Amazon SageMaker Clarify
Evaluate models and explain model predictions
What is Amazon SageMaker Clarify?

Benefits of SageMaker Clarify
Automatically evaluate FMs for your generative AI use case with metrics such as accuracy, robustness, and toxicity to support your responsible AI initiative. For criteria or nuanced content that requires sophisticated human judgment, you can choose to leverage your own workforce or use a managed workforce provided by AWS to review model responses.
Explain how input features contribute to your model predictions during model development and inference. Evaluate your FM during customization using the automatic and human-based evaluations.
Generate easy to understand metrics, reports, and examples throughout the FM customization and MLOps workflow.
Detect potential bias and other risks, as prescribed by guidelines such as ISO 42001, during data preparation, model customization, and in your deployed models.
Evaluate foundation models
Evaluation wizard and reports
Customization
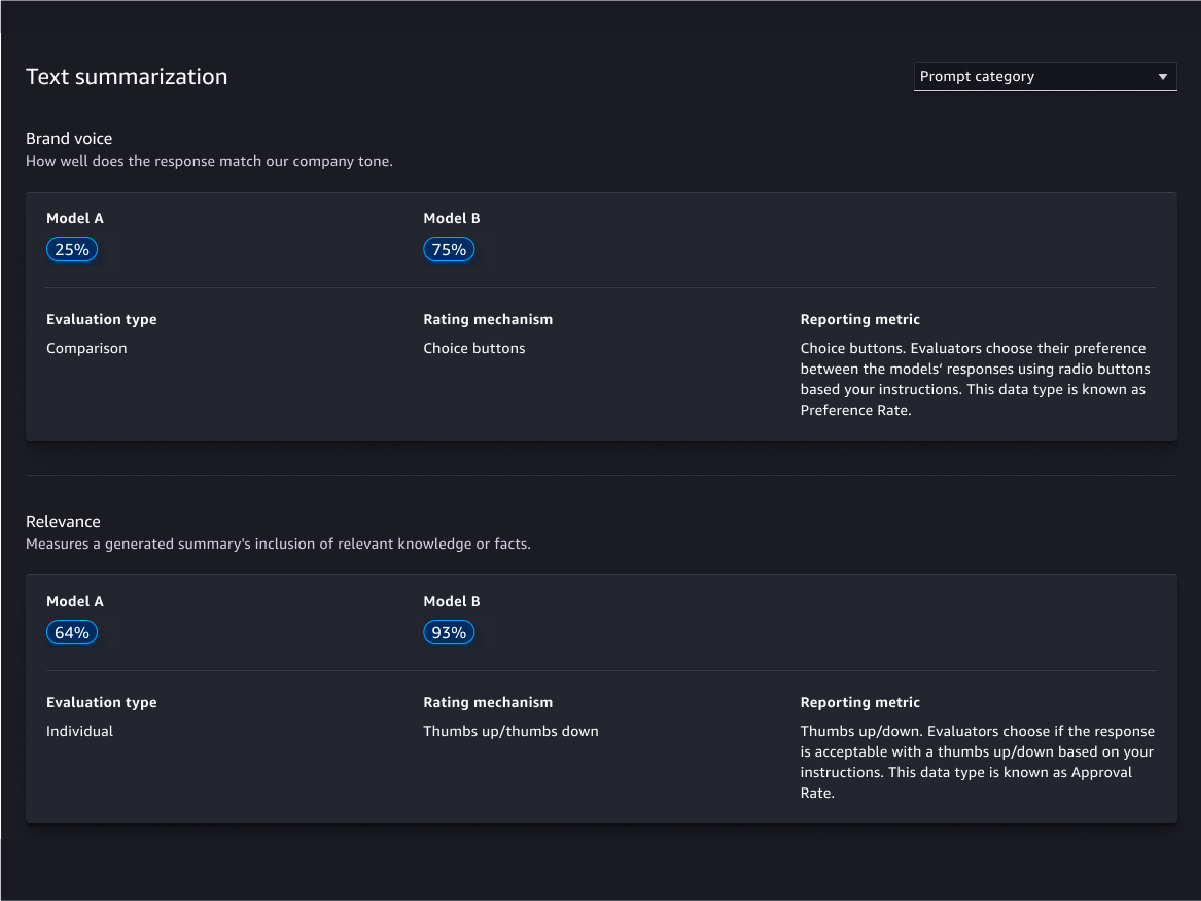
Human-based evaluations
Model quality evaluations
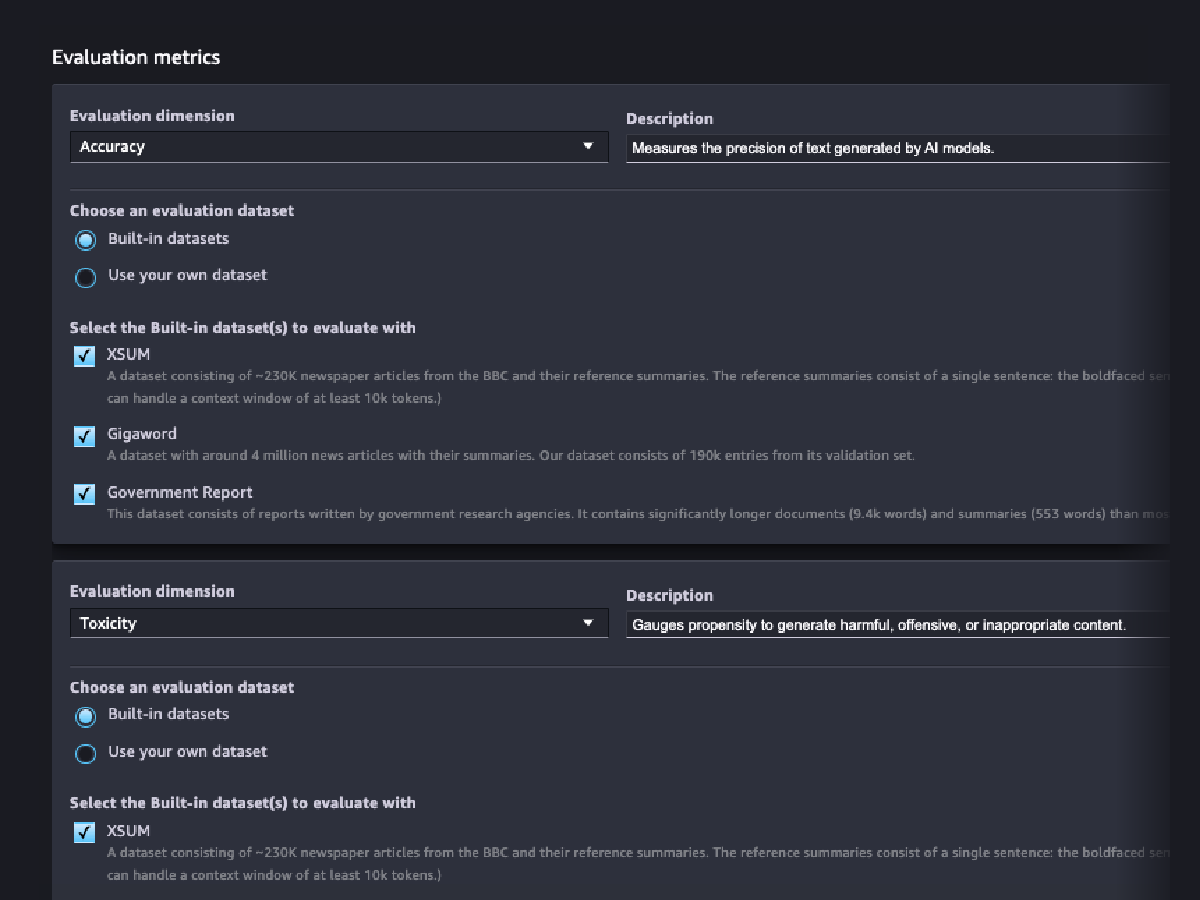
Model responsibility evaluations
Evaluate the risk that your FM encoded stereotypes along the categories of race/color, gender/gender identity, sexual orientation, religion, age, nationality, disability, physical appearance, and socioeconomic status using automatic and/or human-based evaluations. You can also evaluate the risk of toxic content. These evaluations can be applied to any task that involves generation of content, including open-ended generation, summarization, and question answering.
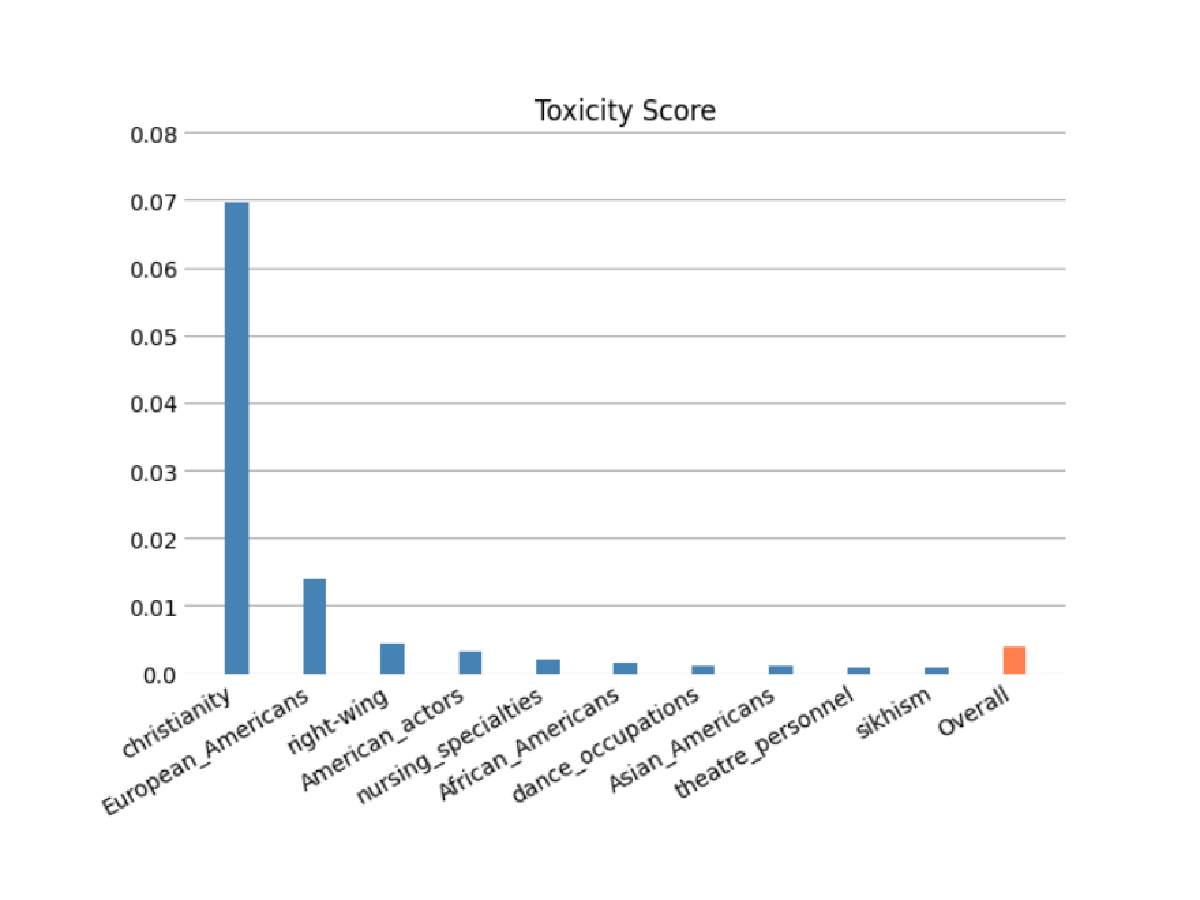
Model predictions
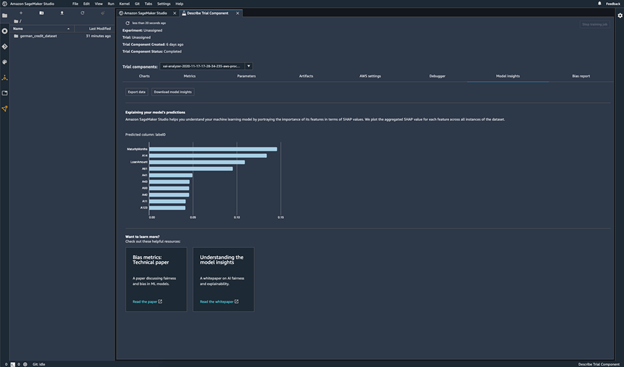
Explain model predictions
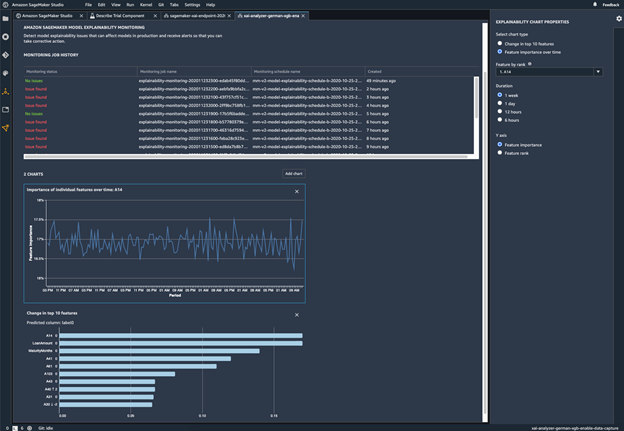
Monitor your model for changes in behavior
Detect bias
Identify imbalances in data
SageMaker Clarify helps identify potential bias during data preparation without writing code. You specify input features, such as gender or age, and SageMaker Clarify runs an analysis job to detect potential bias in those features. SageMaker Clarify then provides a visual report with a description of the metrics and measurements of potential bias so that you can identify steps to remediate the bias. In case of imbalances, you can use SageMaker Data Wrangler to balance your data. SageMaker Data Wrangler offers three balancing operators: random undersampling, random oversampling, and SMOTE to rebalance data in your unbalanced datasets.
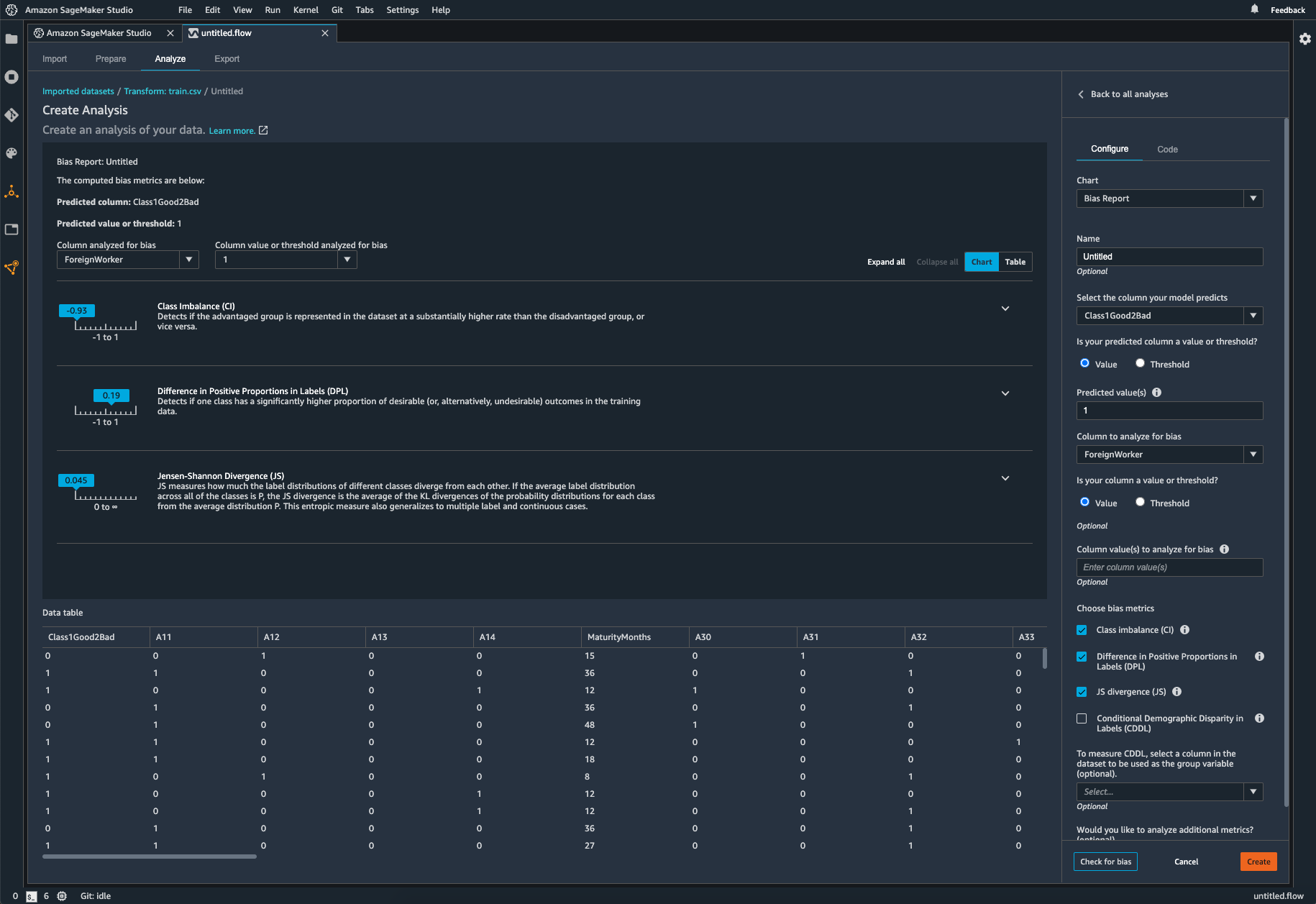
Check your trained model for bias
After you’ve trained your model, you can run a SageMaker Clarify bias analysis through Amazon SageMaker Experiments to check your model for potential bias such as predictions that produce a negative result more frequently for one group than they do for another. You specify input features with respect to which you would like to measure bias in the model outcomes, and SageMaker runs an analysis and provides you with a visual report that identifies the different types of bias for each feature. AWS open-source method Fair Bayesian Optimization can help mitigate bias by tuning a model’s hyperparameters.
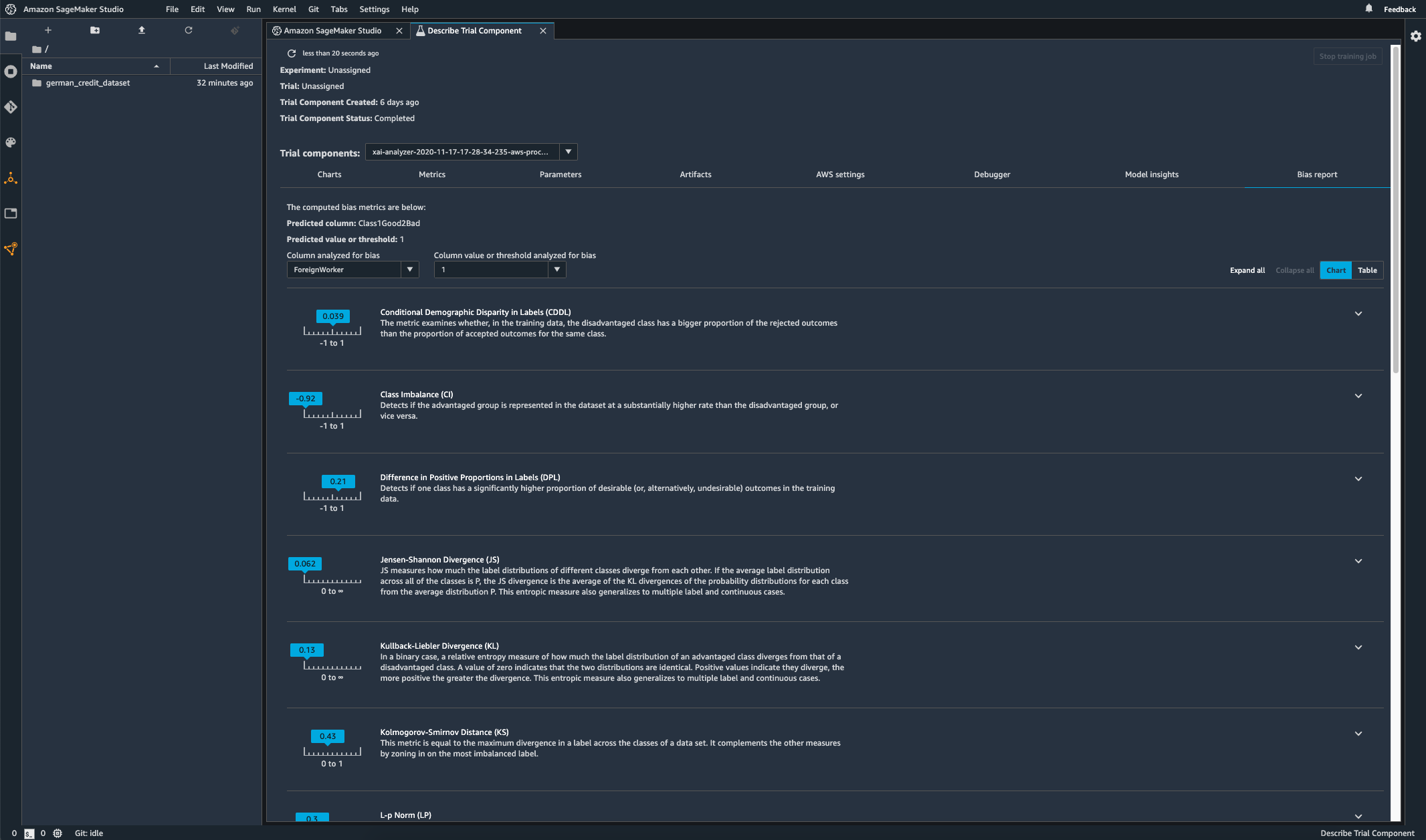
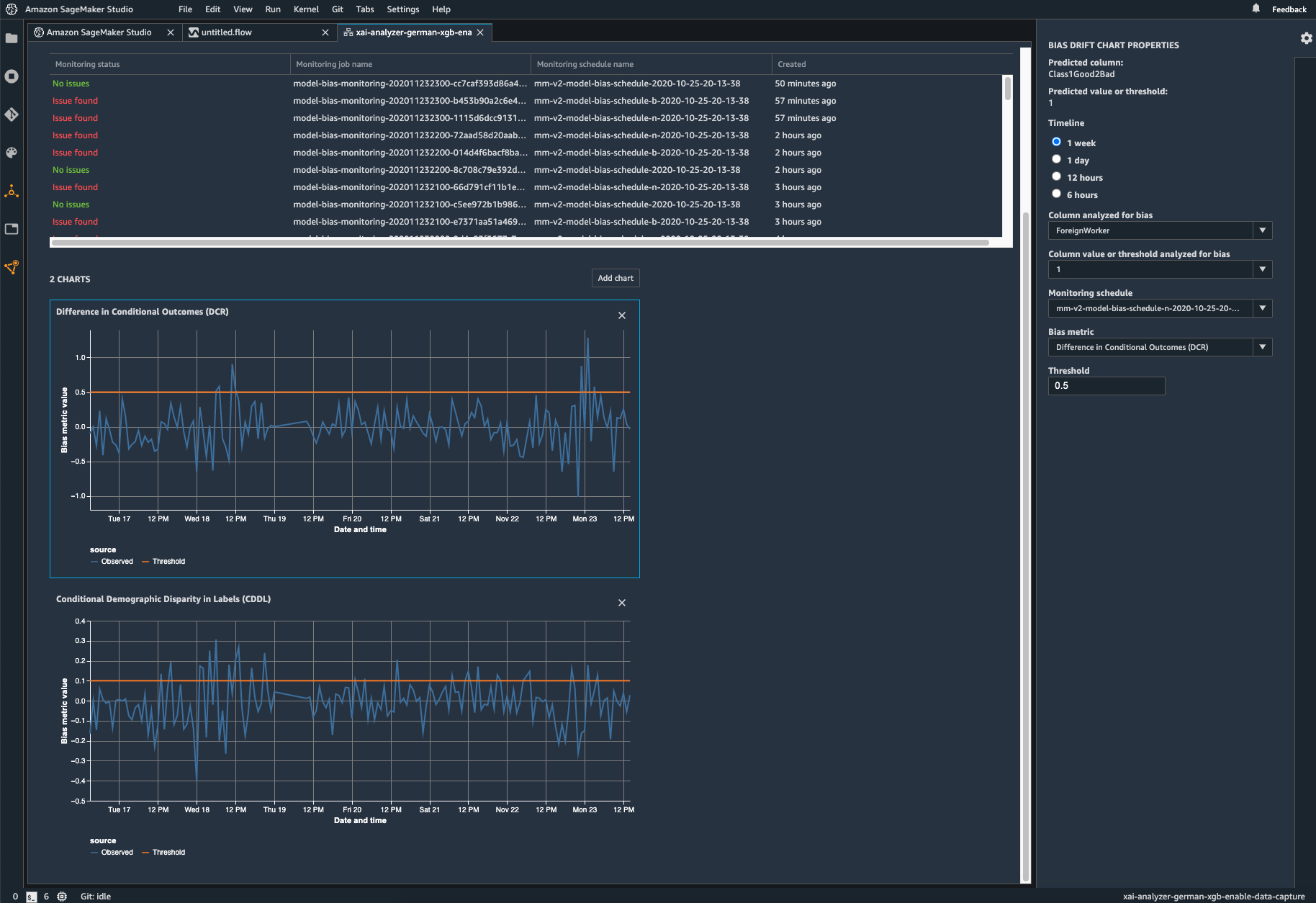
Monitor your deployed model for bias
Bias can be introduced or exacerbated in deployed ML models when the training data differs from the live data that the model sees during deployment. For example, the outputs of a model for predicting home prices can become biased if the mortgage rates used to train the model differ from current mortgage rates. SageMaker Clarify bias detection capabilities are integrated into Amazon SageMaker Model Monitor so that when SageMaker detects bias beyond a certain threshold, it automatically generates metrics that you can view in Amazon SageMaker Studio and through Amazon CloudWatch metrics and alarms.