原文链接:https://aws.amazon.com/cn/blogs/big-data/crafting-serverless-streaming-etl-jobs-with-aws-glue/
各行各业的组织已经构建了基于流的提取、转换与加载(ETL)应用程序,从而可以更高效地从其数据集中提取有意义的洞察。尽管流接收与流处理框架在过去几年中已经得到了迅猛发展,但市场对于构建全无服务器式流处理系统的需求仍在快速增长。自2017年以来,Amazon Glue已经简化了使用ETL来准备并加载数据,从而进行数据分析。
在本文中,我们将深入探讨Amazon Glue中的流式ETL,介绍此功能如何帮助您在流式数据上构建持续的ETL应用程序。Amazon Glue中的流式ETL基于Apache Spark的结构化流引擎,该引擎提供一种高容错、可扩展且易于实现的方法,能够实现端到端的流处理。本文向大家展示使用Amazon Glue构建流处理管道的示例,其中包括从 Amazon Kinesis Data Streams当中读取流式数据、发现schema、运行流式ETL并将结果写入至接收端。
无服务器流式ETL架构
在本文中,我们的案例和当前COVID-19疫情下的现实情况相关。全球各国对呼吸机的需求极为旺盛,并需要在各类环境中广泛应用,包括医院、疗养院甚至是私人住宅。呼吸机会生成大量必须被监控的数据,而呼吸机使用的增加也使得需要被处理的流式数据总量迅速膨胀,从而可以确保服务方在必要时尽快为患者提供服务。在本文中,我们将以呼吸机的数据指标为基础构建一个流式ETL作业,在详细数据的基础上丰富数据指标,如果指标超出正常范围时则提高警报级别。在通过这些数据指标丰富数据后,就可以使用它在监视器上显示可视化结果。
在我们的流式ETL架构中,将使用Python脚本生成示例呼吸机指标并将其以流的形式发布至Kinesis Data Streams当中。我们还将在Amazon Glue中创建一项流式ETL作业,该作业以微批次形式获取连续生成的呼吸机指标,对数据进行转换、聚合,并将结果传递至接收器,最终利用这部分结果显示可视化图表或在下游流程中继续使用。
由于企业经常使用流式数据扩展其在Amazon Simple Storage Service (Amazon S3)上构建的数据湖,因此我们的第一个用例首先对通过Kinesis Data Streams提取的JSON数据流进行转换,并将结果以Parquet格式加载至Amazon S3的数据湖内。在数据被提取到Amazon S3之后,您可以使用Amazon Athena查询数据,并使用Amazon QuickSight构建可视化的仪表板。
在第二个用例中,我们从Kinesis Data Streams提取数据,将其与Amazon DynamoDB中的引用数据相结合以计算警报级别,最后将计算结果写入Amazon DynamoDB中。这种方法使您可以构建起包含警报通知的近实时仪表板。
下图所示,为本用例的基本架构。

Amazon Glue流式ETL作业
借助Amazon Glue,您现在可以使用连续运行的作业在流式数据上创建ETL管道。您可以从Kinesis Data Streams以及Amazon Managed Streaming for Kafka(Amazon MSK)中摄取流式数据。Amazon Glue流式作业可以对各微批次中的数据执行聚合,再将处理后的数据交付至Amazon S3。您可以使用Amazon Glue DynamicFrame API从数据流中读取信息,并将结果写入Amazon S3。您还可以使用原生Apache Spark Structured Streaming API向任意接收器执行写入。
以下各节将向您介绍如何在Amazon Glue中构建流式ETL作业。
创建Kinesis数据流
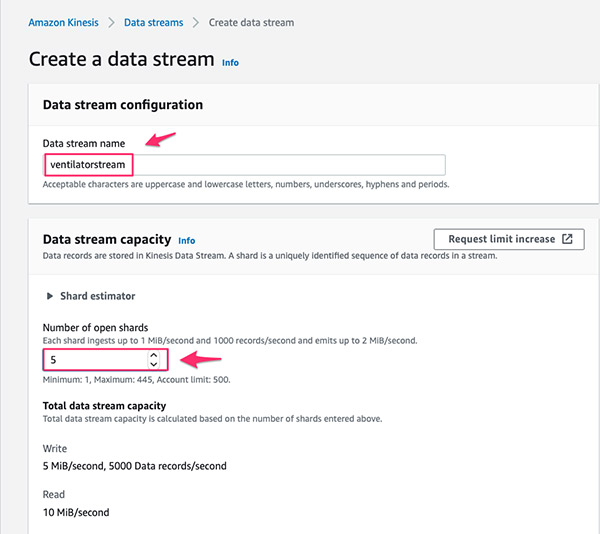
首先,我们需要一个流式摄取源,用于消费连续生成的流式数据。在本文中,我们创建一条具有五个分片的Kinesis数据流,该数据流可以每秒注入5000条记录。
- 在Amazon Kinesis 仪表板上,选择Data streams。
- 选择 Create data stream。

- 在Data stream name部分,输入
ventilatorsstream。
- 在Number of open shards(开启的分片数量)部分, 选择 5。

如果您希望使用Amazon Web Services命令行界面(AWS CLI),可以使用以下命令创建流:
aws kinesis create-stream \
--stream-name ventilatorstream \
--shard-count 5
生成流式数据
我们可以使用简单的Python应用程序(详见 GitHub repo)或Kinesis Data Generator (KDG)以JSON格式对呼吸机生成的数据进行聚合。
使用基于Python的数据生成器
要使用Python脚本生成流式数据,您可以在笔记本电脑或Amazon Elastic Compute Cloud (Amazon EC2)实例上运行以下命令。在运行脚本之前,请确保已在系统上安装有faker 库,并正确设置boto3凭证。
python3 generate_data.py --streamname glue_ventilator_stream
使用 Kinesis Data Generator
此外,您也可以将 Kinesis Data Generator与 GitHub repo上的呼吸机模板配合使用。如以下截屏所示,为KDG控制台上的模板。

在创建完成Amazon Glue流式作业之后,即可开始推送数据。
定义schema
我们需要为流式数据指定schema,具体操作方式有以下两种:
- 从流源处检索一小部分数据(在流作业开始之前),以批量方式推理schema,再将提取到的schema用于流式作业。
- 使用Amazon Glue数据目录手动创建一个表。
在本文中,我们使用Amazon Glue数据目录创建呼吸机schema。
- 在Amazon Glue控制台上, 选择 Data Catalog。
- 选择 Tables。
- 在Add Table下拉菜单中, 选择 Add table manually。
- 在表名称部分,输入
ventilators_table。
- 创建一个数据库,将其命名为
ventilatordb。
- 选择 Kinesis 作为源类型。
- 输入流名称与
https://kinesis.<aws-region>.amazonaws.com.
- 在分类部分, 选择 JSON。
- 根据下表定义schema。
| 列名称 |
数据类型 |
ventilatorid |
int |
eventtime |
string |
serialnumber |
string |
pressurecontrol |
int |
o2stats |
int |
minutevolume |
int |
manufacturer |
string |
10. 选择 Finish。
创建一项Amazon Glue流式作业以充实Amazon S3上的数据湖
在流数据源与schema准备完成之后,接下来即可创建Amazon Glue流式作业了。我们首先创建一项作业,使用Amazon Glue DataFrame API从流数据源中提取数据。
- 在 Amazon Glue控制台的ETL之下, 选择 Jobs。
- 选择 Add job。
- 在Name部分, 输入一条UTF-8字符串,长度不可超过255个字符。
- 在IAM role部分,指定一个角色以授权作业运行及存储数据访问所需的相应资源。由于流式作业需要同时接入数据源及接收器,因此您应确保AWS身份与访问管理(IAM)角色具备从Kinesis Data Stream读取、对Amazon S3进行写入,以及对Amazon DynamoDB进行读取/写入的相应权限。关于更多详细信息,请参阅管理AWS Glue资源的访问权限。
- 在Type部分, 选择 Spark Streaming。
- 在Glue Version部分, 选择 Spark 2.4, Python 3。
- 在This job runs部分,选择 A new script authored by you。
您可以让Amazon Glue为您生成流式ETL代码,但在本文中,我们选择从头开始自行编写。
8. 在Script file name部分,输入GlueStreaming-S3。
9. 在S3 path where script is stored部分,输入您的S3路径。

10. 在 Job bookmark部分, 选择 Disable。
在本文中,我们使用Amazon Glue提供的检查点机制(而非作业书签)跟踪读取到的数据。
11. 在Monitoring options部分,选择Job metrics与Continuous logging。
12. 在Log filtering部分,选择Standard filter与 Spark UI。
13. 在Amazon S3 prefix for Spark event logs部分,为事件日志输入相应的S3路径。

14. 在Job parameters部分,输入以下键-值:
-
- –output path – 保留最终聚合结果的S3路径
- –aws_region – 作业运行所在的区域

15. 跳过连接部分,选择 Save and edit the script。
将流式ETL指向 Amazon S3接收器
我们使用Amazon Glue DynamicFrameReader 类的from_catalog 方法读取流式数据。我们将与该数据流相关联的表指定为数据源(请参阅定义schema部分)。这里,我们还添加了additional_options以设定Kinesis Data Streams中的起始读取位置。使用TRIM_HORIZON 即可从分片中的最早记录开始读取。
# 从Kinesis Data Stream中读取数据
sourceData = glueContext.create_data_frame.from_catalog( \
database = "ventilatordb", \
table_name = "ventilatortable", \
transformation_ctx = "datasource0", \
additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "true"})
在以上代码中,sourceData 表示流式DataFrame。我们使用foreachBatch API调用一项函数(processBatch),用以处理此流式DataFrame表示的数据。而 processBatch 函数则接收一个静态DataFrame,其中包含窗口大小为100秒(默认)的流式数据。此函数根据静态DataFrame创建一个DynamicFrame,并将分区数据写出至Amazon S3。具体请参见以下代码:
glueContext.forEachBatch(frame = sourceData, batch_function = processBatch, options = {"windowSize": "100 seconds", "checkpoint_locationation": checkpoint_location})
要转换 DynamicFrame以修复事件时间的数据类型(从字符串转换为时间戳),并将呼吸机指标以Parquet格式写入至Amazon S3,请输入以下代码:
def processBatch(data_frame, batchId):
now = datetime.datetime.now()
year = now.year
month = now.month
day = now.day
hour = now.hour
minute = now.minute
if (data_frame.count() > 0):
dynamic_frame = DynamicFrame.fromDF(data_frame, glueContext, "from_data_frame")
apply_mapping = ApplyMapping.apply(frame = dynamic_frame, mappings = [ \
("ventilatorid", "long", "ventilatorid", "long"), \
("eventtime", "string", "eventtime", "timestamp"), \
("serialnumber", "string", "serialnumber", "string"), \
("pressurecontrol", "long", "pressurecontrol", "long"), \
("o2stats", "long", "o2stats", "long"), \
("minutevolume", "long", "minutevolume", "long"), \
("manufacturer", "string", "manufacturer", "string")],\
transformation_ctx = "apply_mapping")
dynamic_frame.printSchema()
# 写入至S3接收器
s3path = s3_target + "/ingest_year=" + "{:0>4}".format(str(year)) + "/ingest_month=" + "{:0>2}".format(str(month)) + "/ingest_day=" + "{:0>2}".format(str(day)) + "/ingest_hour=" + "{:0>2}".format(str(hour)) + "/"
s3sink = glueContext.write_dynamic_frame.from_options(frame = apply_mapping, connection_type = "s3", connection_options = {"path": s3path}, format = "parquet", transformation_ctx = "s3sink")
进行聚合
在Glue ETL代码编辑器中,输入以下代码,而后保存并运行此作业:
import sys
import datetime
import boto3
import base64
from pyspark.sql import DataFrame, Row
from pyspark.context import SparkContext
from pyspark.sql.types import *
from pyspark.sql.functions import *
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue import DynamicFrame
args = getResolvedOptions(sys.argv, \
['JOB_NAME', \
'aws_region', \
'output_path'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# S3接收器位置
aws_region = args['aws_region']
output_path = args['output_path']
s3_target = output_path + "ventilator_metrics"
checkpoint_location = output_path + "cp/"
temp_path = output_path + "temp/"
def processBatch(data_frame, batchId):
now = datetime.datetime.now()
year = now.year
month = now.month
day = now.day
hour = now.hour
minute = now.minute
if (data_frame.count() > 0):
dynamic_frame = DynamicFrame.fromDF(data_frame, glueContext, "from_data_frame")
apply_mapping = ApplyMapping.apply(frame = dynamic_frame, mappings = [ \
("ventilatorid", "long", "ventilatorid", "long"), \
("eventtime", "string", "eventtime", "timestamp"), \
("serialnumber", "string", "serialnumber", "string"), \
("pressurecontrol", "long", "pressurecontrol", "long"), \
("o2stats", "long", "o2stats", "long"), \
("minutevolume", "long", "minutevolume", "long"), \
("manufacturer", "string", "manufacturer", "string")],\
transformation_ctx = "apply_mapping")
dynamic_frame.printSchema()
# 写入至S3接收器
s3path = s3_target + "/ingest_year=" + "{:0>4}".format(str(year)) + "/ingest_month=" + "{:0>2}".format(str(month)) + "/ingest_day=" + "{:0>2}".format(str(day)) + "/ingest_hour=" + "{:0>2}".format(str(hour)) + "/"
s3sink = glueContext.write_dynamic_frame.from_options(frame = apply_mapping, connection_type = "s3", connection_options = {"path": s3path}, format = "parquet", transformation_ctx = "s3sink")
# 从Kinesis Data Stream处读取
sourceData = glueContext.create_data_frame.from_catalog( \
database = "ventilatordb", \
table_name = "ventilatortable", \
transformation_ctx = "datasource0", \
additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "true"})
sourceData.printSchema()
glueContext.forEachBatch(frame = sourceData, batch_function = processBatch, options = {"windowSize": "100 seconds", "checkpoint_locationation": checkpoint_location})
job.commit()
使用Athena执行查询
将处理后的流式数据以Parquet格式写入至Amazon S3之后,我们即可在Athena上运行查询。在写入流式数据的Amazon S3位置上运行Amazon Glue爬取器,以下截屏所示为我们的查询结果。

关于在Amazon S3中使用流式数据构建可视化仪表板的具体说明,请参阅快速入门:使用示例数据通过单一视图创建分析。以下仪表板每小时根据异常情况显示一次指标、平均值与警报的分布结果,您也可以按照需求创建间隔更短(分钟)的高级仪表板。

将流式ETL指向DynamoDB接收器
在第二个用例中,我们将在流式数据到达时对其进行转换,而不再进行微分批处理,而后将数据持久化至DynamoDB表当中。用于创建DynamoDB表的脚本请参见GitHub repo。我们使用Apache Spark的Structured Streaming API从数据流中读取呼吸机生成的数据,将其与DynamoDB表中关于常规指标范围的参考数据相结合,并根据与常规指标值的偏差计算出状态,最终将处理后的数据写入至DynamoDB表。具体请参见以下代码:
import sys
import datetime
import base64
import decimal
import boto3
from pyspark.sql import DataFrame, Row
from pyspark.context import SparkContext
from pyspark.sql.types import *
from pyspark.sql.functions import *
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue import DynamicFrame
args = getResolvedOptions(sys.argv, \
['JOB_NAME', \
'aws_region', \
'checkpoint_location', \
'dynamodb_sink_table', \
'dynamodb_static_table'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 读取参数
checkpoint_location = args['checkpoint_location']
aws_region = args['aws_region']
# DynamoDB config
dynamodb_sink_table = args['dynamodb_sink_table']
dynamodb_static_table = args['dynamodb_static_table']
def write_to_dynamodb(row):
'''
Add row to DynamoDB.
'''
dynamodb = boto3.resource('dynamodb', region_name=aws_region)
start = str(row['window'].start)
end = str(row['window'].end)
dynamodb.Table(dynamodb_sink_table).put_item(
Item = { 'ventilatorid': row['ventilatorid'], \
'status': str(row['status']), \
'start': start, \
'end': end, \
'avg_o2stats': decimal.Decimal(str(row['avg_o2stats'])), \
'avg_pressurecontrol': decimal.Decimal(str(row['avg_pressurecontrol'])), \
'avg_minutevolume': decimal.Decimal(str(row['avg_minutevolume']))})
dynamodb_dynamic_frame = glueContext.create_dynamic_frame.from_options( \
"dynamodb", \
connection_options={
"dynamodb.input.tableName": dynamodb_static_table,
"dynamodb.throughput.read.percent": "1.5"
}
)
dynamodb_lookup_df = dynamodb_dynamic_frame.toDF().cache()
# 从Kinesis Data Stream处读取
streaming_data = spark.readStream \
.format("kinesis") \
.option("streamName","glue_ventilator_stream") \
.option("endpointUrl", "https://kinesis.us-east-1.amazonaws.com") \
.option("startingPosition", "TRIM_HORIZON") \
.load()
# 检索Sensor列并进行简单投射
ventilator_fields = streaming_data \
.select(from_json(col("data") \
.cast("string"),glueContext.get_catalog_schema_as_spark_schema("ventilatordb","ventilators_table")) \
.alias("ventilatordata")) \
.select("ventilatordata.*") \
.withColumn("event_time", to_timestamp(col('eventtime'), "yyyy-MM-dd HH:mm:ss")) \
.withColumn("ts", to_timestamp(current_timestamp(), "yyyy-MM-dd HH:mm:ss"))
# 流静态join,使用ETL以增加状态
ventilator_joined_df = ventilator_fields.join(dynamodb_lookup_df, "ventilatorid") \
.withColumn('status', when( \
((ventilator_fields.o2stats < dynamodb_lookup_df.o2_stats_min) | \
(ventilator_fields.o2stats > dynamodb_lookup_df.o2_stats_max)) & \
((ventilator_fields.pressurecontrol < dynamodb_lookup_df.pressure_control_min) | \
(ventilator_fields.pressurecontrol > dynamodb_lookup_df.pressure_control_max)) & \
((ventilator_fields.minutevolume < dynamodb_lookup_df.minute_volume_min) | \
(ventilator_fields.minutevolume > dynamodb_lookup_df.minute_volume_max)), "RED") \
.when( \
((ventilator_fields.o2stats >= dynamodb_lookup_df.o2_stats_min) |
(ventilator_fields.o2stats <= dynamodb_lookup_df.o2_stats_max)) & \
((ventilator_fields.pressurecontrol >= dynamodb_lookup_df.pressure_control_min) | \
(ventilator_fields.pressurecontrol <= dynamodb_lookup_df.pressure_control_max)) & \
((ventilator_fields.minutevolume >= dynamodb_lookup_df.minute_volume_min) | \
(ventilator_fields.minutevolume <= dynamodb_lookup_df.minute_volume_max)), "GREEN") \
.otherwise("ORANGE"))
ventilator_joined_df.printSchema()
# 丢弃正常指标值
ventilator_transformed_df = ventilator_joined_df \
.drop('eventtime', 'o2_stats_min', 'o2_stats_max', \
'pressure_control_min', 'pressure_control_max', \
'minute_volume_min', 'minute_volume_max')
ventilator_transformed_df.printSchema()
ventilators_df = ventilator_transformed_df \
.groupBy(window(col('ts'), '10 minute', '5 minute'), \
ventilator_transformed_df.status, ventilator_transformed_df.ventilatorid) \
.agg( \
avg(col('o2stats')).alias('avg_o2stats'), \
avg(col('pressurecontrol')).alias('avg_pressurecontrol'), \
avg(col('minutevolume')).alias('avg_minutevolume') \
)
ventilators_df.printSchema()
# 写入至DynamoDB接收器
ventilator_query = ventilators_df \
.writeStream \
.foreach(write_to_dynamodb) \
.outputMode("update") \
.option("checkpointLocation", checkpoint_location) \
.start()
ventilator_query.awaitTermination()
job.commit()
在上述代码运行完成之后,呼吸机指标聚合结果将持久保存在Amazon DynamoDB表中。您可以使用Amazon DynamoDB中的数据构建自定义用户界面应用,借此创建仪表板。

总结
流式应用程序已经成为数据湖架构中的核心组件。借助AWS Glue流,您可以创建连续运行的无服务器ETL作业,处理来自Kinesis Data Streams与Amazon MSK等流式服务的数据。您也可以使用Structured Streaming API将流处理结果加载至基于Amazon S3的数据湖、JDBC数据存储或者任意其他接收器当中。
关于Amazon Glue流式ETL作业的更多详细信息,请参阅:
我们建议大家使用Amazon Glue流式ETL构建无服务器流式应用程序,并与我们分享您的经验心得。如果您有任何问题或建议,请在评论区中与我们讨论。
本篇作者