亚马逊AWS官方博客
AWS EKS 中实现应用平滑升级
在EKS中,运行的应用大多都会考虑和CI/CD或者DevOps流程相集成,从而可以更快发布新版本应用,将新产品功能推向市场。同时,由于EKS自身的版本也有生命周期,所以也会面临由于EKS升级而导致的应用向新的NodeGroup进行的平级迁移。如何做到应用的平滑升级是快速上线新产品特性的重要前提。
在EKS环境中,为了实现应用的平滑升级,需要满足以下几个方面的需求:
1. 在旧的容器实例被终止前,必须要有新的实例被创建来为后续的新请求服务。这也就要求应用能同时运行多个容器副本,也就要求有客户端或者服务端的负载均衡器将请求在新旧版本之间进行分发,同时要求容器应用的无状态化,有状态的容器应用不在此文章的讨论范围内。
2. 确保创建的的新版本容器能处理应用请求后再加入到负载均衡器后端:在新的实例被创建后,必须等待完成应用的初始化,才能被设置为可处理新请求的Ready状态,避免新请求路由到未准备好的应用容器。由于Kubernetes的Pod机制支持在Pod创建时,可以使用Readiness探针机制来保证只有Pod中的应用已经就绪时才加入到前端Service的Endpoints 列表中,从而可以正常接受请求输入。由于此部分实现方式较为简单明了,所以本文不作过多讨论。
3. 确保旧版本容器在彻底被移除前处理完遗留请求:在停止容器时,需要保证容器处理完当前的请求才能最终退出,避免引起客户端错误。如何实现这个保证,将会是本文讨论的重点。
4. 需要使用特定的升级方法,如滚动升级和蓝绿部署方法。Kubernetes的Recreate方法不适用于应用的平滑升级,因为这种方法会有应用上的停机时间。
本文将深入内里讨论在EKS环境中以下几种情形下是否可以实现平滑升级,以及如何实现。(EKS中Pod的IP地址是平坦模式,也就是和计算节点地址在同一范围内的物理地址,不同于采用Overlay方式时的地址模式,所以本文的部分内容可能不适用其他Kubernetes环境)。
1. 在纯EKS场景下.Kubernetes的Service对象作为服务端负载均衡器,Deployment的滚动部署作为升级方法。
2. 在EKS中使用SpringCloud微服务框架的场景下.Ribbon作为客户端负载均衡器,Deployment的滚动部署作为升级方法。
3. 在EKS中使用AWS AppMesh/Istio这种以SideCar形式实现微服务框架的场景下.Virtual Service作为客户端负载均衡器,采用Virtual Service的蓝绿部署方法。
在纯EKS场景下实现平滑升级
在纯属EKS环境中,Kubernetes的Service对象作为服务端负载均衡器,Deployment的滚动部署作为升级方法。
在升级应用过程中停止掉旧版本的容器时,需要停止向正在被停止的容器分发新请求,同时也要容忍容器将连接中未处理请求处理完成再退出,也即要满足如下两个条件:
条件1:在停止容器后,如果有新请求发送到此容器,请求自然会得不到正确的响应,所以要求在前端的请求分发层面,不再将请求路由到将即将删除的容器。
条件2:但同时要求针对未完成的请求能继续处理,比如在客户端和后端服务容器之间建立的连接上,仍有正在处理的请求或者有后续的连续请求,应该要允许这些请求处理完成。
如何在Pod的停止过程中实现如上两个条件,需要解析Pod生命周期中的停止过程。

图一:Pod关闭流程
开始Pod的delete流程,Pod进入关闭流程,触发原因可能是用户执行Pod的delete操作,也有可能是执行rollout操作,也有可能是减少replicaset的数量。其整个流程如下:(以下过程从第1到第4步是同时发生)。
1. Kubernetes将容器状态置为Terminating,使用命令查看状态时会处于Terminating状态。
2. 同时通知API Server将Pod从其所属的Endpoints中移除,比如从使用selector归属的某一个Service中移除,此操作执行过程,Service的后端列表中将移除此Pod。
3. 启动Grace shotdown 定时器(值由deployment中的terminationGracePeriodSeconds参数指定,默认值为30)。通知Pod所属节点的Kubelet开始执行Pod的shutdown操作。
4. 通知计算节点上的Kubelet守护进程关闭相应的Pod。
如果Pod定义了preStop hook,kubelet会触发此hook脚本在Pod中的执行.preStop Hook中执行用户定义过程。执行完成后,发送TERM信号给Pod里面的所有容器。
如果未定义PreStop Hook,直接发送TERM给Pod中的所有容器。
5. 执行上述过程后,如果所有清楚过程在Grace Period周期内结束,则Pod结束工作完成。如果Pod仍然未退出,则发送KILL信号,强制结束Pod。针对有preStop Hood的Pod,在发送KILL信号前,有额外一次2秒的时延。
6. 到此,Pod实体已经结束,继续将Pod从API Server记录中清除,此时,客户端无法再检索到Pod。
首先分析Pod被删除时,是否会从其所属的负载均衡器中移除,从而不再接收新的请求。纯EKS模式下,Pod采用Kubernetes Service作为负载均衡器,Kubernetes Service是依赖在计算节点中的Iptables服务来实现。以一个Service有两个对应的Pod为例,查看其在Iptables表中的实现。
1. 找到Service的Cluster IP: kubectl get service php-apache -o custom-columns=ClusterIP:.spec.clusterIP
2. 登录任意节点,查看Cluster IP对应的Iptables条目
iptables -L -t nat
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-SVC-BJ47X7EXARPH4MMJ tcp — 0.0.0.0/0 10.100.81.62 / default/php-apache: cluster IP / tcp dpt:80
Chain KUBE-SVC-BJ47X7EXARPH4MMJ (1 references)
target prot opt source destination
KUBE-SEP-FEFBLPTU36TWIWKJ all — 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.50000000000
KUBE-SEP-2CJO3665RSYCSLOT all — 0.0.0.0/0 0.0.0.0/0
Chain KUBE-SEP-2CJO3665RSYCSLOT (1 references)
target prot opt source destination
KUBE-MARK-MASQ all — 192.168.92.92 0.0.0.0/0
DNAT tcp — 0.0.0.0/0 0.0.0.0/0 tcp to:192.168.92.92:80
KUBE-MARK-MASQ all — 192.168.92.92 0.0.0.0/0
DNAT tcp — 0.0.0.0/0 0.0.0.0/0 tcp to:192.168.92.92:80
每一个Cluster IP都是在Iptables的 chain中, 以ClusterIP为匹配条件,链的背后是两个目标KUBE-SEP-FEFBLPTU36TWIWKJ 和KUBE-SEP-2CJO3665RSYCSLOT,分别对应的是后端两个Pod的地址。两个目标之间是利用statistic模式采用random选择,否则流量只会路由到第一个目标中。0.50000000表示选择到第一个目标的机率是50%,那选择到第二个目标的机率也是50%。
在删除Pod的同时,观察在删除Pod时iptables中的变化,watch -n 0.5 “iptables -L -t nat -n| grep KUBE-SVC-DTU5BYSZICDKSKGD -A 3″。在delete命令执行后,API Server 立即通知各计算节点上kubelet守护进程将Iptables中对应Pod的target删除,此实现可以满足条件一:执行删除Pod的命令后,不再将新请求发送到正在被结束的Pod上。
假如请求是通过基于TCP,或者基于Http1.1或者Http2.0这种长连接机制的协议,后续请求可能会共用同一连接,而将后续的请求发送到被删除的Pod,那Iptables实现的Service负载均衡是否也可以将同一连接中未完成的后续请求继续发送到旧版本Pod呢?这就涉及到Iptables中的两条规范:
Chain中目标的选择,只在建立TCP连接的时候进行。
IPtables的ConnCtrack机制通过Iptables建立的连接,记录连接对应的后端目标。
通过规范一,可以保证针对旧版本Pod的后续的请求不会发送到新的Pod。
通过规范二,可以保证针对旧版本Pod的后续的请求仍然发送到正在被停止的旧版本Pod上。
也就是先前通过iptables建立的到后端的Iptables的连接,会在conntrace模块中记录连接信息。通过在发起节点上的connctrack中记录连接信息,连接中的后续请求可以直接经过同一连接到达后端。连接保持信息可以通过 cat /proc/net/nfconntrack文件查看,如
ipv4 2 tcp 6 86400 ESTABLISHED src=192.168.25.253 dst=10.100.81.62 sport=34784 dport=80 src=192.168.23.104 dst=192.168.25.253 sport=80 dport=34784 [ASSURED] mark=0 zone=0 use=2
也就是建立的连接信息会保持一段时间,此时间由系统选项/proc/sys/net/netfilter/nfconntracktcptimeout_established控制,也就是这里的86400s/24小时。也即是只要双方不主动关闭连接,仍然能将请求在后续24小时内通过conntrack发送到对应的后端。
连接信息已经保存,请求可以继续向目标发送,只要求目标Pod继续在这段时间内存活就可以继续处理后续的请求。可以通过terminationGracePeriodSeconds参数延缓对Pod 的KILL信号发送而延长Pod的存活时间,因为KILL信号无法被Pod捕获,Pod中的进程会被系统强制结束。通过此参数指定一个Pod结束的最长时间,并配合如下机制:
* 利用preStop hook,在这个hook中执行例如sleep一段时间这样的操作,目的是为了延缓进入到下一步结束过程的处理。在hook执行的这一段时间里,Pod可以继续正常运行。
preStop hook配合terminationGracePeriodSeconds就能实现延缓Pod结束的目的,当然也可以考虑在TERM的信号处理函数中执行延缓退出操作,但推荐采用preStop hook的方式,因为TERM信号处理需要在应用代码中进程编程,而且需要Pod中每个容器都要进行TERM捕获的捕获,复杂度较高。相反preStop hook这种方式可以直接在deployment中配置,简单明了。配置如下:
spec:
containers:
lifecycle:
preStop:
exec:
command:
- /bin/sh -c sleep 120
terminationGracePeriodSeconds: 120
通过以上过程的分析,通过EKS的基于Iptables的Service服务结合滚动升级是可以实现平滑升级的。包含以下Service类型
* ClusterIP/NodePort/EKS中类型为LoadBalancer,因为这些Service都是基于利用Iptables实现服务端负载均衡。
但不包含类型为Headless的Service,因为此种Service的实现不基于Iptables。
不过由于以上机制是kubernetes配合计算节点的实现,不是纯粹的应用层机制。如果能完全在应用层实现平滑升级,则整个过程更优雅。
在EKS中使用SpringCloud微服务框架的场景下实现平滑升级
在SpringCloud微服务框架下,服务组件之间采用Ribbon进行请求的分发。Ribbon是客户端负载均衡模式,后端服务节点的选择由客户端负责,在Pod的delete过程中需要让客户端不再分发新的请求到正被删除的节点。需要有机制让客户端感知到后端Pod的删除行为,此机制同样可以利用Pod的preStop hook加以实现。以客户端应用通过Zuul访问后端服务为例,与在纯粹的EKS环境中preStop hook单纯执行sleep操作不同的是,要在preStop hoo中执行:
1. 向Eureka Server注销自己
2. 等待客户端Ribbon中的ServerList过期,在此时间内,Pod仍然能接收前端新的请求

图二:SpringCloud中服务注销及失效周期
由于Eureka和Zuul中组件都有各自的缓存,为了让Pod在客户端彻底过期,需要准确计算应该在上述第二步中的等待时间,涉及以下几个阶段。
Pod向Eurora注销自己,清除readwritemap中的记录,同时停止发送心跳防止再注册
Eureka的readwritemap map同步信息到readonlymap的间隔时间eureka.server.response-cache-update-interval-ms(30s)
Zuul作为Eureka客户端,每隔eureka.client.registry-fetch-interval-seconds(30)去从readonly map中去拉取服务列表
Ribbon更新其ServerList的时间间隔ribbon.ServerListRefreshInterva(30)
Pod在结束前主动向Eureka发起注销操作,则要保证在preStop hook中等待 30+30+30=90秒的时间,客户端才不会再使用此服务的endpoint建立新的请求连接,所以此时的terminationGracePeriodSeconds值应该设置为90。如果此连接是长连接,则还要加上在此连接中处理所有请求需要的时间作为最终的等待时间,比如5s,那在hoop中等待的时间应该是95s。
在内部服务之间使用Feign进行访问,Feign内部也依赖Ribbon进行负载均衡,所以整个实现方法和Zuul场景下并无不同。
在EKS环境中使用AppMesh/Istio Sidecar形式的微服务框架实现平滑升级
AppMesh是AWS推出的基于sidecar的微服务框架,基于每个集成到每个Pod的Sidecar,可以实现请求在多个版本的Pod之间分发,从而可以以蓝绿部署的方式实现Pod级的应用平滑升级。
AppMesh在标准的Kubernetes的Service和Pod基础之上,将一个Service抽象成如下架构。
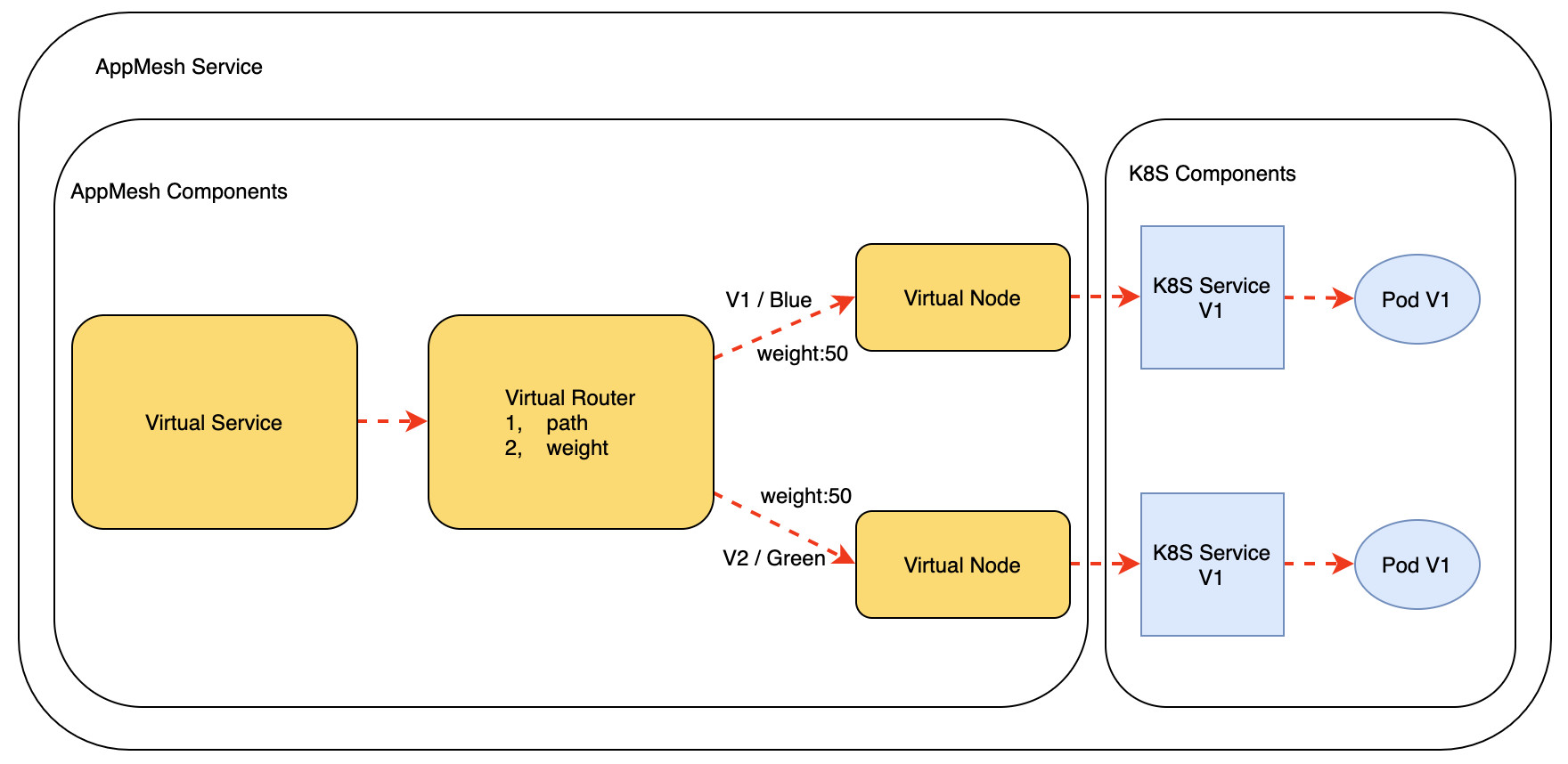
图三:AppMesh架构图
AppMesh中各组件定义如下:
| 组件 | 作用 |
| Virtual Service | 微服务组件的抽象实例,代表一种微服务实体,也是客户端的访问对象。 |
| Virtual Router | 在7层应用请求的情形下,Virtual Service内部使用,通过其内部的路由规则,路由请求到对应的后端服务。同时后端有多个实体提供相同服务的情况下,也通过Weight决定请求流向多个后端的配比,实际上启到负载均衡的作用,同时也可为不同版本的应用服务的蓝绿部署提供了基础。 |
| Virtual Node | 对应到后端不同的服务实体,是直接对Kubernets中Service和Pod的抽象。 |
| K8S Service & Pod | 原生的Kubernetes的Service和Pod对象。 |
由于Virtual Router里面在定义路由规则时,可以将请求分别定向到不同版本的后端,并且可以在不同后端之间通过调整Weight值进行按比例分配,所以就为应用提供了蓝绿部署的能力。通过蓝绿部署,应用可以以最小的代价实现平滑升级,不需要考虑Kubernes在停止Pod时的具体实现,也不需要考虑SpringCloud中服务向客户端注销的问题。
在AppMesh中升级后端应用时,只需要使用新的Deployment和Service创建新的后端,并建立新的Virtual Node,将在Virtual Rotuer中将部分流量分配到新的Virtual Node。在确认新版本应用组件工作正常后,在Virtual Router中只需要将旧版本应用组件对应的Virtual Node 的Weight设置为0,新版本应用组件对应的Virtual Node的Weight权重设置为100即可,这样可以满足条件1:新进入的请求不会到达旧版本的Pod,而是全部发送给新版本的Pod。那是否能满足条件2:旧版本的请求仍然发送到与旧版本建立的连接中呢??为了进一步说明AppMesh及Istio场景下,在进行蓝绿部署时,是否能保证旧版本的服务仍能提供连接供未完成的请求执行,特对Envoy的请求连接作进一步说明。以AWS的EKS Workshop中AppMesh集成实验为例:链接在此。(附:EKS Workshop中Istio实验参考,链接在此,仅作后续参考)
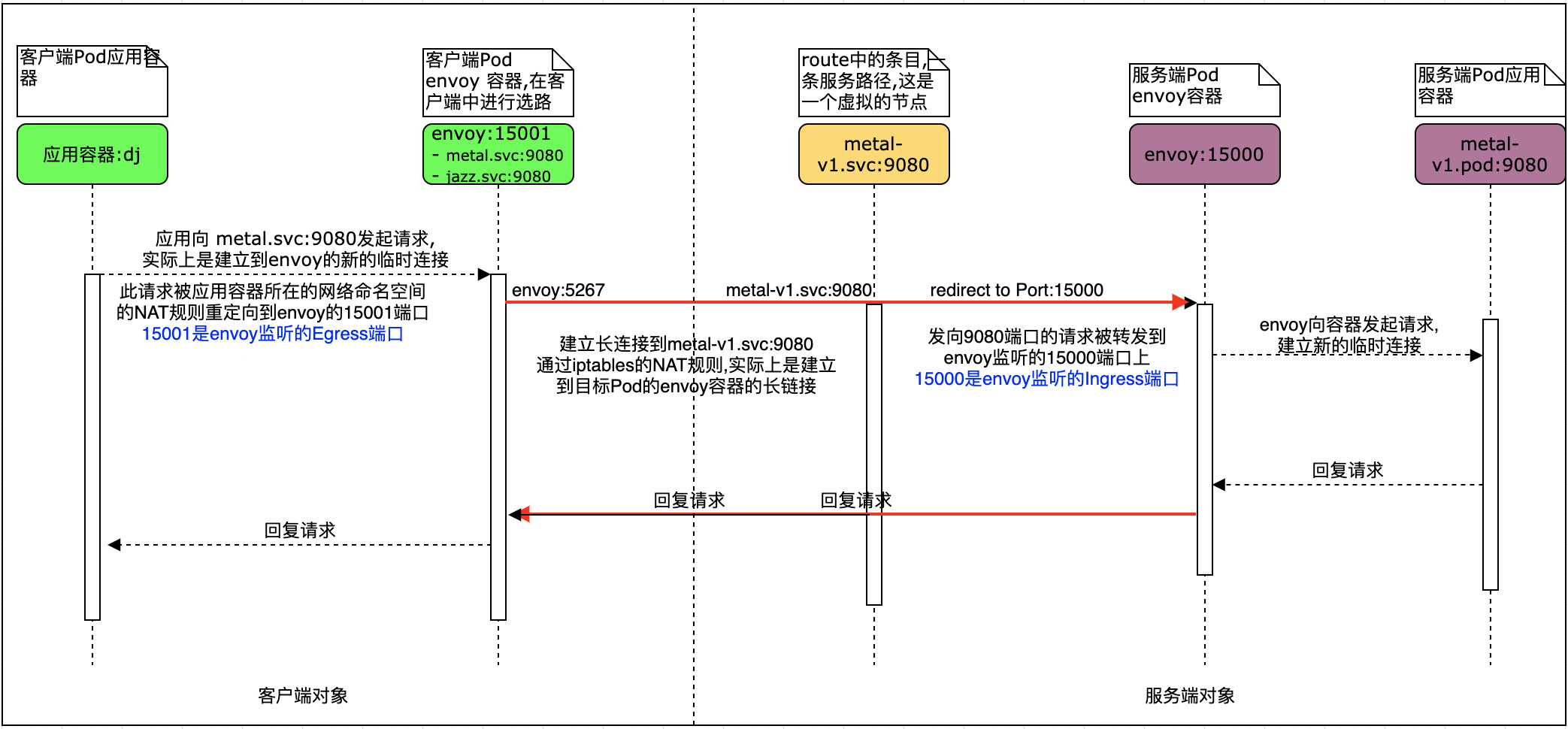
图四:AppMesh客户端与服务请求服务流程图
- 客户端中的envoy会和服务端中的每条路由条目的对象所属的envoy建立一个长链接。
- 客户端发起对服务端的访问时,实际上的新建一个向与自身同Pod的Envoy Proxy建立连接发起请求。
- Envoy Proxy通过长连接发送请求到服务端Pod的Envoy Proxy
- 服务端的Envoy Proxy再建立一个临时连接发送请求到同Pod的应用容器,从而完成整个请求链。
- 在设置到旧版本服务的Weight为0时,Envoy Proxy到服务端之间的长链接仍然保持,而且是永久保持,除非一端主动发起关闭。所以不转发新的请求到旧版本服务端,但仍然可以继续处理完未完成的旧请求。
综上虽然旧版本的Weight权限设置为0,但客户端和其建立的连接却会继续保持,所以可以平滑切换,不会造成业务中断。
针对Istio,里面同样有Virtual Service的抽象,且数据层面采用的是与AppMesh一致的Envoy Proxy,以Istio自然而然也支持通过蓝绿部署的方式实现平滑升级。
总结
通过在不同的使用模式下,有不同的方法来实现应用的平滑升级
- 纯Kubernetes模式下:可以实现滚动模式的平滑升级,需要借助Service的负载均衡能力,以及Pod的preStop能力,让Pod在退出前能继续处理未完成的请求,在preStop中的等待时间取决于客户端一次完整请求的持续时间。
- SpringCloud微服务框架下:此时Pod的preStop hook中,还需要执行向服务注册服务如Eureka注销自己,并等待客户端中Ribbon记录过期从而不同转发新请求到正在被停止的Pod,同样地,其等待时间还需要加上客户端一次完整请求的持续时间。所以preStop中hook的等待时间为客户端记录过期时间加上一次完整请求需要的处理时间。
- 在AppMesh及Istio微服务框架下:每个Pod的SideCar中包含了完整的Virtual Service及请求Weight分配能力实现蓝绿部署,所以可以做到对每个Pod的平滑升级,而且不需要针对Pod配置preStop,这种模式下实现应用服务的平滑升级最为方便。