- Machine Learning
- Amazon SageMaker AI
- Amazon SageMaker AI MLOps
Amazon SageMaker für MLOps
Stellen Sie leistungsstarke ML-Produktionsmodelle schnell und in großem Maßstab bereit
Warum Amazon SageMaker MLOps?
Funktionsweise
Vorteile von SageMaker MLOps
-
Wiederholbare Training-Workflows erstellen – Modellentwicklung beschleunigen
-
Katalogisieren Sie ML-Artefakte zentral für die Modellreproduzierbarkeit und -steuerung
-
Integrieren Sie ML-Workflows in CI/CD-Pipelines für eine schnellere Produktionszeit
-
Kontinuierliche Überwachung der Daten und Modelle in der Produktion zur Aufrechterhaltung der Qualität
Modellentwicklung beschleunigen
Standardisierte datenwissenschaftlicher Umgebungen bereitstellen
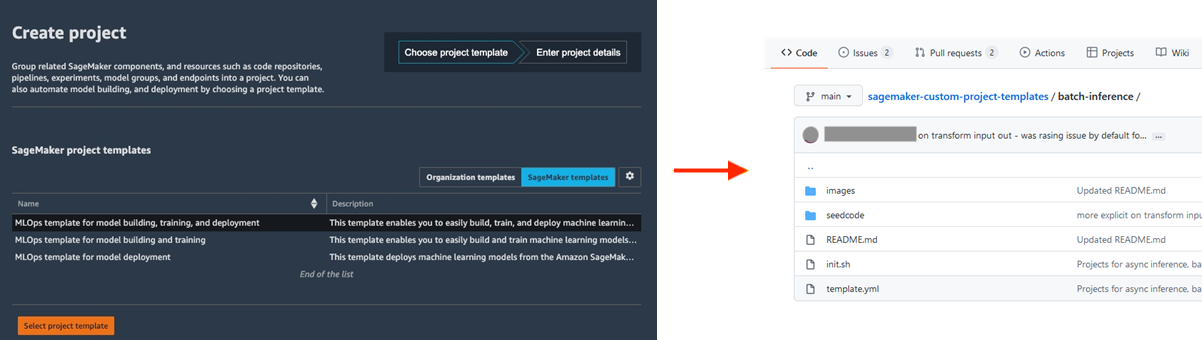
Die Standardisierung von ML-Entwicklungsumgebungen steigert die Produktivität von Datenwissenschaftlern und letztlich das Innovationstempo. Dadurch wird es einfach, neue Projekte zu starten, Datenwissenschaftler projektübergreifend zu rotieren und bewährte Methoden für ML zu implementieren. Amazon SageMaker Projects bietet Vorlagen zur schnellen Bereitstellung standardisierter Umgebungen für Data Scientists mit bewährten und neuesten Tools und Bibliotheken, Source-Control-Repositories, Boilerplate-Code und CI/CD-Pipelines.
Zusammenarbeit mit MLflow während ML-Experimenten
Die ML-Modellbildung ist ein iterativer Prozess, bei dem Hunderte von Modellen trainiert werden, um den besten Algorithmus, die beste Architektur und die besten Parameter für eine optimale Modellgenauigkeit zu finden. MLflow ermöglicht es Ihnen, die Inputs und Outputs dieser Trainingsiterationen zu verfolgen, wodurch die Wiederholbarkeit von Studien verbessert und die Zusammenarbeit zwischen Datenwissenschaftlerinnen und -wissenschaftlern gefördert wird. Mit vollständig verwalteten MLflow-Funktionen können Sie MLflow-Tracking-Server für jedes Team erstellen, was eine effiziente Zusammenarbeit bei ML-Experimenten ermöglicht.
Amazon SageMaker mit MLflow verwaltet den gesamten Machine-Learning-Lebenszyklus und optimiert so das effiziente Modelltraining, die Nachverfolgung von Experimenten und die Reproduzierbarkeit in verschiedenen Frameworks und Umgebungen. Die Lösung bietet eine zentrale Oberfläche, auf der Sie laufende Trainingsjobs visualisieren, Experimente mit anderen teilen und Modelle direkt aus Experimenten registrieren können.
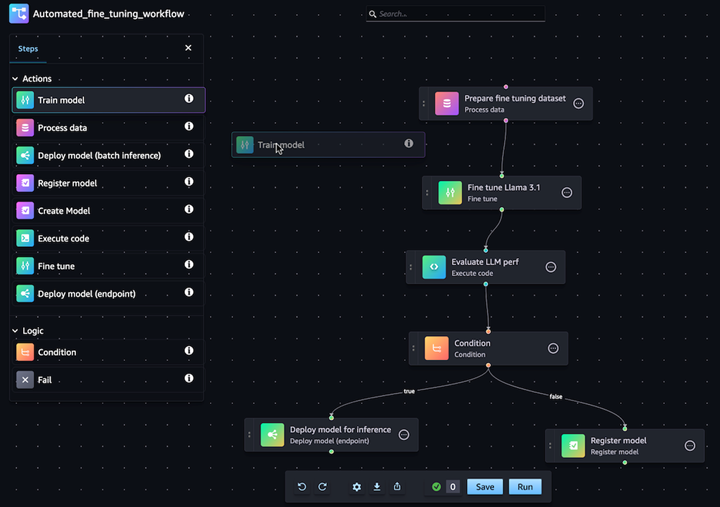
Workflows zur Anpassung generativer KI-Modelle automatisieren
Mit Amazon SageMaker Pipelines können Sie den End-to-End-ML-Workflow aus Datenverarbeitung, Modelltraining, Feinabstimmung, Bewertung und Bereitstellung automatisieren. Erstellen Sie Ihr eigenes Modell oder passen Sie ein Basismodell aus SageMaker Jumpstart mit wenigen Klicks im visuellen Editor von Pipelines an. Sie können SageMaker Pipelines so konfigurieren, dass sie in regelmäßigen Abständen oder beim Auslösen bestimmter Ereignisse automatisch ausgeführt werden (z. B. neue Trainingsdaten in S3)
Einfache Bereitstellung und Verwaltung von Modellen in der Produktion
Schnelles Reproduzieren Ihrer Modelle für die Fehlersuche
Häufig müssen Sie Modelle in der Produktion reproduzieren, um das Modellverhalten zu beheben und die Grundursache zu ermitteln. Um dies zu unterstützen, protokolliert Amazon SageMaker jeden Schritt Ihres Workflows und erstellt einen Prüfungspfad von Modellartefakten wie Trainingsdaten, Konfigurationseinstellungen, Modellparameter und Lerngradienten. Mithilfe des Lineage-Trackings können Sie Modelle erneut erstellen, um potenzielle Probleme zu beheben.
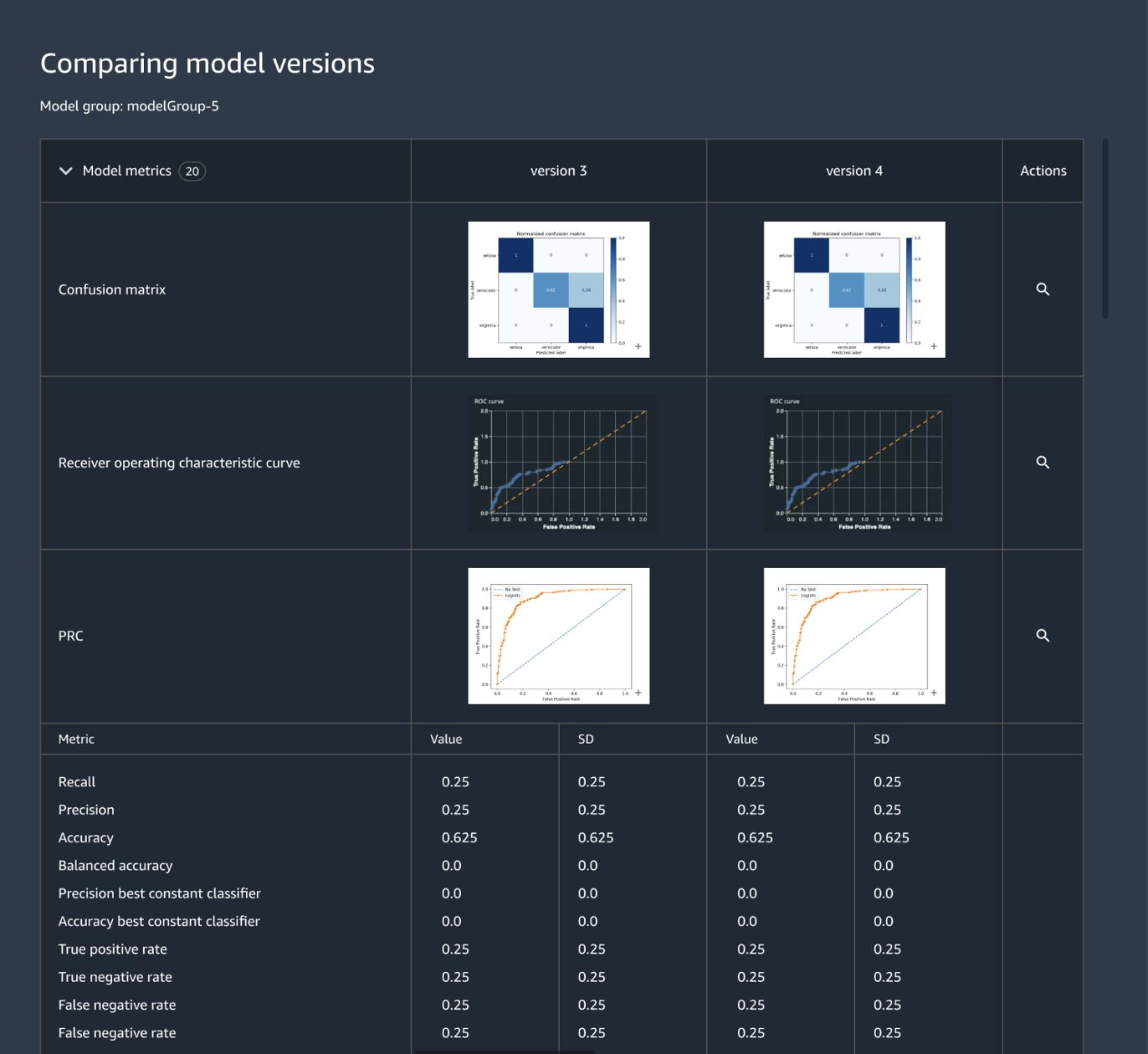
Zentrales Nachverfolgen und Verwalten von Modellversionen
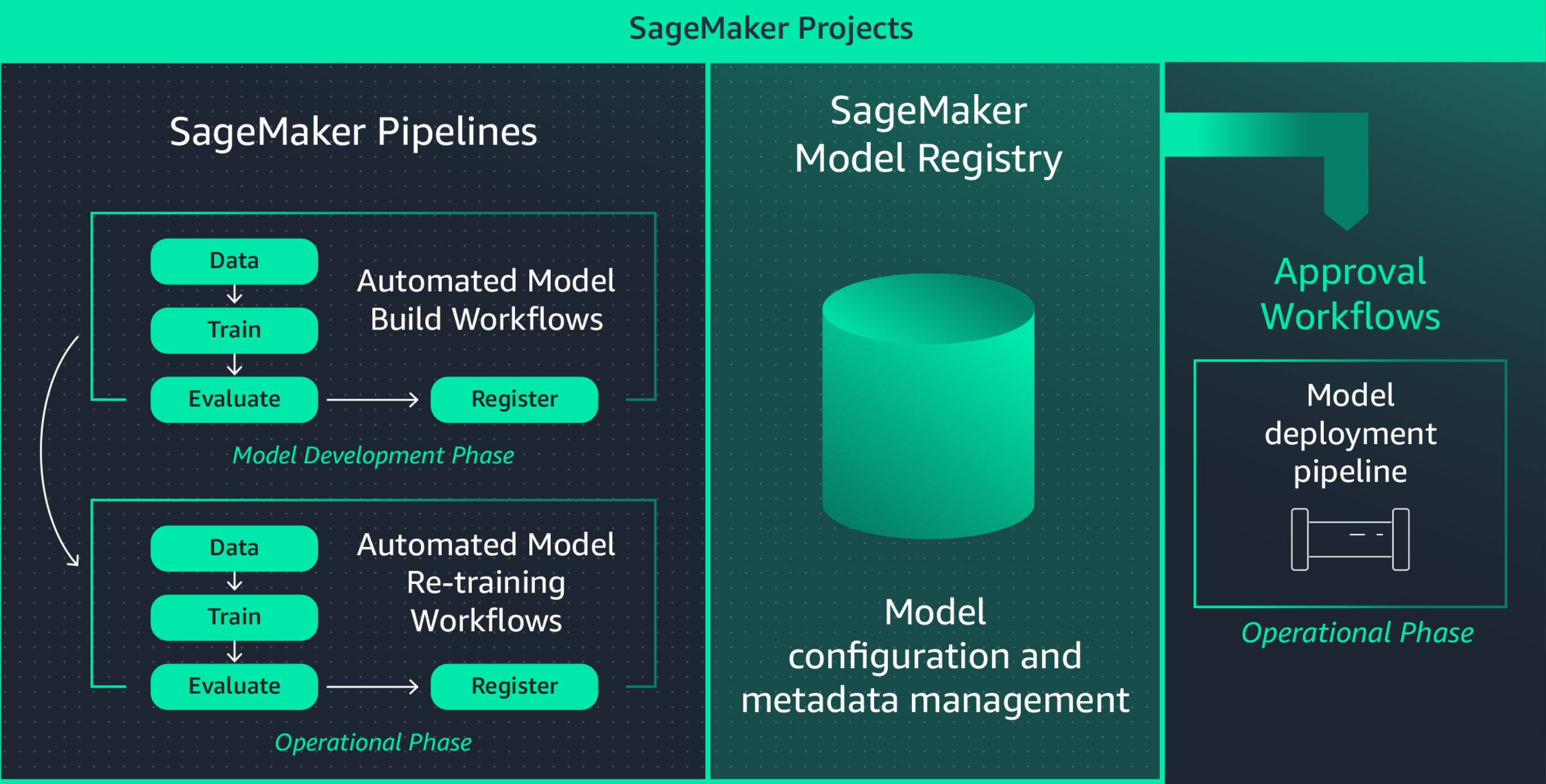
Das Erstellen einer ML-Anwendung umfasst die Entwicklung von Modellen, Daten-Pipelines, Training-Pipelines und Validierungstests. Mit Amazon SageMaker Model Registry können Sie Modellversionen, deren Metadaten, wie beispielsweise die Gruppierung von Anwendungsfällen, und Modellleistungsmetriken in einem zentralen Repository nachverfolgen, in dem es einfach ist, das richtige Modell für die Bereitstellung auf der Grundlage Ihrer Geschäftsanforderungen auszuwählen. Darüber hinaus protokolliert SageMaker Model Registry automatisch Genehmigung-Workflows für Audit und Compliance.
ML-Infrastruktur durch Code definieren
Die Orchestrierung der Infrastruktur durch erklärende Konfigurationsdateien, allgemein als „Infrastructure-as-Code“ bezeichnet, ist ein beliebter Ansatz für die Bereitstellung der ML-Infrastruktur und zur Implementierung der Lösungsarchitektur wie sie von CI/CD-Pipelines oder Bereitstellungstools vorgegeben wird. Mit Amazon SageMaker Projects können Sie Infrastructure-as-Code mithilfe von vorgefertigten Vorlagendateien schreiben.
Automatisierung von Integration- und Bereitstellungs- (CI/CD) Workflows
ML-Entwicklungs-Workflows sollten in Integrations- und Bereitstellungs-Workflows integriert werden, um schnell neue Modelle für Produktionsanwendungen bereitzustellen. Amazon SageMaker Projects integriert CI/CD-Praktiken in ML, wie beispielsweise die Aufrechterhaltung der Parität zwischen Entwicklungs- und Produktionsumgebung, Quell- und Versionskontrolle, A/B-Tests und End-to-End-Automatisierung. Dadurch bringen Sie ein Modell sofort nach der Freigabe in Produktion und steigern die Agilität.
Darüber hinaus bietet Amazon SageMaker integrierte Sicherheitsvorkehrungen, die Ihnen dabei helfen, die Endpunktverfügbarkeit aufrechtzuerhalten und das Bereitstellungsrisiko zu minimieren. SageMaker übernimmt die Einrichtung und Orchestrierung bewährter Bereitstellungsverfahren wie Blue/Green-Bereitstellungen, um die Verfügbarkeit zu maximieren, und integriert diese mit Mechanismen zur Endpunktaktualisierung, wie automatischen Rollback-Mechanismen. So können Sie Probleme frühzeitig automatisch erkennen und Korrekturmaßnahmen ergreifen, bevor sie die Produktion wesentlich beeinträchtigen.
Kontinuierliches Neutrainieren der Modelle zur Aufrechterhaltung der Prognosequalität
Sobald ein Modell in Produktion ist, müssen Sie seine Leistung überwachen. Dazu konfigurieren Sie Warnmeldungen, damit ein Datenwissenschaftler auf Abruf das Problem beheben und ein erneutes Training auslösen kann. Amazon SageMaker Model Monitor unterstützt Sie bei der Aufrechterhaltung der Qualität, indem es Modell- und Konzeptabweichungen in Echtzeit erkennt und Ihnen Warnmeldungen sendet, damit Sie sofort Maßnahmen ergreifen können. SageMaker Model Monitor überwacht fortlaufend die Leistungsmerkmale des Modells, wie beispielsweise die Genauigkeit, die die Anzahl der korrekten Prognosen im Vergleich zur Gesamtzahl der Prognosen misst, damit Sie Anomalien beheben können. SageMaker Model Monitor ist in SageMaker Clarify integriert, um mehr Transparenz in Bezug auf potenzielle Verzerrungen zu schaffen.
Optimierung der Bereitstellung von Modellen im Hinblick auf Leistung und Kosten
Amazon SageMaker vereinfacht die Bereitstellung von ML-Modellen für Inferenzen mit hoher Leistung und geringen Kosten für jeden Anwendungsfall. Die Lösung stellt eine umfangreiche Auswahl an ML-Infrastruktur- und Modellbereitstellungsoptionen zur Verfügung, um all Ihre ML-Inferenzanforderungen zu erfüllen.

Ressourcen für SageMaker MLOps
Neuerungen
Amazon-SageMaker-Autopilot-Experimente aus Amazon SageMaker Pipelines starten, um MLOps-Workflows einfach zu automatisieren
30.11.2022
Amazon SageMaker Pipelines unterstützt jetzt den Test von Machine-Learning-Workflows in deiner lokalen Umgebung
17.08.2022
Amazon SageMaker Pipelines unterstützt jetzt die kontoübergreifende Freigabe von Pipeline-Einheiten
08.09.2022
MLOps Workload Orchestrator fügt Unterstützung für die´Modellerklärbarkeit und Modellabweichungsüberwachung von Amazon SageMaker hinzu
02.02.2022
Amazon SageMaker Pipelines unterstützt jetzt Gleichzeitigkeitskontrolle
21.01.2022