亚马逊AWS官方博客
使用Amazon SageMaker Hyperpod Cluster部署whisper模型
摘要:本篇博客详细介绍了如何利用 Amazon SageMaker HyperPod Cluster,在托管的 EKS 集群中部署基于 TensorRT-LLM 编译的 Whisper 模型,并通过 Triton Inference Server 对外提供高性能推理服务。
一、背景
在大模型快速发展的当下,越来越多的用户开始尝试在应用中增加开源模型的能力,以提升用户体验。使用亚马逊云科技服务时,您可以选择将开源模型部署在Amazon SageMaker上,通过推理endpoint对外提供服务。SageMaker能够根据您设定的业务监控指标,自动对endpoint底层的GPU实例进行弹性扩缩容,帮助您在性能和成本之间取得最佳平衡。然而,通过托管endpoint部署模型存在以下局限性:
- 异构GPU部署受限:当模型需要部署时,由于GPU容量限制,您可能需要在多种实例类型上混合部署,例如同时使用G5和G6e实例。由于托管endpoint目前不支持异构GPU部署,您不得不为每种机型创建独立的endpoint。
- 请求调度复杂:多个endpoint会显著增加应用层请求调度的复杂度。每个endpoint都有自己的QPS上限,且底层实例会动态扩缩容,这使得客户端很难精准判断应将新请求路由到哪个endpoint,从而影响整体的负载均衡效果。
二、解决方案
针对上述挑战,容器化部署是一个更加灵活的解决方案。您可以利用Amazon SageMaker Hyperpod Cluster,将模型部署在SageMaker托管的Amazon Elastic Kubernetes Service(EKS)集群中。这种部署方式将为您带来以下显著优势:
- 统一集群异构部署:通过为每种GPU机型创建独立的Hyperpod Cluster节点组,您可以在同一个EKS集群中实现多种异构GPU实例的统一管理和部署,打破了托管endpoint的限制。
- 灵活的弹性伸缩:借助成熟的Kubernetes生态工具,如Karpenter和Cluster Autoscaler,您可以更精细地控制集群中GPU节点的弹性扩缩策略,实现更高效的资源利用。
- 完善的可观测性:结合Amazon Managed Prometheus (AMP) 和 Amazon Managed Grafana (AMG),您可以构建完整的模型推理性能监控体系,实时洞察服务状态,快速定位和解决问题。
三、部署说明
接下来我们以Whisper模型为例,详细说明在SageMaker Hyperpod Cluster部署开源模型的方法。
3.1 前期准备
- 申请quota。需提高sagemaker服务中的ml.xxx for cluster usage的账户quota。具体机型视需求而定,本篇Blog采用g5.2xlarge和g6e.2xlarge为例;
- 在本篇Blog中,我们会利用Tensorrt-llm 对whisper模型进行编译,最终将模型部署在Triton Inference Server中,以提升推理速度。有关Triton Server的详细内容,请参考Nvidia官方Blog。您需按照该repo,提前完成对应机型的whisper triton模型编译,以及推理服务器镜像的上传。当上传完成后,您可以在对应Region的Amazon Elastic Container Registry镜像仓库中,查找到对应的镜像。
- 克隆repo到本地
3.2 创建集群
通过控制台创建集群。选择创建方式为Custom Setup。控制台会自动帮助我们创建Hyperpod集群,包括配套的可观测性组件。大部分参数保持默认即可,几个关键参数如下:
- VPC选择。可以选择新创建VPC或保持现有VPC
- EKS版本,建议选择最新版本
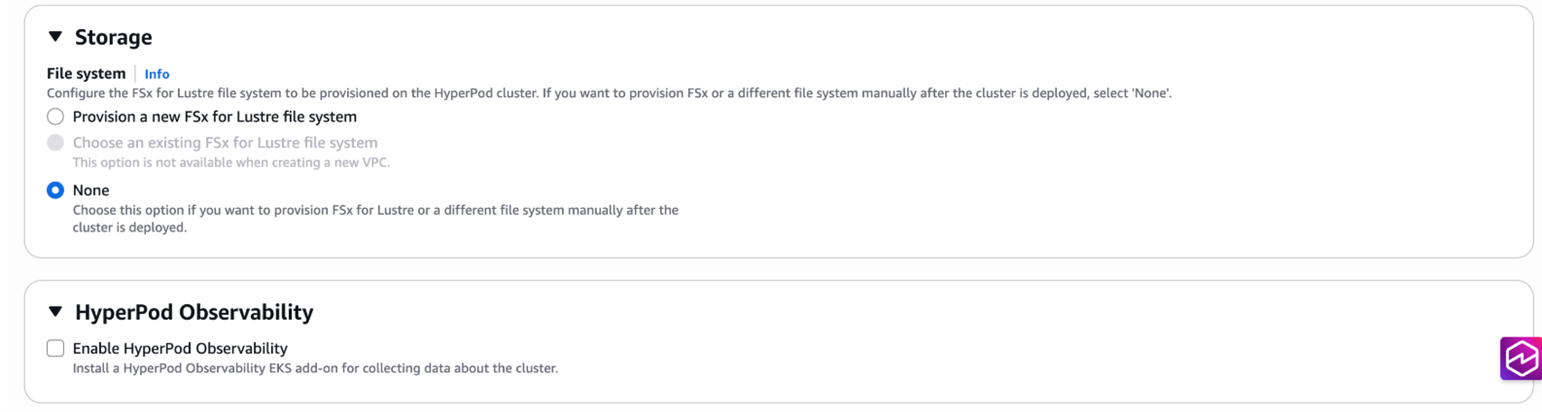
- Storage默认配置了FSx文件系统,在我们此次演示中暂时不需要,可以先设置为none;
- 另外可观测性组件我们后续会单独部署,也可以将Enable选项去掉
[图1] |
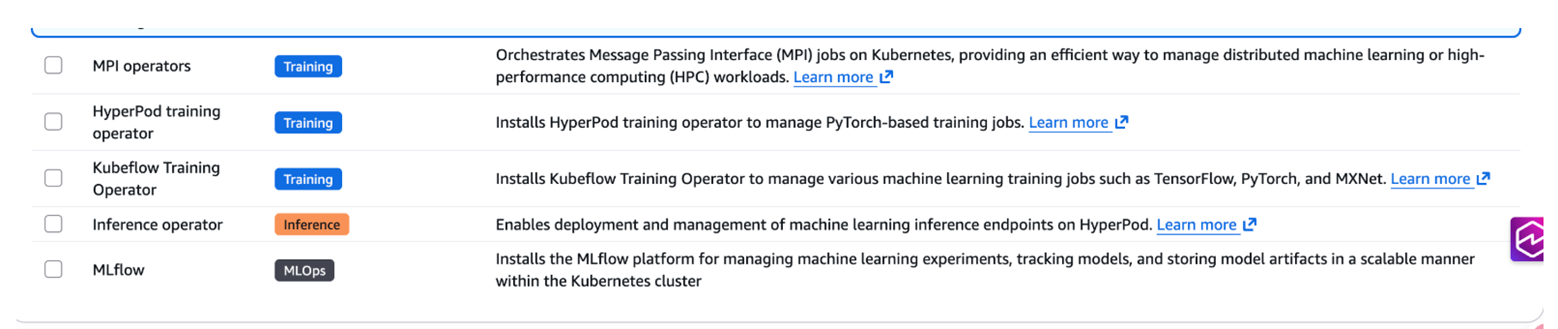
- operator选项中,关于training和MLops相关的operator暂时用不到,可以先不勾选以节省集群资源
[图2] |
- instance group配置。需根据需求创建对应的GPU实例类型以及对应数量。Advanced configuration配置中,Threads per core要选择为2(默认为1)
Hyperpod Cluster创建完成后,您即可以在EKS控制台中看到对应的EKS集群ID。
3.3 环境变量配置
- 您可以通过修改config.env.example文件进行统一的环境变量配置,修改完后,将其重命名为config.env。
3.4 创建S3 PV/PVC
- 部署s3 csi driver以及相关service account。您可以使用脚本 create_s3_csi_driver.sh 快速部署。
- 部署load balancer controller及相关service account。您可以使用脚本 create_lb_controller.sh 快速部署。
3.5 上传模型脚本/部署whisper服务
3.6 查看服务部署/确认对外Endpoint
其中,k8s-default-whispert-82ac852532-007fe009a29cb74b.elb.us-east-1.amazonaws.com即为whisper对外服务的endpoint地址,服务通过NLB对外暴露。可以通过http://k8s-default-whispert-82ac852532-007fe009a29cb74b.elb.us-east-1.amazonaws.com:8080/invocations进行访问,NLB会将外部请求路由到g6e,g5实例上的whisper pod上。
3.7 测试服务是否正常
3.8 可观测性配置
我们可以通过Amazon Managed Service for Prometheus (AMP) 的托管的scraper功能进行Prometheus指标的收集,它是一个完全托管的无代理采集器,该功能简化了 EKS 集群的监控部署和管理,让您可以专注于业务逻辑而不是基础设施管理。
- EKS集群必须启用Private Access,您可以通过该命令修改
- 控制台进入EKS集群Observability界面,点击Add scraper:
- 上传 scraper 配置(注意将cluster参数修改为您的集群ID),点击创建,等待scraper ready。
- 测试指标采集是否正常
3.9 Grafana 配置
您可以通过控制台创建Grafana Workspace,并且连接上述的Prometheus Workspace。Grafana仪表板配置,您可以通过该链接下载。通过如下配置模板,即可完成对Grafana面板的配置:
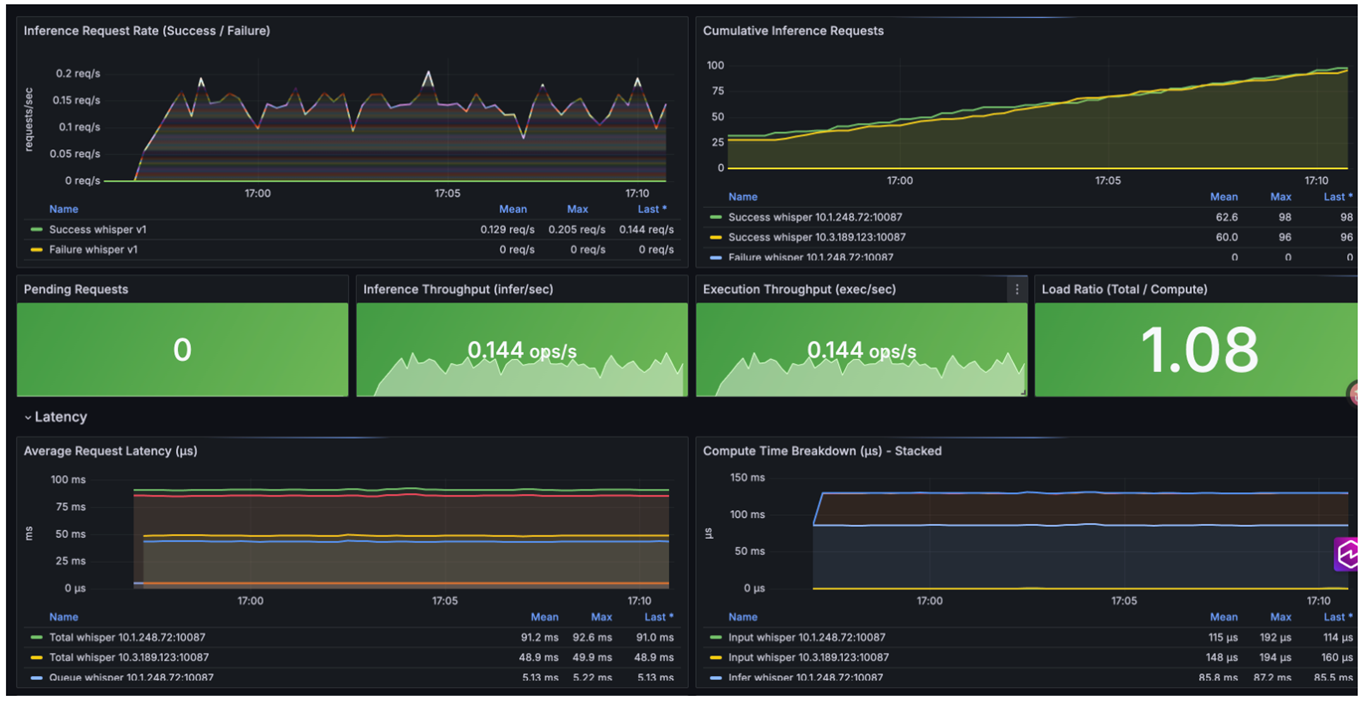
配置完成后,即可在Grafana面板中看到Triton Server相关指标:
[图3] |
详细指标及说明如下:
- Overview(概览)
- Inference Request Rate(成功/失败 请求速率)
- Cumulative Inference Requests(累积请求数)
- Pending Requests(待处理请求数)
- Inference Throughput(推理吞吐量)
- Execution Throughput(执行吞吐量)
- Load Ratio(负载比率 = 总时间/计算时间)
- Latency(延迟)
- Average Request Latency(平均请求延迟:总/队列/计算)
- Compute Time Breakdown(计算时间分解:Input/Infer/Output 堆叠图)
- Queue Time(队列等待时间)
- Load Ratio Over Time(负载比率趋势)
- GPU Metrics
- GPU Utilization(GPU 利用率,含阈值线)
- GPU Memory Usage(GPU 显存使用)
- GPU Power Usage(GPU 功耗)
以上面板可以帮助您全面监控 Triton 推理服务的吞吐量、延迟、负载和成功率等核心性能指标。
四、总结
本篇博客详细介绍了如何利用 Amazon SageMaker HyperPod Cluster,在托管的 EKS 集群中部署基于 TensorRT-LLM 编译的 Whisper 模型,并通过 Triton Inference Server 对外提供高性能推理服务。整个部署流程涵盖以下关键环节:
- 集群创建与配置:通过控制台创建 HyperPod Cluster,配置异构 GPU 节点组(如 g5.2xlarge 和 g6e.2xlarge),实现多种 GPU 实例在同一集群中的统一管理。
- 存储与网络配置:通过 S3 CSI Driver 将模型文件挂载到集群,并借助 AWS Load Balancer Controller 创建 NLB,对外暴露推理服务。
- 模型部署与服务发布:将 TensorRT-LLM 编译后的 Whisper 模型部署至 Triton Inference Server,通过 Kubernetes Deployment 实现跨异构 GPU 节点的统一调度,NLB 自动将外部请求路由至不同机型的推理 Pod 上。
- 可观测性建设:集成 Amazon Managed Prometheus 托管 Scraper 进行指标采集,结合 Amazon Managed Grafana 构建完整的监控面板,覆盖推理吞吐量、请求延迟、队列状态及 GPU 利用率等核心性能指标。
相比传统的 SageMaker 托管 Endpoint 部署方式,HyperPod Cluster 方案在异构 GPU 混合部署、请求负载均衡、弹性伸缩策略以及可观测性方面具备更高的灵活性和可控性。对于有多机型混合部署需求、或需要精细化运维管控的场景,HyperPod Cluster 是一个值得考虑的部署选择。
➡️ 下一步行动:
相关产品:
- Amazon SageMaker — 适用于所有数据、分析和 AI 的中心
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon VPC — 隔离云网络
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
相关文章:
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
