Análisis en AWS
Un conjunto completo de funcionalidades para cada carga de trabajo de análisis, optimizadas para lograr una mejor relación precio-rendimiento y una mejor escalabilidad
Información general
AWS ofrece un conjunto completo de funcionalidades para cada carga de trabajo de análisis. Desde el procesamiento de datos y el análisis de SQL hasta la transmisión, la búsqueda y la inteligencia empresarial, AWS ofrece una relación precio-rendimiento y escalabilidad incomparables con gobernanza integrada. Elija servicios personalizados y optimizados para cargas de trabajo específicas u optimice y administre sus flujos de trabajo de datos e IA con Amazon SageMaker. Ya sea que esté iniciando su viaje con los datos o buscando una experiencia integrada, AWS brinda las funcionalidades de análisis adecuadas para ayudarlo a reinventar su negocio con datos.
Impulse resultados empresariales tangibles con análisis en AWS
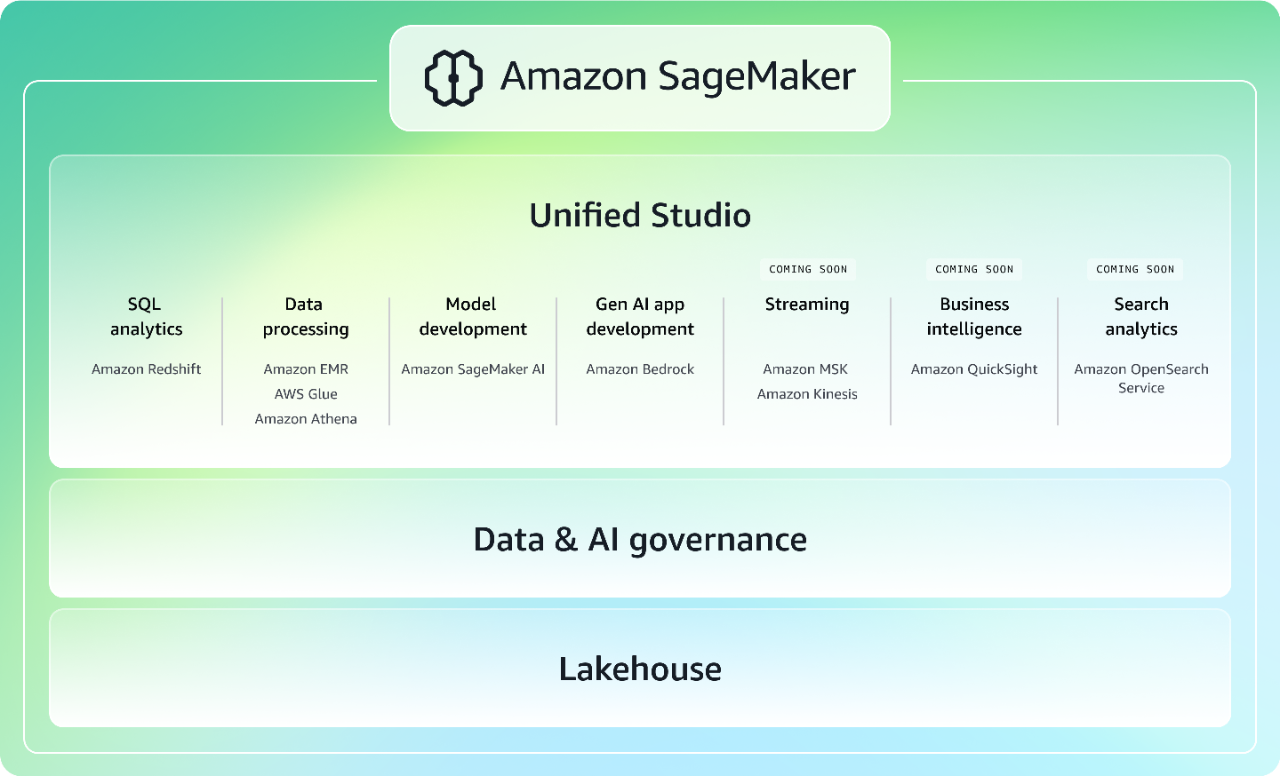
Acelere los datos, el análisis y la IA con una experiencia integrada
Al combinar las capacidades de análisis y machine learning (ML) de AWS ampliamente adoptadas, la próxima generación de Amazon SageMaker ofrece una experiencia integrada de análisis e IA con acceso unificado a todos sus datos. Colabore y cree más rápido desde un estudio unificado con las conocidas herramientas de AWS para el desarrollo de modelos, el desarrollo de aplicaciones de IA generativa, el procesamiento de datos y el análisis de SQL, aceleradas por Amazon Q Developer, el asistente de IA generativa más capaz para el desarrollo de software. Acceda a todos sus datos, ya sea que estén almacenados en lagos de datos, almacenes de datos u orígenes de datos federados o de terceros, con una gobernanza integrada para abordar las necesidades de seguridad empresarial. Obtenga más información sobre SageMaker.
Habilitación de estrategias multinube con AWS
AWS ofrece una colección completa de potentes servicios de análisis que permiten el acceso y el procesamiento de datos sin interrupciones en entornos híbridos y multinube. Puede lograr esta flexibilidad mediante consultas federadas, integración de datos, movimiento seguro de datos y compatibilidad con estándares abiertos, lo que le permite obtener información de todos sus datos, independientemente de dónde residan.
Amazon Athena le permite consultar y obtener información de los datos almacenados en diversos orígenes de datos externos, como Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server y muchas otros, sin necesidad de copiar ni transformar los datos.
AWS Glue simplifica el descubrimiento, la preparación y la integración de todos sus datos a cualquier escala, con conectores para más de cien orígenes de datos diferentes que abarcan el almacenamiento en la nube, las bases de datos y los servicios de análisis. Las integraciones sin ETL de Glue facilitan la ingesta y la replicación de datos de aplicaciones de terceros, como Salesforce, SAP, Facebook Ads e Instagram Ads, directamente en sus lake houses, lagos de datos y almacenamientos de datos de AWS. AWS Glue también ofrece interoperabilidad de datos mediante la compatibilidad con estándares abiertos como Apache Hive, Apache Parquet y Apache Iceberg.
La próxima generación de Amazon SageMaker se basa en una arquitectura abierta de lake house de datos, que proporciona acceso unificado a los lagos de datos y almacenamientos de datos de AWS, así como a orígenes de datos federados como Google BigQuery y Snowflake. Esta arquitectura de lake house es totalmente compatible con Apache Iceberg, lo que le brinda flexibilidad para acceder a datos de forma local y consultarlos mediante cualquier herramienta y motor compatible con Iceberg.
Uso de análisis para los seres humanos y la IA
Potencie el análisis a escala con servicios personalizados para almacenar, consultar, transmitir, procesar y gobernar datos. Desde los formatos de tabla abierta (OTF) hasta la infraestructura agéntica, AWS está evolucionando los motores y las aplicaciones de análisis para adaptarse al panorama de los análisis, que cambia rápidamente. En esta sesión, descubra cómo AWS ofrece soluciones optimizadas creadas tanto para los usuarios humanos como para los flujos de trabajo agénticos.

Servicios
|
Categoría de análisis
|
Descripción
|
Servicios y funcionalidades de AWS
|
|---|---|---|
|
Transmisión
|
Cree, escale y opere aplicaciones y canalizaciones de datos en tiempo real sin la carga de la administración de la infraestructura. |
|
|
Almacén de lago de datos, almacén de datos, lago de datos
|
Acceda a todos sus datos en los lake houses de datos, los almacenamientos de datos y el lago de datos y analícelos. |
|
|
Procesamiento de datos
|
Analice, prepare e integre datos para el análisis y la IA mediante marcos de código abierto. |
|
|
Inteligencia empresarial
|
Cree, descubra y comparta información significativa a través de modernos paneles interactivos, informes ultraprecisos, consultas en lenguaje natural y análisis integrados. |
|
|
Análisis de búsqueda
|
Busque, supervise y analice de manera segura y en tiempo real los datos empresariales y operativos. |
|
|
Gobernanza de datos e IA
|
Catalogue, descubra, comparta y gobierne los datos almacenados en orígenes de AWS, en las instalaciones y de terceros. |
El impacto económico total de la estrategia moderna de datos de AWS
Según lo informado por Forrester, la estrategia moderna de datos de Amazon Web Services facilita el ahorro de costos y los beneficios empresariales.
Estadísticas
¿Encontró lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios