关键方法
相比较于传统的 RAG 方案,Bedrock Knowledge Base 内置了很多调优能力,灵活使用这些方法进行调优,是实现生产级别 RAG 的关键。接下来先介绍一下各种调优方法的原理以及能力范围,为后面实操教程铺平理论基础。
-
查询:"How to file a claim in Washington"
-
自动生成的过滤条件:"state = Washington"
-
最终检索的文档:仅包含 Washington 州相关的文档,而非全国范围的所有索赔指南。
元数据过滤是一种在检索前缩小搜索范围的有效方法。通过为每个文档添加结构化的元数据标签(如主题、时间、作者等),我们可以在执行语义搜索之前先基于元数据标签做一次预筛选。
特别地,Amazon Bedrock Knowledge Base目前支持自动生成查询过滤(Auto-Generated Metadata Filtering),扩展了手动元数据过滤(Manual Metadata Filtering)的功能。该功能可自动识别查询中的关键属性,并智能应用元数据筛选条件。用户可以在不手动构建复杂过滤规则的情况下,自动筛选出高相关性的文档,从而优化 RAG系统的整体表现。
例如:
如若文档本身有置信度高的、贴合业务的元数据标签,可以考虑此种优化思路。
排序是一种后处理技术,用于在初始向量检索之后,通过更复杂的评分机制对 Top-K 检索结果进行重新排序,以提升最终返回内容的精准度与相关性。那可能会个问题,既然向量检索就已经包含了语义匹配,为什么还需要一遍重排序呢?类比一下日常,向量检索就像是招聘的时候进行简历筛选,需要从大量备选项中快速找到相关的内容。而重排序就像是通过简历筛选之后的候选人面试,成本较高速度较慢,但是可以更准确全面的进行评估。通过向量检索和重排序的双重筛选,检索出的结果会更加的符合我们的需要。
Amazon Bedrock Knowledge Base 内置 Rerank 模型,可自动对检索结果进行重新排序,确保最相关的文档排在前面。该模型利用 深度语义匹配 (Deep Semantic Matching) 技术,以更精细的方式计算 查询与文档之间的匹配度,相比于仅基于向量相似度的检索方式,能够提供更高质量的结果。
分块策略对 RAG 系统的性能至关重要。分块的数据质量越高,数据的组织结构越清晰,信息的可检索性越强。反之,若知识库中的信息密度较低,回答一个问题可能需要引用多个文本块,从而在 LLM 的上下文窗口中插入更多文本。这不仅增加了 token 的消耗和计算成本,还可能导致关键信息因湮没在大量文本中而被稀释,使得LLM 失焦。
所以,清洗数据在构建知识库中十分重要,降低与业务无关信息出现在知识库中的可能性。此外,为了提高数据块的信息密度,可以考虑利用 LLM 作为事实提取器,从原始文档中筛选和提炼关键信息。但是这种方法存在一定的风险,在提纯过程中可能导致部分关键信息的丢失。因此,在优化信息密度的同时,需要在数据完整性与精炼度之间寻求平衡。
-
阿根廷队在 2022 年 FIFA 世界杯决赛中进了多少球?
-
2022 年 FIFA 世界杯决赛中法国队进了多少球?
查询重写是一种从客户的查询入手,以优化 RAG 性能的策略。旨在通过改写、扩展或分解用户查询,提高检索系统的召回率和准确性,确保重写后的用户问题能够更贴合、更匹配知识库中的文档。Amazon Bedrock Knowledge Base 支持 Query Decomposition(查询分解)是查询重写的一个子类。具体做法是:先将复杂查询拆解为多个子查询,并分别检索相关内容;之后动态组合子查询的结果,生成更全面的答案。
例如,针对查询 "2022 年 FIFA 世界杯上谁得分更高,阿根廷队还是法国队?",Amazon Bedrock 知识库可能会首先生成以下子查询,然后再生成最终答案:
通过拆分长查询,分别搜索再整合答案,提高对复杂问题的支持能力。
实施步骤
一、设置请求访问模型
Amazon Bedrock 用户需要先请求访问模型,然后才能使用模型。 如果您想要添加用于文本、聊天和图像生成的其他模型,您需要请求访问 Amazon Bedrock 中的模型。请注意,只有具有所需 IAM 权限的用户才能管理此帐户的模型访问权限。
1. 登录控制台并选择 AWS 部署区域
登录您的亚马逊云科技账户,进入管理控制台,在控制台右上角选择您方案部署的区域。这里我选择了 us-west-2 进行实验演示。
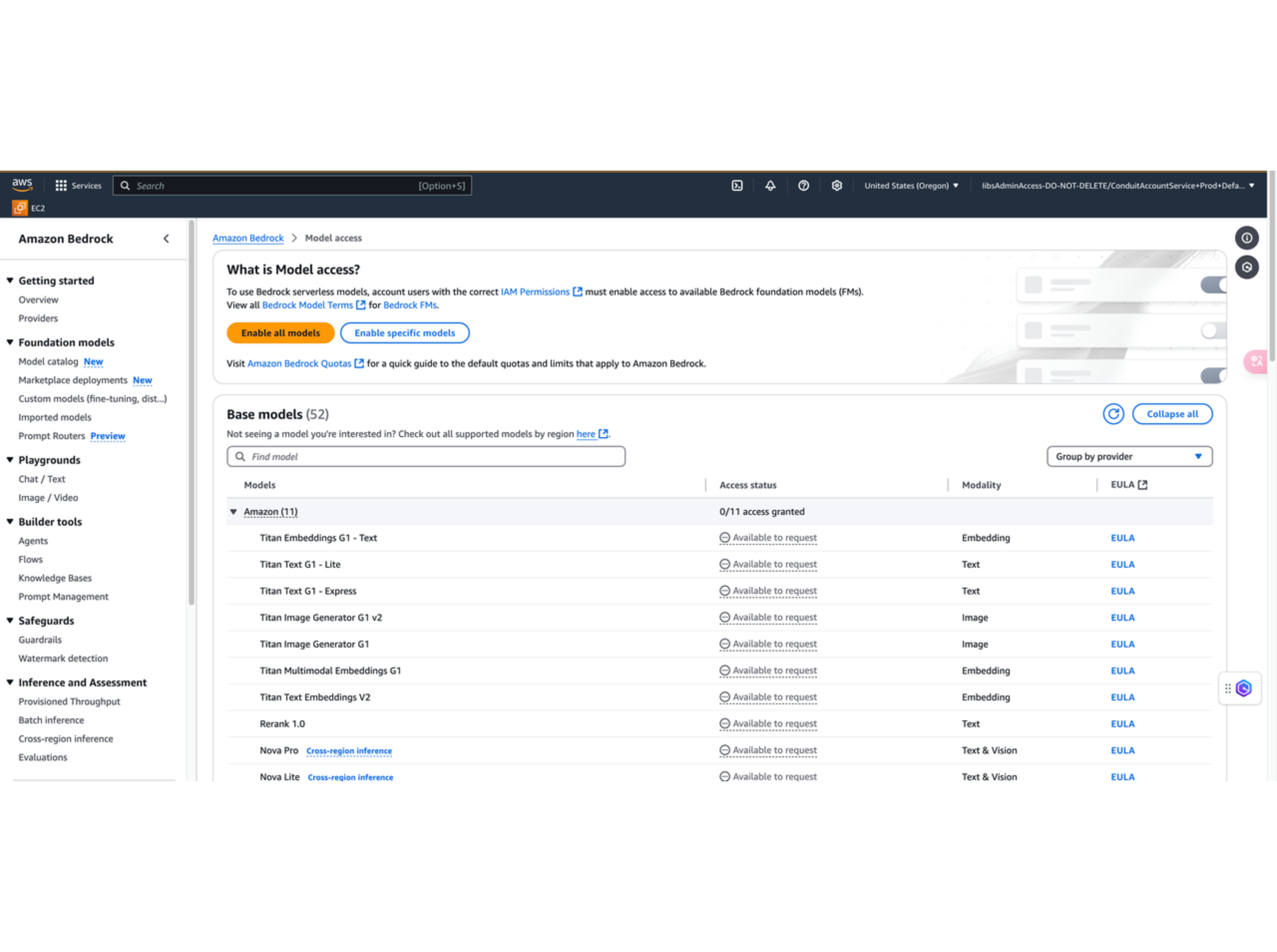
2. 访问 Amazon Bedrock 控制台
点击控制台的查找框,搜索 Amazon Bedrock,进入 Amazon Bedrock 的控制台界面,找到下图所示的 Model access ,点击 Enable specific models。
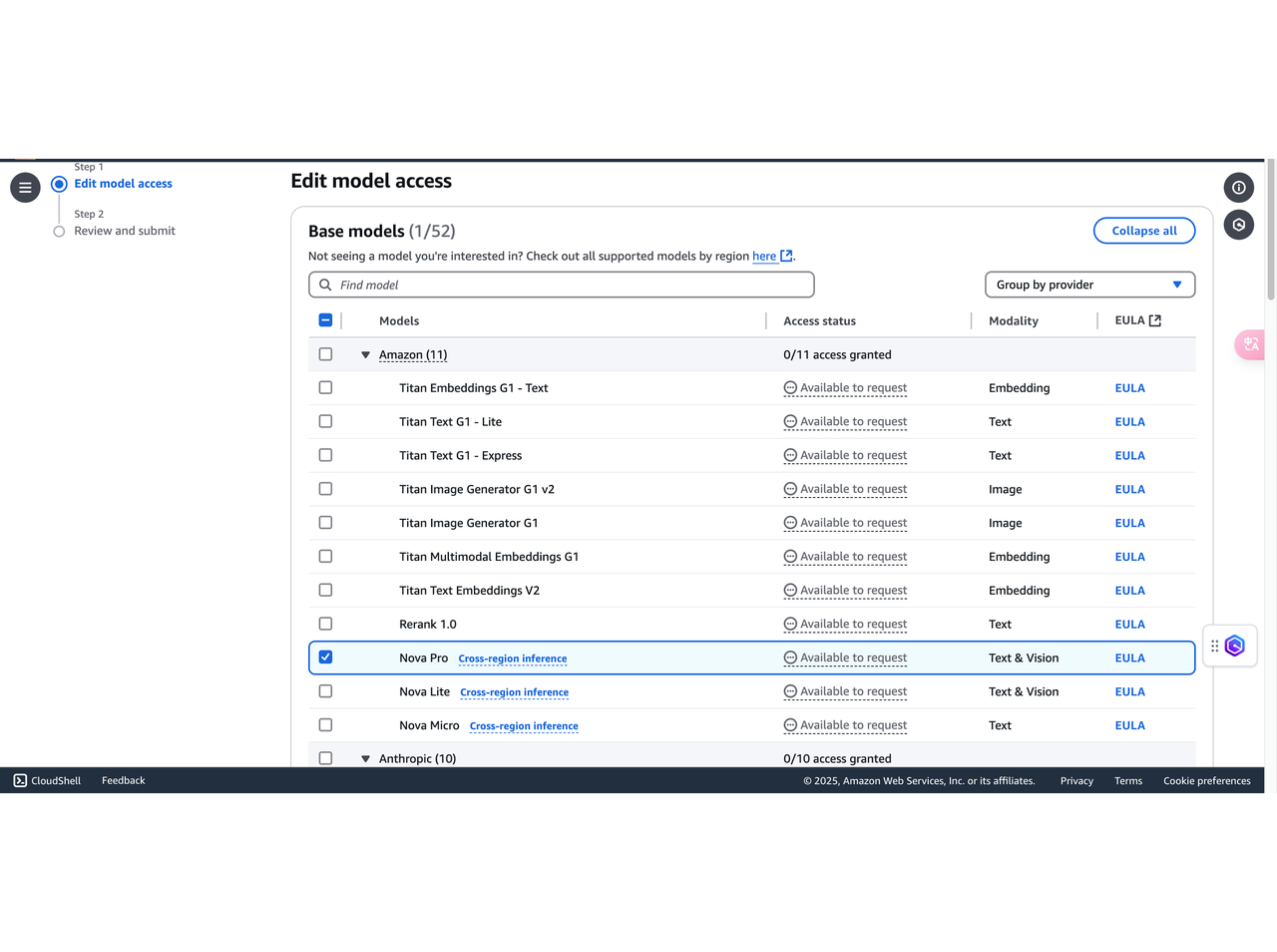
3. 启用 Amazon Nova Pro 模型
可以看到 Amazon Bedrock 提供的模型,勾选我们需要的模型,并滚动到底部点击右下角的 Submit。设置好请求访问模型后,模型即刻便可访问。本次实验主要会用到 Amazon Nova Pro
二、知识库文档准备
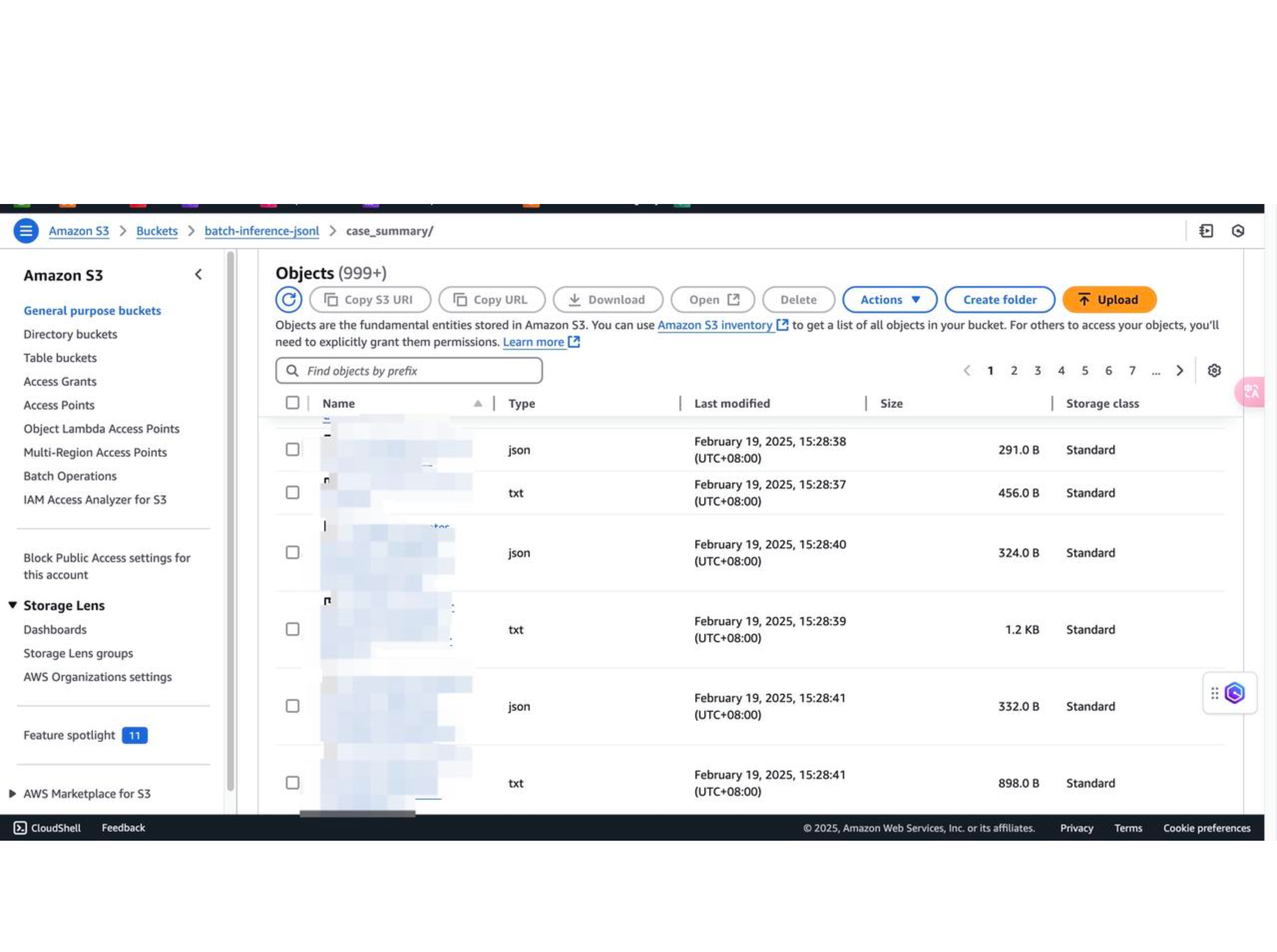
1. 上传知识库文档到 S3
上传时,除了文档本身,还需要包含文档的元数据(下图的所有 json 文件),在生成内容时会使用元数据过滤去预筛选检索到的内容。下图为通过爬虫得到的文档及其元数据。在爬虫阶段,可考虑使用 Amazon Bedrock 提供的大语言模型或使用 Amazon Q Developer 来辅助编写 Python 爬虫代码,并通过 SDK 的方式上传至 S3,并在本地 Python 环境中运行,以提升文档准备阶段的效率。
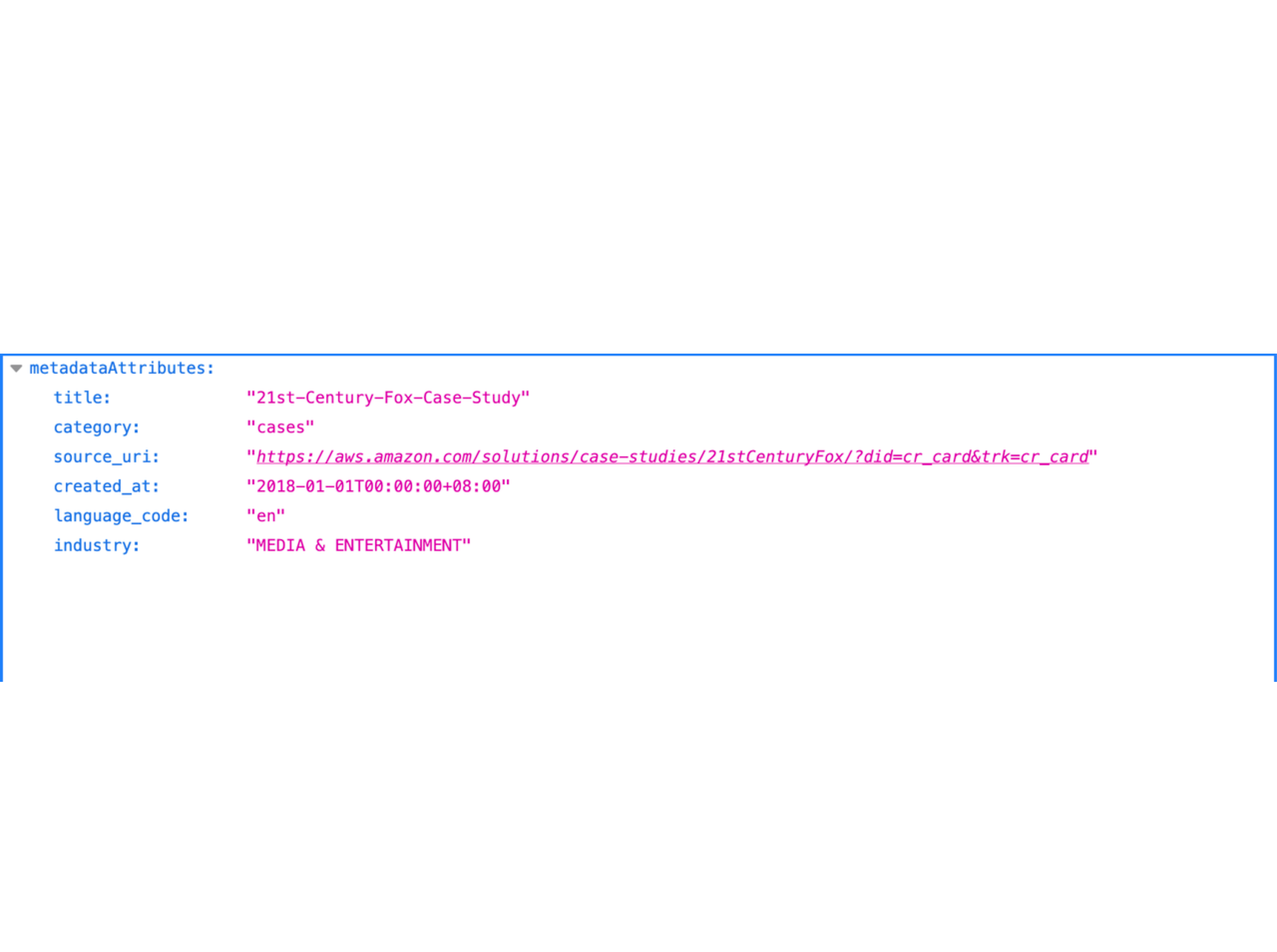
2. 准备文档元数据
这里包含的元数据字段有文档的 title, category, source_uri, created_at, language_code, industry。这其中的一些字段将在下文中用于元数据过滤。
在爬取文档的数据及元数据时当文档质量不高时会对检索的效果有影响。所以可以考虑使用大模型对文档进行提纯后,再上传到 S3。
三、知识库创建
在 Amazon Bedrock 控制台中,选择导航窗格中的 Knowledge bases 。
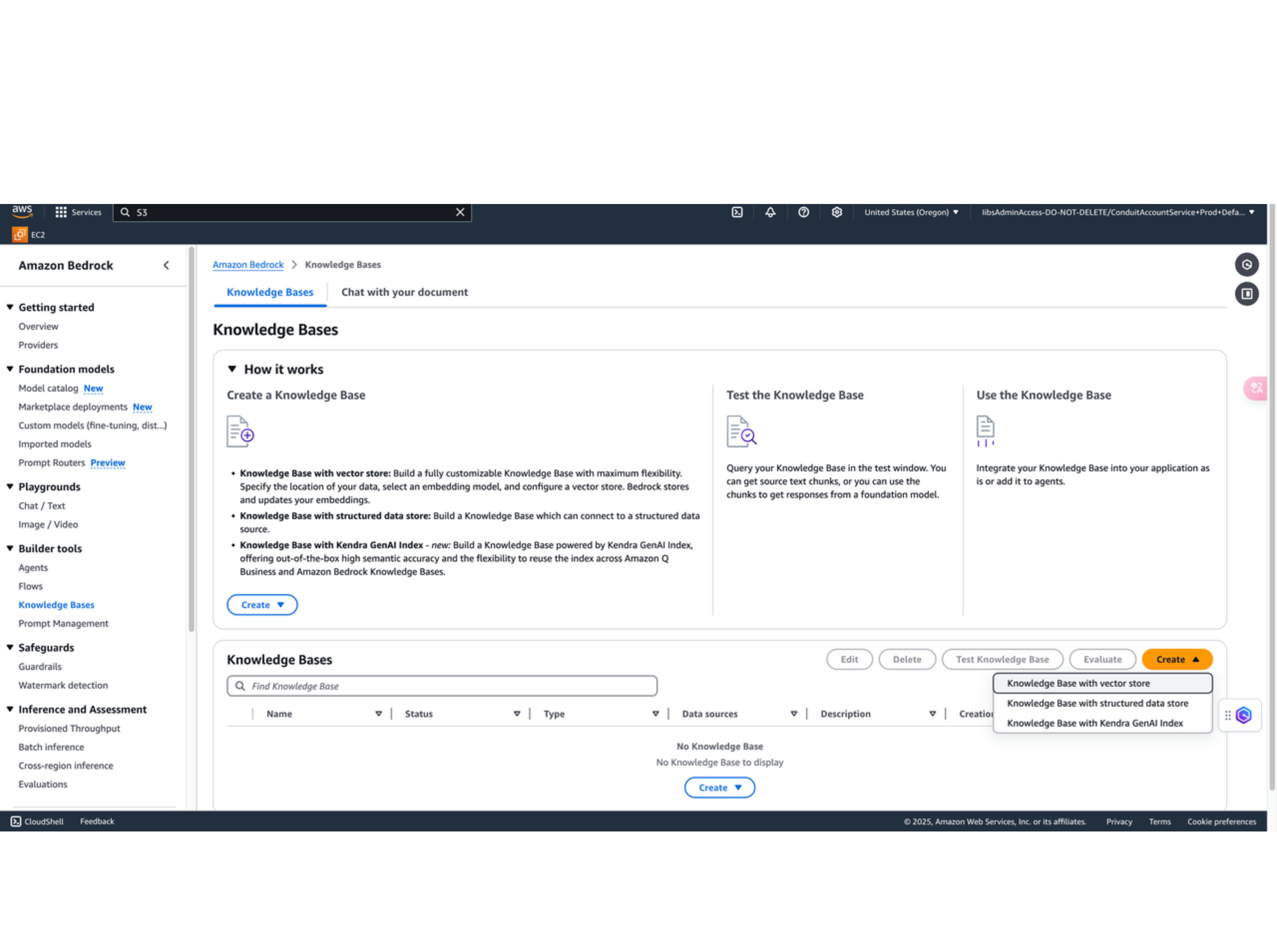
1. 知识库配置项
点击 Create knowledge base。
在 Provide knowledge base details 页面,设置以下配置:
- 为知识库命名。
- 对于 IAM permissions 项,选择 Create and use a new service role。
- 对于 Choose data source项,选择 S3 作为数据源。
- 点击 Next。
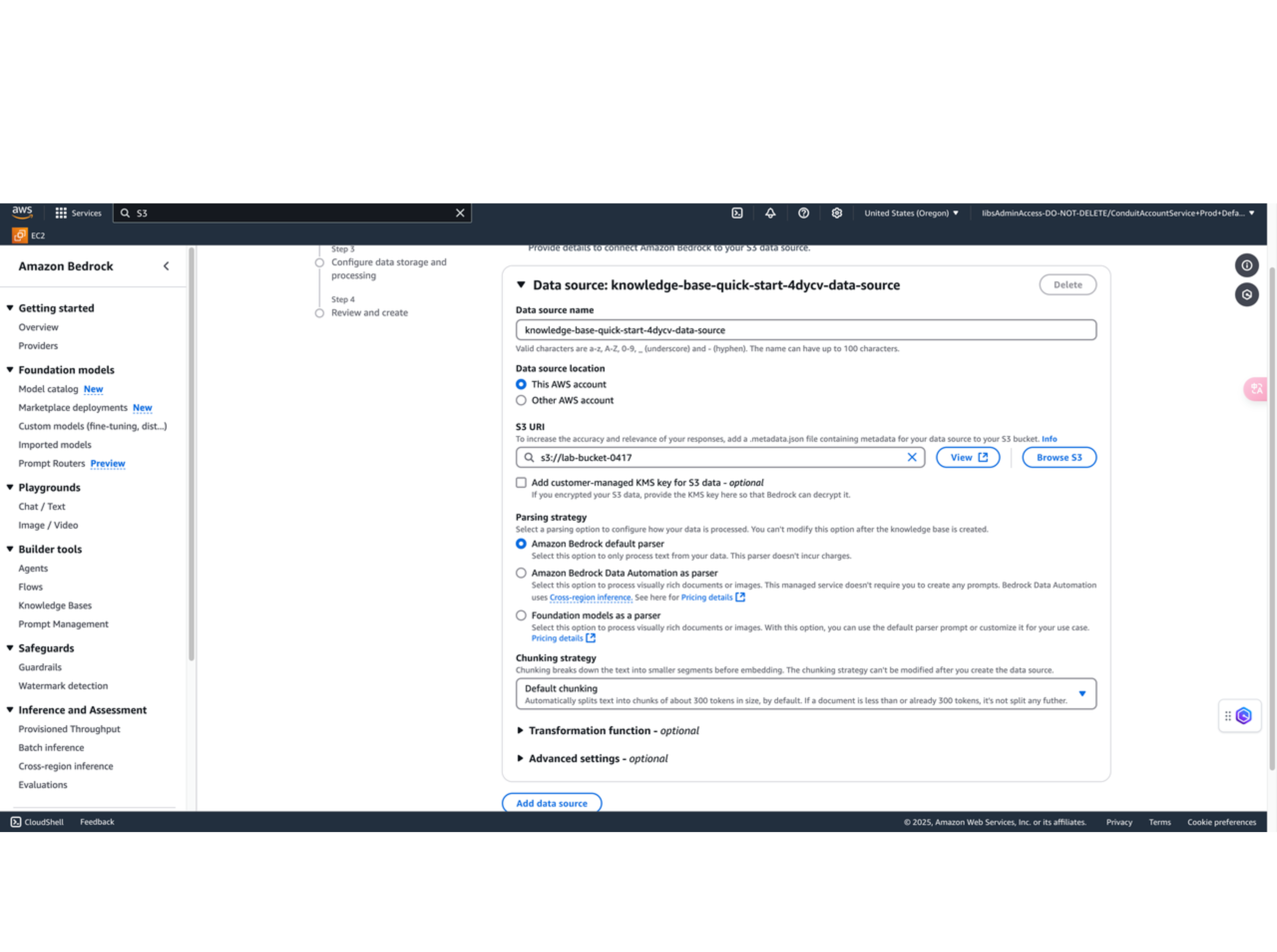
2. 数据源配置
- S3 URI 项点击 Browse S3
- Parsing Strategy 选择 Amazon Bedrock default parser 。
- Chunking strategy 项我选择的是 Default chunking 。这里对应不同的分块策略在上文有详细解释,您可以根据自己的 chunking 需求选择合适的 Chunking strategy。
- 点击 Next。
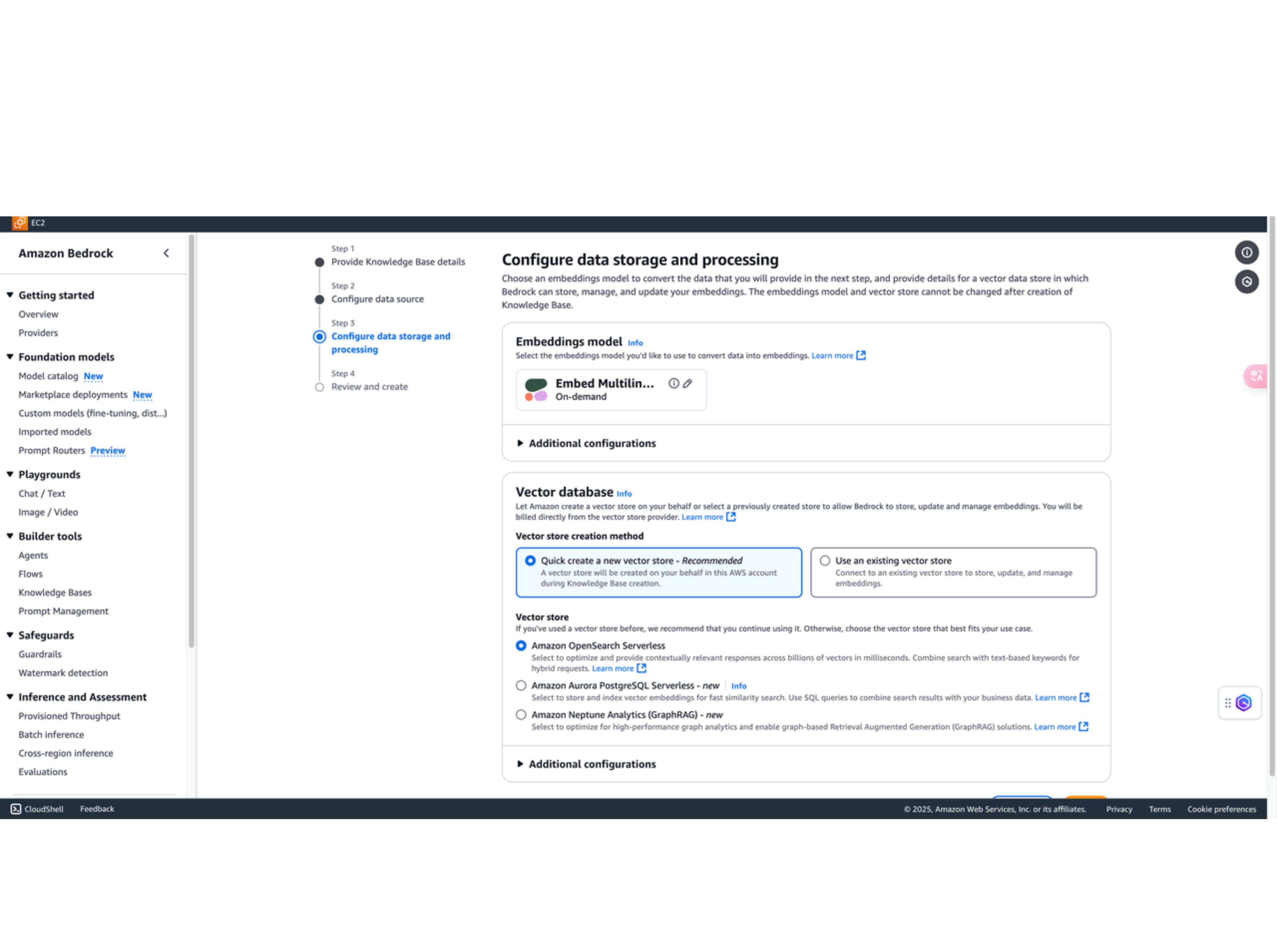
3. 嵌入向量模型和向量数据库配置
- Embeddings model 项选择 Cohere,多语言模型支持混合语意查询(中文搜英文,英文搜中文)。
- Vector dimensions 项输入 1024。
- Vector database 项选择 Quick create a new vector store。Vector store 选择 Amazon OpenSearch Serverless
- 点击 Next。
- 仔细检查后,选择 Create knowledge base。
四、测试知识库
接下来,我们来了解一下如何测试使用网络爬虫作为数据源的知识库
1. 数据源同步
-
在 Amazon Bedrock 控制台上,导航至先前创建的知识库。
-
在 Data source 下,选择数据源名称并点击 Sync。同步过程可能需要几分钟到几小时,具体取决于数据大小。
2. 测试知识库配置项
-
同步任务完成后,点击右上角的 Test knowledge base。
-
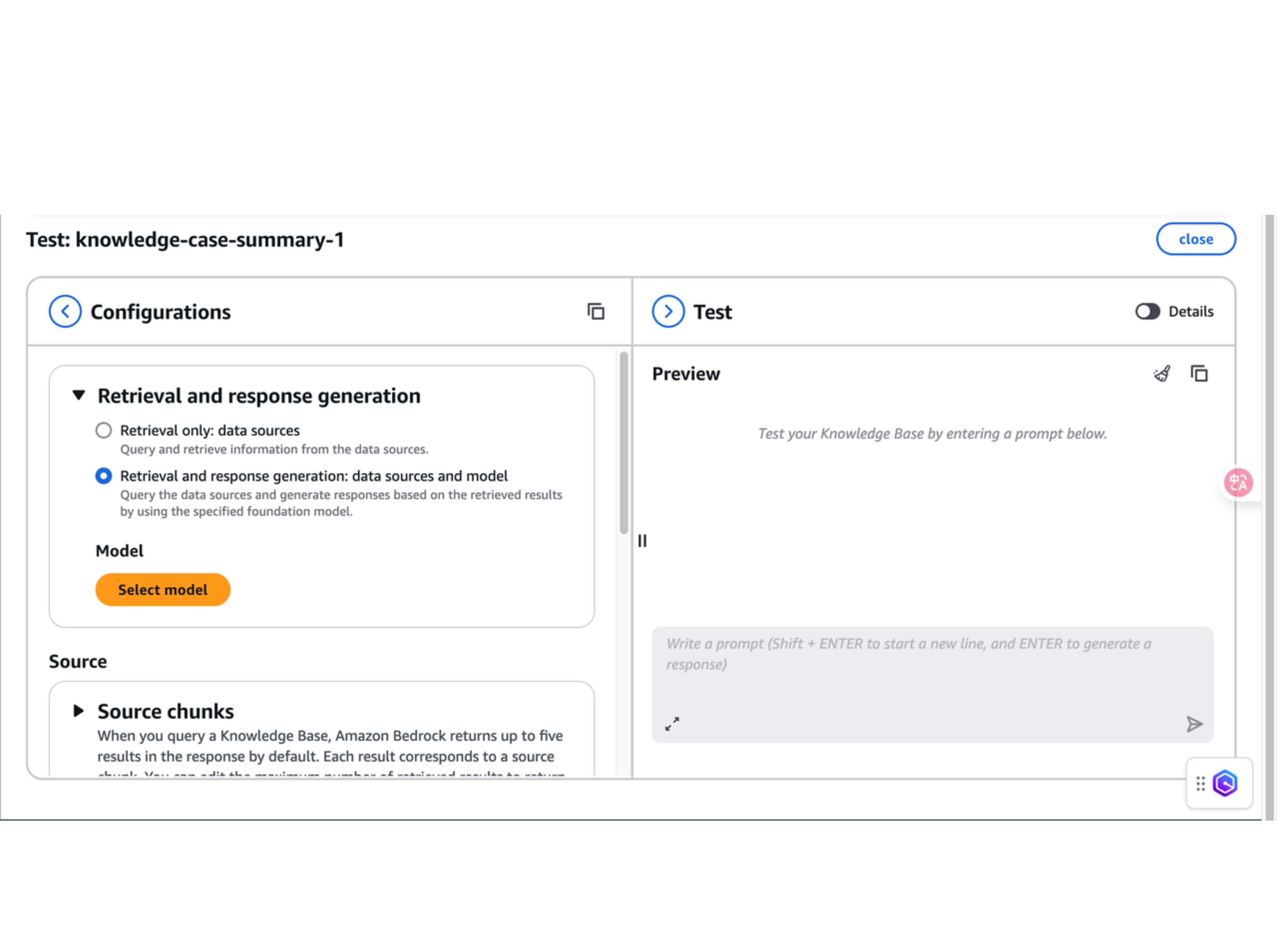
Retrieval and response generation 包含 Retrieval only 和 Retrieval and response generation 两个选项。这里我选择的是 Retrieval and response generation,让大模型基于检索到的 chunks 来生成最终的回答。选择 Select model 并点击想要选择的模型。我这里选择 Amazon Nova Pro。
Source chunks 这里输入最终想要检索到的 chunk 数量。Search Type 保持默认,Streaming preference 也保持默认。
3. Data manipulation 相关设置
-
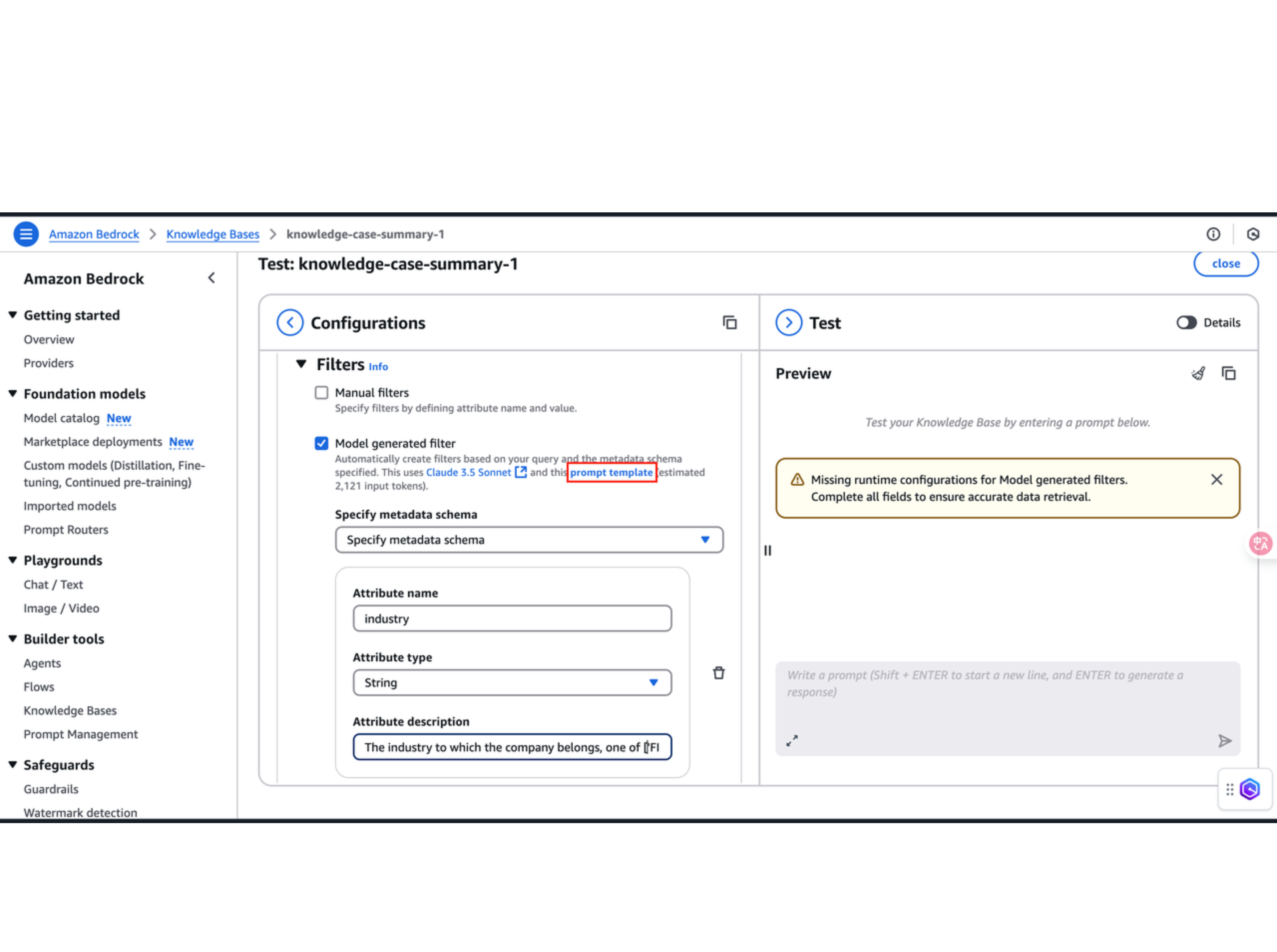
Filters 选择 Model generated filter,填入用于过滤 chunks 的元数据属性。这里待过滤的元数据,是我们在上传S3过程中,在 metadata.json 中配置好的。我这里用的是客户案例的行业作为过滤属性。所以在 Attribute name 填入 industry,Attribute type 选择 String,并在 Attribute description 中给出关于元数据属性的描述,例如:The industry to which the company belongs, one of ['FINANCIAL SERVICES', 'SOFTWARE & INTERNET', 'HEALTHCARE', 'AUTOMOTIVE', 'MANUFACTURING', 'DIGITAL MARKETING']。更多的填写示例,可以点击下图中红框处的 prompt template 进行查看。
-
Guardrails 保持默认。
-
Reranking 点击 Select model,选择 Cohere Rerank 3.5 。
-
Additional Reranking options - Optional 中的 Number of source chunks after reranking,填入重排后想要取回的 chunk 数量。Metadata attributes 留空
-
Query modification 打开 Break down queries 选项。(这里对应查询重写的功能,这是 knowledgebase 内置好的,只需要开启即可)
4. 测试知识库
-
输入提示词“”,并查看模型响应:
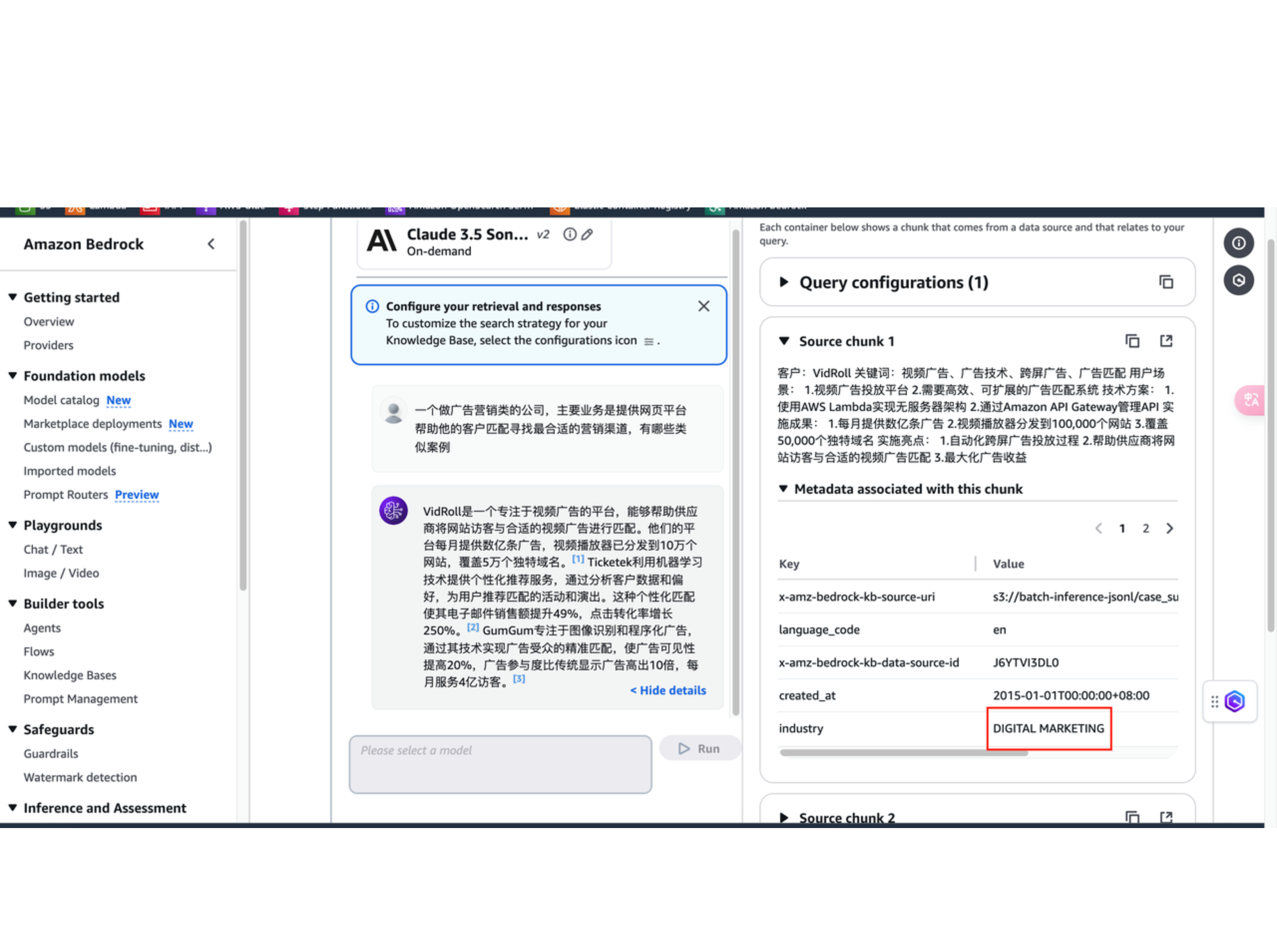
可以点击 Show details,看到 Source chunks 和 Metadata associated with this chunk。最终返回的都是跟 DIGITAL MARKETING相关的案例。从而验证了元数据过滤在处理海量数据检索时发挥的作用。
5. 元数据过滤功能对照实验
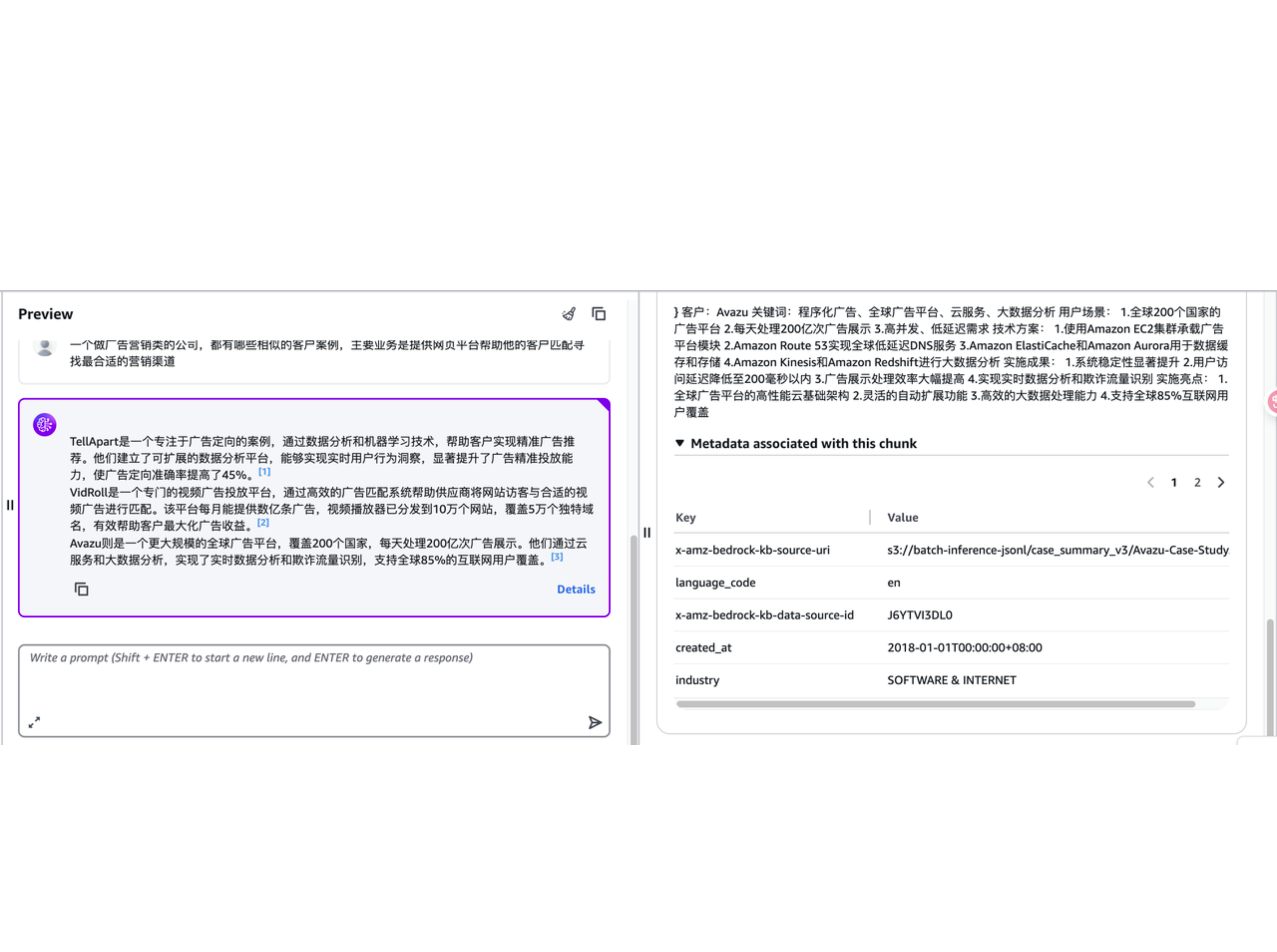
若关闭 Filters 功能,直接在全量的向量数据库去搜,则会返回一些与“DIGITAL MARKETING”行业不那么强相关的文档,如下图所示。通过此对比实验,可以说明有效的元数据过滤可以帮助缩小匹配内容的范围,在经过一次预过滤之后再基于语义去检索内容,提升检索的效率和准确性。
清理资源
本实验手册旨在带您快速体验基于 Bedrock 内置的知识库功能实现生产级 RAG,因此,若您完成测试体验之后,如不需要将此知识库用于实际工作或项目当中,您可以删除已经部署的内容。
1. 删除知识库
您可以直接在控制台界面,选择不需要的知识库进行删除。执行删除时,您会看到如下页面提示,请在确认之前,仔细阅读删除知识库的提示内容。
2. 删除对应的 opensearch serverless
删除掉知识库之后,对应的向量数据库并不会自动删除。因此您需要手动进入 opensearch 页面,删除不再使用的向量数据库。通过 Knowledge base 默认创建的 opensearch 是 serverless 版本。您需要找到对应的集合并删除。
3. 删除 S3 中的文件
之前上传 S3 的知识库文件,也需要手动删除,以免产生存储费用
费用无忧,限时体验
限时申领 50 美元亚马逊云科技服务抵扣券 ,用于抵扣部署及试用过程中使用亚马逊云科技服务所产生的费用。
1. 免费注册亚马逊云科技账号

2. 申领服务抵扣券

3. 服务抵扣券充值
活动须知
通过注册本活动,您同意本推广活动的条款和条件
- 此活动面向于 2025 年 5 月 26 日 00:00:00 至 2025 年 9 月 30 日 23:59:59 期间(以 12 位 ID 在亚马逊云科技系统中显示时间为准)新注册有效(active 状态)的亚马逊云科技海外区域账户(需完成完整的 6 步账号注册流程)。活动采取报名制度,客户需要填写申领表单报名此活动,经审核后,符合相关要求且前 200 名在活动期间填写表单报名的用户可以获得亚马逊云科技服务抵扣券。亚马逊云科技服务抵扣券会于表单提交后10个工作日内充值至相应账号中。
- 活动截止时间为 2025 年 9 月 30 日 23:59:59。
- 亚马逊云科技海外区域为中国大陆以外的亚马逊云科技区域。
- 创建的账户需要是常规独立账户,不能为主账户下的附属子账户 (linked account) 。
- 账单地址需选择中国大陆地区。
- 本活动仅限中国大陆地区的居民参加。居民需年满18 周岁。
- 活动优惠不与其他优惠叠加使用。
- 申领表单提交截止时间为 2025 年 9 月 30 日 23:59:59,晚于该时间,抵扣券无法发放。
- 每个用户或账号仅限参与一次,并获取一次亚马逊云科技服务抵扣券,超过一次按一次计算且只能获得一次抵扣券。亚马逊云科技相关工作人员会对账户进行审核,审核通过方有资格领取抵扣券。
- 亚马逊云科技抵扣券的使用受载于 https://aws.amazon.com/awscredits/(以及指定的任何后续或相关网址)的条款与条件的限制。亚马逊云科技抵扣券没有任何金钱价值,不得转让或转售。
- 50 美元亚马逊云科技服务抵扣券可使用的亚马逊云科技服务类别以最终充值的服务抵扣券所涵盖的服务为准。
- 本活动的亚马逊云科技服务抵扣券的使用有效期至 2025 年 12 月 31 日,亚马逊云科技服务抵扣券只可以抵扣未来账单,不可以抵扣历史账单。
- 我们保留修改或取消本活动的权利。
- 如果你违反了本活动的条款和条件,将失去参与本活动的资格。
- 如本活动被法律所禁止,本活动将无效。
- 我们将根据亚马逊云科技隐私政策处理您的个人信息。