背景介绍
推荐系统是利用 电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。最早的推荐算法通常是用关联规则建立的,如著名的啤酒尿不湿的故事,就是利用关联规则推荐商品促进成交的经典案例。而为之而生的算法,如Apriori算法,就是亚马逊所发明的。当我们在Amazon上购买图书时,会经常看到下面两个提示:1.这些书会被消费者一起购买,并且价格上有一定的折扣;2.购买了这本书的人,也会购买其他书。Amazon对平台中海量的用户记录进行挖掘,发现了这些规律,然后将这些规律应用于实际销售工作当中。而结果也显示,使用这种算法优化,对于当时亚马逊的业绩提升起到了很大作用。
今天,随着电子商务规模的不断扩大,商品种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关信息和产品的过程无疑会使淹没在信息过载问题中的消费者不断流失。为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。区别于传统的规则推荐,个性化推荐算法通常使用机器学习甚至深度学习算法,对于用户信息与其行为信息充分挖掘,进而进行有效的推荐。
常用的推荐算法有很多,其中最为经典的,就是基于Matrix Factorization(矩阵分解)的推荐。矩阵分解的思想简单来说就是每一个用户和每一个物品都会有自己的一些特性,用矩阵分解的方法可以从评分矩阵中分解出用户——特性矩阵,特性——物品矩阵,这样做的好处是得到了用户的偏好和每件物品的特性。矩阵分解的思想也被扩展和泛化到深度学习及embedding中,这样构建模型,能够增强模型的准确率及灵活易用性。
本解决方案使用 Amazon SageMaker,它可以帮助开发人员和数据科学家构建、训练和部署 ML 模型。Amazon SageMaker 是一项完全托管的服务,涵盖了 ML 的整个工作流,可以标记和准备数据、选择算法、训练模型、调整和优化模型以便部署、预测和执行操作。同时,本方案基于Gluon API,Gluon 是微软联合亚马逊推出的一个开源深度学习库,这是一个清晰、简洁、简单但功能强大的深度学习 API,该规范可以提升开发人员学习深度学习的速度,而无需关心所选择的深度学习框架。Gluon API 提供了灵活的接口来简化深度学习原型设计、创建、训练以及部署,而且不会牺牲数据训练的速度。
本节将介绍如何使用Amazon SageMaker 的自定义脚本 (Bring Your Own Script,简称BYOS)方式来运行gluon程序(MXNet后端)的训练任务,并且进行部署调用。首先我们来看下如何在Amazon SageMaker Notebook上运行这个项目,本地运行训练任务,然后再把它进行部署,直接利用Amazon SageMaker的相关接口进行调用。
解决方案概览
在此示例中, 我们将使用Amazon SageMaker执行以下操作:
- 环境准备
- 使用Jupyter Notebook下载数据集并将其进行数据预处理
- 使用本地机器训练
- 使用 Amazon SageMaker BYOS进行模型训练
- 托管部署及推理测试
环境准备
我们首先要创建一个Amazon SageMaker Notebook,笔记本实例类型最好选择ml.p3.2xlarge,因为本例中用到了本地机器训练的部分用来测试我们的代码,卷大小建议改成10GB或以上,因为运行该项目需要下载一些额外的数据。
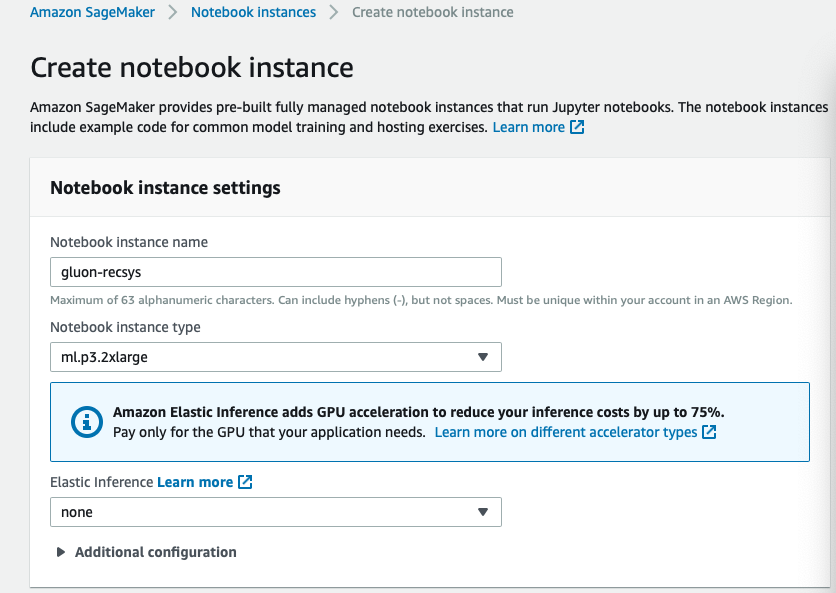
笔记本启动后,打开页面上的终端,执行以下命令下载代码, 或者您也可以通过Sagemaker Examples中,找到Introduction to Applying Machine Learning/ gluon_recommender_system.ipynb点击 use 运行代码。
cd ~/SageMaker
git clone https://github.com/awslabs/amazon-sagemaker-examples/tree/master/introduction_to_applying_machine_learning/gluon_recommender_system
使用 Jupyter Notebook 下载数据集并将其进行数据预处理
本文使用了亚马逊官方开源数据集,包含了2000亚马逊电商用户对于160k个视频的评论打分,打分分数为1-5,您可以访问该数据集主页查看完整的数据说明和进行下载。由于本数据集很大,我们将使用临时目录进行存储。
!mkdir /tmp/recsys/
!aws s3 cp s3://amazon-reviews-pds/tsv/amazon_reviews_us_Digital_Video_Download_v1_00.tsv.gz /tmp/recsys/
数据预处理
在您下载好数据后,我们可以通过python的pandas库进行数据的读取,浏览和预处理。
首先,运行如下代码加载数据
df=pd.read_csv('/tmp/recsys/amazon_reviews_us_Digital_Video_Download_v1_00.tsv.gz', delimiter='\t',error_bad_lines=False)
df.head()
您可以看到如下的结果,因为列比较多,这里截图显示的不完整
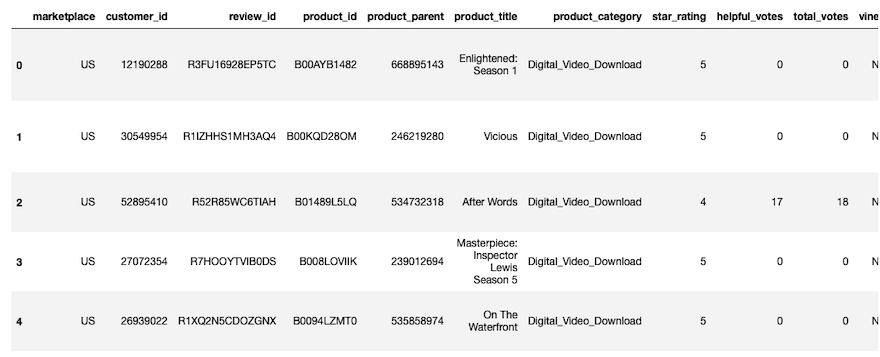
我们可以看到该数据集包含了很多特征(列),其中每列具体的含义如下:
- marketplace:两位数的国家编码,此处都是‘US’
- customer_id: 一个代表发表评论用户的随机编码,对于每个用户唯一
- review_id: 对于评论的唯一编码
- product_id: 亚马逊通用的产品编码
- product_parent:母产品编码,很多产品有同属于一个母产品
- product_title:产品的描述
- product_category:产品品类
- star_rating:评论星数,从1到5
- helpful_votes: 有用评论数
- total_votes:总评论数
- vine:是否为vine项目中的评论
- verified_purchase:该评论是否来源于已购买该产品的客户
- review_headline:评论标题
- review_body:评论内容
- review_date:评论时间
在这个例子中,我们只会使用custermor_id, product_id, star_rating三列构建模型。这也是我们构建一个推荐系统所需要最少的三列数据,其余的特征列如果在构建模型时添加,可以有效提高模型的准确率,但本文不会包括这部分内容。同时我们会保留product_title列用于结果验证。
df = df[['customer_id', 'product_id', 'star_rating', 'product_title']]
同时,因为大部分的视频大部分人都没有看过,所以我们的数据是很稀疏的。一般来说,推荐系统的模型对于稀疏数据可以很好的处理,但是这一般需要大规模的数据进行模型的训练,为了实验示例运行更加顺畅,这里我们将把这种数据稀疏的场景进行验证,并且进行清洗,使用一个较为稠密的reduced_df进行模型的训练
可以通过如下代码进行稀疏(‘长尾效应’)的验证
customers = df['customer_id'].value_counts()
products = df['product_id'].value_counts()
quantiles = [0, 0.01, 0.02, 0.03, 0.04, 0.05, 0.1, 0.25, 0.5, 0.75, 0.9, 0.95, 0.96, 0.97, 0.98, 0.99, 1]
print('customers\n', customers.quantile(quantiles))
print('products\n', products.quantile(quantiles))
你可以看到只有5%的客户评论了5个及以上的视频,同时只有25%的视频被超过10个用户评论。
接下来我们将把数据进行过滤,去掉长尾用户和产品。
customers = customers[customers >= 5]
products = products[products >= 10]
reduced_df = df.merge(pd.DataFrame({'customer_id': customers.index})).merge(pd.DataFrame({'product_id': products.index}))
接下来我们对用户与产品进行重新编码。
customer_index = pd.DataFrame({'customer_id': customers.index, 'user': np.arange(customers.shape[0])})
product_index = pd.DataFrame({'product_id': products.index,
'item': np.arange(products.shape[0])})
reduced_df = reduced_df.merge(customer_index).merge(product_index)
下一步,我们将我们准备好的数据集进行切割为训练集和验证集。其中验证集将作为模型效果的验证使用,并不会在训练中使用。
test_df = reduced_df.groupby('customer_id').last().reset_index()
train_df = reduced_df.merge(test_df[['customer_id', 'product_id']],
on=['customer_id', 'product_id'],
how='outer',
indicator=True)
train_df = train_df[(train_df['_merge'] == 'left_only')]
最后一步,我们将数据集由Pandas DataFrame转换为MXNet NDArray, 这里因为我们即将使用基于MXNe的gluon接口进行模型训练
batch_size = 1024
train = gluon.data.ArrayDataset(nd.array(train_df['user'].values, dtype=np.float32),
nd.array(train_df['item'].values, dtype=np.float32),
nd.array(train_df['star_rating'].values, dtype=np.float32))
test = gluon.data.ArrayDataset(nd.array(test_df['user'].values, dtype=np.float32),
nd.array(test_df['item'].values, dtype=np.float32),
nd.array(test_df['star_rating'].values, dtype=np.float32))
train_iter = gluon.data.DataLoader(train, shuffle=True, num_workers=4, batch_size=batch_size, last_batch='rollover')
test_iter = gluon.data.DataLoader(train, shuffle=True, num_workers=4, batch_size=batch_size, last_batch='rollover')
使用本地机器训练
我们首先通过自己定义一个简单的网络结构在本地进行训练,这里我们会继承gluon接口构建MFBlock类,需要设置如下的主要网络结构, 更多关于如何使用gluon构建自定义网络模型的信息,您可以参考动手深度学习。简单的说明如下:
class MFBlock(gluon.HybridBlock):
def __init__(self, max_users, max_items, num_emb, dropout_p=0.5):
super(MFBlock, self).__init__()
self.max_users = max_users
self.max_items = max_items
self.dropout_p = dropout_p
self.num_emb = num_emb
with self.name_scope():
self.user_embeddings = gluon.nn.Embedding(max_users, num_emb)
self.item_embeddings = gluon.nn.Embedding(max_items, num_emb)
self.dropout_user = gluon.nn.Dropout(dropout_p)
self.dropout_item = gluon.nn.Dropout(dropout_p)
self.dense_user = gluon.nn.Dense(num_emb, activation='relu')
self.dense_item = gluon.nn.Dense(num_emb, activation='relu')
def hybrid_forward(self, F, users, items):
a = self.user_embeddings(users)
a = self.dense_user(a)
b = self.item_embeddings(items)
b = self.dense_item(b)
predictions = self.dropout_user(a) * self.dropout_item(b)
predictions = F.sum(predictions, axis=1)
return predictions
##set up network
num_embeddings = 64
net = MFBlock(max_users=customer_index.shape[0],
max_items=product_index.shape[0],
num_emb=num_embeddings,
dropout_p=0.5)
# Initialize network parameters
ctx = mx.gpu()
net.collect_params().initialize(mx.init.Xavier(magnitude=60),
ctx=ctx,
force_reinit=True)
net.hybridize()
# Set optimization parameters
opt = 'sgd'
lr = 0.02
momentum = 0.9
wd = 0.
trainer = gluon.Trainer(net.collect_params(),
opt,
{'learning_rate': lr,
'wd': wd,
'momentum': momentum})
同时,我们需要构建一个评估函数用来评价我们的模型。这里我们将使用MSE.
def eval_net(data, net, ctx, loss_function):
acc = MSE()
for i, (user, item, label) in enumerate(data):
user = user.as_in_context(ctx)
item = item.as_in_context(ctx)
label = label.as_in_context(ctx)
predictions = net(user, item).reshape((batch_size, 1))
acc.update(preds=[predictions], labels=[label])
return acc.get()[1]
好了,接下来,我们定义训练的代码并且示例一下进行几个轮次的训练。
def execute(train_iter, test_iter, net, epochs, ctx):
loss_function = gluon.loss.L2Loss()
for e in range(epochs):
print("epoch: {}".format(e))
for i, (user, item, label) in enumerate(train_iter):
user = user.as_in_context(ctx)
item = item.as_in_context(ctx)
label = label.as_in_context(ctx)
with mx.autograd.record():
output = net(user, item)
loss = loss_function(output, label)
loss.backward()
trainer.step(batch_size)
print("EPOCH {}: MSE ON TRAINING and TEST: {}. {}".format(e,
eval_net(train_iter, net, ctx, loss_function),
eval_net(test_iter, net, ctx, loss_function)))
print("end of training")
return net
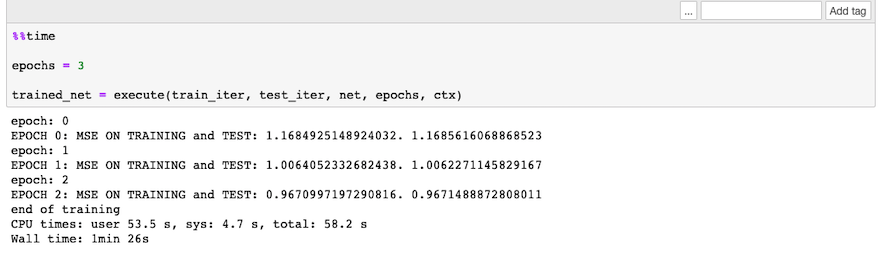
%%time
epochs = 3
trained_net = execute(train_iter, test_iter, net, epochs, ctx)
可以看到,打印出来的训练日志,显示训练成果运行,并且loss随着迭代次数的增加在下降。
使用 Amazon SageMaker BYOS进行模型训练
在上文的范例中,我们使用本地环境一步步的训练了一个较小的模型,验证了我们的代码。现在,我们需要把代码进行整理,在Amazon SageMaker上,进行可扩展至分布式的托管训练任务。
首先,我们要将上文的代码整理至一个python脚本,然后使用SageMaker上预配置的MXNet容器,我们提供了很多灵活的使用方式来使用该容器,可以参考mxnet-sagemaker-estimators。
在本文中,我们将覆盖如下几步:
- 将所有数据预处理的工作封装至一个函数,本文中为prepare_train_data
- 将所有训练相关的代码(函数或类)复制粘贴
- 定义一个名为train的函数,用于:
- 添加一段Sagemaker训练集群读取数据的代码
- 定义超参数为一个字典作为入参,在之前的例子我们是全局定义的
- 创建网络并且执行训练
您可以在下载的代码目录中看到recommender.py脚本,是编辑后的范例。
现在,我们需要将数据从本地上传至S3,这样Amazon SageMaker后台运行时可以直接读取。这种方式通常对于大数据量的场景和生产环境的实践十分常见。
boto3.client('s3').copy({'Bucket': 'amazon-reviews-pds',
'Key': 'tsv/amazon_reviews_us_Digital_Video_Download_v1_00.tsv.gz'},
bucket,
prefix + '/train/amazon_reviews_us_Digital_Video_Download_v1_00.tsv.gz')
最后,我们可以通过SageMaker Python SDK创建一个MXNet estimator, 需要传入以下设置:
- 训练的实例类型和实例个数,SageMaker提供的MXNet容器支持单机训练也支持多gpu训练,只需要您指定训练机型个数即可切换
- 模型存储的S3路径及其对应的权限设置
- 模型对应的超参数,这里我们将embedding的个数提升,后面可以看到这个结果会优于之前的结果,这里的超参数配置可以进一步进行调优,从而得到更为准确的模型
完成以上配置后,我们可以用.fit()来开启训练任务,这会创建一个SageMaker的训练任务加载数据和程序,运行我们recommender.py脚本中的train函数,将模型结果保存至传入的S3路径。
m = MXNet('recommender.py',
py_version='py3',
role=role,
train_instance_count=1,
train_instance_type="ml.p2.xlarge",
output_path='s3://{}/{}/output'.format(bucket, prefix),
hyperparameters={'num_embeddings': 512,
'opt': opt,
'lr': lr,
'momentum': momentum,
'wd': wd,
'epochs': 10},
framework_version='1.1')
m.fit({'train': 's3://{}/{}/train/'.format(bucket, prefix)})
训练启动后,我们可以在Amazon SageMaker控制台看到这个训练任务,点进详情可以看到训练的日志输出,以及监控机器的GPU、CPU、内存等的使用率等情况,以确认程序可以正常工作。


托管部署及推理测试
在本地完成训练后,我们可以轻松的将上面的模型部署成一个实时可在生产环境中调用的端口。
predictor = m.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
predictor.serializer = None
上述命令运行后,你会在控制面板中看到相应的endpoint配置。当成功创建后,我们可以测试一下,这里可以通过发出一个http post请求,也可以简单的通过调用sdk的.predict()直接调用,你会得到返回的预测结果:[5.446407794952393, 1.6258208751678467]
predictor.predict(json.dumps({'customer_id': customer_index[customer_index['user'] == 6]['customer_id'].values.tolist(),
'product_id': ['B00KH1O9HW', 'B00M5KODWO']}))
进一步的,我们可以计算模型在测试集上的误差,结果为1.27,这个结果优于我们之前本地embedding设置为64的1.65,这也体现了通过调节网络结构,我们可以不断优化我们的模型。
test_preds = []
for array in np.array_split(test_df[['customer_id', 'product_id']].values, 40):
test_preds += predictor.predict(json.dumps({'customer_id': array[:, 0].tolist(),
'product_id': array[:, 1].tolist()}))
test_preds = np.array(test_preds)
print('MSE:', np.mean((test_df['star_rating'] - test_preds) ** 2))
总结
在本文中,我们向大家展示了如何利用Amazon SageMaker基于gluon构建一个简单的推荐系统,并且将它进行部署调用。这可以是您入手推荐系统的很好的入门教程,但值得注意的是,本文作为基础示例,并没有包含超参数调优,网络结构的优化,多特征的引入等工作,这都是后续提升准确率构建一个完备的推荐系统所必需的工作。如果您使用更复杂深入的推荐系统模型,或是基于gluon构建其他应用,请关于我们后续博客和Amazon SageMaker的官方文档。
参考资料
- 本文代码: https://github.com/awslabs/amazon-sagemaker-examples/tree/master/introduction_to_applying_machine_learning/gluon_recommender_system
- Apriori算法: https://en.wikipedia.org/wiki/Apriori_algorithm
- MXNet: https://mxnet.incubator.apache.org
- Amazon SageMaker: https://docs.aws.amazon.com/sagemaker/index.html
- 动手深度学习: http://zh.d2l.ai/chapter_preface/preface.html
本篇作者




