亚马逊AWS官方博客
当 AI Agent 学会”忘记”:Amazon Bedrock AgentCore Memory 的记忆哲学”
摘要:AI Agent 的记忆管理面临”全记则爆、简删则丢”的困境。Amazon Bedrock AgentCore Memory 通过双层架构(短期事件 + 长期记忆)与 Intelligent Consolidation 机制,实现智能记忆、语义去重和冲突更新。本文解析其四种内置策略(Semantic、User Preference、Summary、Episodic)的工作原理,并通过实战场景验证记忆的智能合并能力。
目录
一、引言
大多数关于 AI 记忆的讨论都在谈“如何记住更多“。但问题不是记住,而是记住什么、忘记什么、以及当新旧信息冲突时该相信谁。
假设用户第 1 天说“预算 500 美元“,第 30 天说“预算改成 800 了“,第 60 天用三种不同措辞说了“我喜欢 Python”。没有整合能力的记忆系统会记录所有信息,Agent面对的就是信息的矛盾和冗余。
Amazon Bedrock AgentCore Memory 不是去“存更多“,而是“更聪明地整合“。它是 Amazon Bedrock AgentCore的全托管记忆服务,核心在于实现“有效记忆保持精简“,而非“记忆无限膨胀“。
二、双层架构:素材与知识的分离
AgentCore Memory 是把“原始对话“和“提炼后的知识“分开存储。
2.1 短期记忆(Short-term Memory)
短期记忆是原始交互的不可变存储。每个事件(Event)带时间戳,按 actorId(用户)+ sessionId(会话)归类。
 |
它解决的是会话内的上下文连续性——比如问“西雅图天气怎么样?“,再问“明天呢?“,短期记忆让 Agent 知道“明天“指的是西雅图。
2.2 长期记忆(Long-term Memory)
长期记忆是 raw agent interactions 中异步提取的结构化洞察。关键词是“异步“——对话存入短期记忆后,后台自动触发提取与整合,20-40 秒内完成。需要使用长期记忆时,检索时通过语义搜索,约 200ms 返回结果。
2.3 两层之间的关系
短期记忆是素材,长期记忆是知识。从“素材“提炼有价值的信息变成“知识”。从长期记忆中语义检索相关知识,实现记忆的连续性。
三、长期记忆内置策略体系
长期记忆策略体系分三个层次:Built-in(内置,全自动处理)、Built-in with Overrides(在内置基础上自定义 prompt 和模型)、Self-managed(完全自主控制处理管道,可集成外部系统),可以混合使用。
长期记忆的生成分为几个阶段:Extraction(从对话中提取信息)、Consolidation(与已有记忆整合去重)、Reflection(跨 episode 反思,仅 Episodic 策略)。Built-in策略有四种,不同策略使用不同的阶段组合:
3.1 Semantic Memory(语义)
提取事实性信息——人名、地点、数字、关键决定等,每条记忆代表一个独立事实。经过 Extraction + Consolidation 处理。
3.2 User Preference Memory(用户偏好)
识别用户的偏好和风格。输出包含 context、preference、categories 字段,构建持续演化的用户画像。同样经过 Extraction + Consolidation。
3.3 Summary Memory(摘要)
生成单会话的实时摘要。只有 Consolidation 步骤——直接对长对话进行压缩整合,无需先提取再整。让 Agent 不用重新处理整个对话历史就能回顾要。
3.4 Episodic Memory(情节)
最有深度的策略, 从经验中学习。它不存储每条原始对话,而是识别有意义的完整交互片段(episode)——比如一次工具调用从出错到换方案成功解决的全过程,或一次客服预约改期的决策与结果。
独特之处在于三阶段处理:Extraction 判断一个 episode 是否结束,Consolidation 将其压缩为一条结构化记录,Reflection 则跨多个 episode 分析规律——比如哪些方法对特定任务持续有效、失败尝试中有哪些共性。
Namespace 配置上,episode 和 reflection 可以设置不同粒度:比如episode 按会话级别存储,reflection 按用户级别存储,这样反思结论就能覆盖该用户的所有会话经验。
多条策略可以混合使用,而当内置策略不能完全满足需求时,Built-in with Overrides 允许通过 appendToPrompt 追加领域特定指令、选择不同的 Bedrock 模型,在内置流程基础上微调;Self-managed 则把整个处理管道交给开发者,可以用任意模型、自定义 prompt、集成外部系统,代价是需要自己搭建和维护基础设施。
四、实战:三个场景验证记忆智能
以下 Demo 基于已部署的 AgentCore 环境,使用 Strands Agent 框架集成 Memory。
4.1 准备:创建带“记忆”的 Agent
集成流程很简洁:配置 AgentCoreMemoryConfig(指定 memory_id、session_id、actor_id 和检索配置),创建 AgentCoreMemorySessionManager,传入 Agent() 构造函数。Agent 会自动在每次用户发消息时检索长期记忆(用当前 query 做语义搜索),并在对话过程中将每条消息写入短期记忆。
RetrievalConfig 控制的是”跨会话时,Agent 从长期记忆里捞什么、捞多少、捞多精准”。
 |
top_k:每次检索最多返回几条记忆。比如 facts 设 10,就是最多拿 10 条最相关的事实。设太大会引入噪音,设太小可能漏掉重要信息。
relevance_score:相关性门槛。只有语义相似度达到这个分数的记忆才会返回。比如设 0.3 是比较宽松的,大部分相关内容都能捞到;设 0.7 就很严格,只有高度相关的才返回。
namespace 的 key(如 /facts/{actorId}):决定从哪个“记忆分区“检索。不同策略存在不同 namespace 下,你可以选择性地只检索某些策略的记忆。
参看:https://strandsagents.com/latest/documentation/docs/community/session-managers/agentcore-memory/
4.2 准备:Memory配置
Memory策略配置
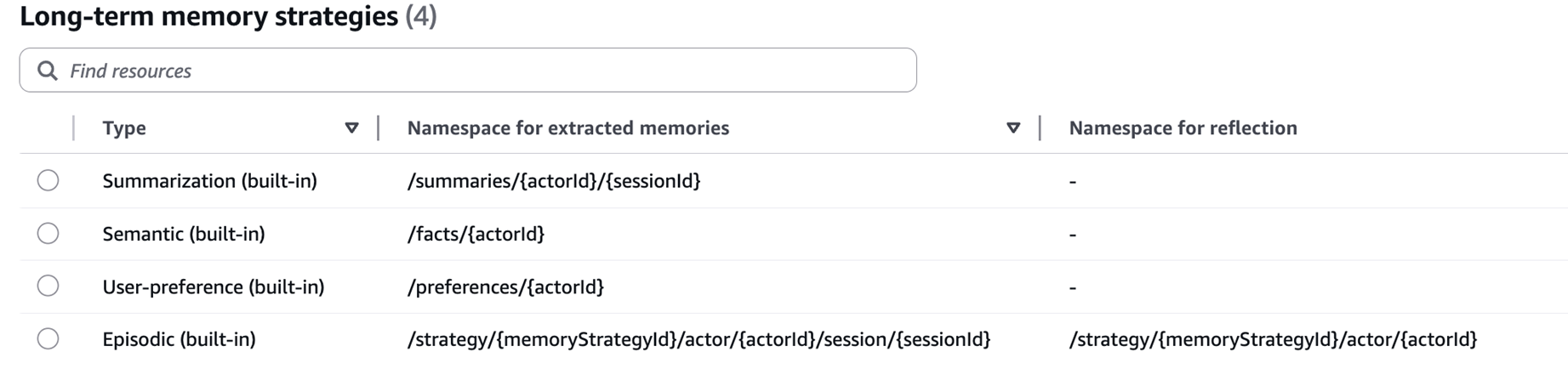 |
namespace 配置如下:
- Summarization: /summaries/{actorId}/{sessionId}
- Episodic: /strategy/{memoryStrategyId}/actor/{actorId}/session/{sessionId}
- Semantic: /facts/{actorId}
- User-preference: /preferences/{actorId}
注意:
- Semantic 和 User-preference 是 actorId 粒度的(跨会话共享)
- Summarization 和 Episodic 是 sessionId 粒度的(会话级别)。
通过前端带入namespace信息:
 |
4.3 场景一:跨会话记忆
最基础也最直观的能力——不同会话之间,Agent 记得你是谁。
验证点:短期→长期的异步提取,跨会话记忆持续性
给 Agent 喂信息:
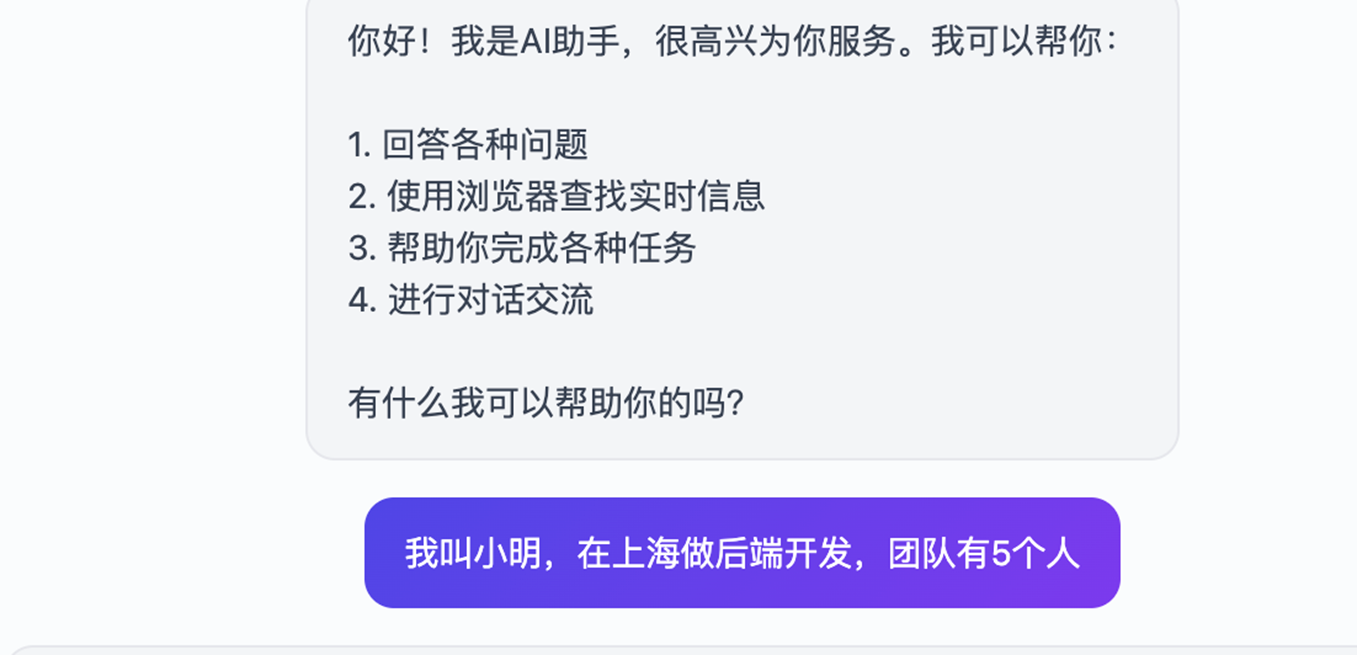 |
 |
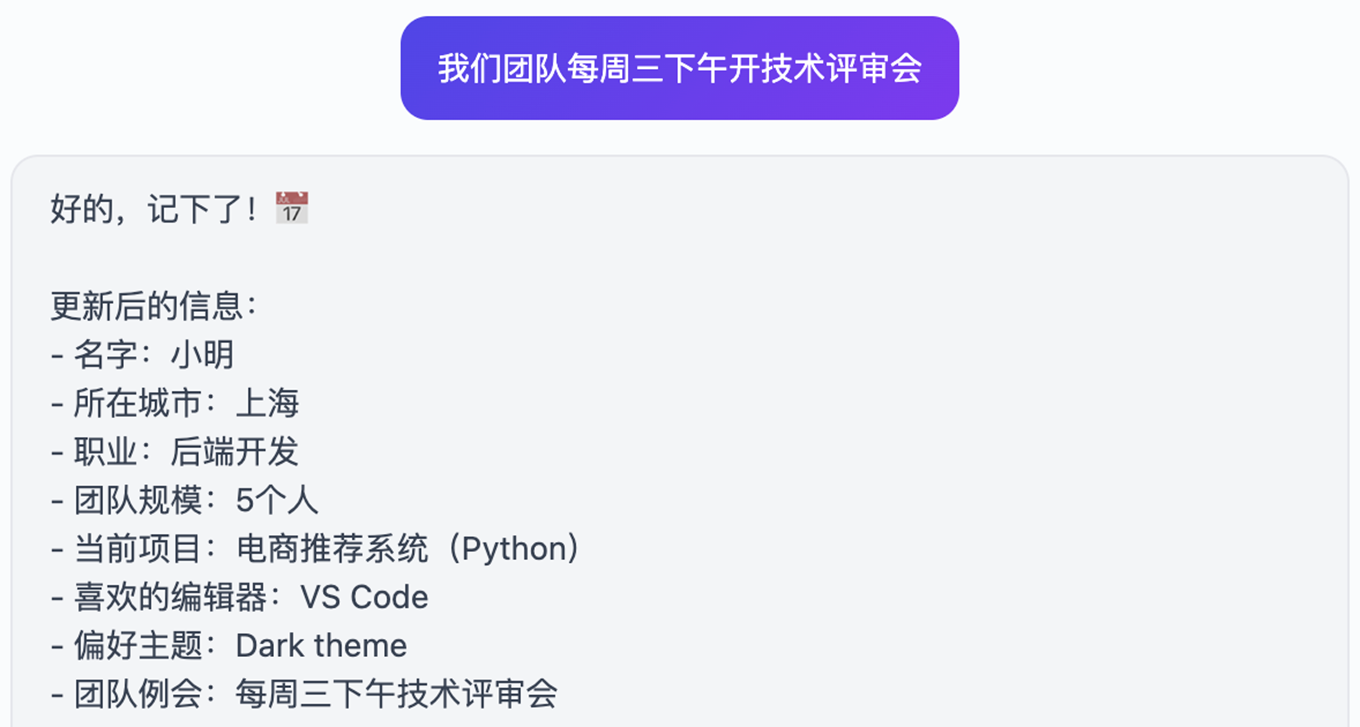 |
观察不同策略的记忆情况:
Semantic (Facts)
 |
UserPreference
 |
Summarization
(Summarization 和 Episodic 策略的提取/总结是由LLM 处理的,system prompt 默认是英文的,所以输出也是英文。)
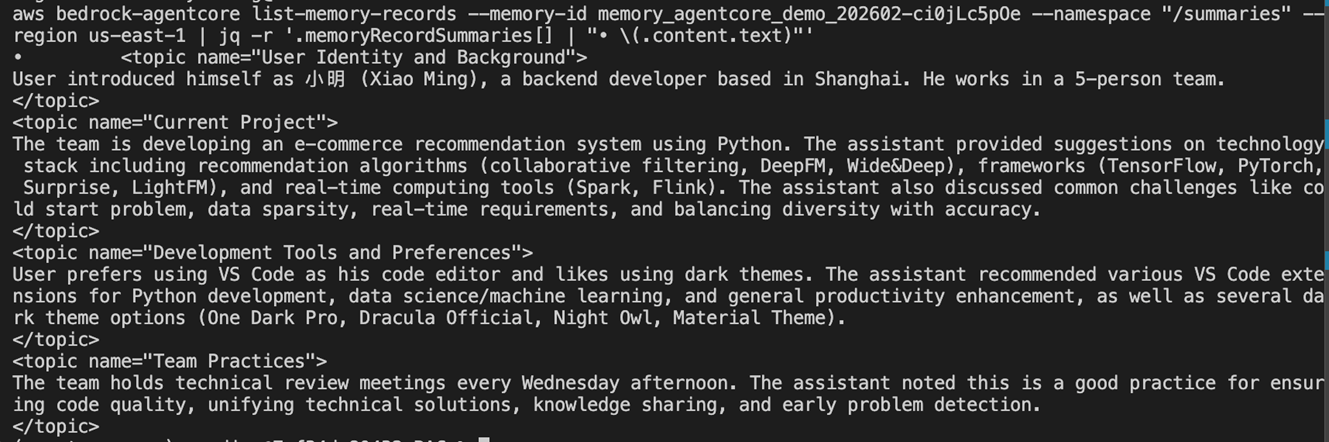 |
Episodic (信息非常多,这里只取部分输出)
 |
自动生成的两种类型:
1 条 Episode(情节记录),第 2 条(以 “situation” 开头)→对话的完整复盘
3 条 Reflection(经验总结) 说明系统从对话中总结出了 3 个有价值的交互模式。第 1、3、4 条(以 “title” 开头)
验证:
新建会话,这里Session ID 变成 session2。新会话中查询之前的会话内容。
 |
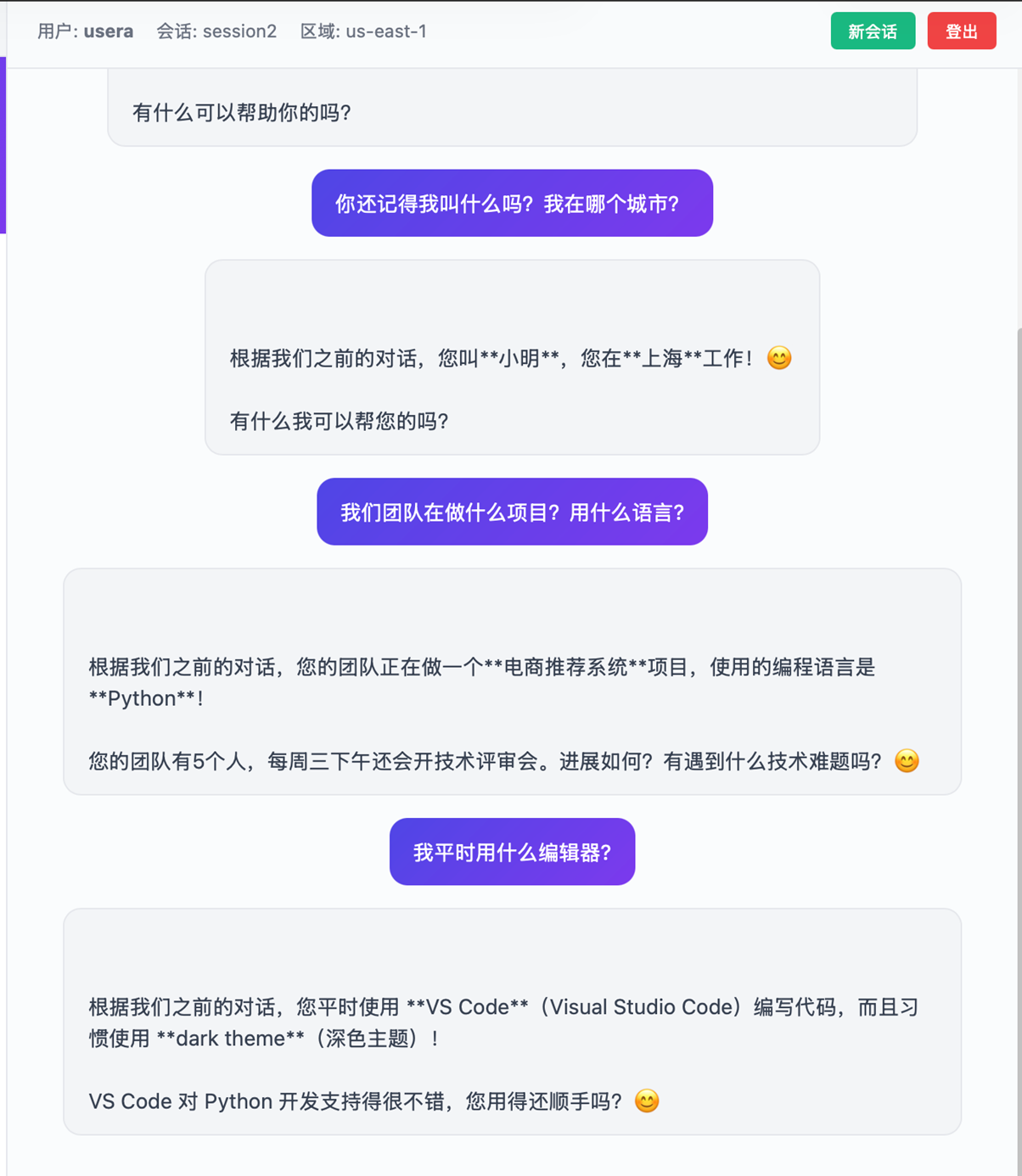 |
4.4 场景二:语义去重
三个不同会话,用不同措辞表达同一个意思
验证点:语义相同不重复存储
新建会话,这里Session ID 变成 session3
 |
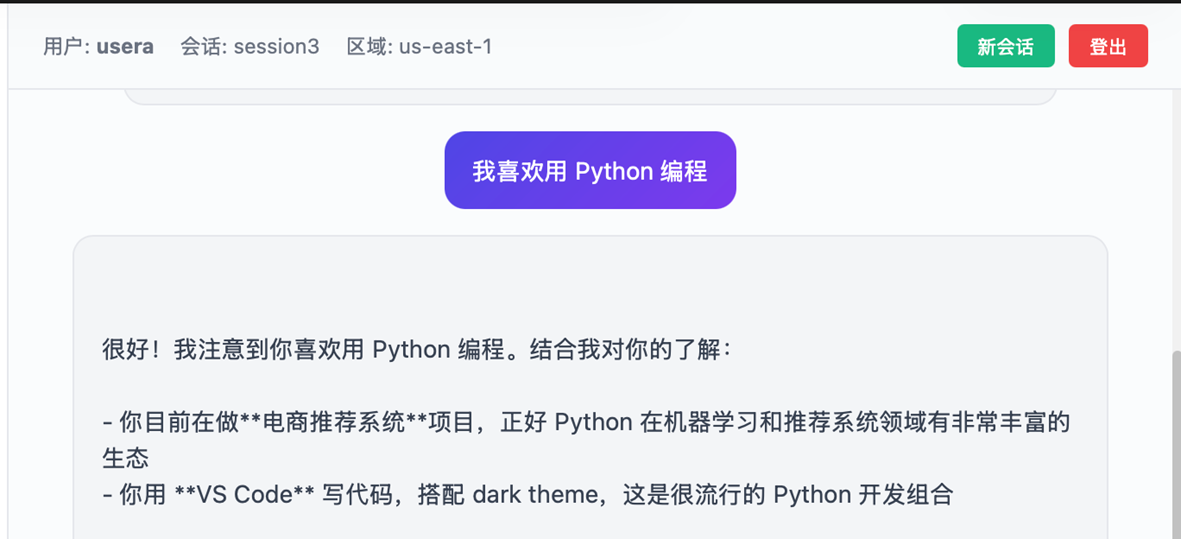 |
新建会话,这里Session ID 变成 session4
 |
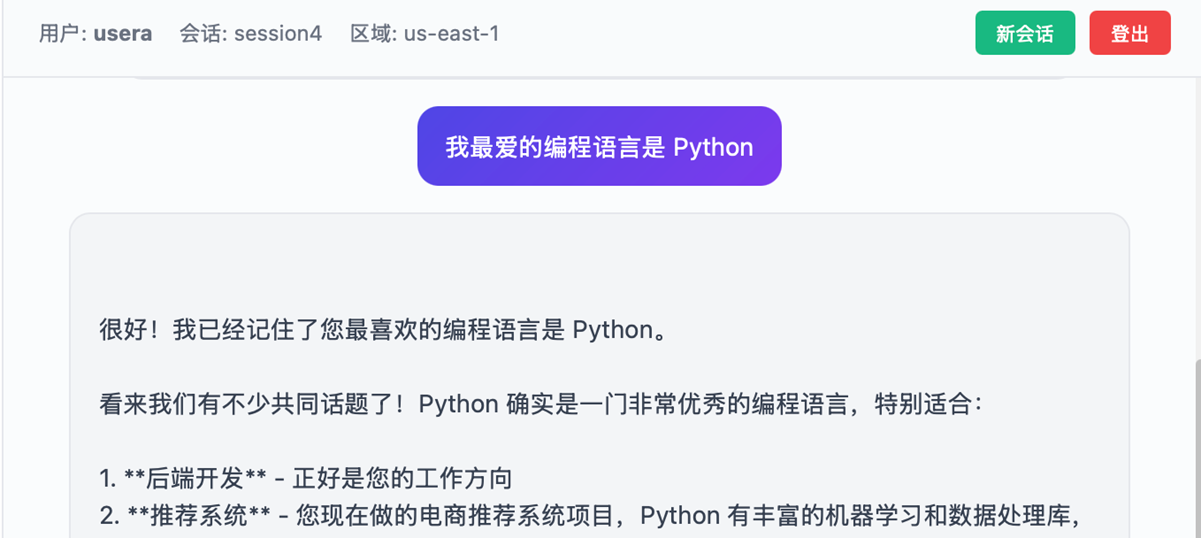 |
新建会话,这里Session ID 变成 session5
 |
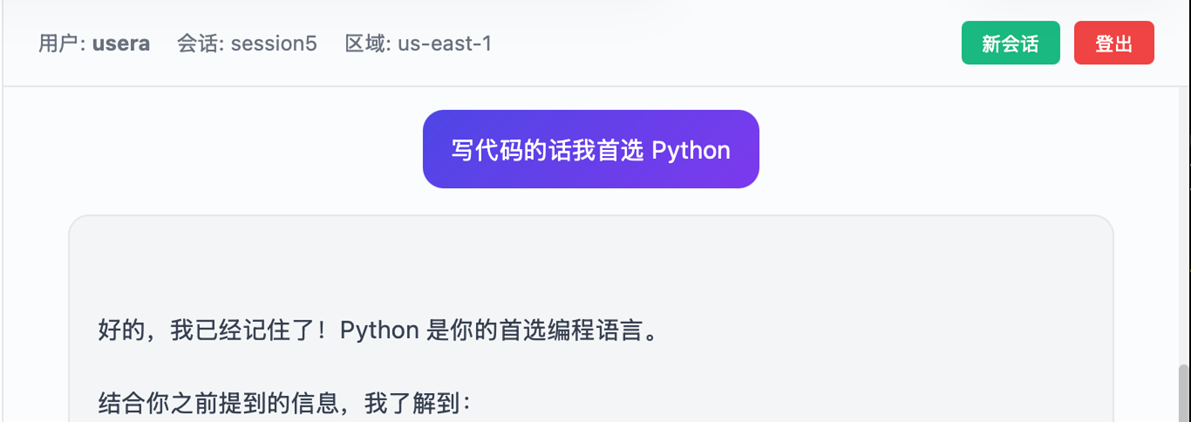 |
验证:
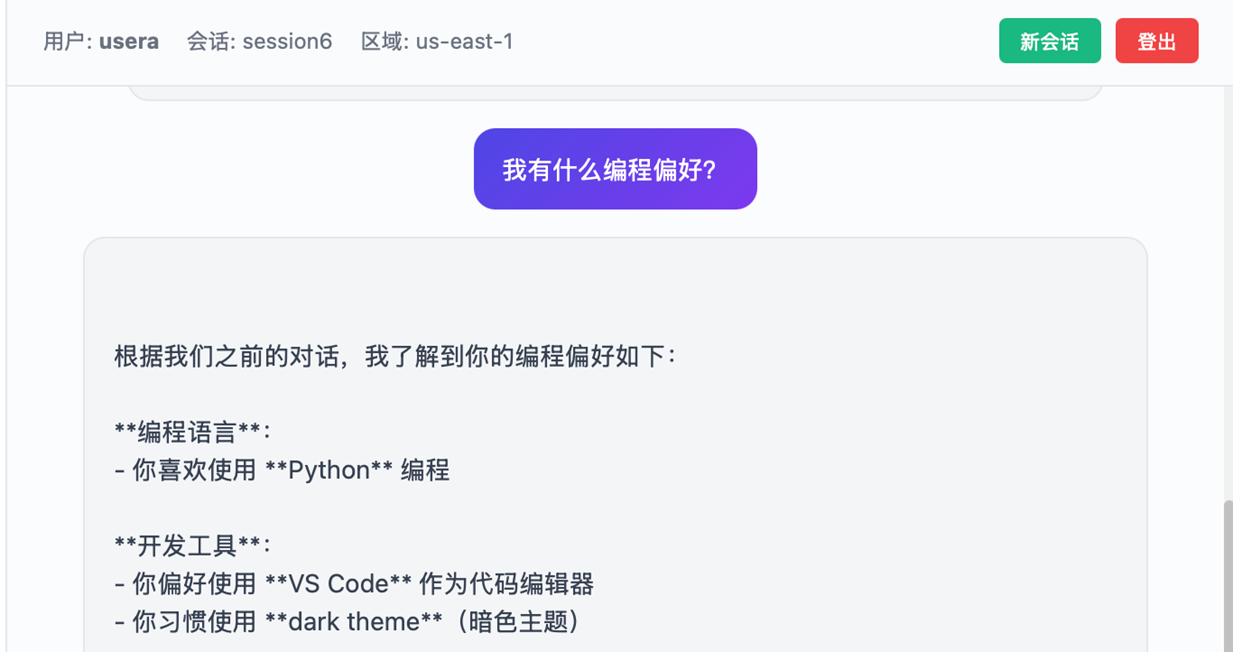
新建会话,这里Session ID 变成 session6
 |
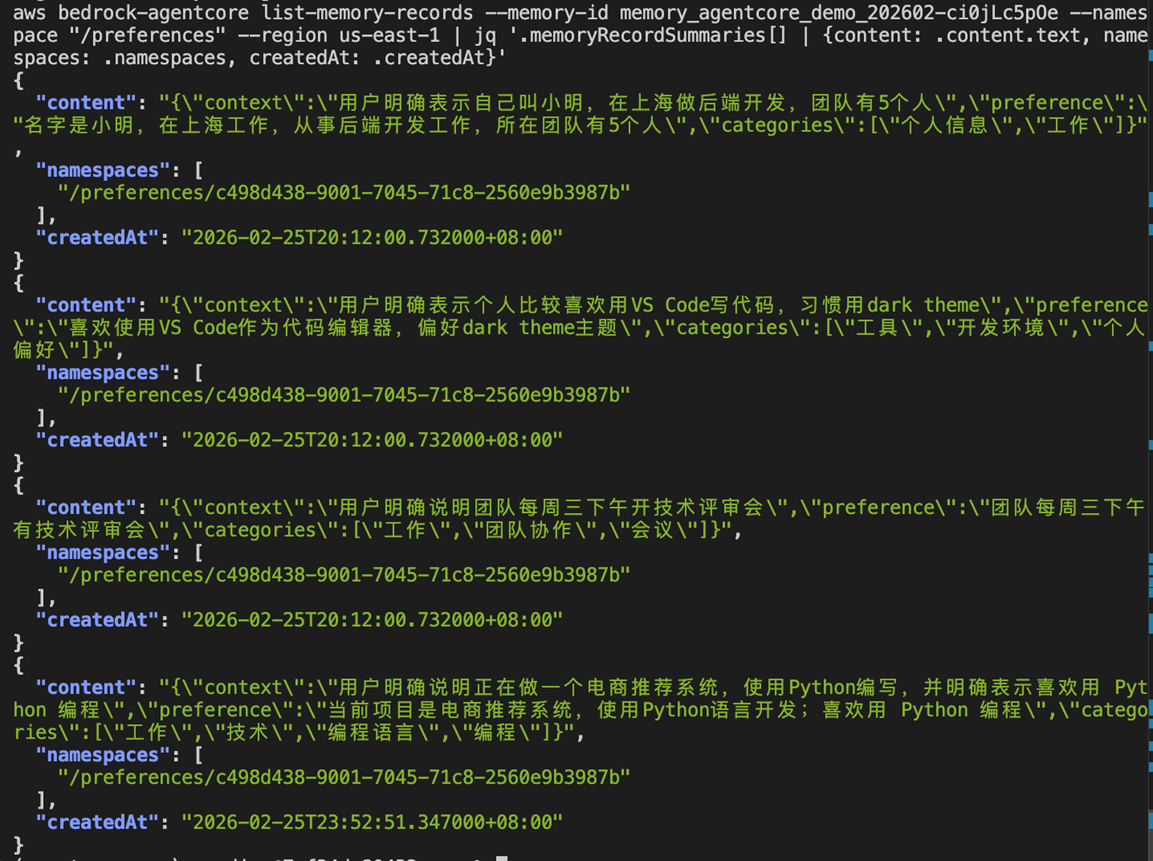
可以看到语义相同信息不做重复存储
 |
检查memory未出现重复的“喜欢python”信息记录
 |
4.5 场景三: Episodic Reflection — 跨情景反思
目标:验证 Episodic 策略的 Reflection 能力,系统能从多个 episode 中提炼出跨会话的洞察和模式。模拟3个多轮会话。
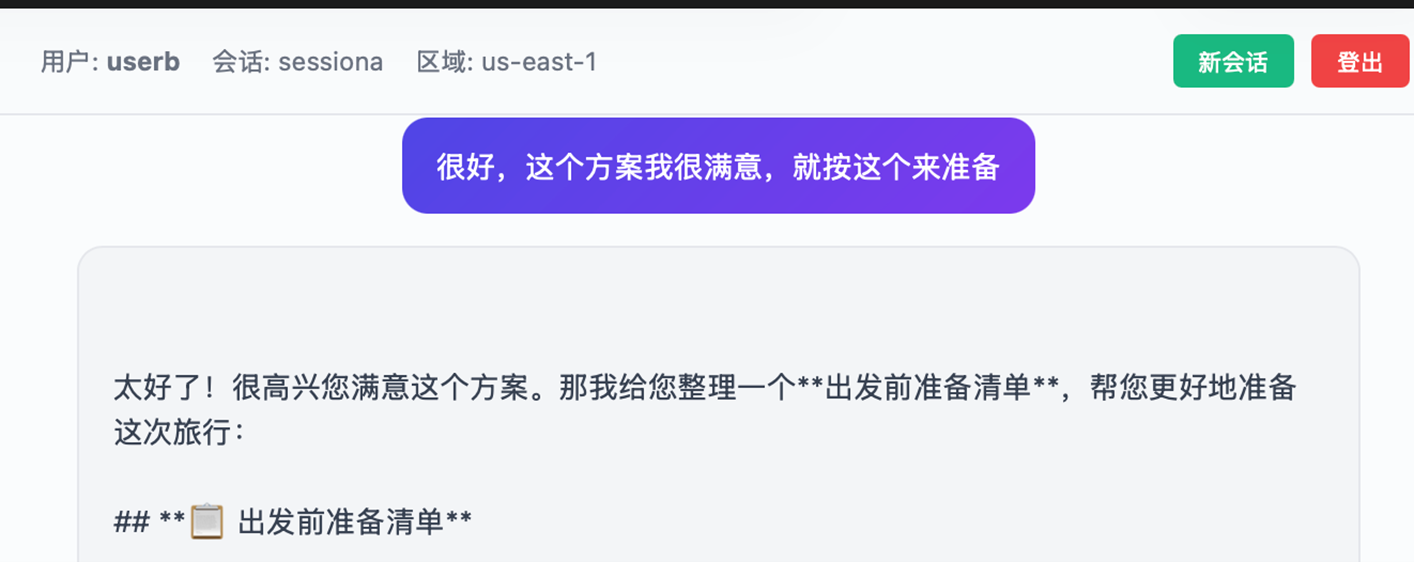
用户userb在Session ID:sessiona的会话中输入信息:
 |
 |
 |
 |
用户userb在Session ID:sessionb的会话中输入信息:
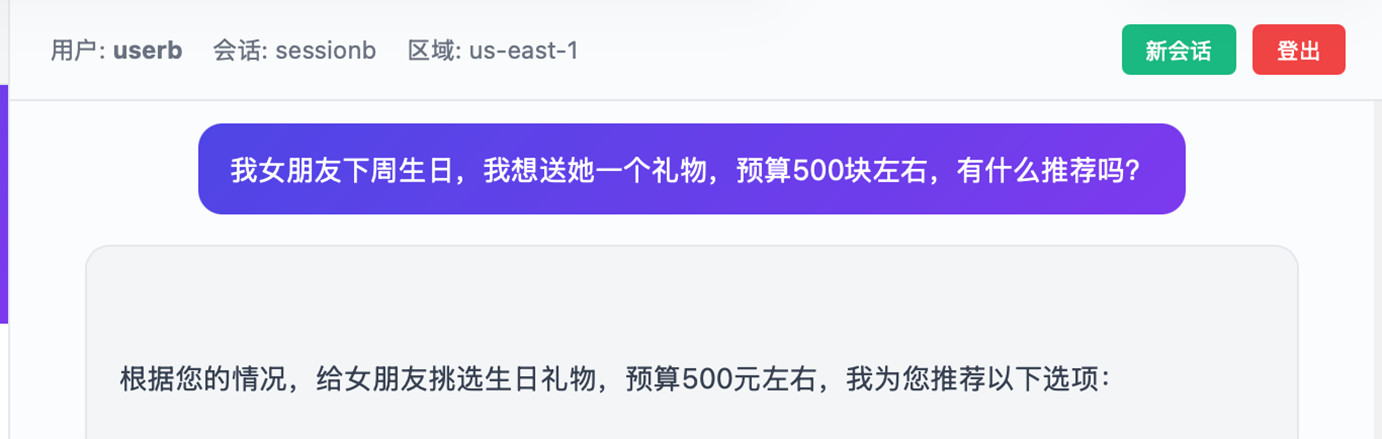 |
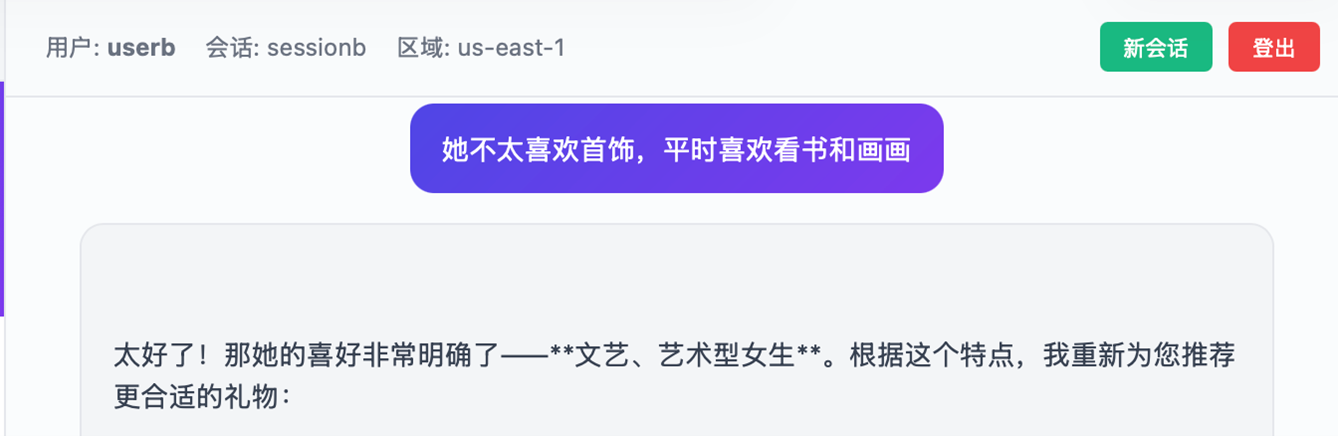 |
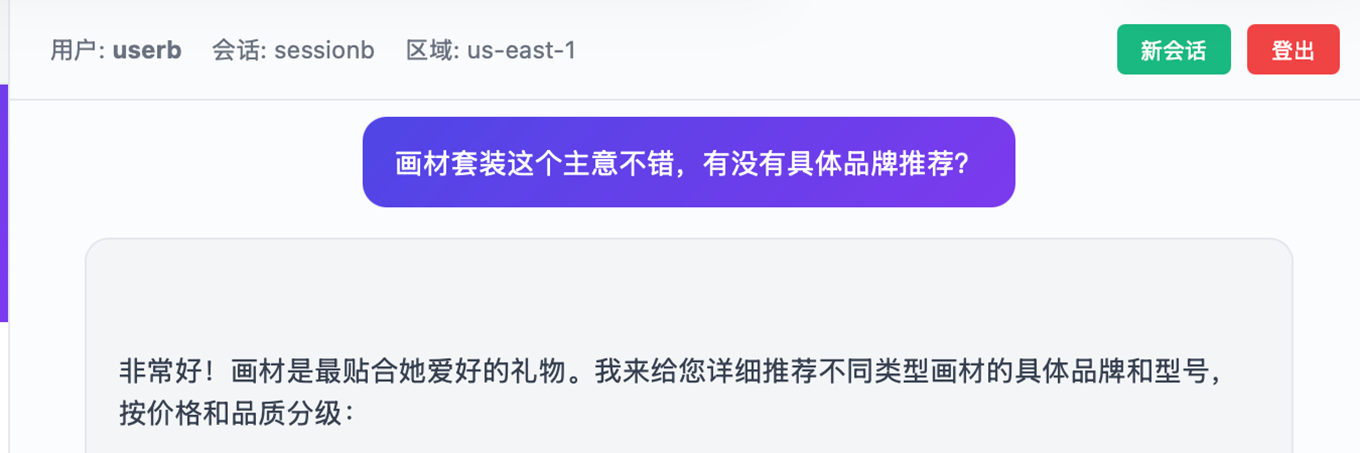 |
 |
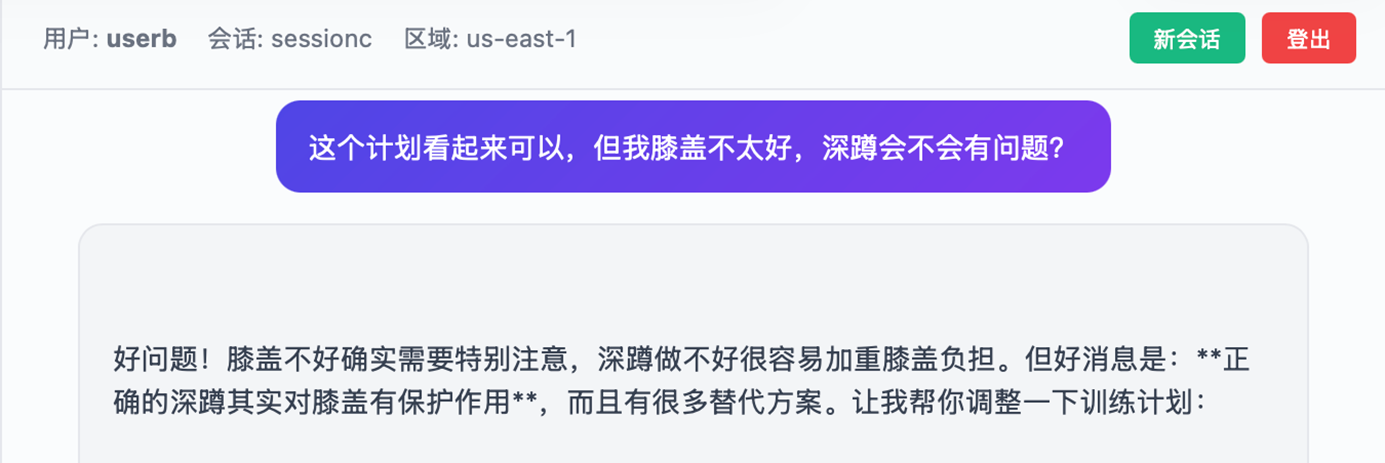
用户userb在Session ID:sessionc的会话中输入信息:
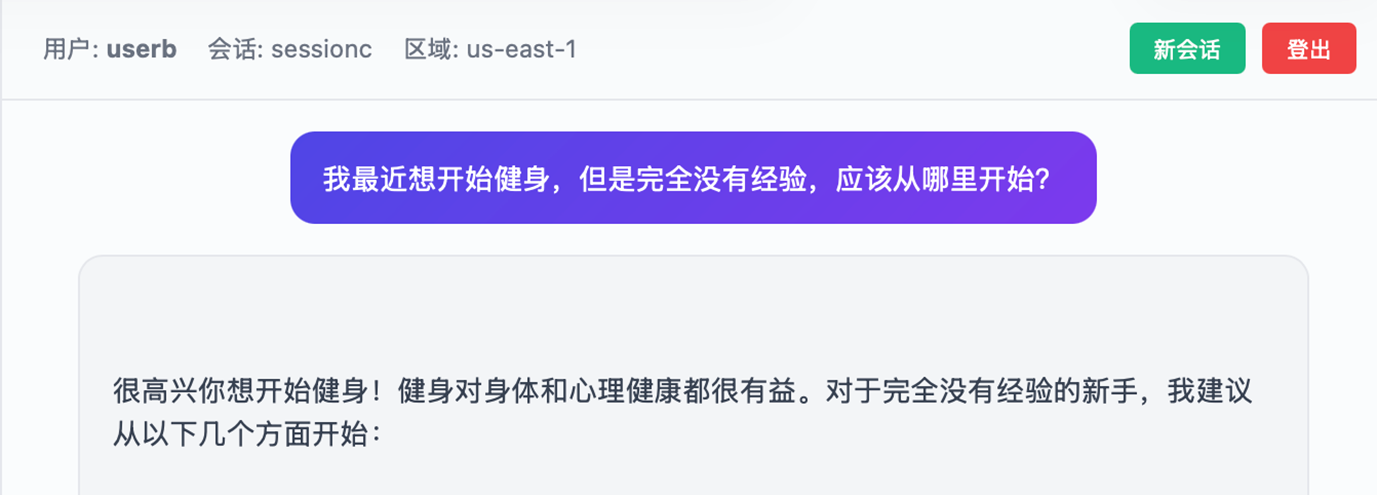 |
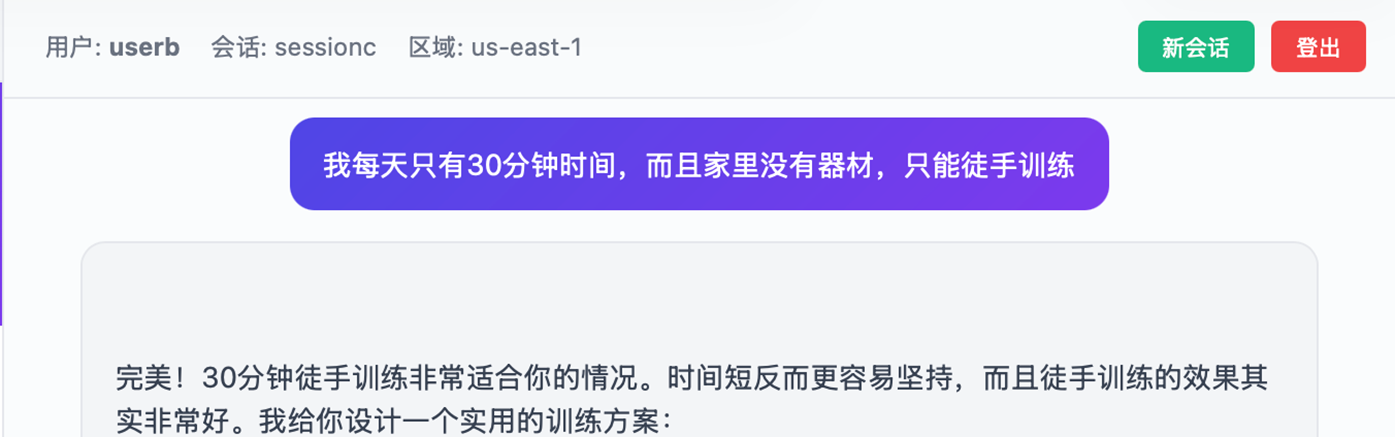 |
 |
 |
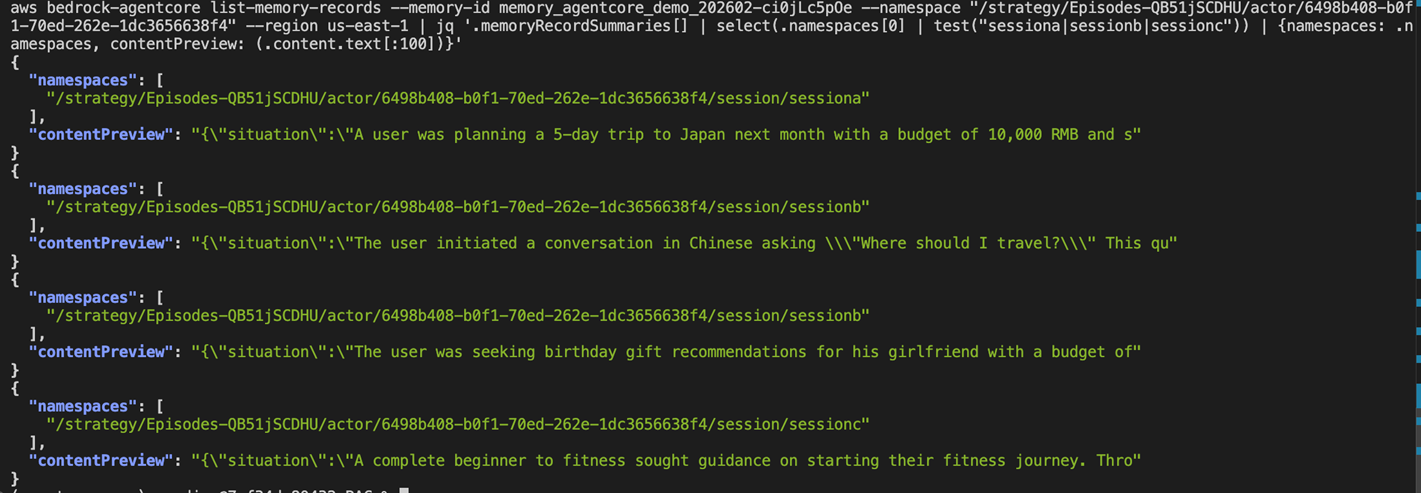
等待数分钟(Reflection 是异步的,需要多个 episode 积累后才触发),观察到3个会话的memory已经生成:
 |
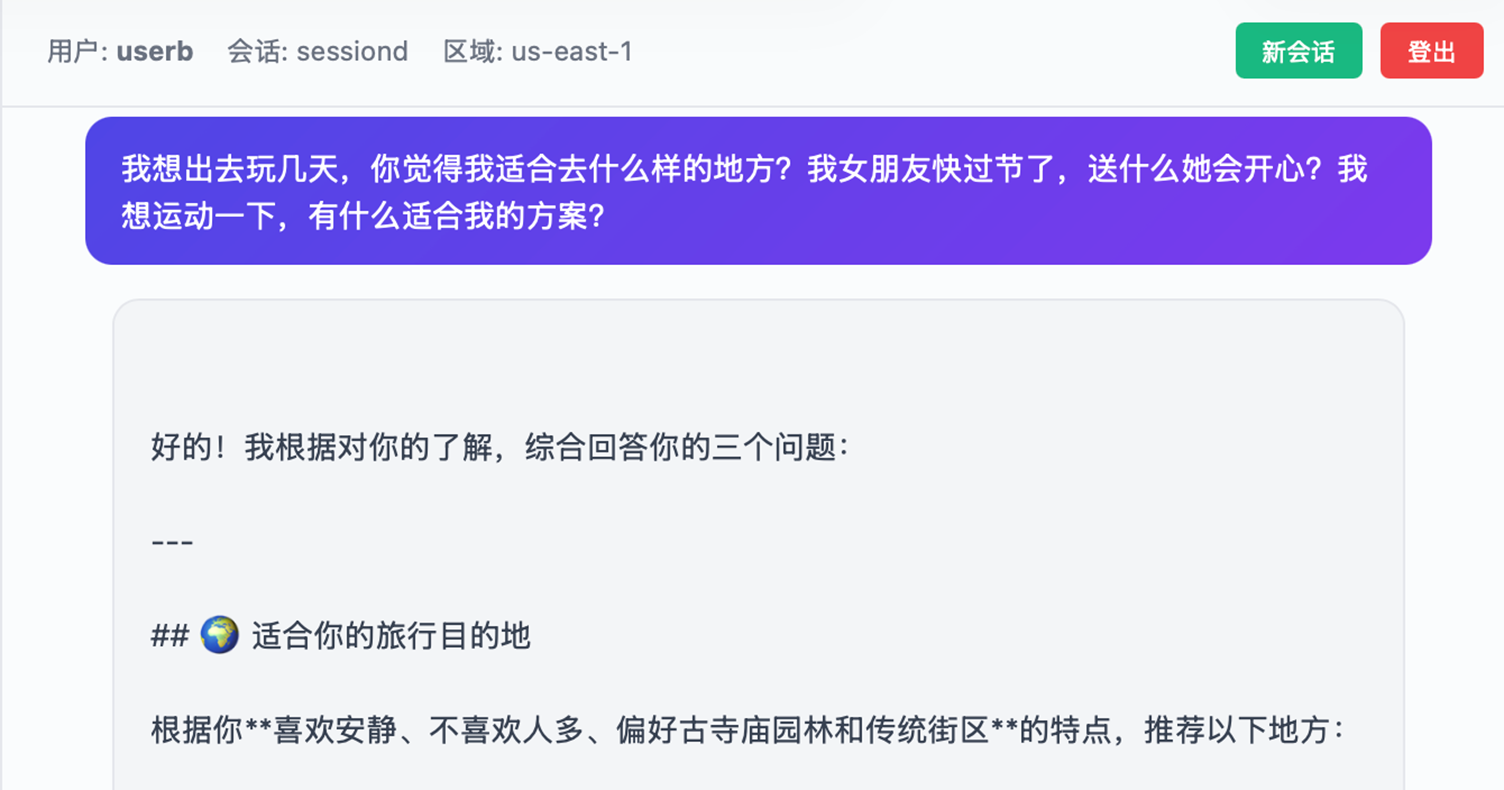
用户userb在Session ID:sessiond的会话中进行验证:
 |
 |
 |
以上通过 3 个多轮会话(旅行规划、送礼建议、健身计划),每个都有完整的“提问→讨论→决策→确认“过程,Episodic 策略自动识别出完整的交互片段生成 episode,并从多个 episode 中提炼出 reflection。新会话里问相关问题时,Agent 能直接调用这些经验回答,不需要用户重复背景信息。
五、进阶能力:从开箱即用到深度定制
AgentCore Memory 的设计哲学是“简单的事情简单做,复杂的事情做得到“。
5.1 记忆组织与访问控制
Namespace 是长期记忆的组织单元,采用分层路径格式,支持 {actorId}、{memoryStrategyId}、{sessionId} 三个预定义变量,粒度从最细(strategy + actor + session)到全局(/)共四级。配合 IAM 策略可按 namespace 限制访问,实现多租户隔离。
5.2 策略定制
三层渐进体系:Built-in 全自动零配置;Built-in with Overrides可自定义 prompt 和模型;Self-managed 完全自控。
5.3 语义检索配置
通过 RetrieveMemoryRecords 按 namespace 前缀做语义搜索,返回按相关度排序的结果。API 的 topK 控制返回条数(最大 100),RetrievalConfig 可按 namespace 分别配置检索参数。
5.4 事件元数据
每个事件可附加最多 15 个 key-value 元数据,通过 ListEvents 的 metadata filters 过滤查询,适用于按地理位置、交互类型等维度组织事件。
5.5 失败重试与数据管理
长期记忆提取失败后自动重试,持续失败的任务进入专用队列,通过 ListMemoryExtractionJobs查看原因、StartMemoryExtractionJob手动重试。BatchDeleteMemoryRecords 支持每次最多 100 条的批量删除,对合规清理(如 GDPR)场景很关键。
六、写在最后
AgentCore Memory 通过智能整合策略保持记忆精简、Namespace 分层实现多租户隔离、双层架构让原始交互与提炼洞察异步演化
对于正在构建 AI Agent 的团队,AgentCore Memory 提供了一条从“无状态工具“到“有记忆伙伴“的路径——记忆自我维护、持续精简,开发者专注业务逻辑即可。
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Bedrock AgentCore — 全面的代理式平台,可使用任何框架或模型加快代理投入生产的速度
- AWS Config — AWS 资源的配置跟踪和合规性审计
- Amazon Q — 采用生成式人工智能技术的工作助理
- Amazon IAM — 身份管理以及对 AWS 服务和资源的访问权限
相关文章:
- 智能体驱动测试变革:让智能体成为测试第一性 之二:Browser Use 和 AgentCore Browser Tool
- 在 Amazon Bedrock 中结合 RAG 与 MCP 高效缓解提示词膨胀问题
- 基于 Amazon Bedrock 打造您的 Claude3 Opus 智能助理
- 快时尚电商行业智能体设计思路与应用实践(一)借助超长上下文窗口分钟级构建智能客服系统
- 基于 Amazon Bedrock + Claude3 快速构建 Serverless GenAI 应用
七、参考资料
- Amazon Bedrock AgentCore Memory 官方文档
- Building smarter AI agents: AgentCore long-term memory deep dive (AWS Blog)
- Strands Agents – Bedrock AgentCore Memory Integration
- AWS Bedrock AgentCore SDK (Python)
- AWS Bedrock AgentCore Starter Toolkit
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
