AWS News Blog
Amazon SageMaker Ground Truth – Build Highly Accurate Datasets and Reduce Labeling Costs by up to 70%

|
In 1959, Arthur Samuel defined machine learning as a “field of study that gives computers the ability to learn without being explicitly programmed”. However, there is no deus ex machina: the learning process requires an algorithm (“how to learn”) and a training dataset (“what to learn from”).
Today, most machine learning tasks use a technique called supervised learning: an algorithm learns patterns or behaviours from a labeled dataset. A labeled dataset containing data samples as well as the correct answer for each one of them, aka ‘ground truth’. Depending on the problem at hand, one could use labeled images (“this is a dog”, “this is a cat”), labeled text (“this is spam”, “this isn’t”), etc.
Fortunately, developers and data scientists can now rely on a vast collection of off-the-shelf algorithms (as illustrated by the built-in algorithms in Amazon SageMaker) and of reference datasets. Deep learning has popularized image datasets such as MNIST, CIFAR-10 or ImageNet, and more are also available for tasks like machine translation or text classification. These reference datasets are extremely useful for beginners and experienced practitioners alike, but a lot of companies and organizations still need to train machine learning models on their own dataset: think about medical imaging, autonomous driving, etc.
Building such datasets is a complex problem, particularly when working at scale. How long would it take one person to label one thousand images or documents? ‘Quite some time’ is probably the answer! Now imagine having to label one million images or documents: how many people would you now need? For most companies and organizations, this is a moot point, as they would never be able to muster enough people anyway.
Well, no more! Today, I’m very happy to announce Amazon SageMaker Ground Truth, a new capability of Amazon SageMaker that makes it easy for customers to to efficiently and accurately label the datasets required for training machine learning systems.
Introducing Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth helps you build datasets for:
- Text classification.
- Image classification, i.e categorizing images in specific classes.
- Object detection, i.e. locating objects in images with bounding boxes.
- Semantic segmentation, i.e. locating objects in images with pixel-level precision.
- Custom user-defined tasks.
Amazon SageMaker Ground Truth can optionally use active learning to automate the labeling of your input data. Active learning is a machine learning technique that identifies data that needs to be labeled by humans and data that can be labeled by machine. Automated data labeling incurs Amazon SageMaker training and inference costs, but it can help to reduce the cost (up to 70%) and time that it takes to label your dataset over having humans label your complete dataset.
When manual effort is required, you can choose to use a crowdsourced Amazon Mechanical Turk workforce of over 500,000 workers, a private workforce of your own workers, or one of the curated third party vendors listed on the AWS Marketplace.
Let’s look at the high-level steps required to label a dataset:
- Store your data in Amazon S3,
- Create a labeling workforce,
- Create a labeling job,
- Get to work,
- Visualize results.
How about an example? Let me show you how to label images from the CBCL StreetScenes dataset. This dataset contains 3548 images such as this one. For the sake of brevity, I will only use the first 10 images and annotate cars only.

Storing data in Amazon S3
The first step is to create a manifest file for the dataset. This is a simple JSON file listing all images present in the dataset. Mine looks like this: please note that each line corresponds to a single object and is an independent JSON document.
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00001.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00002.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00003.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00004.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00005.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00006.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00007.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00008.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00009.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00010.JPG"}Then, I simply copy the manifest file and the corresponding images to an Amazon S3 bucket.
Creating a labeling workforce
Amazon SageMaker Ground Truth gives us different options:
- Public workforce, backed by Amazon Mechanical Turk,
- Private workforce, backed by internal resources,
- Vendor workforce, backed by third-party resources.
The first option is probably the most scalable one. However, the last two may be a better fit if your job requires confidentiality, service guarantees, or special skills.
I can only count on myself here, so I create a private team authenticated by a new Amazon Cognito group. Indeed, authentication is required before any worker can access the dataset.
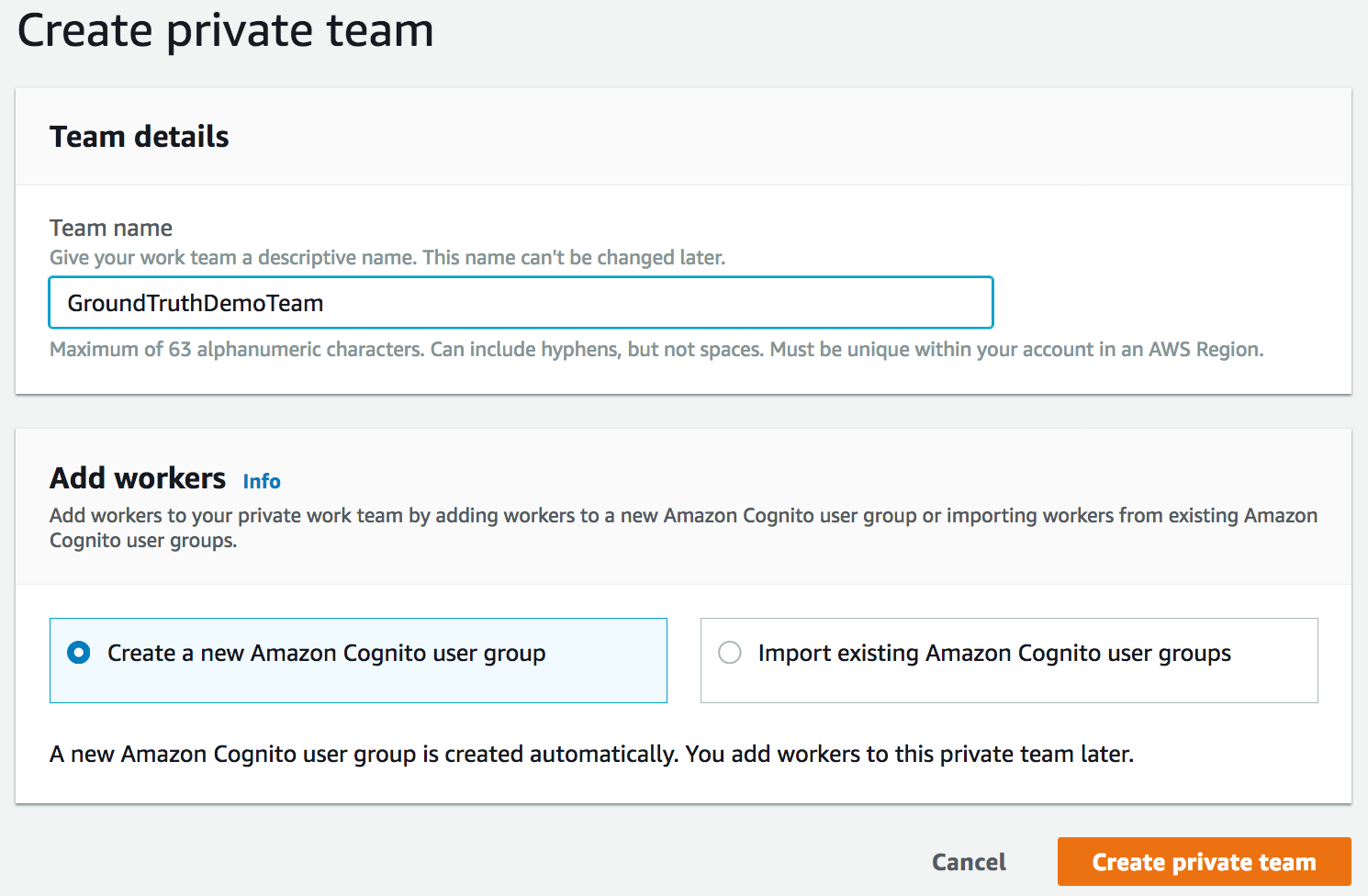
Then, I add myself to the team by entering my email address. A few seconds later, I receive an invitation containing credentials and a URL. This URL also can be found on the labeling workforces dashboard.

Once I’ve clicked on the link and changed my password, I am registered as a verified worker for this team.

The one-man team is now ready. It’s time to create the labeling job itself.
Creating a labeling job
As you would expect, I have to define the location of the manifest file and of the dataset.
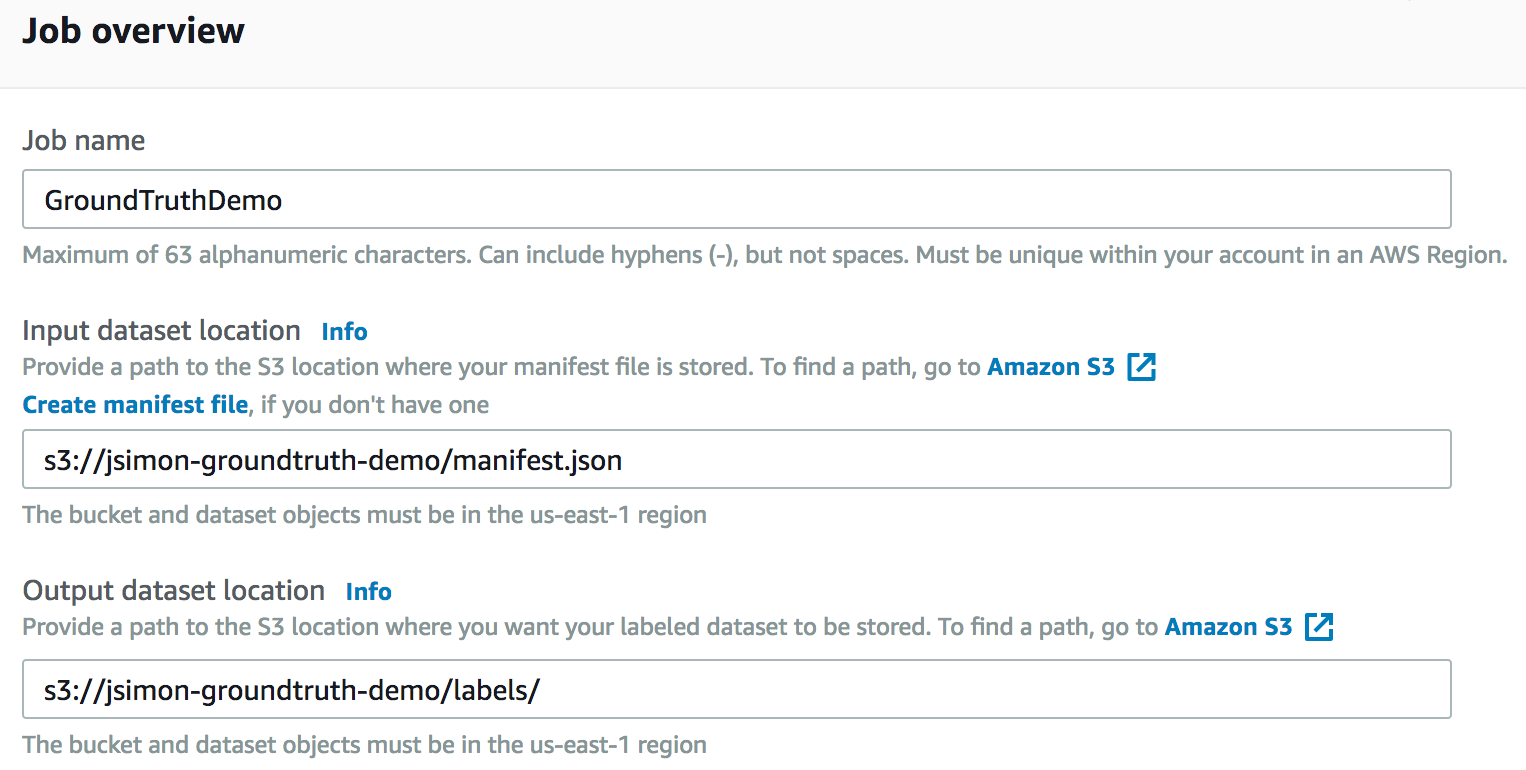
Then, I can decide whether I want to use the full dataset or a subset: I could even write a SQL query to filter the files. Here, let’s use the full dataset, as it only has 10 images.

Next, I have to select the type of the labeling job. As stated earlier, there are multiple options available and here I’m interested in adding bounding boxes to my images.
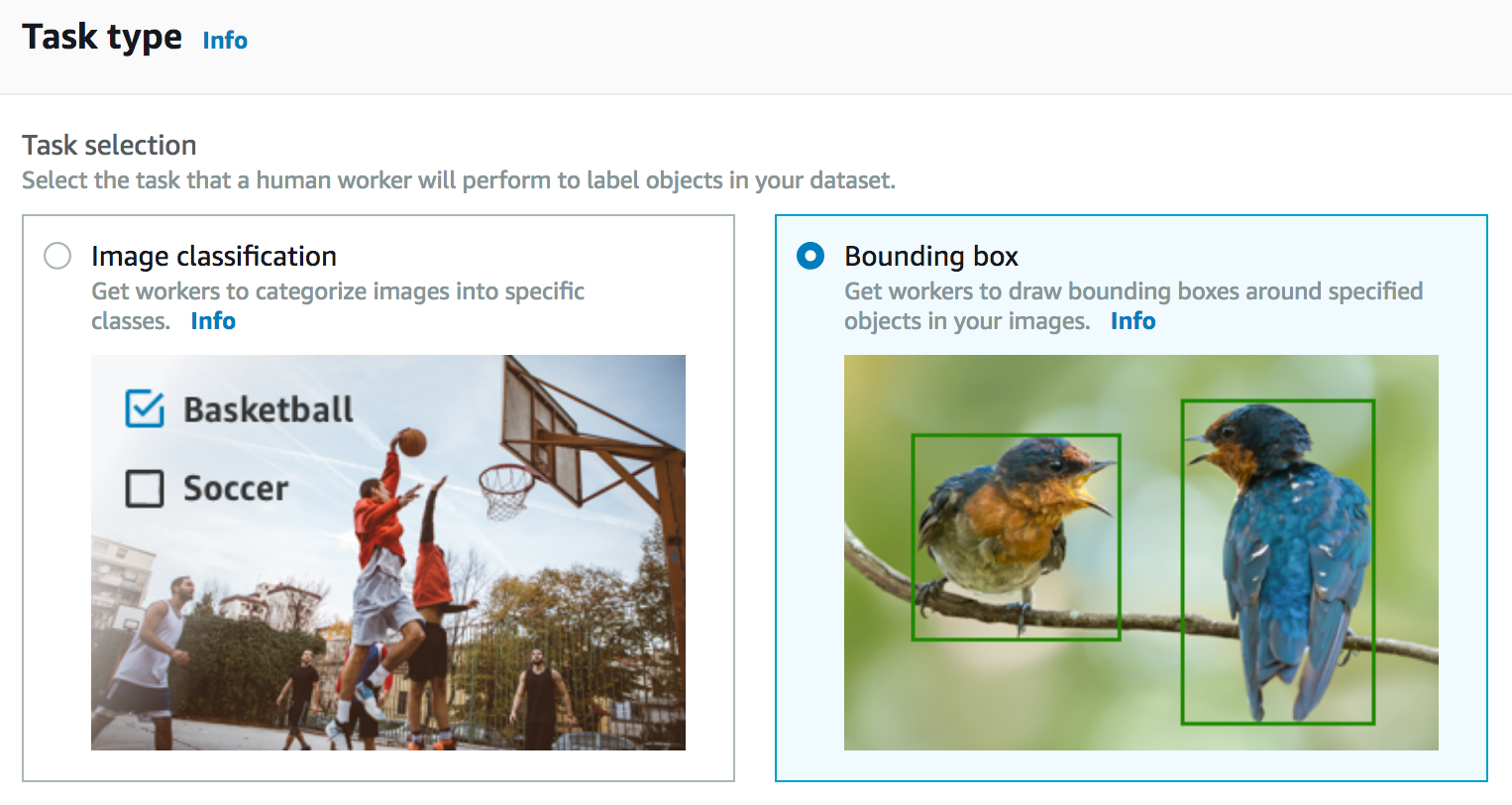
Next, I select the team that I want to assign to the job. This is where I could select automated data labeling. I could also decide to ask multiple workers to label the same image to increase accuracy.

Finally, I can provide additional instructions to workers, detailing the specific task that needs to be performed and giving them a couple of examples.

That’s it. Our labeling job is now ready. Time for the team (well… me, really) to get to work.

Labeling images
Logging into the URL I received by email, I see the list of jobs I’m assigned to.

When I click on the ‘Start working’ button, I see instructions as well as a first image to work on. Using the toolbox, I can draw boxes, zoom in and out, etc. This is pretty intuitive, but drawing boxes that fit just right takes time and care. Now I understand why this is such a time-consuming process… and I have only ten images to go!

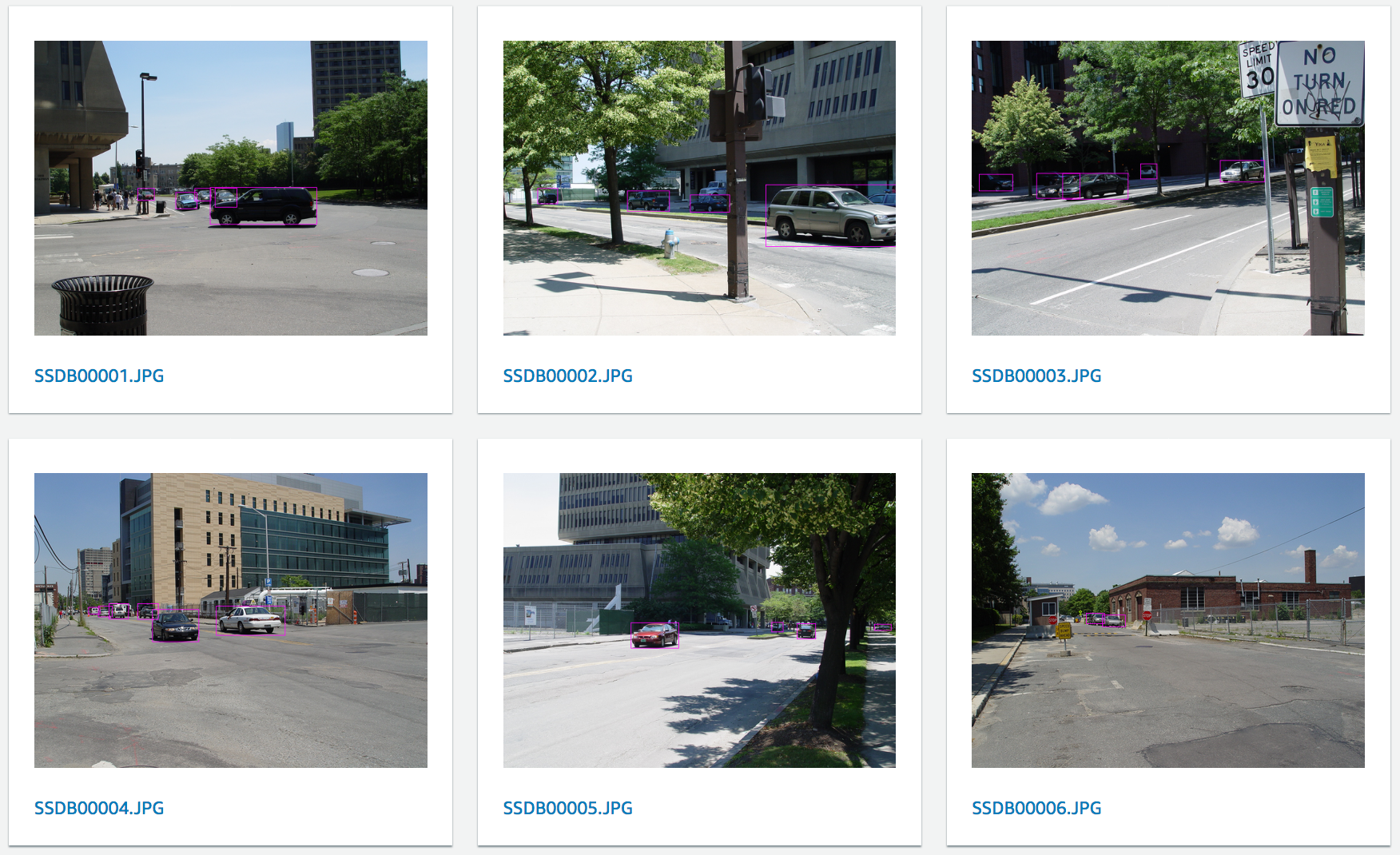
Here’s a zoom on another image. Can you see all seven cars?

Once I’m done with all ten images, I can take a well-deserved break and enjoy the completion of the labeling job.

Visualizing results
Annotated images are visible directly in the AWS console, which comes in handy for sanity checks. I can also click on any image and see the list of labels that have been applied.
Of course, our purpose is to use this information to train machine learning models: we can find it in the augmented manifest file stored in our bucket. For example, here’s what the manifest has to say about the first image, where I labeled five cars.
{
"source-ref": "s3://jsimon-groundtruth-demo/SSDB00001.JPG",
"GroundTruthDemo": {
"annotations": [
{"class_id": 0, "width": 54, "top": 482, "height": 39, "left": 337},
{"class_id": 0, "width": 69, "top": 495, "height": 53, "left": 461},
{"class_id": 0, "width": 52, "top": 482, "height": 41, "left": 523},
{"class_id": 0, "width": 71, "top": 481, "height": 62, "left": 589},
{"class_id": 0, "width": 347, "top": 479, "height": 120, "left": 573}
],
"image_size": [{"width": 1280, "depth": 3, "height": 960}
]
},
"GroundTruthDemo-metadata": {
"job-name": "labeling-job/groundtruthdemo",
"class-map": {"0": "Car"},
"human-annotated": "yes",
"objects": [
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94}
],
"creation-date": "2018-11-26T04:01:09.038134",
"type": "groundtruth/object-detection"
}
}This has all the information required to train an object detection model, such as the built-in Single-Shot Detector available in Amazon SageMaker, but this is another story!
Now available!
I hope this post was informative. We just scratched the surface of what Amazon SageMaker Ground Truth can do. The service is available today in US-East (Virginia), US-Central (Ohio), US-West (Oregon), Europe (Ireland) and Asia Pacific (Tokyo). Now it’s your turn to try it, and let us know what you think!
— Julien;