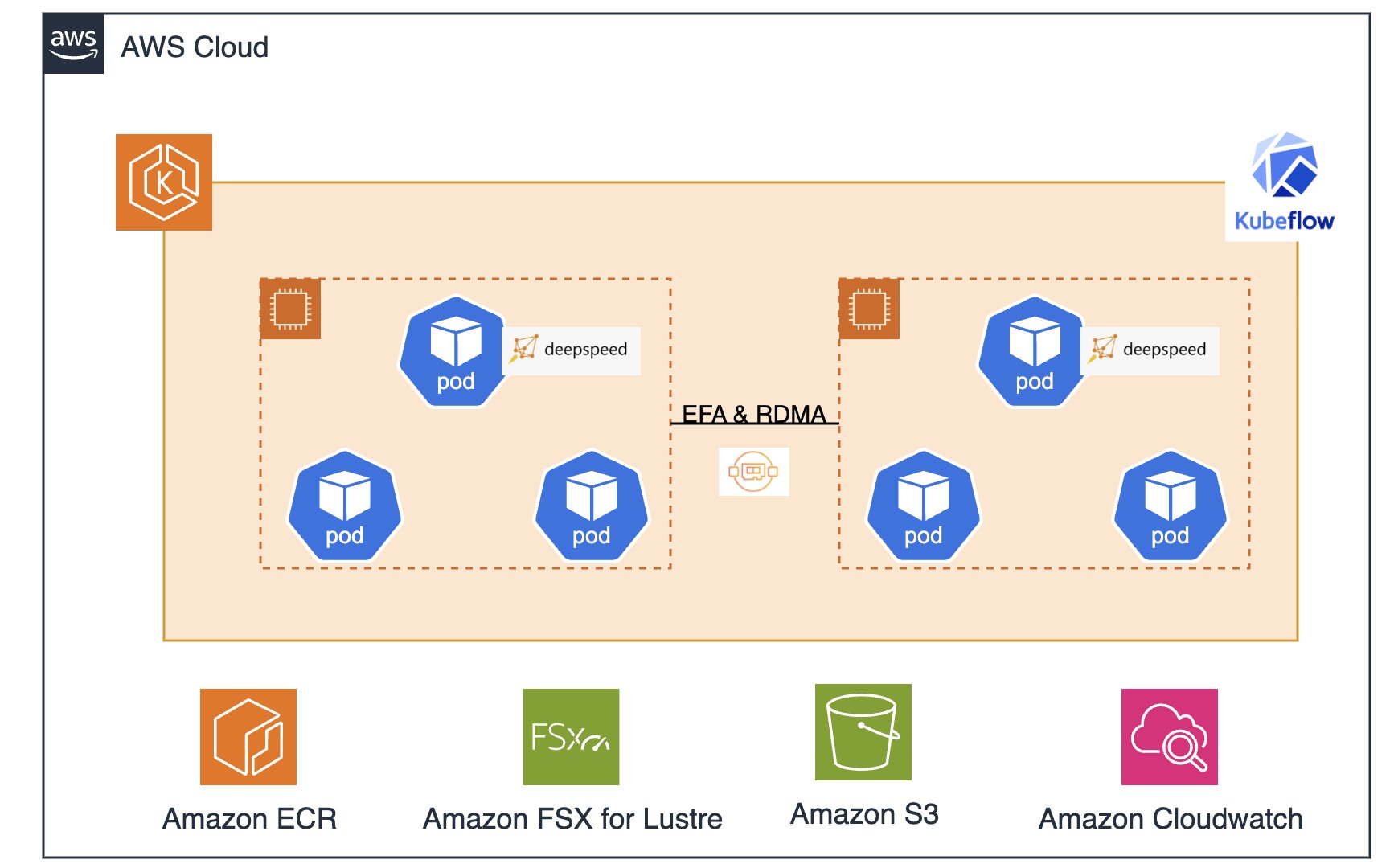
机器学习模型,尤其是深度学习模型,近年来变得越来越复杂。在单台机器上训练这些模型,特别是大型语言模型,可能会非常低效,甚至由于单个设备计算资源和内存容量的限制而无法实现。这就是分布式训练发挥作用的地方。分布式训练是一种允许您将训练工作负载分散到多台机器或设备(如 GPU)上的技术。分布式训练有几种方法,包括数据并行、模型并行。目前,有许多分布式训练框架,如 Horovod、PyTorch 分布式数据并行(DDP)、TensorFlow 分布式策略、Megatron 和 DeepSpeed。这些框架处理工作节点之间的通信、梯度聚合和其他必要操作,使用户可以专注于模型架构和训练逻辑。在本文章中,我们将介绍如何使用 DeepSpeed 在亚马逊云科技的服务上进行 Llama 2 的分布式训练。
方案概览
在深入到方案之前我们需要了解一些知识:
- DeepSpeed 是一个开源库,它能够高效地进行大型语言模型和其他深度学习模型的分布式训练。它提供了各种优化技术,例如 ZeRO(零冗余优化器),以减少内存消耗。
- Kubeflow Training Operator 是一个 Kubernetes 原生项目,用于微调和针对机器学习模型做可扩展的分布式训练,这些模型可使用各种机器学习框架创建,如 PyTorch、TensorFlow、HuggingFace、JAX、DeepSpeed、XGBoost、PaddlePaddle 等。
- Amazon EKS 是一个托管的 Kubernetes 服务,可在在亚马逊云上和本地数据中心中运行 Kubernetes。在云环境中,Amazon EKS 自动管理 Kubernetes 控制平面节点的可用性和可扩展性,这些节点负责调度容器、管理应用程序可用性、存储集群数据以及其他关键任务。
- Amazon FSx for Lustre 提供完全托管的共享存储,具有流行的 Lustre 文件系统的可扩展性和性能。
- Amazon Elastic Fabric Adapter (EFA) 是一种适用于 Amazon EC2 实例的网络接口,它使客户能够在 AWS 上大规模运行需要高水平节点间通信的应用程序。它定制的操作系统(OS)旁路硬件接口提升了实例间通信的性能,这对于扩展这些应用程序至关重要。EFA 支持远程直接内存访问(RDMA)协议。
安装步骤
开始训练之前有一些必要的安装步骤:
- 如果您没有 Amazon EKS 和 FSx for Lustre,请安装它们,这里有一个 Terraform 项目可以帮助您搭建环境,请注意的一点是如果您想自定义的 terraform-aws-modules/eks/aws 模块或者指定 EKS 版本。
- terraform-aws-modules/eks/aws 模块:在 data on EKS repo 的 ai-ml/jark-stack/terraform/eks.tf 中更新,请参考 Terraform 官方文档更新部署代码。
- EKS 版本:在 data on EKS repo 的 ai-ml/jark-stack/terraform/variables.tf 中更新,并且注意相关插件版本更新。
- 构建分布式训练的 Docker 镜像,包括 Cuda、DeepSpeed、EFA 插件、PyTorch 等组件。
- 安装 Kubeflow Training Operator,用于将分布式训练任务提交到 Amazon EKS。
- 准备使用 DeepSpeed 和 PyTorch 的 Llama 2 训练代码。
- 定义 AWS 训练 YAML 脚本并立即开始训练。
安装 Amazon EKS 和 FSx for Lustre
如果没有现成的环境,请按照 Amazon EKS 和 FSx for Lustre 的详细说明进行安装。我们还准备了一个 Terraform 项目,用于设置所需组件,包括 Amazon VPC、Amazon FSx for Lustre 和 Amazon EKS、EKS 插件(如 EFA 设备插件、NVIDIA 设备插件等)。这个 Terraform 项目基于 Data-on-EKS 项目开发。
Run the install script
使用提供的辅助脚本 install.sh 来运行 terraform init 和 apply 命令。默认情况下,该脚本会在 us-west-2 区域部署 EKS 集群。如需更改区域,请更新 variables.tf 文件。此时也可以更新任何其他输入变量或对 terraform 模板进行任何其他更改。
更新本地的 kubeconfig 文件以便能够访问新部署的 EKS 集群,请执行以下命令,如果您在 variables.tf 中更改了区域,请确保在上述命令中使用正确的区域。<集群名称>应替换为您的 EKS 集群的实际名称,这通常在 terraform 输出中可以找到。执行:
aws eks update-kubeconfig --name deepspeed-on-eks #or whatever you used for EKS cluster name
执行此命令后,kubectl 命令行工具将被配置为与您的 EKS 集群通信。您可以通过运行以下命令来验证连接:
这应该会显示您的 EKS 集群中的节点列表:
同时,请检查集群中所有必要的 Pod 是否正常运行,特别是 nvidia-device-plugin 和 fsx-csi-controller。
安装 Kubeflow Training Operator
Training Operator 可以作为独立组件安装,运行以下命令来安装 Training Operator 控制平面的稳定版本:v1.8.1,如果您需要安装其他版本,只需将命令中的 v1.8.1 替换为您想要的版本号即可。
kubectl apply -k "github.com/kubeflow/training-operator.git/manifests/overlays/standalone?ref=v1.8.1"
这个命令将从 GitHub 仓库获取 Training Operator v1.8.1 的配置,并将其应用到您的 Kubernetes 集群中。安装完成后,让我们验证 Training Operator 是否已成功部署:
构建分布式训练的 Docker 镜像
构建用于分布式训练的 Docker 镜像涉及以下几个关键步骤:
- 指定基础镜像:
- 对于 LLM 训练,需要使用带有 CUDA 支持的 Python 基础镜像。在本仓库中,使用了
nvidia/cuda:11.8.0-devel-ubuntu22.04 镜像,该镜像提供了预装 NVIDIA CUDA 11.8.0 的 Ubuntu 22.04 环境。
- 确保基础操作系统镜像与您的目标硬件兼容,并满足机器学习工作负载的要求。
- 为您的 LLM 训练安装必要的插件,如 EFA 和 NCCL 插件,具体请参考 Get started with EFA and NCCL for ML workloads。
- 安装 Elastic Fabric Adapter(EFA)插件:能够在 AWS 上的 GPU 实例之间实现高性能通信。
- 安装 NVIDIA 集合通信库(NCCL)插件:为深度学习工作负载优化了多 GPU 和多节点通信。
- 机器学习库:
- 安装所需的机器学习库,包括 DeepSpeed、PyTorch、Transformers、Accelerate、NumPy 和其他依赖项。
- 特别注意这些库的版本,因为版本不匹配可能会导致兼容性问题。
当然,如果您已有一个指定了这些库正确版本的可用 Dockerfile,可以直接使用它来确保兼容性。以下是我的 Dockerfile,用于参考:
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04
ARG EFA_INSTALLER_VERSION=1.29.1
ARG AWS_OFI_NCCL_VERSION=v1.7.4-aws
ARG NCCL_TESTS_VERSION=master
ARG NCCL_VERSION=2.18.6
RUN apt-get update -y
RUN apt-get remove -y —allow-change-held-packages \
libmlx5-1 ibverbs-utils libibverbs-dev libibverbs1 libnccl2 libnccl-dev
RUN rm -rf /opt/hpcx \
&& rm -rf /usr/local/mpi \
&& rm -f /etc/ld.so.conf.d/hpcx.conf \
&& ldconfig
ENV OPAL_PREFIX=
RUN DEBIAN_FRONTEND=noninteractive apt-get install -y —allow-unauthenticated \
git \
gcc \
vim \
kmod \
openssh-client \
openssh-server \
build-essential \
curl \
autoconf \
libtool \
gdb \
automake \
python3-distutils \
cmake \
apt-utils \
devscripts \
debhelper \
libsubunit-dev \
check \
pkg-config
RUN mkdir -p /var/run/sshd
RUN sed -i 's/[ #]\(.*StrictHostKeyChecking \).*/ \1no/g' /etc/ssh/ssh_config && \
echo " UserKnownHostsFile /dev/null" >> /etc/ssh/ssh_config && \
sed -i 's/#\(StrictModes \).*/\1no/g' /etc/ssh/sshd_config
ENV LD_LIBRARY_PATH /usr/local/cuda/extras/CUPTI/lib64:/opt/amazon/openmpi/lib:/opt/nccl/build/lib:/opt/amazon/efa/lib:/opt/aws-ofi-nccl/install/lib:/usr/local/lib:$LD_LIBRARY_PATH
ENV PATH /opt/amazon/openmpi/bin/:/opt/amazon/efa/bin:/usr/bin:/usr/local/bin:$PATH
RUN curl https://bootstrap.pypa.io/get-pip.py -o /tmp/get-pip.py \
&& python3 /tmp/get-pip.py \
&& pip3 install awscli pynvml
#################################################
## Install EFA installer
RUN cd $HOME \
&& curl -O https://efa-installer.amazonaws.com/aws-efa-installer-${EFA_INSTALLER_VERSION}.tar.gz \
&& tar -xf $HOME/aws-efa-installer-${EFA_INSTALLER_VERSION}.tar.gz \
&& cd aws-efa-installer \
&& ./efa_installer.sh -y -g -d —skip-kmod —skip-limit-conf —no-verify \
&& rm -rf $HOME/aws-efa-installer
###################################################
## Install NCCL
RUN echo "Installing NCCL_VERSION = v${NCCL_VERSION}-1"
RUN git clone https://github.com/NVIDIA/nccl -b v${NCCL_VERSION}-1 /opt/nccl \
&& cd /opt/nccl \
&& make -j $(nproc) src.build CUDA_HOME=/usr/local/cuda \
NVCC_GENCODE="-gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_90,code=sm_90"
###################################################
## Install AWS-OFI-NCCL plugin
RUN apt-get install libtool autoconf cmake nasm unzip pigz parallel nfs-common build-essential hwloc libhwloc-dev libjemalloc2 libnuma-dev numactl libjemalloc-dev preload htop iftop liblapack-dev libgfortran5 ipcalc wget curl devscripts debhelper check libsubunit-dev fakeroot pkg-config dkms -y
RUN apt-get install python3-dev -y
RUN export OPAL_PREFIX="" \
&& git clone https://github.com/aws/aws-ofi-nccl.git /opt/aws-ofi-nccl \
&& cd /opt/aws-ofi-nccl \
&& git checkout ${AWS_OFI_NCCL_VERSION} \
&& ./autogen.sh \
&& ./configure —prefix=/opt/aws-ofi-nccl/install \
--with-libfabric=/opt/amazon/efa/ \
--with-cuda=/usr/local/cuda \
--with-mpi=/opt/amazon/openmpi/ \
--enable-platform-aws \
&& make -j $(nproc) && make install
###################################################
## Install fsdp
RUN mkdir -p /workspace/
WORKDIR /workspace
RUN pip3 install -U pip setuptools
RUN pip3 install fsspec==2023.1.0
RUN pip3 install huggingface_hub==0.17.0
RUN pip3 install huggingface
RUN pip3 install torch==1.13.0
RUN DS_BUILD_UTILS=1 DS_BUILD_FUSED_ADAM=1 pip3 install deepspeed==0.12.0
RUN pip3 install transformers==4.33.0
RUN pip3 install tqdm==4.66.1
RUN pip3 install peft==0.5.0
RUN pip install sentencepiece==0.1.99
RUN pip3 install tabulate
RUN pip3 install protobuf
RUN pip3 install python-etcd
RUN pip3 install datasets==3.0.1
RUN pip3 install numpy==1.26.4
RUN pip3 install accelerate==0.28.0
准备训练代码
训练代码使用 PyTorch,包含以下几个模块:
- 参数解析:使用 argparse 解析命令行参数,允许用户指定各种超参数和训练目录
- 对于分布式训练的 launcher/启动器的设置:代码使用 distributed.init_process_group 和 nccl 后端初始化分布式进程组,实现多 GPU 或多节点训练
- 数据加载:使用 load_from_disk 从指定目录加载训练数据集,请指定您偏好的数据集
- 加载模型和分词器
- 训练参数配置和初始化 Transformer Trainer 对象
- 模型训练和保存:执行模型训练并保存训练结果
具体代码如下:
from transformers import AutoModelForCausalLM, Trainer, TrainingArguments, AutoTokenizer
from transformers.models.llama.tokenization_llama import LlamaTokenizer
from datasets import load_from_disk,load_dataset
import random
import logging
import sys
import argparse
import os
import torch
import subprocess
import deepspeed
import torch.distributed as dist
if __name__ == "__main__":
dist.init_process_group(backend='nccl')
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--num_train_epochs", type=int, default=3)
parser.add_argument("--per_device_train_batch_size", type=int, default=2)
parser.add_argument("--per_device_eval_batch_size", type=int, default=4)
parser.add_argument("--warmup_steps", type=int, default=100)
#parser.add_argument("--eval_steps",type=int,default=5000)
parser.add_argument("--learning_rate", type=str, default=2e-5)
parser.add_argument("--evaluation_strategy",type=str,default="epoch")
parser.add_argument("--gradient_accumulation_steps",type=int,default=4)
parser.add_argument("--c",type=bool,default=False)
#parser.add_argument("--logging_steps",type=int,default=5000)
parser.add_argument("--save_steps",type=int,default=500)
parser.add_argument("--save_strategy",type=str,default="steps")
parser.add_argument("--save_total_limit",type=int,default=4)
parser.add_argument("--model_max_length",type=int,default=512)
parser.add_argument("--bf16",type=bool,default=True)
#parser.add_argument("--deepspeed_config",type=str,default="/data/")
# Data, model, and output directories
parser.add_argument("--output_data_dir", type=str, default="/data/llmma/output_data")
parser.add_argument("--output_dir", type=str, default="/data/data/llama2/output")
parser.add_argument("--model_dir", type=str, default="/data/llmma/model")
parser.add_argument("--n_gpus", type=str, default=8)
parser.add_argument("--training_dir", type=str, default="/data/llmma/training")
parser.add_argument("--test_dir", type=str, default="/data/llmma/test")
parser = deepspeed.add_config_arguments(parser)
args, _ = parser.parse_known_args()
# Set up logging
logger = logging.getLogger(__name__)
logging.basicConfig(
level=logging.getLevelName("INFO"),
handlers=[logging.StreamHandler(sys.stdout)],
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
rank = dist.get_rank()
world_size = dist.get_world_size()
print(f"Rank: {rank}, World_size:{world_size}")
# load datasets
train_dataset = load_from_disk(args.training_dir)
#test_dataset = load_dataset(args.test_dir)
logger.info(f" loaded train_dataset length is: {len(train_dataset)}")
#logger.info(f" loaded test_dataset length is: {len(test_dataset)}")
model_name_or_path = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,use_cache=False)
tokenizer = LlamaTokenizer.from_pretrained(model_name_or_path, model_max_length=args.model_max_length)
# Print additional special tokens
print("BOS Token:", tokenizer.bos_token)
print("EOS Token:", tokenizer.eos_token)
print("Mask Token:", tokenizer.mask_token)
print("Pad Token:", tokenizer.pad_token)
print("Unknown Token:", tokenizer.unk_token)
# define training args
training_args = TrainingArguments(
output_dir = f"{args.output_dir}/checkpoint",
num_train_epochs=args.num_train_epochs,
per_device_train_batch_size=args.per_device_train_batch_size,
per_device_eval_batch_size=args.per_device_eval_batch_size,
warmup_steps=args.warmup_steps,
evaluation_strategy="no", #just for test
logging_dir=f"{args.output_dir}/logs",
logging_steps = 10,
gradient_checkpointing=True,
learning_rate=float(args.learning_rate),
deepspeed=args.deepspeed_config,
#save_steps = args.save_steps,
save_strategy = "epoch", #just for test
save_total_limit = args.save_total_limit,
remove_unused_columns=False,
save_on_each_node = True,
gradient_accumulation_steps = args.gradient_accumulation_steps,
fp16=True,
bf16=False, # Use BF16 if available
)
# create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
# eval_dataset=test_dataset,
# tokenizer=tokenizer
)
# train model
trainer.train()
print("------saving model!-----")
save_model_dir = f"{args.output_dir}/model"
tokenizer.save_pretrained(save_model_dir)
trainer.save_model(save_model_dir)
print("------model is saved!-----")
自定义训练 YAML 和开始训练
在本篇 Blog 中,我们使用每节点 4 个GPU,一共 2 个节点。请替换以下内容:
- 将镜像 URL 替换为
REPLACE_WITH_YOUR_TRAINING_IMAGE_REPO_LINK
containers:
- name: pytorch
image: <REPLACE_WITH_YOUR_TRAINING_IMAGE_REPO_LINK>
- 替换为您的 Hugging Face token,因为 Llama 需要访问权限,当然如有需要,可以更改训练数据、测试数据目录和 DeepSpeed 配置的相关内容。
huggingface-cli login --token <REPLACE_WITH_YOUR_HUGGINGFACE_TOKEN> &&
torchrun
--nproc_per_node 4
--nnodes 2 /data/data/llama2/train.py
--per_device_eval_batch_size 1
--per_device_train_batch_size 1
--model_max_length 2048
--distributed-backend nccl
--learning_rate 0.00001
--training_dir /data/data/llama2/train
--test_dir /data/data/llama2/test
--deepspeed
--deepspeed_config /data/data/llama2/ds_z3_fp16.json
--num_train_epochs 1"
- 具体 YAML 文件如下,其他的主要的内容包括:
- Master 和 Worker 都需要指定 GPU 数量
FI_EFA_USE_DEVICE_RDMA 的参数值指定为 1,用于开启 RDMAcommand 中为提交的训练任务命令
apiVersion: "kubeflow.org/v1"
kind: PyTorchJob
metadata:
name: llama2
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
spec:
volumes:
- name: shmem
hostPath:
path: /dev/shm
- name: persistent-storage
persistentVolumeClaim:
claimName: fsx-static-pvc
containers:
- name: pytorch
image: <REPLACE_WITH_YOUR_TRAINING_IMAGE_REPO_LINK>
imagePullPolicy: Always
resources:
requests:
nvidia.com/gpu: 4
#vpc.amazonaws.com/efa: 1
limits:
nvidia.com/gpu: 4
#vpc.amazonaws.com/efa: 1
env:
- name: LOGLEVEL
value: DEBUG
- name: NCCL_DEBUG
value: INFO
- name: TORCH_NCCL_ASYNC_ERROR_HANDLING
value: '1'
- name: OMP_NUM_THREADS
value: '1'
- name: FI_PROVIDER
value: 'efa'
- name: NCCL_PROTO
value: 'simple'
- name: FI_EFA_USE_DEVICE_RDMA
value: '1'
- name : NCCL_IGNORE_DISABLED_P2P
value: '1'
command: ["/bin/sh", "-c", "huggingface-cli login --token <REPLACE_WITH_YOUR_HUGGINGFACE_TOKEN> && torchrun --nproc_per_node 4 --nnodes 2 /data/data/llama2/train.py --per_device_eval_batch_size 1 --per_device_train_batch_size 1 --model_max_length 2048 --distributed-backend nccl --learning_rate 0.00001 --training_dir /data/data/llama2/train --test_dir /data/data/llama2/test --deepspeed --deepspeed_config /data/data/llama2/ds_z3_fp16.json --num_train_epochs 1"]
volumeMounts:
- name: shmem
mountPath: /dev/shm
- name: persistent-storage
mountPath: /data
Worker:
replicas: 1
restartPolicy: OnFailure
template:
spec:
volumes:
- name: shmem
hostPath:
path: /dev/shm
- name: persistent-storage
persistentVolumeClaim:
claimName: fsx-static-pvc
containers:
- name: pytorch
image: <REPLACE_WITH_YOUR_TRAINING_IMAGE_REPO_LINK>
imagePullPolicy: Always
resources:
requests:
nvidia.com/gpu: 4
#vpc.amazonaws.com/efa: 1
limits:
nvidia.com/gpu: 4
#vpc.amazonaws.com/efa: 1
env:
- name: LOGLEVEL
value: DEBUG
- name: NCCL_DEBUG
value: INFO
- name: TORCH_NCCL_ASYNC_ERROR_HANDLING
value: '1'
- name: OMP_NUM_THREADS
value: '1'
- name: FI_PROVIDER
value: 'efa'
- name: NCCL_PROTO
value: 'simple'
- name: FI_EFA_USE_DEVICE_RDMA
value: '1'
- name : NCCL_IGNORE_DISABLED_P2P
value: '1'
command: ["/bin/sh", "-c", "huggingface-cli login --token <REPLACE_WITH_YOUR_HUGGINGFACE_TOKEN> && torchrun --nproc_per_node 4 --nnodes 2 /data/data/llama2/train.py --per_device_eval_batch_size 1 --per_device_train_batch_size 1 --model_max_length 2048 --distributed-backend nccl --learning_rate 0.00001 --training_dir /data/data/llama2/train --test_dir /data/data/llama2/test --deepspeed --deepspeed_config /data/data/llama2/ds_z3_fp16.json --num_train_epochs 1"]
volumeMounts:
- name: shmem
mountPath: /dev/shm
- name: persistent-storage
mountPath: /data
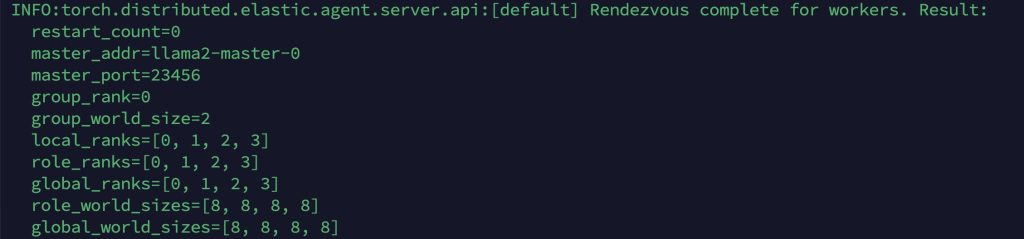
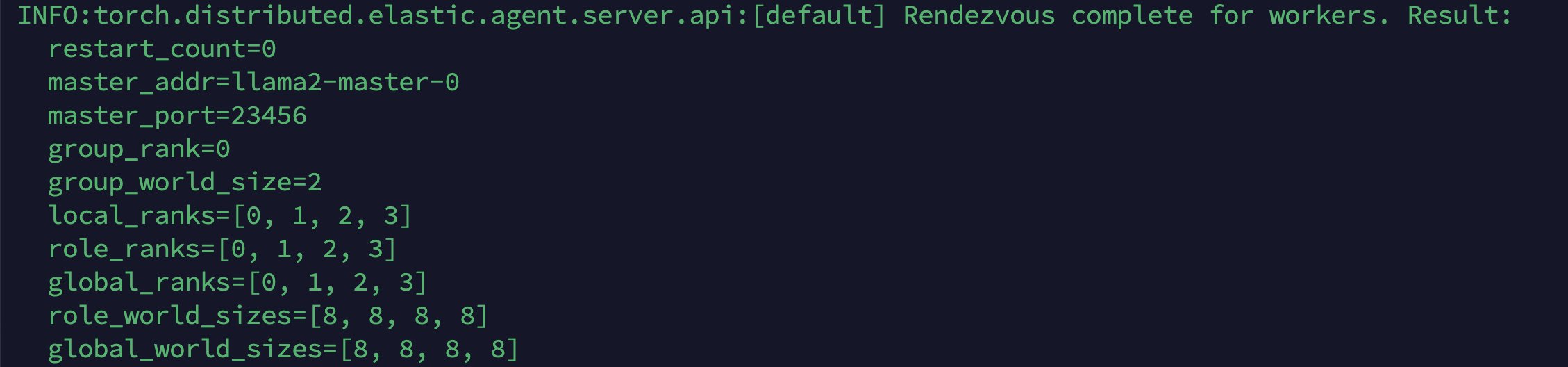
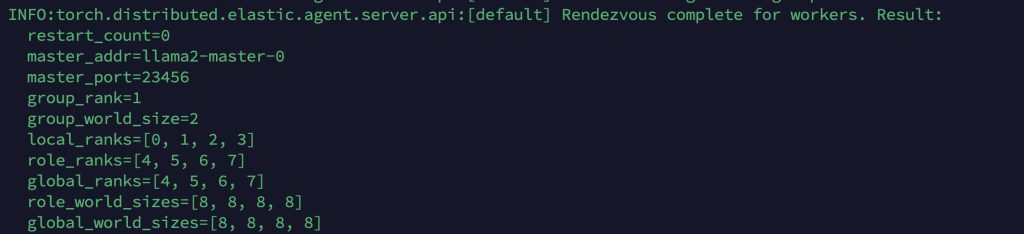
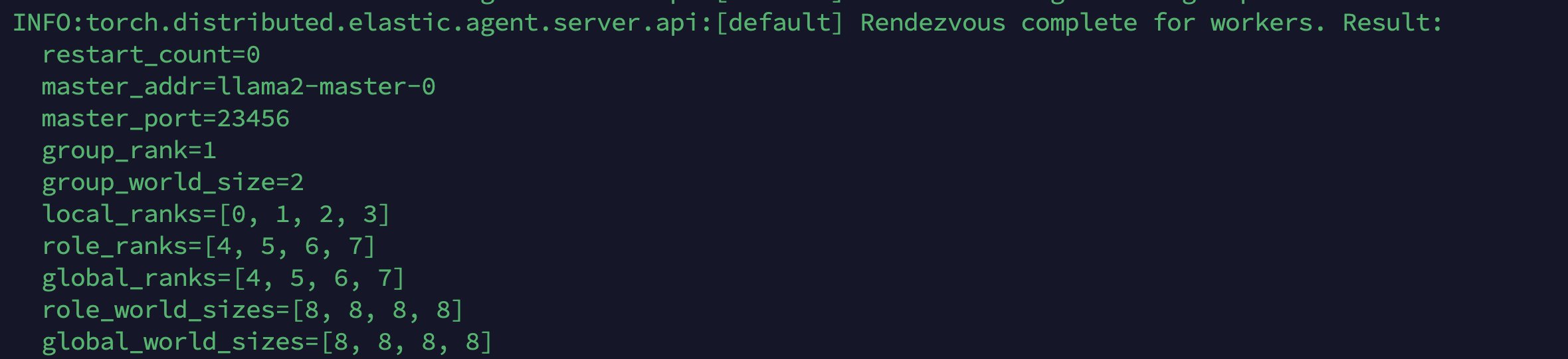
通过 kubectl apply -f deepspeed-llama2-job.yaml 执行上述的 YAML 文件后,训练任务成功提交到 Kubernetes 集群。系统会自动调度并在指定的 GPU 节点上启动训练容器。在初始化阶段,您将观察到如下日志输出,这些日志展示了分布式训练环境的建立过程:
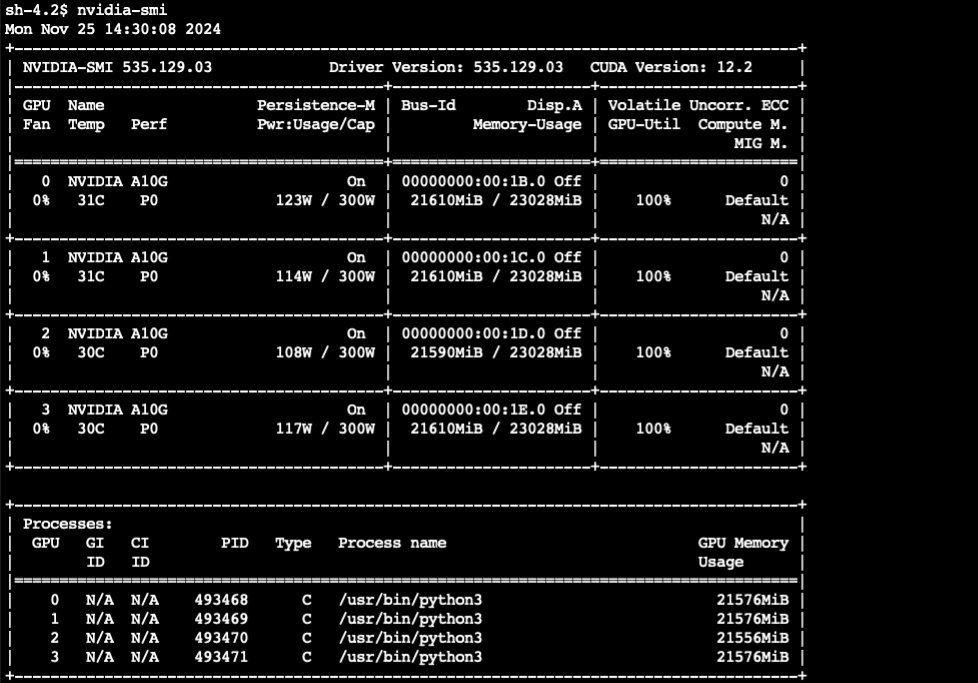
任务提交成功后,我们可以看到 GPU 的使用情况了。如下截图只是个示例,这是通过登录到 EC2 节点上,使用 nvidia-smi 命令查看 GPU 的实时指标,在真正的生产系统中,可以通过 Kubernetes 集成监控工具或者 CloudWatch 等进行更全面的监控。
总结
本方案成功地在 Amazon EKS 上使用 DeepSpeed 框架训练了 Llama 2 大语言模型,结合 Kubeflow 进行任务编排,DeepSpeed 的 ZeRO 优化器有效降低内存占用, 利用 EFA 网络加速节点间通信,实现了高效的 GPU 资源调度和低延迟数据传输,为企业级模型训练提供了可扩展的解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者