AWS News Blog
Amazon DynamoDB Update – JSON, Expanded Free Tier, Flexible Scaling, Larger Items
Amazon DynamoDB Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale. Our customers love the fact that they can get started quickly and simply (and often at no charge, within the AWS Free Tier) and then seamlessly scale to store any amount of data and handle any desired request rate, all with very consistent, SSD-driven performance.
Today we are making DynamoDB even more useful with four important additions: Support for JSON data, an expanded free tier, additional scaling options, and the capacity to store larger items. We’ve also got a new demo video and some brand-new customer references.
JSON Document Support
You can now store entire JSON-formatted documents as single DynamoDB items (subject to the newly increased 400 KB size limit that I will talk about in a moment).
This new document-oriented support is implemented in the AWS SDKs and makes use of some new DynamoDB data types. The document support (available now in the AWS SDK for Java, the SDK for .NET, the SDK for Ruby, and an extension to the SDK for JavaScript in the Browser) makes it easy to map your JSON data or native language object on to DynamoDB’s native data types and for supporting queries that are based on the structure of your document. You can also view and edit JSON documents from within the AWS Management Console.
With this addition, DynamoDB becomes a full-fledged document store. Using the AWS SDKs, it is easy to store JSON documents in a DynamoDB table while preserving their complex and possibly nested “shape.” The new data types could also be used to store other structured formats such as HTML or XML by building a very thin translation layer.
Let’s work through a couple of examples. I’ll start with the following JSON document:
{
"person_id" : 123,
"last_name" : "Barr",
"first_name" : "Jeff",
"current_city" : "Tokyo",
"next_haircut" :
{
"year" : 2014,
"month" : 10,
"day" : 30
},
"children" :
[ "SJB", "ASB", "CGB", "BGB", "GTB" ]
}
This needs some escaping in order to be used as a Java String literal:
String json = "{"
+ "\"person_id\" : 123 ,"
+ "\"last_name\" : \"Barr\" ,"
+ "\"first_name\" : \"Jeff\" ,"
+ "\"current_city\" : \"Tokyo\" ,"
+ "\"next_haircut\" : {"
+ "\"year\" : 2014 ,"
+ "\"month\" : 10 ,"
+ "\"day\" : 30"
+ "} ,"
+ "\"children\" :"
+ "[ \"SJB\" , \"ASB\" , \"CGB\" , \"BGB\" , \"GTB\" ]"
+ "}"
;
Here’s how I would store this JSON document in my people table:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item item =
new Item()
.withPrimaryKey("person_id", 123)
.withJSON("document", json);
table.putItem(item);
And here’s how I get it back:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item documentItem =
table.getItem(new GetItemSpec()
.withPrimaryKey("person_id", 123)
.withAttributesToGet("document"));
System.out.println(documentItem.getJSONPretty("document"));
The AWS SDK for Java maps the document to DynamoDB’s data types and stores it like this:
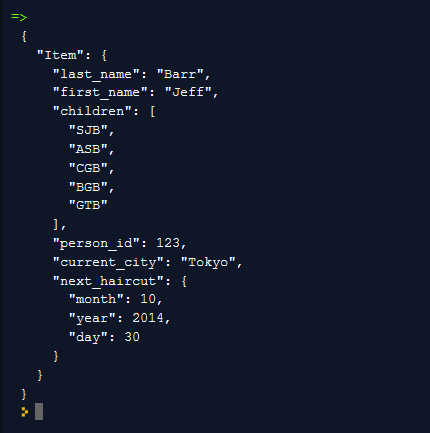
I can also represent and manipulate the document in a programmatic, structural form. This code makes explicit reference to DynamoDB’s new Map and List data types, which I will describe in a moment:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item item =
new Item()
.withPrimaryKey("person_id", 123)
.withMap("document",
new ValueMap()
.withString("last_name", "Barr")
.withString("first_name", "Jeff")
.withString("current_city", "Tokyo")
.withMap("next_haircut",
new ValueMap()
.withInt("year", 2014)
.withInt("month", 10)
.withInt("day", 30))
.withList("children",
"SJB", "ASB", "CGB", "BGB", "GTB"));
table.putItem(item);
Here is how I would retrieve the entire item:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item documentItem =
table.getItem(new GetItemSpec()
.withPrimaryKey("person_id", 123)
.withAttributesToGet("document"));
System.out.println(documentItem.get("document"));
I can use a Document Path to retrieve part of a document. Perhaps I need the next_haircut item and nothing else. Here’s how I would do that:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
Item partialDocItem =
table.getItem(new GetItemSpec()
.withPrimaryKey("person_id", 123)
.withProjectionExpression("document.next_haircut"));
System.out.println(partialDocItem);
Similarly, I can update part of a document. Here’s how I would change my current_city back to Seattle:
DynamoDB dynamo = new DynamoDB(new AmazonDynamoDBClient(...));
Table table = dynamo.getTable("people");
table.updateItem(
new UpdateItemSpec()
.withPrimaryKey("person_id", 123)
.withUpdateExpression("SET document.current_city = :city")
.withValueMap(new ValueMap().withString(":city", "Seattle")));
As part of this launch we are also adding support for the following four data types:
List– An attribute of this data type consists of an ordered collection of values, similar to a JSON array. Thechildrensection of my sample document is stored in a List.Map– An attribute of this type consists of an unordered collection of name-value pairs, similar to a JSON object. Thenext_haircutsection of my sample document is stored in a Map.Boolean– An attribute of this type stores a Boolean value (true or false).Null– An attribute of this type represents a value with an unknown or undefined state.
The mapping from JSON to DynamoDB’s intrinsic data types is predictable and straightforward. You can, if you’d like, store a JSON document in a DynamoDB and then retrieve it using the lower-level “native” functions. You can also retrieve an existing item as a JSON document.
It is important to note that the DynamoDB type system is a superset of JSON’s type system, and that items which contain attributes of Binary or Set type cannot be faithfully represented in JSON. The Item.getJSON(String) and Item.toJSON() methods encode binary data in base-64 and map DynamoDB sets to JSON lists.
Expanded Free Tier
We are expanding the amount of DynamoDB capacity that is available to you as part of the AWS Free Tier. You can now store up to 25 GB of data and process up to 200 million requests per month, at up to 25 read capacity units and 25 write capacity units. This is, in other words, enough free capacity to allow you to run a meaningful production app at no charge. For example, based on our experience, you could run a mobile game with over 15,000 players, or run an ad tech platform serving 500,000 impressions per day.
Additional Scaling Options
As you might know, DynamoDB works on a provisioned capacity model. When you create each of your tables and the associated global secondary indexes, you must specify the desired level of read and write capacity, expressed in capacity units. Each read capacity unit allows you to perform one strongly consistent read (up to 4 KB) per second or two eventually consistent reads (also up to 4 KB) per second. Each write capacity unit allows you to perform one write (up to 1 KB) per second.
Previously, DynamoDB allowed you to double or halve the amount of provisioned throughput with each modification operation. With today’s release, you can now adjust it by any desired amount, limited only by the initial throughput limits associated with your AWS account (which can easily be raised). For more information on this limit, take a look at DynamoDB Limits in the documentation.
Larger Items
Each of your DynamoDB items can now occupy up to 400 KB. The size of a given item includes the attribute name (in UTF-8) and the attribute value. The previous limit was 64 KB.
New Demo Video
My colleague Khawaja Shams (Head of DynamoDB Engineering) is the star of a new video. He reviews the new features and also unveils a demo app that makes use of our new JSON support:

DynamoDB in Action – Customers are Talking
AWS customers all over the world are putting DynamoDB to use as a core element of their mission-critical applications. Here are some recent success stories:
 Talko is a new communication tool for workgroups and families. Ransom Richardson, Service Architect, explained why they are using DynamoDB:
Talko is a new communication tool for workgroups and families. Ransom Richardson, Service Architect, explained why they are using DynamoDB:
DynamoDB is a core part of Talko’s storage architecture. It has been amazingly reliable, with 100% uptime over our two years of use. Its consistent low-latency performance has allowed us to focus on our application code instead of spending time fine-tuning database performance. With DynamoDB it was easy to scale capacity to handle our product launch.
Electronic Arts stores game data for The Simpsons:Tapped Out (a Top 20 iOS app in the US, with millions of active users) in DynamoDB and Amazon Simple Storage Service (Amazon S3). They switched from MySQL to DynamoDB and their data storage costs dropped by an amazing 90%.
The development team behind this incredibly successful game will be conducting a session at AWS re:Invent. You can attend GAM302 to hear how they migrated from MySQL to DynamoDB on the fly and used AWS Elastic Beanstalk and Auto Scaling to simplify their deployments while also lowering their costs.
Online Indexing (Available Soon)
We are planning to give you the ability to add and remove indexes for existing DynamoDB tables. This will give you the flexibility to adjust your indexes to match your evolving query patterns. This feature will be available soon, so stay tuned!
Get Started Now
These new features are available now and you can start using them today in the US East (N. Virginia), US West (N. California), Europe (Ireland), Asia Pacific (Singapore), Asia Pacific (Tokyo), Asia Pacific (Sydney), and South America (São Paulo) Regions. It will be available in the near future in other AWS Regions. Developers targeting any of the AWS Regions can download the newest version DynamoDB Local to develop and test apps locally (read my post, DynamoDB Local for Desktop Development to learn more).
— Jeff;