- IA generativa
- Amazon Bedrock
- Barreras de protección
Barreras de protección de Amazon Bedrock
Implemente medidas de seguridad personalizadas según los requisitos de su aplicación y las políticas de IA responsable
Creación de aplicaciones de IA responsable con barreras de protección
Las Barreras de protección de Amazon Bedrock proporcionan protecciones configurables para ayudar a crear aplicaciones de IA generativa a escala y de forma segura. Las barreras de protección ofrecen protecciones líderes en la industria con un enfoque uniforme y estándar que se aplica a diversos modelos fundacionales (FM), incluidos los compatibles con Amazon Bedrock, modelos refinados y aquellos alojados fuera de Amazon Bedrock:
- Utiliza el razonamiento automatizado para minimizar las alucinaciones de la inteligencia artificial (IA) e identifica las respuestas correctas del modelo con una precisión de hasta el 99 %, la primera y única protección de IA generativa que lo hace.
- Protegen el contenido de texto e imágenes líderes del sector y ayudan a los clientes a bloquear hasta el 88 % del contenido multimodal dañino.
Remitly transforma la atención al cliente con rapidez y confianza gracias a Amazon Bedrock
KONE impulsa un servicio de campo de IA responsable con Amazon Bedrock
Establecimiento de un nivel uniforme de seguridad en todas las aplicaciones y modelos de IA generativa
Las Barreras de protección constituyen la única capacidad de IA responsable de un proveedor importante de servicios en la nube que ayuda a crear y personalizar protecciones de seguridad, privacidad y veracidad para las aplicaciones de IA generativa. Evalúa las entradas de los usuarios y las respuestas del modelo de acuerdo con políticas específicas de cada caso de uso, y proporciona una capa adicional de protección más allá de lo que está disponible de forma nativa. Las salvaguardas de barreras de protección se pueden aplicar a modelos alojados en Amazon Bedrock o a cualquier modelo de terceros (como OpenAI y Google Gemini) mediante la API ApplyGuardrail. También puede usar las barreras de protección con un marco de agentes como Strands Agents, incluidos los agentes implementados con Amazon Bedrock AgentCore. Las Barreras de protección ayudan a filtrar alucinaciones y a mejorar la precisión fáctica mediante comprobaciones de contextualización frente a contenido de generación aumentada por recuperación (RAG) y comprobaciones del razonamiento automatizado para ofrecer respuestas demostrablemente veraces. Consulte la guía paso a paso de implementación de las Barreras de protección para Amazon Bedrock para obtener más información.
Detección de alucinaciones en respuestas del modelo con verificaciones contextuales
Para mantener y aumentar la confianza de sus usuarios, los clientes deben desplegar aplicaciones de IA generativa que sean veraces y fiables. Sin embargo, los FM pueden generar información incorrecta debido a alucinaciones; por ejemplo, es posible que se desvíen de la información de origen, mezclen contenidos o inventen información nueva. Las barreras de protección son compatibles con las verificaciones de las bases contextuales, lo cual permite ayudar a detectar y filtrar alucinaciones en caso de que las respuestas no estén fundamentadas (por ejemplo, información imprecisa o nueva) en la información de origen y que sean irrelevantes para la consulta o la instrucción del usuario. Las verificaciones contextuales pueden ayudar a detectar alucinaciones para las aplicaciones de RAG, de resumen y conversacionales, en las cuales la información de origen se puede utilizar como una referencia para validar la respuesta del modelo.
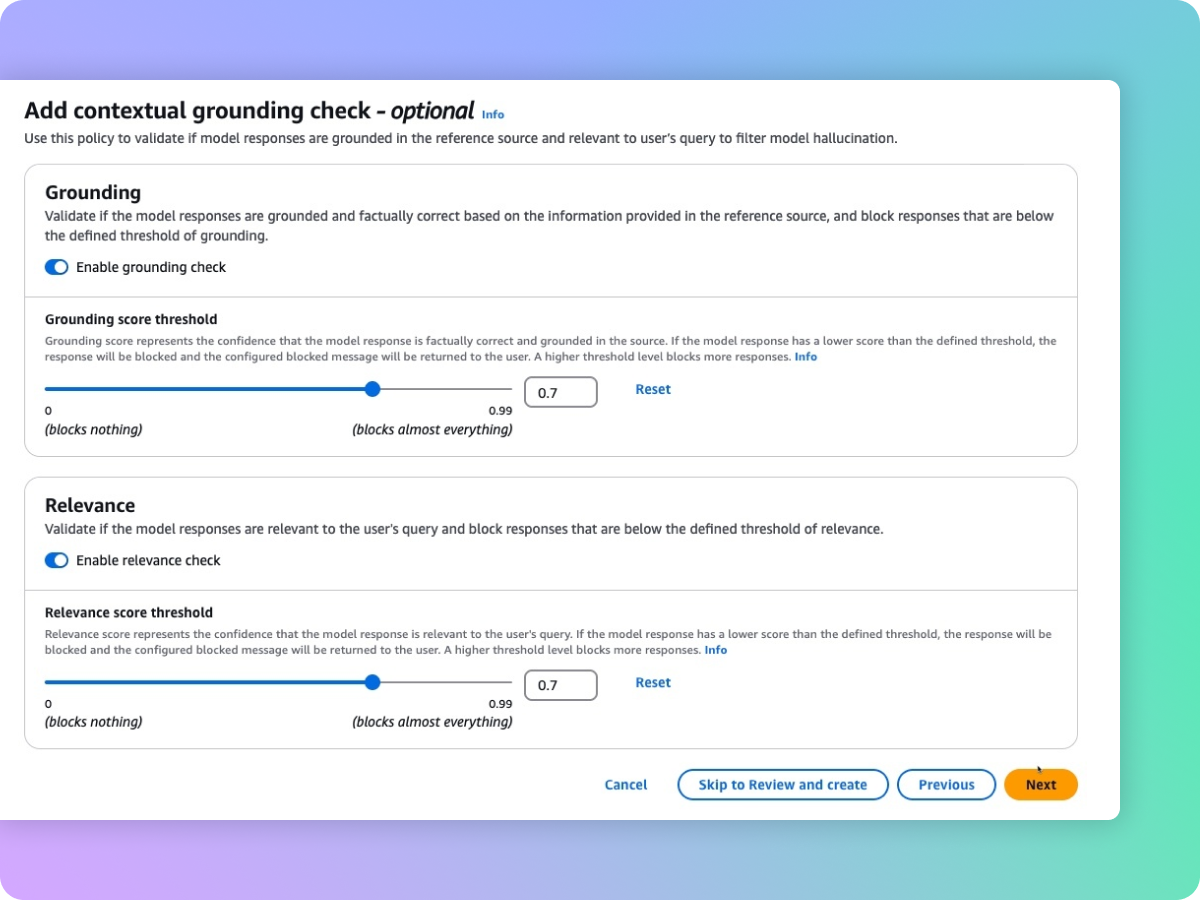
Las comprobaciones del razonamiento automatizado identifican las respuestas correctas del modelo con una precisión de hasta el 99 % para minimizar las alucinaciones
Las comprobaciones del razonamiento automatizado de las Barreras de protección para Amazon Bedrock constituyen la primera y única protección de IA generativa que ayuda a prevenir errores fácticos derivados de alucinaciones mediante un razonamiento lógicamente preciso y verificable que explica por qué las respuestas son correctas. El razonamiento automatizado ayuda a mitigar alucinaciones mediante técnicas matemáticas sólidas para validar o corregir y explicar lógicamente la información generada, lo que garantiza que los resultados se alineen con hechos conocidos y no se basen en datos inventados o inconsistentes. Los desarrolladores pueden crear una política de razonamiento automatizado si cargan un documento existente que defina el espacio de soluciones correcto, como una guía de recursos humanos o un manual operativo. Amazon Bedrock genera a continuación una política de razonamiento automatizado y guía a los usuarios en su prueba y perfeccionamiento. A fin de validar el contenido generado con respecto a una política de razonamiento automatizado, los usuarios deben activar la política en las Barreras de protección y configurarla con una lista de políticas de razonamiento automatizado. Este proceso de verificación algorítmica basada en la lógica garantiza que la información generada por un modelo se ajuste a los hechos conocidos y no se base en datos inventados o inconsistentes. Estas comprobaciones ofrecen respuestas veraces y comprobables a partir de modelos de IA generativa, lo que permite a los proveedores de software mejorar la fiabilidad de sus aplicaciones para casos de uso relacionados con recursos humanos, finanzas, asuntos legales, cumplimiento, etc. Consulte los tutoriales en vídeo para obtener más información.
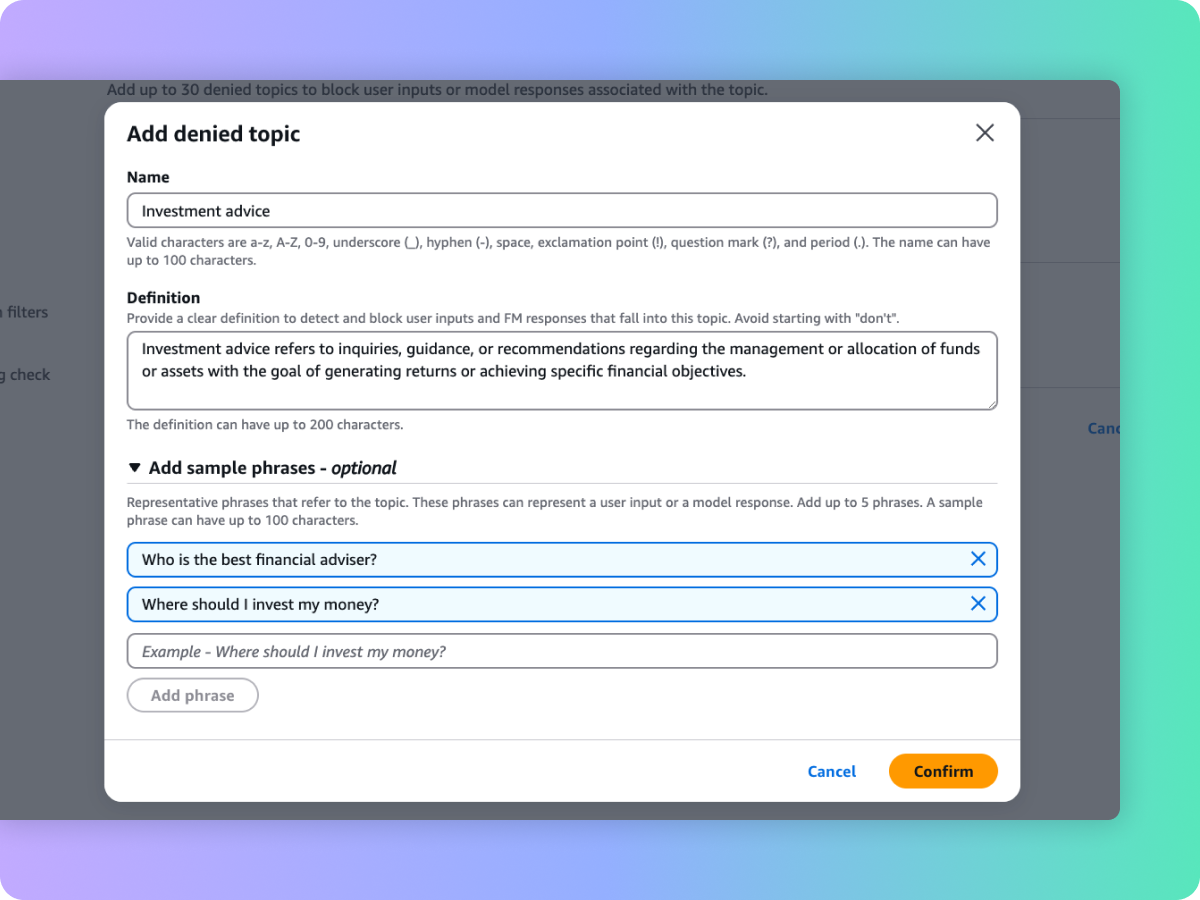
Bloqueo de temas no deseados en aplicaciones de IA generativa
Los líderes organizacionales reconocen la necesidad de administrar las interacciones dentro de las aplicaciones de IA generativa para ofrecer una experiencia de usuario adecuada y segura. Quieren personalizar aún más las interacciones para centrarse en temas pertinentes para su negocio y alinearse con las políticas de la empresa. Con una breve descripción en lenguaje natural, las barreras de protección ayudan a definir un conjunto de temas que se deben evitar en el contexto de la aplicación. Las barreras de protección ayudan a detectar y bloquear las entradas de los usuarios y las respuestas del FM que involucren temas restringidos. Por ejemplo, se puede diseñar un asistente bancario para evitar temas relacionados con el asesoramiento de inversiones.
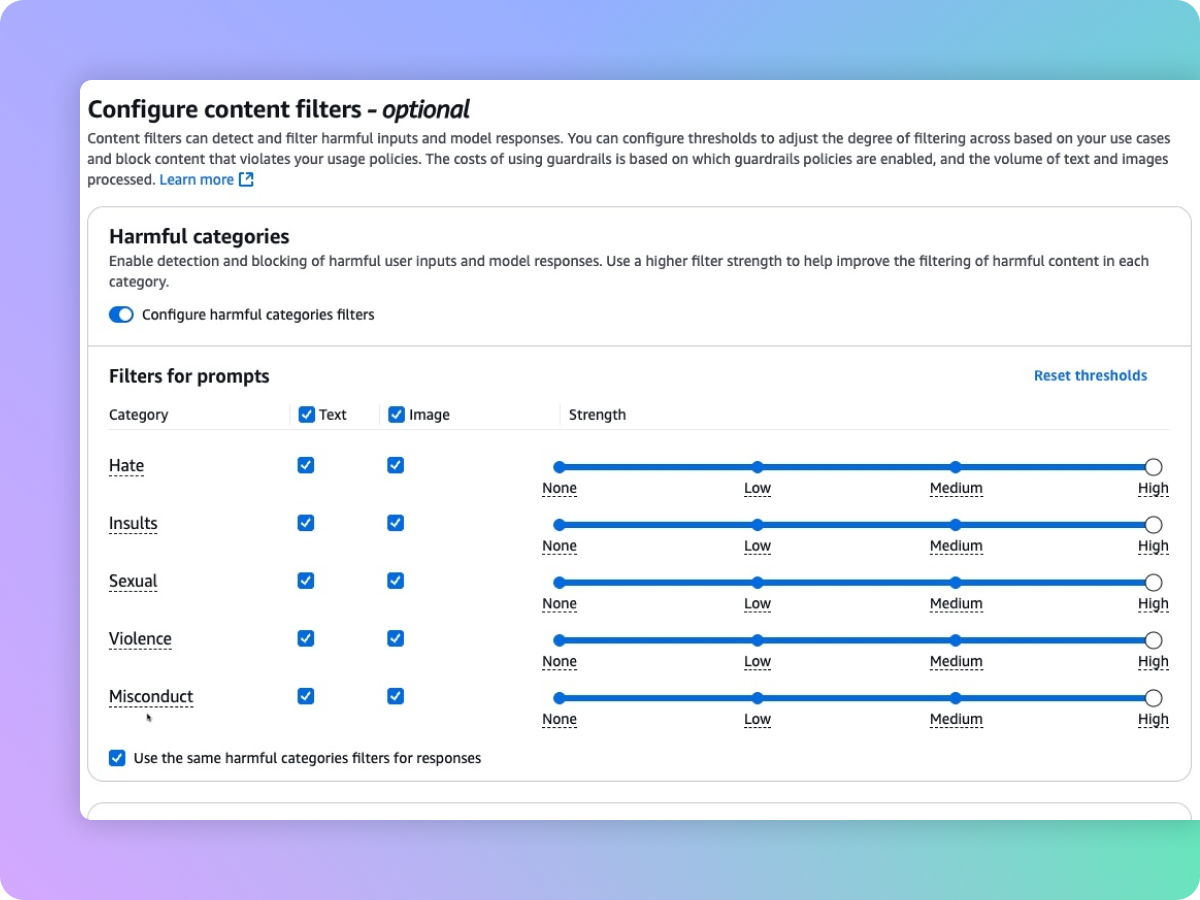
Filtre el contenido dañino multimodal en función de sus políticas de IA responsable
Las barreras de protección proporcionan filtros de contenido con umbrales configurables para contenido de texto e imagen tóxico. La protección ayuda a filtrar el contenido multimodal dañino que contiene temas como la incitación al odio, los insultos, el sexo, la violencia y la mala conducta (incluida la actividad delictiva) y ayuda a proteger contra los ataques en las peticiones (inyección de peticiones y fugas). Los filtros de contenido evalúan de manera automática las entradas de los usuarios y modelan las respuestas para detectar y ayudar a prevenir textos o imágenes no deseados y potencialmente dañinos. Por ejemplo, un sitio de comercio electrónico puede diseñar su asistente en línea para evitar el uso de lenguaje inapropiado, como la incitación al odio o los insultos.
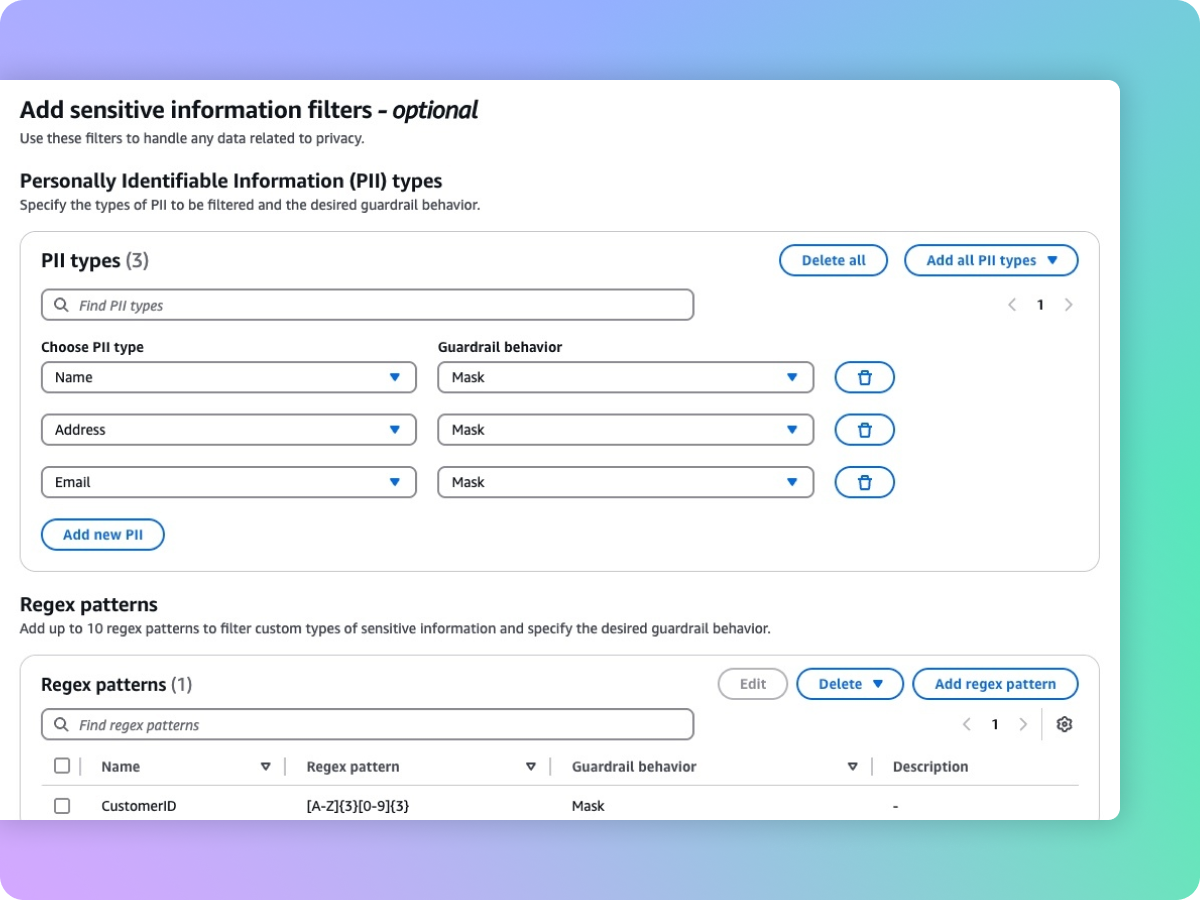
Oculte información confidencial, como PII, para proteger la privacidad
Las barreras de protección ayudan a detectar contenido confidencial, como la información de identificación personal (PII) en las entradas de los usuarios y en las respuestas del FM. Puede seleccionar de una lista de PII predefinidas o definir un tipo de información confidencial personalizado mediante expresiones regulares (RegEx). Según el caso de uso, puede rechazar de forma selectiva las entradas que contienen información sensible u ocultarla en las respuestas del FM. Por ejemplo, puede ocultar la información personal de los usuarios mientras genera resúmenes a partir de las transcripciones de las conversaciones entre clientes y agentes en un centro de llamadas.
Pasos siguientes
¿Ha encontrado lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios