亚马逊AWS官方博客
使用 Kiro 规范驱动开发加速数据质量建设
业务背景
无论是传统行业企业的数据运营分析,互联网企业的数据行为分析,再到 AI 时代的领域数据上下文知识传递,精确的参数知识微调,数据质量一直都是极为重要的一环。在与企业客户的交流中逐渐发现,数据质量已从“技术小问题”升级为业务危机。近年来,即便企业在大数据和工具上投入巨大,脏数据、重复数据和过期数据仍广泛存在,直接威胁到 AI 项目、客户运营和报表的可靠性。
数据管道的质量受数据本身、基础设施、生命周期管理、开发部署和处理流程等多维因素影响,其中错误数据类型、清洗阶段问题和兼容性问题尤为常见,导致管道不稳定、数据不可用。数据从需求到落地阶段的语义表达不一致,实际数据管道中的重复和不一致记录、缺乏前瞻性的清洗与治理、依赖人工排查、以及在合规和监管报送上因格式不一致而出错,这些问题同时带来时间浪费和修复成本增加。糟糕的数据质量会显著拉低生产力、增加成本、拖慢决策与创新节奏;越来越多企业开始建立数据质量指标,但度量和落地仍不统一,需要更系统化的治理与持续监测方案。从业务方视角,需求已经从“偶尔清洗一次”转向“可观测、可度量、可追责”的持续数据质量管理:包括自动监控关键表、快速定位问题源头、量化质量分数,以及与数据产品和 AI 应用的 SLA 挂钩。
技术背景
数据质量的管理,与传统软件开发的需求-设计-实施 -监控的逻辑一致,规范驱动开发与数据质量设计高度契合。在数据需求产生阶段即需要对质量有一定的认知从而在后续流程中形成系统性的监控。
回顾软件开发的历史,1992 年,Bertrand Meyer 在 IEEE Computer 上发表《Applying “Design by Contract”》,系统提出“设计合约”思想,用前置条件、后置条件和不变量来精确定义软件组件的行为,被视为规范驱动开发在面向对象范式中的起点之一。1980–2000 年代,Clarke、Emerson、Sifakis 等人发展并推广模型检查,将系统行为用 Kripke 结构和时序逻辑形式化建模,并用自动算法验证实现是否满足给定规格,其工作在 2007 年获得 ACM 图灵奖。2010 年代,随着 REST API 和微服务兴起,OpenAPI 等规范成为事实标准,推动“spec-first API development”。将 API 规范作为单一事实源,通过工具生成服务器代码、客户端 SDK、文档和契约测试,并在 CI/CD 中校验规范变更的兼容性,形成“规范 → 实现/测试 → 网关策略”的工程闭环。 2020–2023 年,随着大模型和代码生成工具出现,AI 开始参与编码与测试生成,但“纯提示驱动(prompt-based)”开发暴露出难以复现、行为飘移和缺乏治理的痛点。2024–2025 年,业界开始明确提出“spec-driven development with AI”的模式,将大模型从“自由写代码”转向“在规范约束下生成实现和测试”。与此同时,关于数据管道质量和数据质量管理的研究指出:要保证复杂数据系统可控,需要明确定义可检查的数据契约和不变量,使质量规则能够被自动执行和回归验证。
Amazon Kiro 是一款面向“规范驱动开发”的 agentic AI IDE:它把多轮对话和零散需求收敛成结构化规范(如 requirements、design、tasks 等文档),然后由多个 AI 代理在这些规范约束下规划、编写和重构代码,让“写代码”变成“围绕规范运营的软件生产线,而非随意聊天写脚本”。 通过 Steering 文件和 MCP 集成把团队规范、外部 API、数据库和项目系统统一接入同一工作空间,以实现从单人原型到多人协作的一致开发体验。在此基础上,2025 亚马逊云科技 re:Invent 发布的 property-based testing 能力进一步把“规范”变成可执行的正确性度量,Kiro 会从规范中自动提取“对任意输入都应成立的性质”,生成大规模随机测试用例来验证代码是否始终满足这些属性,从而不再只依赖少量示例用例。
本文将围绕规范驱动开发理念,在典型数仓场景下,利用 Kiro AI IDE 使用 Redshift MCP 进行数据采样及血缘探索,自动生成Amazon Glue Data Quality 规则及脚本,并且通过 Glue MCP 部署质量任务,生成质量报告,旨在帮助数据工程团队快速落地质量管理。
方案架构
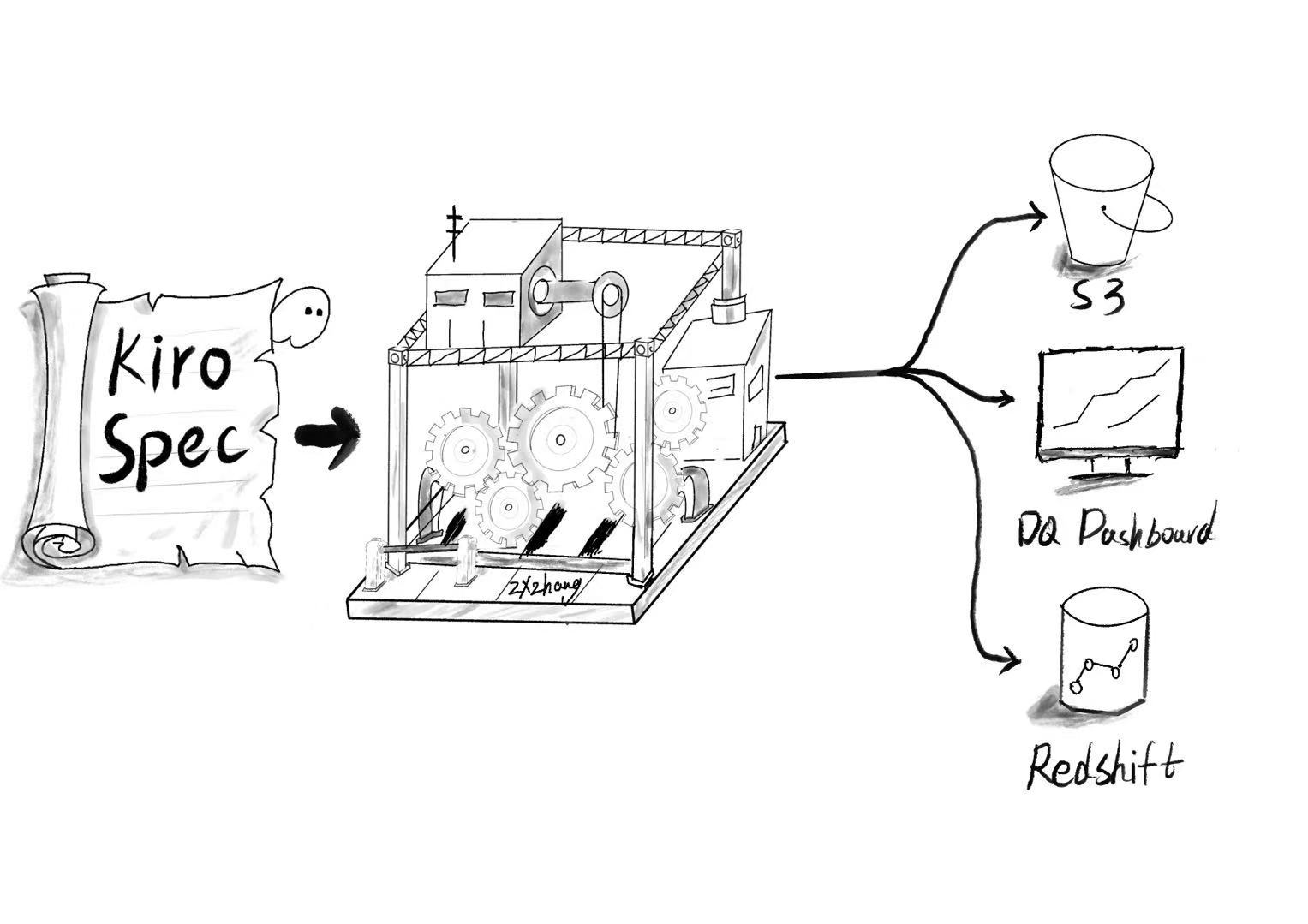 |
- 使用 Kiro 的 Spec-Driven 开发,编写 spec 说明文档;
- 添加必要前置信息,如 Redshift 集群及表范围、Glue connection 等,Kiro 首先通过 Redshift MCP 自动探索表格式及通过物化试图DDL 推断表逻辑,自动生成 Glue Data Quality 规则;
- Kiro 将自动生成设计及任务清单文档,并自我检查每个任务输出内容,也可经过人为验证后执行任务;
- Kiro 通过 Glue MCP生成 data quality 任务作业,运行后获得Json 格式的质量报告存储到 S3 存储,通过集成报表持续监控数据质量。
实践过程
- 前置条件
以典型的建立在Redshift的数仓为例,有 ODS、DWD、ADS三层数仓模型,并且通过物化试图实现分层逻辑。数据源是来自于 RDS Mysql 。Redshift 与 RDS 都分别在 Glue 创建了 Connections。
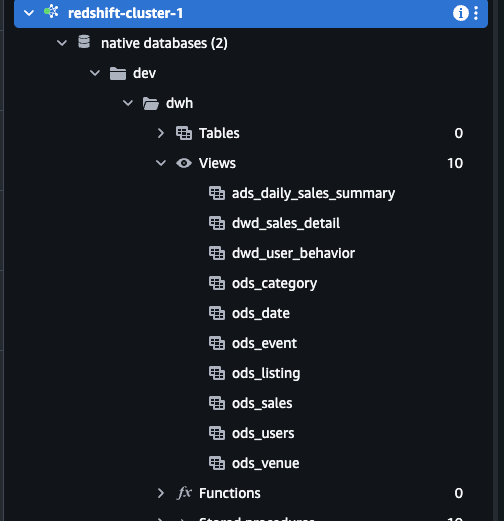 |
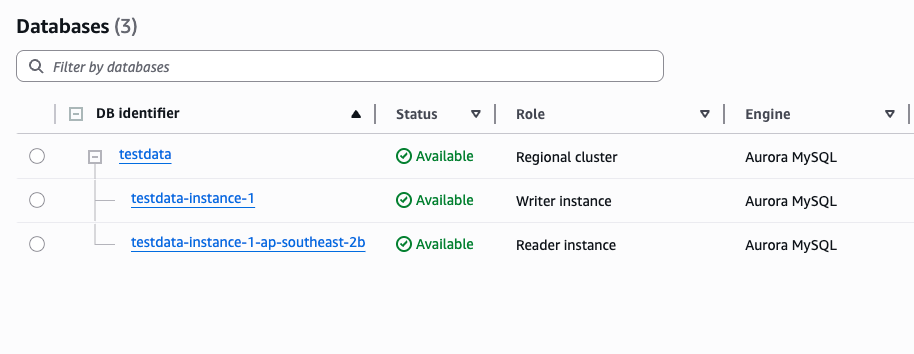 |
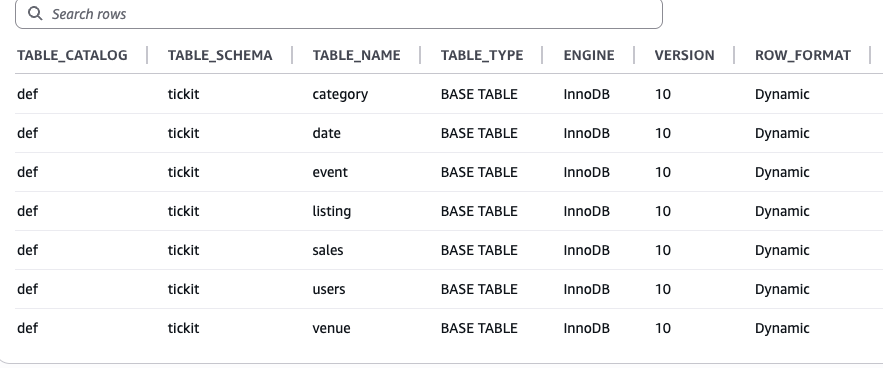 |
 |
- Kiro 工程介绍(参考工程见 Github)
 |
.kiro/、settings/、mcp.json等,是 Kiro 在项目里的配置与 MCP 集成入口,本项目已经把 Redshift、Glue 等外部系统通过 MCP 暴露给 IDE 使用。
specs/redshift-data-quality/目录下有design.md、requirements.md、tasks.md等,典型的 Kiro spec-driven 结构:需求、设计、任务按文档拆开管理。sample-job/中的 Python 脚本,如rds-redshift-row-count-diff.py、redshift-table-base-check.py,是根据这些 spec 生成或演进的 Glue/Redshift 作业样例。
- 示例配置文件及需求说明
配置文件:
需求清单
- DQ Job Generator:为数据质量校验生成可执行 Glue Spark 作业的系统。
- DQDL:由 AWS Glue Data Quality 的 EvaluateDataQuality 变换使用的数据质量定义语言。
- EvaluateDataQuality:在 DataFrame 上应用 DQDL 规则的 AWS Glue 变换。
- Single-Table Check:对单个表字段进行的数据质量校验(完整性、唯一性、取值范围等)。
- Cross-Table Reconciliation:对关联表之间的一致性进行校验(行数、聚合值等)。
- Cross-Source Comparison:对 RDS 源表与 Redshift ODS 表之间的数据同步情况进行校验。
- Materialized View:在 Redshift 中存储查询结果并用于定义数据血缘的物化视图。
- Data Layer:数据仓库中的分层结构(ODS/DWD/DWS/ADS 等)。
- MCP Tool:用于与 AWS 服务交互的 Model Context Protocol 工具。
- Configuration File:由用户提供的、用于描述数仓结构的 markdown 配置文件。
- 示例设计文档解析
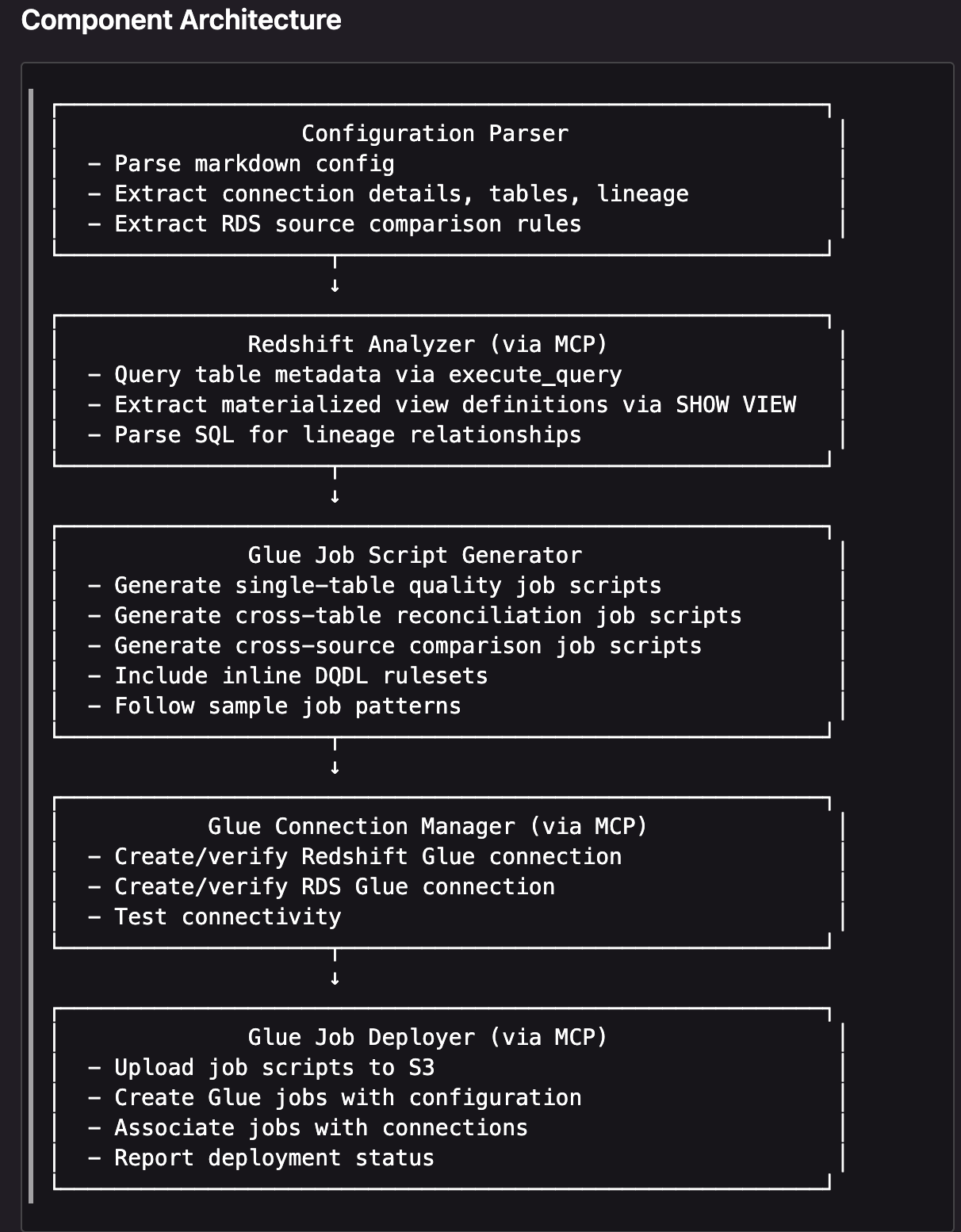 |
- Configuration Parser(配置解析器)
- 解析用户提供的 markdown 配置文件。
- 从中抽取连接信息(Redshift / RDS 等)、需要校验的表及血缘关系。
- 解析 RDS 源与 Redshift 之间的对账/比对规则,为后续跨源核对做输入。
- Redshift Analyzer(Redshift 分析器,经 MCP 调用)
- 通过 MCP 工具调用 Redshift,使用
execute_query查询系统表或视图,获取目标表的元数据(列名、类型、分布键、分区等)。 - 通过
SHOW VIEW等命令抽取物化视图的 DDL,用来理解每张 ODS/DWD 表背后的计算逻辑和数据血缘。 - 解析这些 SQL,构建表之间的血缘关系,为单表校验、跨表对账和跨源对比提供上下游信息。
- 通过 MCP 工具调用 Redshift,使用
- Glue Job Script Generator(Glue 作业脚本生成器)
-
- 根据上一步得到的表结构和血缘信息,生成单表数据质量检查作业脚本(完整性、唯一性、范围等)。
- 生成跨表对账脚本(如事实表与汇总表的行数或聚合值比对)。
- 生成跨源对比脚本(RDS 源表与 Redshift ODS 表的同步一致性检查)。
- 在脚本中内联 DQDL 规则集( Glue Data Quality 的规则定义),并尽量沿用既有的 sample job 模式,便于复用和维护。
- Glue Connection Manager(Glue 连接管理器,经 MCP 调用)
-
- 创建或校验到 Redshift 的 Glue connection,确保 Glue 作业可以访问 Redshift。
- 创建或校验到 RDS 的 Glue connection,用于跨源比较时访问源库。
- 对这些连接执行连通性测试,提前发现权限或网络问题,而不是等作业运行时才失败。
- Glue Job Deployer(Glue 作业部署器,经 MCP 调用)
-
- 将生成好的作业脚本上传到 S3,作为 Glue 作业的代码位置。
- 基于配置创建 Glue 作业(包括 IAM 角色、超时时间、资源配置、参数等)。
- 将作业与前面创建好的 Glue connections 关联起来,保证运行环境就绪。
- 上报部署状态(成功/失败、作业名称、版本等),为后续编排和监控提供依据。
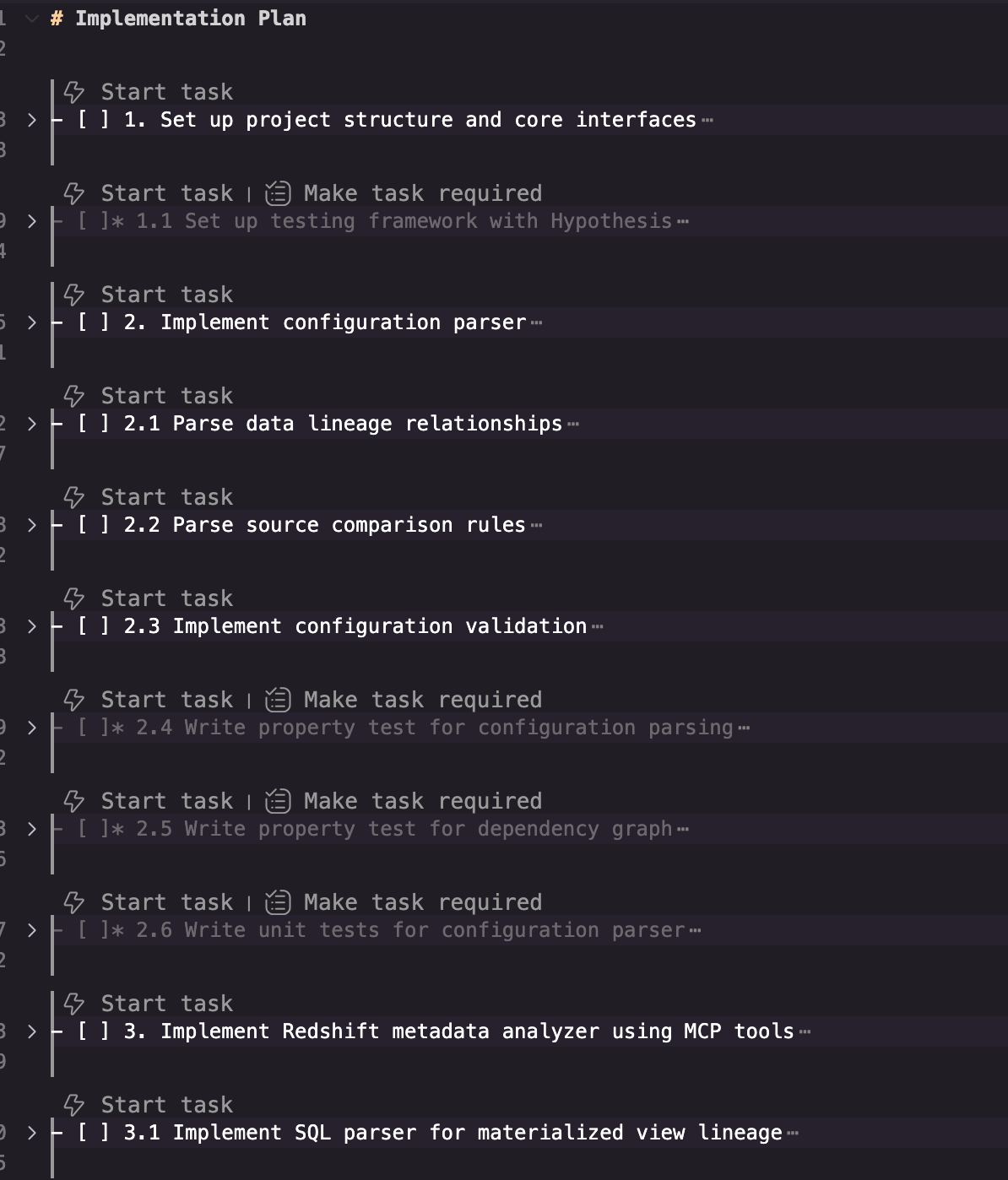
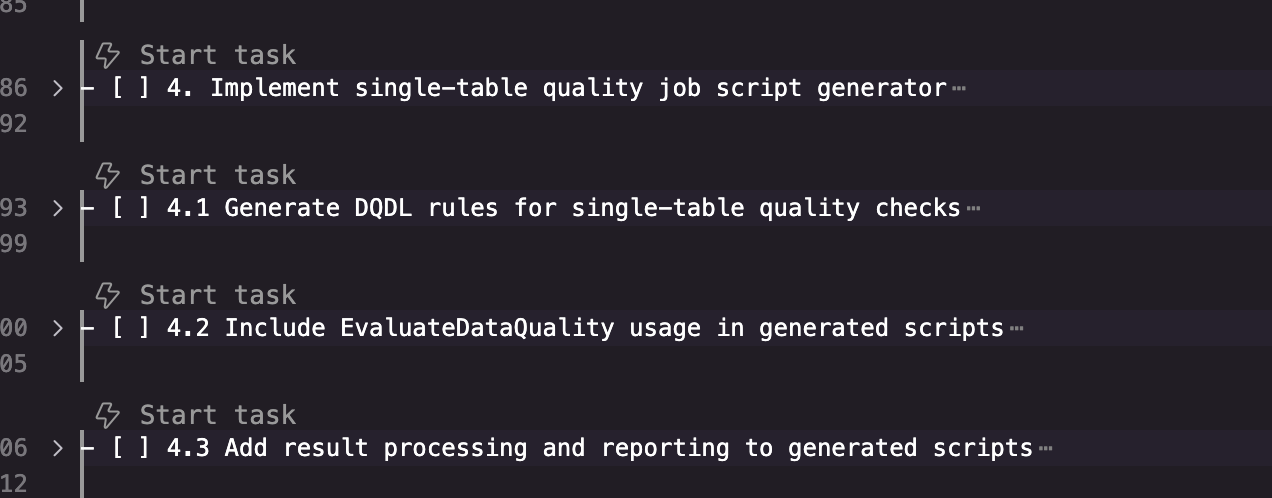
- 示例任务清单示例
 |
 |
 |
- Glue data quality 任务解析
部分生成规则说明
总结与展望
通过使用 Kiro 的 Spec-Driven 开发,将需求、设计和任务固化为结构化的 spec 文档,再结合 Redshift 与 Glue Data Quality 的能力,把数据质量规则从“零散脚本”升级为“可维护的规格资产和自动化流水线”。这种方式一方面利用 Kiro 的上下文管理能力,根据 Redshift 集群信息、表范围、Glue 连接等前置信息自动探索表结构和物化视图 DDL,从而半自动生成 Glue Data Quality 规则;另一方面则通过设计文档与任务清单让人类在关键节点参与审查,形成 AI 与工程团队协作的闭环。结合 Glue 作业执行与质量报告集成报表,可以将数据质量监控从“事后排查”转向“持续观测与预警”,为数据产品和下游 AI 应用提供更稳定的基础。后续将业务规则和指标血缘显式写入 spec,让 Kiro 在生成规则时能覆盖跨表关系和关键 KPI 的不变量,而不仅限于单表校验;引入property-based testing 的思路,对生成的规则和脚本自动构造大量测试场景,验证“在各种数据分布下规则仍然合理”,减少调试时间与误报率。
生成实践建议,从小范围试点开始:选 1–2 个关键业务域(如订单、支付或核心用户行为),约束在有限的 Redshift schema 和 Glue connection 范围内实践 spec-driven 规则生成和执行,把流程打通后再扩展到更多表和域。规格模板标准化:为数据质量场景设计统一的 spec 模板(域/表/字段、质量维度、阈值策略、预期分布、上游下游关系),在 Kiro 中复用模板,避免每次从零开始描述需求。引入多层校验与快照:对 Kiro 生成的规则和脚本,建立“快照对比 + 小样本回归 + 影子运行”的三层校验,将大部分问题拦在开发和预发布阶段,而不是上线后靠人工排错。把运行数据反哺规格:定期分析 Glue Data Quality 报告中的异常模式、误报情况和长期无异常的规则,将这些信息回写到 spec 和生成器配置中,例如调整阈值、补充前置条件、废弃低价值规则,让规格和生成逻辑随业务与数据分布演进,而不是“一次性写完不再更新”。工具链与团队配合:在团队层面明确“规格是单一事实源”的共识,把 spec 文档纳入代码评审和发布流程,要求新增或修改规则必须先改 spec 再生成实现,同时为数据工程师提供 Kiro 与 Glue 的操作指南和最佳实践示例,降低技术负担和使用门槛。
推荐阅读
Kiro and the future of AI spec-driven software development
Spec-driven development with AI: Get started with a new open source toolkit
Stop Chatting, Start Specifying: Spec-Driven Design with Kiro IDE
Bertrand Meyer, “Applying ‘Design by Contract’”, IEEE Computer, 1992
Amazon Glue Data Quality Best Practices
Why Spec-Driven Development Will Define the Next Generation of Elite Engineers
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
