亚马逊AWS官方博客
使用 Karpenter 和 HAMi 实现 GPU 分片和动态扩缩容
概述
在现代 AI 和机器学习工作负载中,GPU 资源的高效利用和动态管理是关键挑战。随着AI应用的普及,企业面临着多样化的GPU使用需求:数据科学家需要在模型开发阶段进行频繁的小规模实验,生产环境中的推理服务往往只需要部分GPU算力,而在业务高峰期又需要快速扩展计算资源。传统的GPU分配方式通常以整卡为单位,导致在多租户场景、混合工作负载调度以及成本敏感型项目中出现严重的资源浪费问题。
本文将介绍如何结合Karpenter 和HAMi(Heterogeneous AI Computing Virtualization Middleware)来实现 GPU 资源的细粒度分片和自动扩缩容,通过GPU虚拟化技术让多个容器共享同一块GPU的显存和算力,并根据实际工作负载需求动态调整集群规模,从而在保证性能的同时显著提升资源利用率并降低成本。
1. Karpenter 和 HAMi 分别解决的问题
在传统的 Kubernetes 集群中,运维团队经常面临以下痛点:
扩容响应慢:使用 Cluster Autoscaler 时,从检测到资源不足到新节点可用往往需要几分钟,导致 AI 训练任务长时间处于 Pending 状态,影响业务迭代速度。
资源浪费严重:预先配置的节点池规格固定,无法根据实际工作负载动态调整。例如,为了应对偶尔的大规模训练任务而长期保持高配置节点,导致平时资源闲置率高。
成本难以控制:缺乏智能的实例类型选择机制,无法充分利用 Spot 实例的成本优势,GPU 实例的高昂费用成为 AI 项目的主要成本负担。
配置复杂繁琐:需要为不同工作负载维护多个 Auto Scaling Group,配置文件冗长且难以维护,增加了运维复杂度和出错风险。
Karpenter 是亚马逊云科技开源的 Kubernetes 节点自动扩缩容解决方案,主要解决:
快速节点供应:相比传统的 Cluster Autoscaler,Karpenter 可以更快的启动新节点
成本优化:智能选择最适合的实例类型,支持 Spot 实例混合使用
资源效率:基于实际工作负载需求进行精确的节点规格选择
简化配置:通过 NodePool 和 EC2NodeClass 简化节点管理
在 GPU 资源管理方面,企业面临着更加严峻的挑战:
GPU 利用率极低:传统方式下,一个容器独占整块 GPU,但实际使用率往往不高, 例如,小型推理服务只需要 2GB 显存,却不得不占用整个 24GB 的 A10G GPU,造成巨大浪费。
多租户隔离困难:多个团队或项目无法安全地共享 GPU 资源,要么为每个项目单独购买昂贵的 GPU 实例,要么面临资源竞争和安全隐患。
开发效率受限:数据科学家在模型开发和调试阶段需要频繁进行小规模实验,但由于 GPU 资源紧张,往往需要排队等待,严重影响开发效率和创新速度。
成本压力巨大:GPU 实例价格相对普通实例比较昂贵,对于预算有限的团队或初创项目来说,GPU 成本成为难以承受的负担。
HAMi 通过以下方式解决这些痛点:
GPU 资源分片:将单个 GPU 分割为多个虚拟 GPU,支持内存和计算核心的细粒度分配
多厂商支持:支持 NVIDIA、AMD等多种 GPU 厂商
资源隔离:确保不同容器间的 GPU 资源隔离和安全性
调度优化:基于 GPU 拓扑和亲和性进行智能调度
2. Karpenter 和 HAMi两者结合的价值
Karpenter 和 HAMi 的结合为企业带来了 1+1>2 的效果:
Karpenter 负责动态管理节点数量,根据工作负载自动扩缩容
HAMi 负责优化单节点内的 GPU 利用率,通过分片技术提升资源效率
两者协同工作,既能快速响应突发需求,又能最大化资源利用率,真正实现按需使用、按量付费的云原生理念。
3. 两者结合的挑战与解决方案
挑战一:扩容失败 – 资源不匹配
问题描述:
在扩展 GPU workload的deployment的时候,出现了pending pod, 但是Karpenter 在尝试扩容node时会报错:
no instance type has enough resources, requirements=nvidia.com/gpumem In [true], resources={"nvidia.com/gpumem":"8192"}
根本原因:
Karpenter 无法理解 HAMi 定义的虚拟 GPU 资源(如 nvidia.com/gpumem、nvidia.com/gpucores),导致无法正确选择实例类型。
解决方案 – NodeOverlay:
- NodeOverlay 功能介绍:
NodeOverlay 是 Karpenter 1.7版本引入的一个新特性,它提供了一种灵活的方式来将一些实际场景中的因素注入到调度模拟中去,如节省计划、许可成本和自定义硬件资源,这些因素在云提供商的基础实例数据中无法体现。在HAMi场景下,它可将HAMi自定义资源纳入到调度模拟中去,具体来讲,NodeOverlay 就像是给 Karpenter 提供了一份”资源清单”,告诉它:”当你创建 g5.xlarge 实例时,这个节点上会有多少虚拟 GPU、多少 GPU 显存、多少 GPU 核心”。这样 Karpenter 就能在调度决策时正确匹配 Pod 的资源需求。
- 启用 NodeOverlay 功能:
kubectl patch deployment karpenter -n kube-system -p '{"spec":{"template":{"spec":{"containers":[{"name":"controller","env":[{"name":"FEATURE_GATES","value":"NodeOverlay=true"}]}]}}}}'- 配置 NodeOverlay 资源映射:
apiVersion: karpenter.sh/v1alpha1
kind: NodeOverlay
metadata:
name: custom-devices
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g5.xlarge"]
capacity:
nvidia.com/gpu: "10"
nvidia.com/gpucores: "100"
nvidia.com/gpumem: "24000"
参数配置指南:
nvidia.com/gpu:根据 HAMi 配置的虚拟 GPU 数量
nvidia.com/gpumem:基于实例 GPU 显存容量(如 A10G 24GB = 24000MB)
nvidia.com/gpucores:根据 HAMi 的核心分片配置,在我们的测试场景中,我们设置为10
挑战二:缩容失败 – NodeClaim 状态异常
问题描述:
NodeClaim 状态显示为 Unknown,错误信息:
Resource “nvidia.com/gpucores” was requested but not registered
Reason: ResourceNotRegistered
Status: Unknown
Type: Initialized
根本原因:
- Karpenter 检测到 Pod 请求了 nvidia.com/gpucores 资源
- 但节点的 capacity 中没有注册这些资源
- 导致 Karpenter 认为节点未完成初始化,阻止缩容操作
解决方案 – Mock Device Plugin:
HAMi Mock Device Plugin 的作用是在节点上注册虚拟 GPU 资源到 capacity 和 allocatable:
Capacity:
cpu: 4
ephemeral-storage: 20893676Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 16164784Ki
nvidia.com/gpu: 10
nvidia.com/gpucores: 100
nvidia.com/gpumem: 23028
nvidia.com/gpumem-percentage: 100
pods: 58
Allocatable:
cpu: 3920m
ephemeral-storage: 18181869946
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15147952Ki
nvidia.com/gpu: 10
nvidia.com/gpucores: 100
nvidia.com/gpumem: 23028
nvidia.com/gpumem-percentage: 100
pods: 58
4. karpenter+HAMi 集成测试方案
版本要求
- Karpenter: >= 1.7
- Kubernetes: >= 1.27
- HAMi: >=2.7.1
- Mock Device Plugin: master branch
部署架构展示
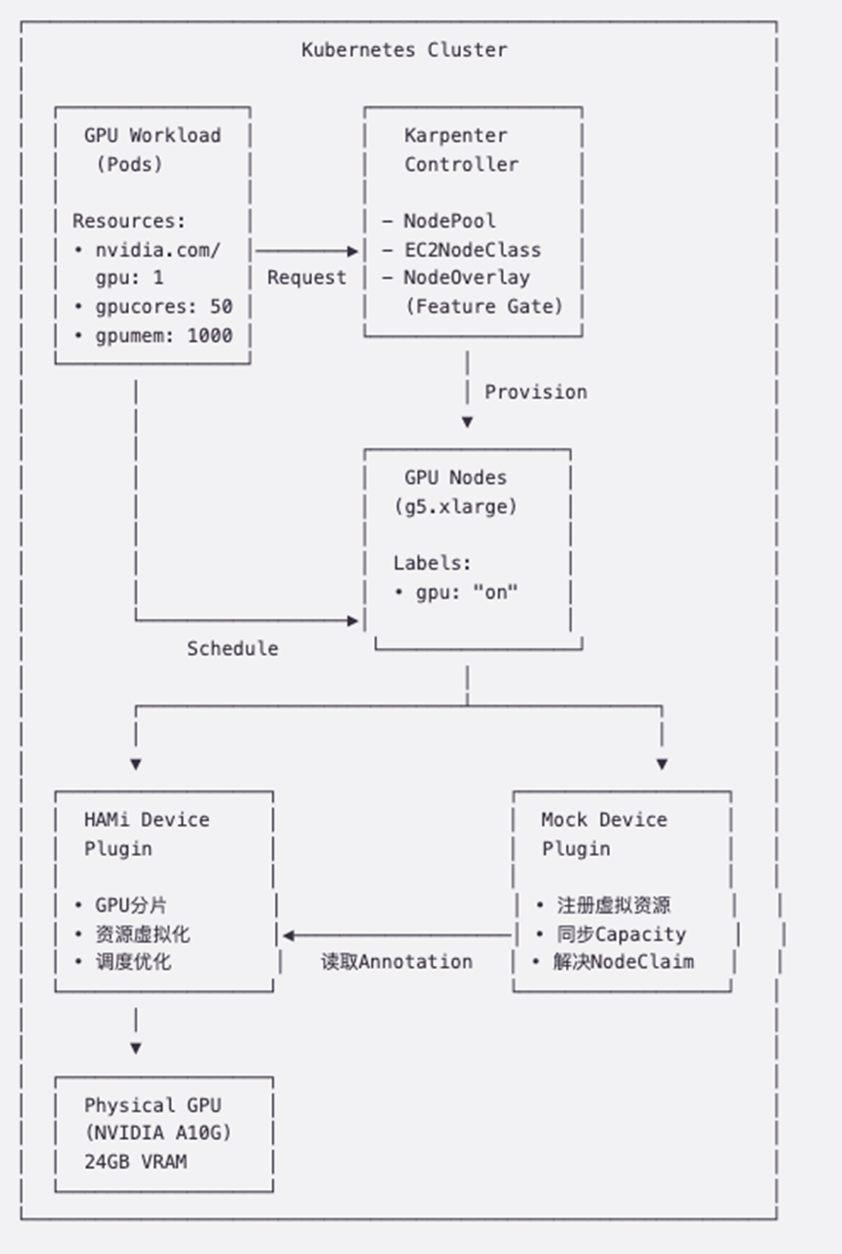 |
配置文件
GPU 工作负载 (gpu-workload.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-inference
spec:
replicas: 0
selector:
matchLabels:
app: gpu-inference
template:
metadata:
labels:
app: gpu-inference
spec:
containers:
- name: inference
image: ubuntu:20.04
command:
- sleep
- infinity
ports:
- containerPort: 8080
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpucores: 50
nvidia.com/gpumem: 1000
requests:
nvidia.com/gpu: 1
nvidia.com/gpucores: 50
nvidia.com/gpumem: 1000
nodeSelector:
karpenter.sh/nodepool: g5-nodepool
Karpenter NodeOverlay (nodeoverlay.yaml)
apiVersion: karpenter.sh/v1alpha1
kind: NodeOverlay
metadata:
name: custom-devices
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g5.xlarge"]
capacity:
nvidia.com/gpu: "10"
nvidia.com/gpucores: "100"
nvidia.com/gpumem: "24000"
HAMi Mock Plugin (k8s-mock-plugin.yaml)
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: hami-mock-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
app.kubernetes.io/component: hami-mock-device-plugin
template:
metadata:
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
labels:
app.kubernetes.io/component: hami-mock-device-plugin
spec:
serviceAccountName: hami-mock-device-plugin
nodeSelector:
gpu: "on"
tolerations:
- key: CriticalAddonsOnly
operator: Exists
containers:
- image: mock-device-plugin
name: hami-mock-dp-cntr
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
command:
- ./k8s-device-plugin
- -v=5
- --device-config-file=/device-config.yaml
securityContext:
privileged: true
allowPrivilegeEscalation: true
capabilities:
drop: ["ALL"]
add: ["SYS_ADMIN"]
volumeMounts:
- name: dp
mountPath: /var/lib/kubelet/device-plugins
- name: sys
mountPath: /sys
- name: device-config
mountPath: /device-config.yaml
subPath: device-config.yaml
volumes:
- name: dp
hostPath:
path: /var/lib/kubelet/device-plugins
- name: sys
hostPath:
path: /sys
- name: device-config
configMap:
name: hami-scheduler-device
RBAC 配置 (k8s-mock-rbac.yaml)
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: hami-mock-device-plugin
rules:
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- update
- list
- patch
- apiGroups:
- ""
resources:
- pods
verbs:
- update
- patch
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: hami-mock-device-plugin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: hami-mock-device-plugin
subjects:
- kind: ServiceAccount
name: hami-mock-device-plugin
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: hami-mock-device-plugin
namespace: kube-system
测试流程
扩容阶段测试
1.部署 HAMi 和修复版本的 Mock Device Plugin
 |
2.配置 Karpenter NodeOverlay 和 NodePool
 |
 |
3.扩展 GPU 工作负载副本数,
kubectl scale deployment gpu-inference --replicas=34.观察 Karpenter 自动创建 GPU 节点
 |
5.验证 HAMi 调度器正确分配 GPU 资源
kubectl describe pod gpu-inference-86954f46ff-phljd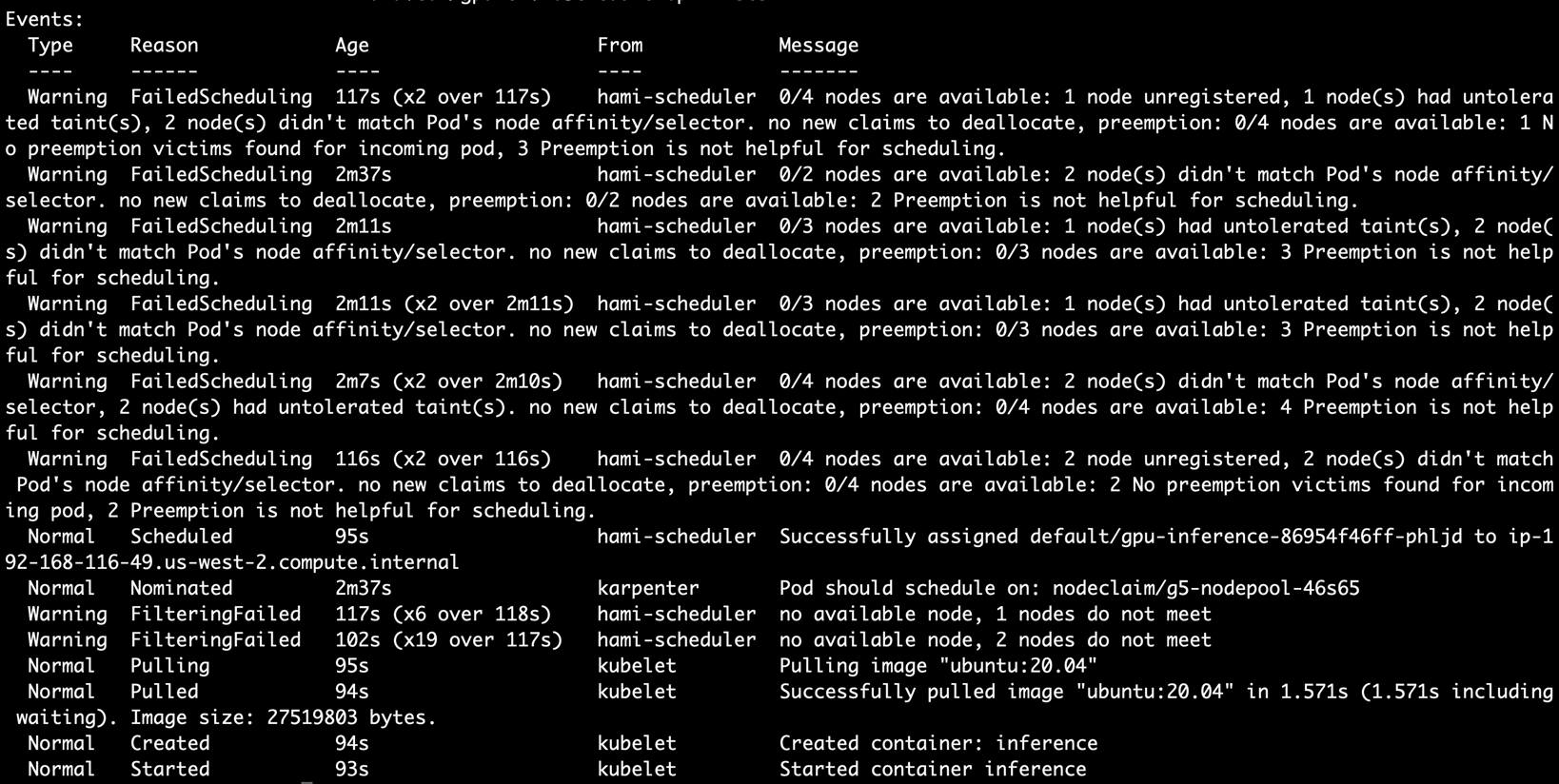 |
6. 观察node被mock plugin注册了Capacity 和Allocable资源(nvidia.com/gpucores,nvidia.com/gpumem)
kubectl describe node ip-192-168-116-49.us-west-2.compute.internal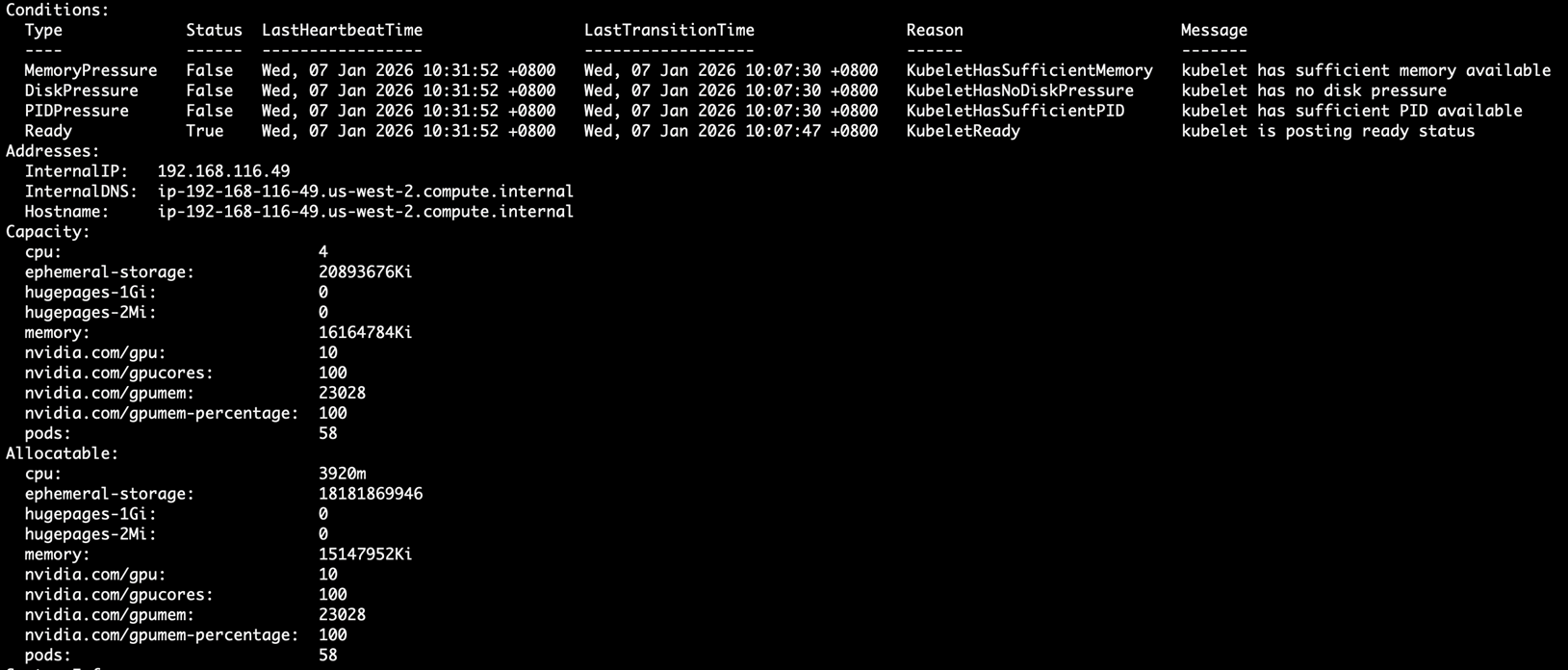 |
7.观察pod被成功扩展出来 :
kubectl get pod -owide  |
8.观察pod的GPU resource 分配情况
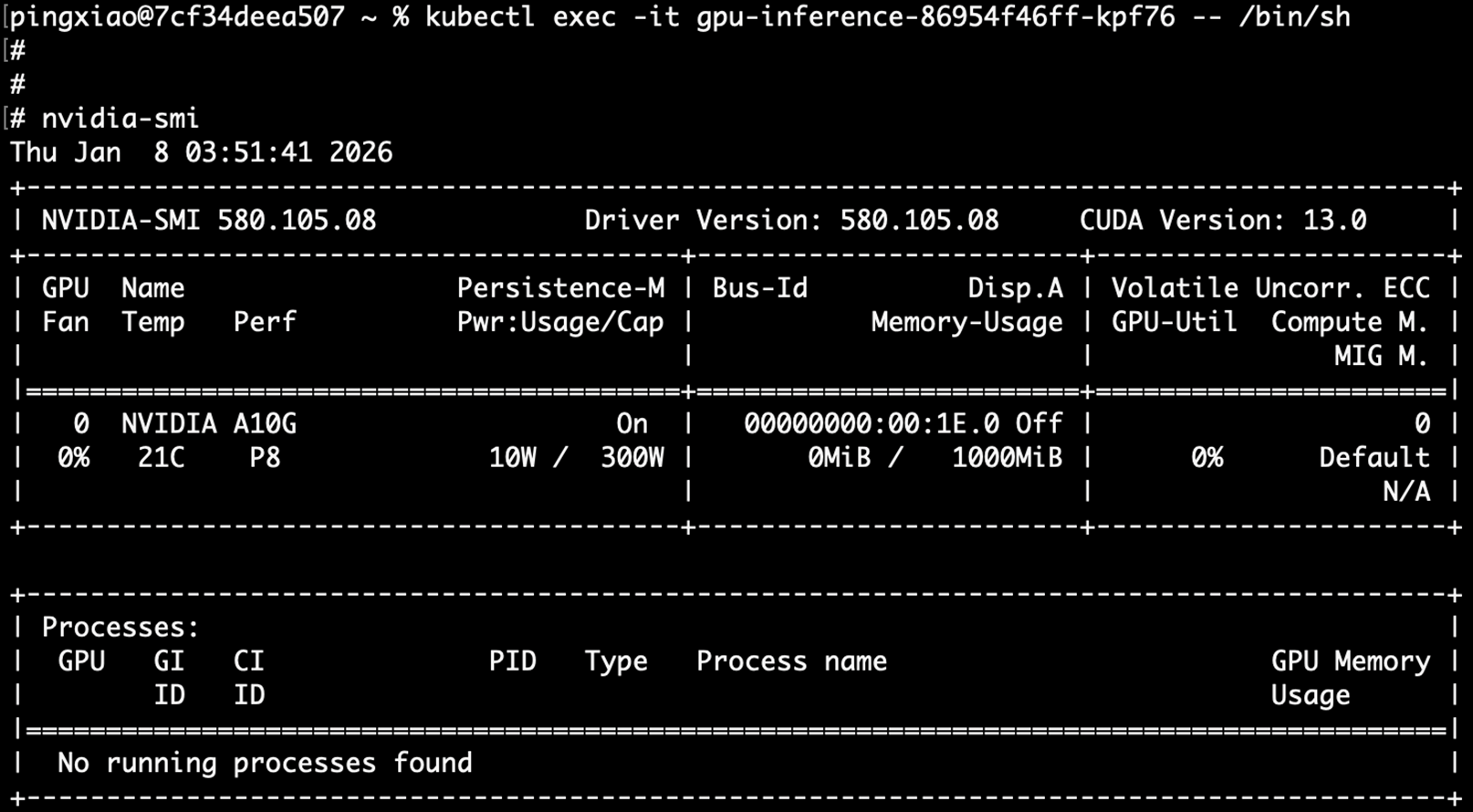 |
缩容阶段测试
1.减少工作负载副本数:
kubectl scale deployment gpu-inference --replicas=12.观察 Node状态变为 NotReady:
 |
3.观察 NodeClaim event 可以看到Karpenter正在删除instance:
kubectl get nodeclaim
kubectl describe nodeclaim <nodeclaim-name>
 |
4.验证 Karpenter 成功回收空闲节点,确认资源释放正确
 |
注意事项
潜在问题
- 资源计算精度:确保 NodeOverlay 中的资源配置与实际 HAMi GPU分片的规格匹配
- 标签一致性:NodePool 和 HAMi device plugin DaemonSet 的节点选择器标签必须一致,例如需要在Nodepool中在 NodePool 配置中添加 gpu: “on” 标签,使得HAMi调度器可以识别到GPU节点
- 网络策略:确保 Mock Device Plugin 能够访问 kubelet 的 Unix socket
- 权限配置:Mock Device Plugin 需要足够的 RBAC 权限来更新节点资源
最佳实践
- 监控告警:设置 NodeClaim 状态监控,及时发现初始化问题
- 资源预留:为系统组件预留足够的 CPU 和内存资源
- 成本优化:合理配置 Spot 实例比例和中断处理策略
- 测试验证:在生产环境部署前充分测试各种场景
- 日志收集:配置完整的日志收集,便于问题排查
- 备份策略:定期备份关键配置和状态信息
故障排查
常见问题及解决方法:
- NodeClaim 长时间处于 Unknown 状态:
- 检查 Mock Device Plugin 是否正常运行
- 验证节点注解是否正确设置
- 查看 kubelet 日志
- 扩容失败:
- 确认 NodeOverlay 配置正确
- 检查 FeatureGate 是否启用
- 验证实例类型可用性
- 资源分配不正确:
- 检查 HAMi 配置与 NodeOverlay 的一致性
- 验证设备插件注册状态
5. 结论与客户价值
通过 Karpenter 和 HAMi 的深度集成,我们实现了:
- 资源利用率提升:GPU 分片技术大幅提升集群资源利用率,改善传统方案中资源闲置的问题
- 成本显著降低:结合动态扩容/缩容和 Spot 实例策略,实现显著的计算成本削减
- 运维复杂度简化:自动化资源管理大幅减少人工运维工作量
- 响应速度提升:从手动扩容的小时级别缩短到分钟级别
这个集成方案特别适合以下场景:
- AI/ML 模型训练和推理:需要大量 GPU 资源的机器学习工作负载
- 科学计算:需要异构计算资源的科研项目
- 图形渲染:需要 GPU 加速的图形处理任务
- 数据分析:需要并行计算的大数据处理
这个集成方案为企业在云原生环境中高效利用 GPU 资源提供了完整的解决方案,是推动 AI 应用规模化部署的重要技术基础。通过解决传统 GPU 资源管理中的痛点,帮助企业在保证性能的同时大幅降低成本,加速数字化转型进程。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
