亚马逊AWS官方博客
AI Agent 的迁移与现代化 — 使用 Amazon Bedrock AgentCore 将 OpenClaw 从单机改造为多租户 Serverless 架构 第一篇
摘要:基于 AWS 示例项目,展示如何将 OpenClaw 迁移为基于 Amazon Bedrock AgentCore 的多租户 Serverless 架构。全系列 6 篇,涵盖 Replatform 与 Refactor 两种策略。本篇为第一篇:为什么要把 OpenClaw 从单机搬到 AWS,介绍背景动机、7R 迁移策略分析、数据迁移方案,以及部署架构全景。
目录
一、背景与动机:将 AI Agent 扩展到多用户场景
OpenClaw 是一个开源的个人 AI Agent 框架,由奥地利开发者 Peter Steinberger 于 2025 年 11 月创建。它以 Node.js 单进程运行,通过 Gateway(网关)连接 Telegram、Slack、飞书等即时通讯渠道,让用户在聊天窗口里直接操作文件、执行命令、浏览网页、管理日程。截至 2026 年 4 月,OpenClaw 在 GitHub 上已获得超过 36 万颗星,是近期增长较快的开源 AI 项目之一。
OpenClaw 的默认部署方式很直接:在一台服务器上 npm install -g openclaw,然后 openclaw onboard --install-daemon,单进程启动,监听 127.0.0.1:18789。这种方式对个人用户来说足够了 — 一台 Mac Mini 或一台 VPS 就能跑起来。当企业或团队想把它提供给多个用户使用时,就需要考虑以下几个方面:
| 需要考虑的方面 | 具体情况 |
|---|---|
| 用户隔离 | 默认部署下,所有用户共享一个 Node.js 进程和同一个文件系统。OpenClaw 的 ~/.openclaw/ 目录存储了配置、会话、凭证等所有状态,多用户场景下需要额外的隔离机制 |
| 弹性扩缩 | 单进程架构下,一台机器的 CPU 和内存就是上限。用户增长时需要手动扩容和配置负载均衡 |
| 数据持久化 | OpenClaw 的工作区(MEMORY.md、USER.md、技能配置、对话历史)存在本地磁盘。服务器维护或迁移时,需要手动打包 ~/.openclaw/ 目录做备份和恢复 |
| 安全防护 | 内容审核、PII(个人身份信息)检测、提示注入防护等能力需要在应用层自行实现。密钥管理依赖本地文件(auth-profiles.json、credentials/) |
| 运维可观测性 | 默认部署下的运维主要依赖本地日志文件,Token 用量统计、成本追踪、告警等能力需要额外搭建 |
这些需求并非 OpenClaw 独有 — 几乎所有从”个人工具”走向”团队/企业服务”的开源项目都会面临类似的多租户扩展需求。AWS 官方示例项目 sample-host-openclaw-on-amazon-bedrock-agentcore 提供了一种参考方案:利用 Amazon Bedrock AgentCore Runtime 的 Per-Session microVM(按会话分配的微型虚拟机)隔离能力,配合 AWS CDK 编排的基础设施,将 OpenClaw 从”单机单用户”扩展为”AWS 托管多用户”架构。
本文将以动手实操的形式,带你完整走一遍这个迁移和现代化改造的过程。在动手之前,我们先从 AWS Migration & Modernization(迁移与现代化)的视角分析一下这次改造的策略选择。
二、迁移策略分析:这属于 7R 中的哪一种?
AWS 在 Prescriptive Guidance 中定义了 7 种云迁移策略,通常称为 7R。下图按改造程度从低到高排列,并标注了本项目所采用的两种策略:

[图1] |
对于 OpenClaw 这个项目,改造涉及的策略主要是 Replatform 和 Refactor(图中高亮),两者交织在不同的改造维度上。
按照 AWS Prescriptive Guidance 的定义,Replatform 也称为”lift, tinker, and shift”(迁移并微调),即将应用迁移到云上并引入一定程度的优化以利用云能力,但不改变应用的核心架构;Refactor 也称为”re-architect”(重新架构),即充分利用云原生特性重新设计应用架构,以提升敏捷性、性能和可扩展性。下表对照了 OpenClaw 在迁移前后的变化,以及每个维度对应的策略:
| 改造维度 | 迁移前(传统 OpenClaw) | 迁移后(本项目) | 对应策略 |
|---|---|---|---|
| 运行环境 | 一台 VPS / EC2,手动管理进程 | AgentCore Runtime,Serverless 托管,按需启停 microVM | Replatform |
| 用户隔离 | 所有用户共享一个 Node.js 进程 | 每用户独立 microVM(微型虚拟机)+ AWS STS scoped credentials(限制版临时凭证)实现数据和权限隔离 | Refactor |
| 模型调用 | 直接调用 OpenAI / Anthropic API | 通过容器内 Bedrock Proxy 转为 Amazon Bedrock ConverseStream API 调用 | Replatform |
| 数据持久化 | 本地磁盘 ~/.openclaw/ 目录(MEMORY.md、USER.md、会话历史、技能配置) |
Amazon S3 + Workspace Sync(microVM 临时存储,数据持久化到 S3,按用户 ID 前缀隔离) | Refactor |
| 消息接入 | OpenClaw 自带的 Gateway 直接监听 | Amazon API Gateway + AWS Lambda Router 处理 webhook(回调通知),支持多渠道签名验证 | Refactor |
| 安全体系 | 靠应用代码和本地文件(auth-profiles.json) |
Amazon VPC 网络隔离 + AWS KMS 加密 + Amazon Bedrock Guardrails 内容审核 + AWS STS Per-User 权限隔离 | Replatform |
| 监控运维 | 看本地日志文件 | Amazon CloudWatch Dashboard + Alarm + Token 用量统计 + AWS X-Ray 分布式追踪 | Replatform |
| 扩缩容 | 手动加机器 | AgentCore Runtime 按会话自动扩缩,空闲超时自动销毁 | Replatform |
可以看到,Replatform 主要体现在”把原有能力平移到 AWS 托管服务上”(运行环境、模型调用、安全、监控、扩缩容),而 Refactor 主要体现在”为多租户场景重新设计架构”(用户隔离、数据持久化、消息接入)。这种 Replatform + Refactor 的混合策略在实际迁移中很常见 — 不是所有维度都需要重构,能用托管服务直接替换的就直接替换,只在必须改架构的地方做重构。
2.1 数据迁移:从本地 ~/.openclaw/ 到 S3
对于已经在使用 OpenClaw 的用户,迁移到本项目时还涉及一个实际问题:已有的工作区数据怎么办?
OpenClaw 的所有用户状态都存储在 ~/.openclaw/ 目录下,包括:
| 文件 / 目录 | 内容 | 迁移后存储位置 |
|---|---|---|
openclaw.json |
Gateway 配置 | 容器镜像内置配置(由 CDK 管理) |
MEMORY.md |
Agent 的长期记忆 | S3 用户桶,按用户 ID 前缀存储,通过 Workspace Sync 定期同步 |
USER.md |
用户偏好和个人信息 | 同上 |
agents/*/auth-profiles.json |
模型 API 密钥和 OAuth 凭证 | AWS Secrets Manager(集中加密管理) |
credentials/ |
渠道登录状态(WhatsApp session 等) | AWS Secrets Manager + Amazon DynamoDB Identity 表 |
| 会话历史 | 对话记录和 Agent 状态 | S3 工作区 + AgentCore Session Storage(/mnt/workspace) |
| 技能和插件 | 用户安装的 ClawHub 技能 | 容器镜像预装 + S3 工作区持久化 |
本项目的容器在启动时会自动从 S3 恢复用户的工作区,运行期间每 5 分钟(可通过 cdk.json 的 workspace_sync_interval_seconds 配置)将 .openclaw/ 目录同步回 S3。这意味着即使 microVM 被销毁(空闲超时或达到最大生命周期),用户下次发消息时,新的 microVM 会自动恢复之前的工作区状态。
如果你有已有的 OpenClaw 工作区数据需要迁移,可以将 ~/.openclaw/ 下的 Markdown 文件(MEMORY.md、USER.md 等)上传到 S3 用户桶对应的前缀下。API 密钥等敏感信息则应存入 AWS Secrets Manager,而非直接上传到 S3。
接下来,我们进入动手环节。
三、部署概览
你将完成什么?
整个部署分 10 个步骤,完成后你会在自己的 AWS 账号里得到一个完整的多用户 AI Agent 平台 — 也就是上面分析的迁移改造的最终产物。
搭建完成后你拥有的东西
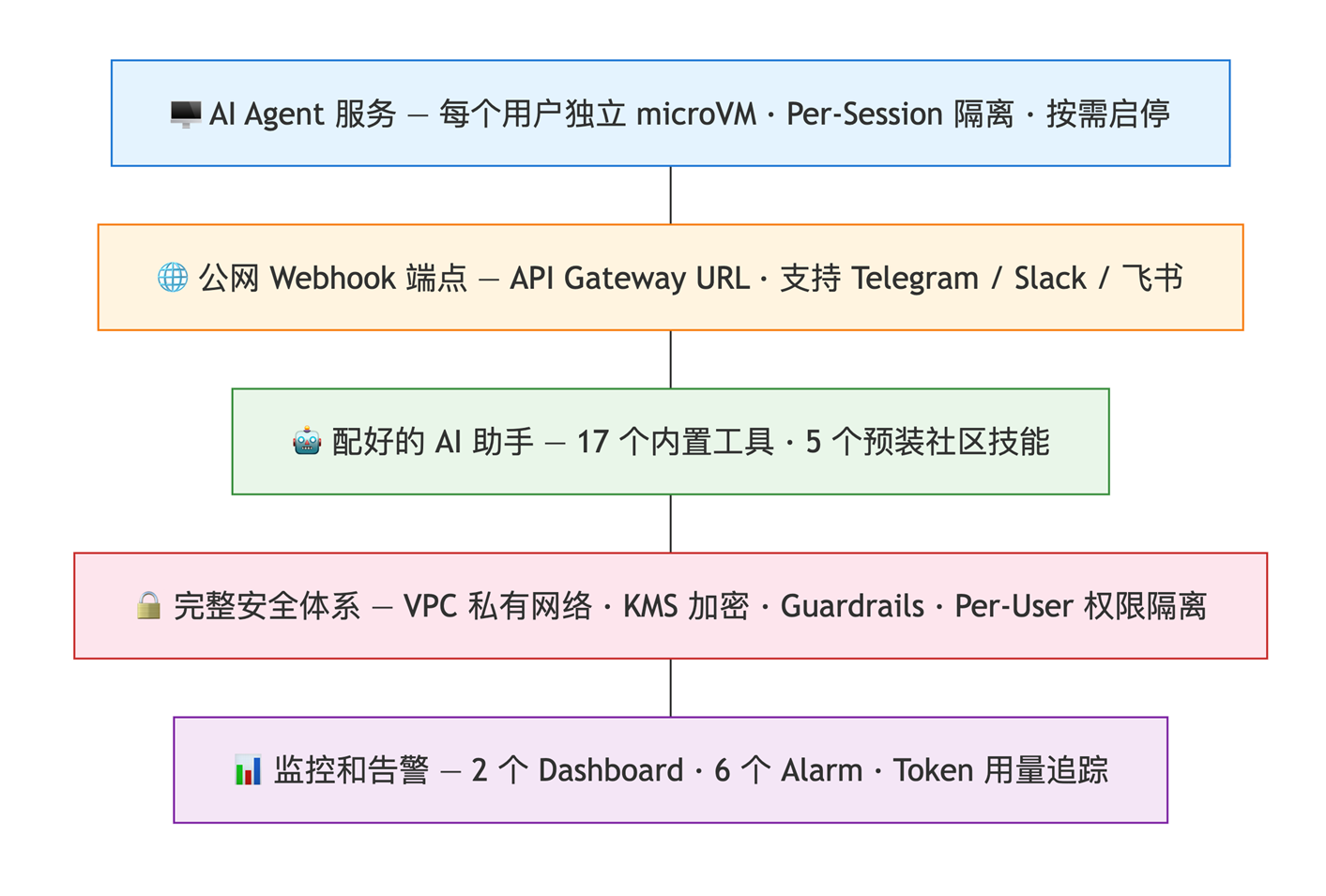
[图2] |
怎么用?
本项目没有独立的 UI,也没有账号密码系统。用户通过已有的 IM 渠道(Telegram / Slack / 飞书)与 AI 交互,身份由渠道的 user ID 自动标识:
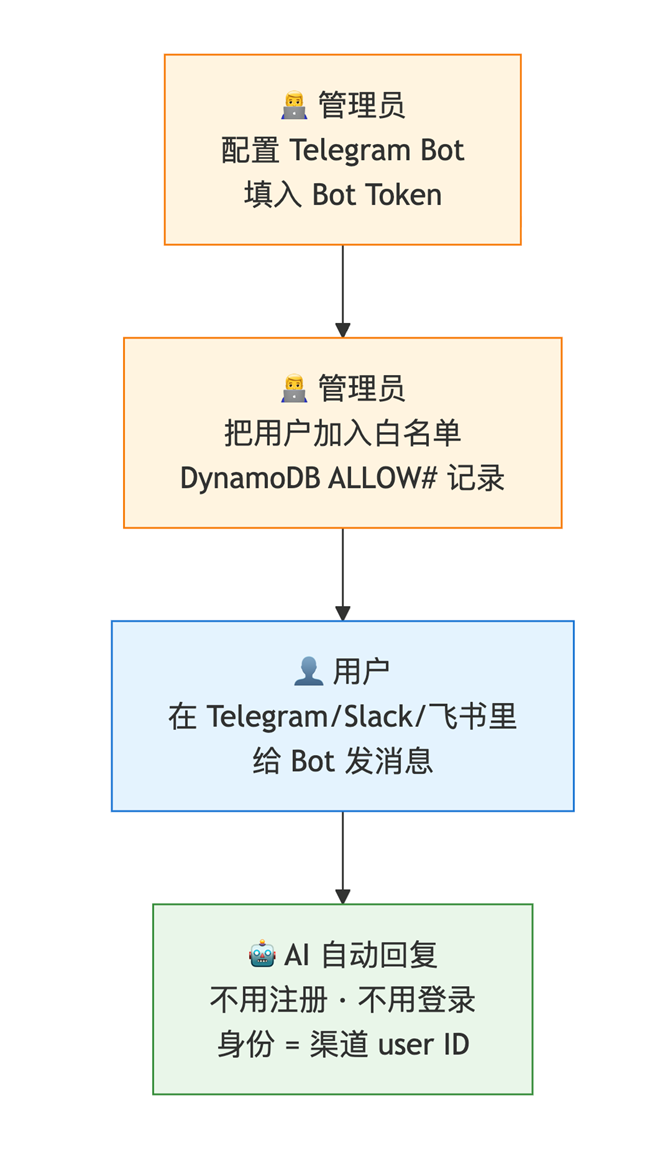
[图3] |
⚠️ 重要提示:
这个项目必须配置至少一个 IM 渠道才能实际使用。如果不配置 Telegram/Slack/飞书,Amazon API Gateway 收不到任何消息,用户无法触发 AI。建议至少配置 Telegram 或飞书(第七步)。
3.1 部署会用到的核心 AWS 服务
按默认配置,以下服务全部会被部署。这也是 Replatform 策略的具体体现 — 每一项原本需要自己实现或手动管理的能力,都由对应的 AWS 托管服务接管。
| 服务 | 在本项目中具体做什么 | 为什么用它 |
|---|---|---|
| Amazon Bedrock | 用户发消息后,容器调用 Bedrock 的 ConverseStream API 让 Claude 模型生成回复 | 托管的大模型服务,API 调用即可,无需自己部署推理集群 |
| AgentCore Runtime | 收到用户消息时,自动为该用户创建一个独立的 microVM 运行 AI Agent;用户不活跃时自动销毁 | Serverless 运行时,自动隔离、扩缩容、按需计费 |
| Amazon Bedrock Guardrails | 每次调用 Claude 时自动检查:过滤仇恨/暴力内容、检测 PII(个人身份信息)、拒绝危险话题、阻止提示注入 | 开箱即用的内容审核,不用自己写规则 |
| AgentCore Browser | AI 需要浏览 JS 动态渲染的网页时,通过 Playwright 连接到这个托管的 Chrome 浏览器实例 | 不用在容器里装 Chrome,AWS 托管 |
| Amazon API Gateway | Telegram/飞书把用户消息 POST 到这个 URL(/webhook/telegram 等),是整个系统唯一的公网入口 |
托管 HTTPS 入口,自带限流(burst 50 / sustained 100 req/s)和访问日志 |
| AWS Lambda | 3 个函数:Router 处理 webhook 消息并调用容器;Cron 执行定时任务并推送结果;Token Metrics 统计每次 AI 调用的用量 | 按调用计费,没请求时零成本 |
| Amazon DynamoDB | 2 张表:Identity 表存用户身份/白名单/会话/定时任务;Token Usage 表存每次 AI 调用的 Token 数和成本 | 毫秒级 NoSQL,按需计费,不用管数据库服务器 |
| Amazon S3 | 1 个桶按用户 ID 分前缀:存对话历史(.openclaw/ 同步)、用户文件(read/write_user_file 工具)、Telegram/飞书发的图片 |
近乎无限容量,11 个 9 持久性 |
| Amazon VPC | 所有容器和 Lambda 跑在私有子网里,没有公网 IP,外部无法直接访问 | 网络隔离是多租户安全的基础 |
| VPC Endpoint | 容器在私有子网里没有公网,通过 8 条内部专线访问 Bedrock/ECR/S3/Secrets Manager 等 AWS 服务 | 流量走 AWS 骨干网,不经过互联网 |
| NAT Gateway | AI 的 web_search/web_fetch 工具需要访问外网搜索信息,私有子网的出网流量通过 NAT 转发 | 托管 NAT,不用自己维护 NAT 实例 |
| AWS KMS | 1 个加密密钥(别名 openclaw/secrets),被 S3/DynamoDB/Secrets Manager/SNS 引用做静态加密,自动轮换 | 托管密钥服务,是各服务加密的基础 |
| AWS Secrets Manager | 8 个 Secret:Telegram/Slack/飞书的 Bot Token、Gateway Token(容器认证)、Webhook 签名密钥、Amazon Cognito 密码派生密钥 | 密钥不写在代码里,集中加密管理 |
| Amazon Cognito | 容器内的 Proxy 自动为每个渠道用户注册 Cognito 身份,签发 JWT Token,用于容器内部识别”当前在服务哪个用户”。容器内的凭证隔离、文件存储、工作区同步、用量统计都依赖这个身份标签才能把数据路由到正确的用户。这不是面向用户的登录系统,用户不需要输入账号密码,整个过程对用户透明 | 系统内部的身份标签机制,不用自己实现 |
| AWS STS | 容器启动时调用 STS 生成限制版临时凭证,把权限缩小到只能访问当前用户的 S3 前缀/DynamoDB 记录/Secrets,原始凭证删除 | Per-User 权限隔离的核心,用户 A 拿不到用户 B 的数据 |
| AWS IAM | 约 8 个角色:容器执行角色、3 个 Lambda 角色、Bedrock 日志角色、Flow Logs 角色、Amazon EventBridge Scheduler 角色等 | 最小权限原则,每个组件只有它需要的权限 |
| Amazon EventBridge Scheduler | 用户对 AI 说”每天早上 8 点提醒我”,AI 在 EventBridge 里创建一条 cron 规则,到点触发 Cron Lambda 执行并推送结果 | 托管 cron,支持时区,不用自己维护定时系统 |
| Amazon CloudWatch | 6 个 Log Group 收集各组件日志;2 个 Dashboard 展示运维指标和用量分析;6 个 Alarm 监控错误/延迟/预算 | AWS 原生监控,多数服务默认推送指标 |
| Amazon SNS | CloudWatch Alarm 触发后(比如 Bedrock 错误率过高、Token 用量超预算),通过 SNS 发通知给管理员邮箱 | 简单的消息分发,连接告警和通知渠道 |
| AWS CodeBuild | deploy.sh 在 Phase 2 触发 CodeBuild 用 ARM64 构建机构建 Docker 镜像,构建完自动推送到 ECR | AgentCore 要求 ARM64 镜像,云端构建不用本地装 QEMU |
| Amazon ECR | 存储构建好的 OpenClaw 容器镜像,AgentCore Runtime 启动新 microVM 时从这里拉取镜像 | 私有镜像仓库,和 AgentCore 在同一 VPC 内拉取快 |
| AWS X-Ray | 记录一次用户消息从 API Gateway → Lambda → AgentCore → Bedrock 的完整调用链路和每段耗时 | 排错时能看到哪个环节慢或出错 |
默认不部署的可选服务(如需开启,修改 cdk.json):
| 服务 | 配置项 | 说明 |
|---|---|---|
| AWS CloudTrail | enable_cloudtrail: false |
默认关闭。大多数 AWS 账号已经有组织级 Trail,不需要额外创建 |
3.2 部署架构分三个阶段
整个部署通过一个 deploy.sh 脚本自动串联三个阶段。之所以分阶段,是因为后一阶段依赖前一阶段的输出(比如 Phase 3 的 Router Lambda 需要知道 Phase 2 创建的 AgentCore Runtime ID)。这也是基础设施即代码(Infrastructure as Code)在复杂项目中的典型编排模式。
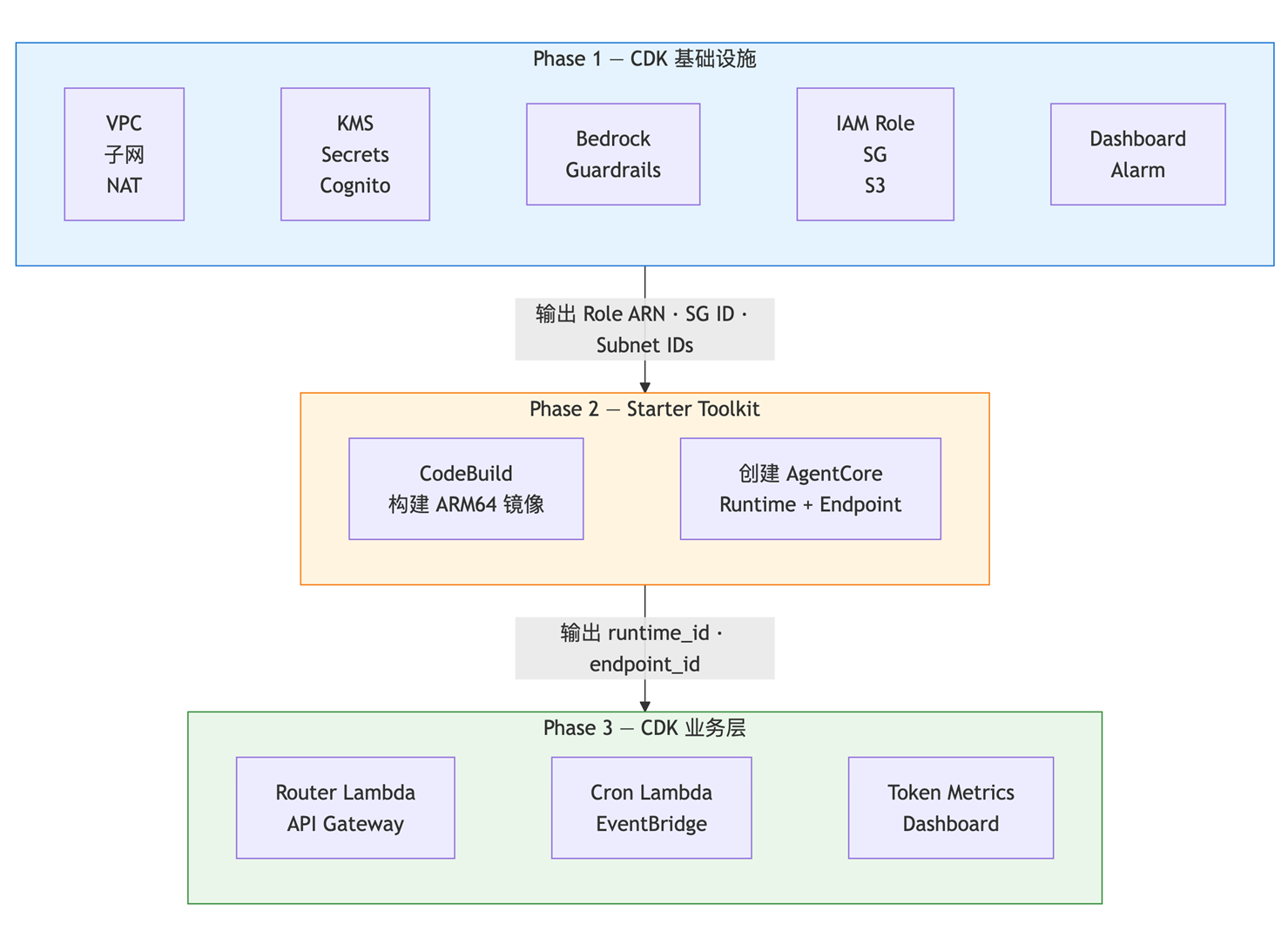
[图4] |
为什么分三阶段?因为 Phase 3 的 Router Lambda 需要知道 Phase 2 创建的 AgentCore Runtime 的 ID,所以不能一次部署完。脚本会自动串联这三个阶段。
相关链接
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Bedrock AgentCore — 加快代理投入生产的速度
系列文章:
- 第二篇:环境准备与代码获取
- 第三篇:Phase 1 — 部署基础设施
- 第四篇:Phase 2 & 3 — 部署 AgentCore Runtime 与业务层
- 第五篇:配置消息渠道与端到端验证
- 第六篇:清理资源与总结展望
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
