Amazon SNS控制台上向您的标记作业发布请求,请完成以下操作步骤:
-
- 在Amazon SNS控制台上, 选择Topics。
- 选择您的输入主题。
- 选择Publish message。

使用Publish API操作发布请求
通过支持的AWS SDK,您可以使用Amazon SNS API操作 Publish 发送请求以标记流式标记作业中的数据对象。
Notebook将演示如何使用此项操作发布消息。
以下代码所示,为您演示了为如何使用AWS Python (Boto3) SDK向Publish发送请求。请将其中的INPUT_TOPIC_ARN 替换为您的输入主题ARN,并将REQUEST 替换为类似于以上示例的请求。
sns = boto3.client('sns')
published_message = sns.publish(TopicArn=INPUT_TOPIC_ARN,Message=REQUEST)
发布请求后,对DescribeLabelingJob的调用显示Unlabeled递增1:
"LabelCounters" : {
'TotalLabeled': 0,
'HumanLabeled': 0,
'MachineLabeled': 0,
'FailedNonRetryableError': 0,
'Unlabeled': 1
}
预览工作人员任务
如果您使用内部员工进行数据标记,请将您自己设定为标记人员,借此导航至工作人员门户以预览标记任务。您可以在用于启动标记作业的区域内的Ground Truth控制台(在Amazon SageMaker控制台上)的Labeling workforces页面中找到工作人员门户链接。在将自己添加至工作小组之后,即可使用下图中的链接收取欢迎邮件。

当工作人员完成数据对象标记并进行提交数据对象时,结果将发送至输出主题。此外,结果还会定期添加至我们在S3OutputPath中创建标记作业时所指定的S3输出存储桶中。
停止标记作业
您可以在长期运行工作流中使用流式标记作业,这些作业将一直运行直到您停止它们为止。通过这种方式,您可以将对象持续馈送至标记作业中。
但是,如果系统检测到没有需要标记的对象,并且闲置状态持续超过特定天数,则Ground Truth会尝试停止作业。关于更多详细信息,请参阅停止流式作业。
您可以在Ground Truth控制台上或使用Ground Truth API操作StopLabelingJob停止标记作业。要使用控制台,完成以下操作步骤:
-
- 在Amazon SageMaker控制台上, 选择Ground Truth。请确保使用您启动标记作业所在的区域。
- 选定您希望停止的标记作业。
- 在Actions下拉菜单中,选择Stop job。

Notebook中的最后一个单元格演示了如何使用AWS Python(Boto3)SDK停止标记作业:
sagemaker = boto3.client('sagemaker')
sagemaker.stop_labeling_job(LabelingJobName=LABELING_JOB_NAME)成功停止标记作业后,其状态将显示为 Stopped。
流式标记作业的其他功能
以下各节将介绍流式标记作业的其他功能:将对象放入S3存储桶中将其自动发送至标记作业,以及将多个标记作业链接起来。
使用S3存储桶将数据对象发送至标记作业
您可以将S3存储桶设置为在数据对象添加到存储桶时,自动将数据标签请求发布到SNS输入主题。使用此设置,您可以将对象放入S3存储桶,并将其自动发送至流式标记作业。
要将S3存储桶配置为自动将数据对象发送至SNS输入主题,您需要向该输入主题添加访问策略,以允许Amazon S3向其添加事件。以下代码所示,为如何使用主题ARN(请替换其中的SNS-topic-ARN)进行策略设置:
{
"Version": "2012-10-17",
"Id": "example-ID",
"Statement": [
{
"Sid": "example-statement-ID",
"Effect": "Allow",
"Principal": {
"AWS":"*"
},
"Action": [
"SNS:Publish"
],
"Resource": "SNS-topic-ARN",
"Condition": {
"ArnLike": { "aws:SourceArn": "arn:aws:s3:*:*:<bucket-name>" },
"StringEquals": { "aws:SourceAccount": "<bucket-owner-account-id>" }
}
}
]
}
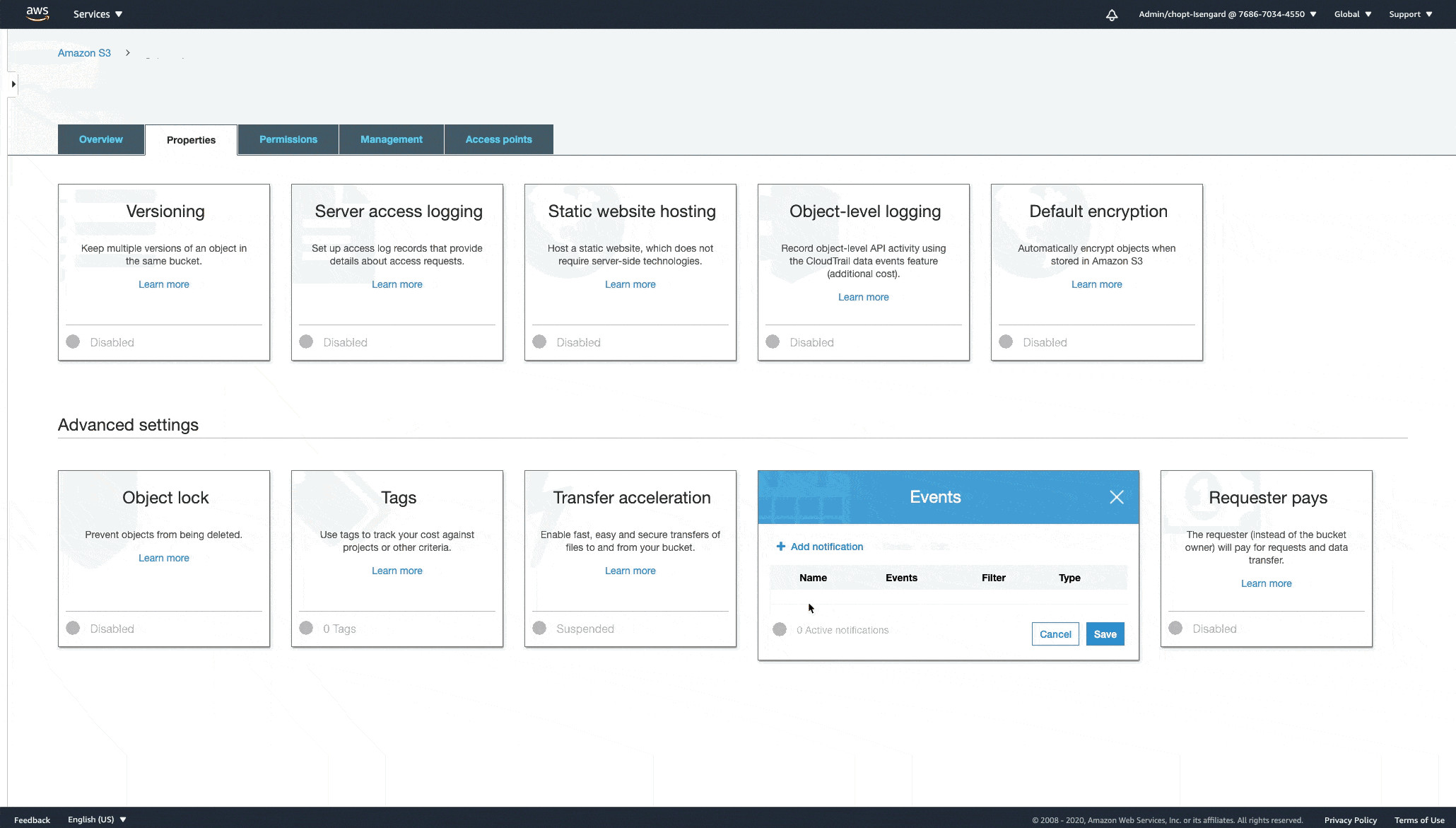
要设置S3存储桶以将数据对象发送至Amazon S3控制台上的流式标记作业,请完成以下操作步骤:
- 在Amazon S3控制台上, 选择用于将数据对象发送至标记作业的存储桶。
- 在Properties选项卡的Advanced settings之下, 选择Events。
- 选择Add notification。
- 为您的通知设定名称。
- 选择All object create events。
- 作为可选项,如果要将数据对象放入S3存储桶中的前缀中,请输入前缀。
- 如果您只希望将特定类型的数据对象发送至SNS输入主题,可以指定相应的后缀。例如,要确保仅将图像文件发送至SNS输入主题,则可设定.jpg,.png,.jpeg。
- 在Send to下拉菜单中,选择SNS Topic。
- 选择您用于或将用于创建标记作业的SNS输入主题。
- 选择Save。
以下GIF演示了如何在Amazon S3控制台上完成此项配置。
作业链接
要创建复杂且持久的实时数据标记管道,为数据对象添加多种类型的注释、审核与验证标签等,您可以将多个流式标记作业链接起来。
换言之,您可以将一个流式标记作业的输出结果发送至另一个流式标记作业。例如,作业1的输出数据可以发送至作业2,作为作业2的输入数据,而作业2的输出数据又可以发送至作业n-1,再由作业n-1将输出数据实时发送至作业n。
例如,您可以使用作业1将语义分段掩码添加至视频帧序列中。然后使用作业2为视频帧添加边界框,以识别并定位每一帧内的数据对象。最后,您可以使用作业3来根据需要对标签进行验证及调整。
为此,我们需要将作业1的输出SNS主题设置为作业2的输入SNS主题。同样的,您可以将作业2的输出SNS主题设置为作业3的输入SNS主题,以此类推。下图所示为这一基本架构。
通过这种方式设置作业之后,流经作业1的数据对象在经过作业1后会自动进入作业2。以下是将两个作业链接起来的潜在应用场景:
- 为具有相似任务类型的作业指定不同的标签属性名称。例如,作业1(标签数据)接入作业2(调整、查看并验证作业1的注释)。
- 在不同任务类型的作业中使用不同的标签属性名称。例如,作业1(用于图像分类的标签)接入作业2(用于物体检测的标签)。
- 在两个作业上使用相同的标签属性名称。例如作业1(标记)链接到作业2(作业1的部分标记数据被流传递至作业2)。
您也可以使用notebook ground_truth_create_chained_streaming_labeling_job.ipynb 学习如何将两个流式标记作业链接起来。本示例演示了上述列表中的第一种用例(为具有相似任务类型的作业指定不同的标签属性名称)。在默认模式下使用时,此notebook会将边界框(对象检测)作业(作业1)链接至边界框审查作业(作业2),即在作业2中实时调整由作业1完成注释的边界框。您也可以对此用例进行泛化,借此建立质量检查工作流,由某一工作小组检查另一工作小组的注释结果。
您也可以使用notebook设置任意类型的链接流作业,以实现多个作业的链接配置。
总结
本文向您介绍了Ground Truth流式功能的优势,以及如何创建并链接流式标记作业。当然,受到篇幅所限,本文所涉及的只是Ground Truth流式功能的一点皮毛。
要亲自动手尝试,请您使用本文提供的notebook启动并操作流式标记作业,或者参阅创建流式标记作业。
如果您有任何建议或意见,请在评论区中与我们分享。