Blog de Amazon Web Services (AWS)
Prácticas recomendadas de replicación con Amazon RDS PostgreSQL
Por Vivek Singh, Technical Account Manager
Amazon RDS para PostgreSQL le permite configurar fácilmente réplicas de la instancia de PostgreSQL de origen para aliviar la carga de trabajo de lectura y crear recursos de recuperación ante desastres (DR). Puede configurar réplicas de lectura en la misma región que el origen o en una región diferente.
Cuando se usa una instancia de réplica de lectura de RDS PostgreSQL, se transfiere la carga de trabajo de lectura a una instancia de réplica y se reservan los recursos informáticos de la instancia de origen para las actividades de escritura. Sin embargo, debe configurar las réplicas de lectura correctamente y establecer los valores de parámetros adecuados para evitar retrasos (latencia) en la replicación.
Resumen
En esta publicación, proporciono algunas prácticas recomendadas para configurar correctamente las réplicas de lectura. Analizo los pros y los contras de varias opciones de replicación de RDS PostgreSQL, incluida la replicación intra-regional, entre regiones y lógica. Recomiendo valores de parámetros y métricas apropiadas para monitorear. Los siguientes pasos muestran cómo optimizar estrategias de DR, cargas de trabajo solo-lectura, y el buen estado de la instancia de origen minimizando la latencia en la replicación.
Recomendación General
Como práctica recomendada general, asegúrese de que las consultas SQL que ejecuta en réplicas de lectura utilicen la última versión de los datos disponibles en la instancia de origen. Puede confirmar la versión de los datos consultando latencia de replicación en las métricas de Amazon CloudWatch. Al minimizar la latencia de replicación, se evitan los resultados de consultas basadas en datos obsoletos y comprometer el estado de la instancia de origen.
Replicación Intra-Región
Para crear una réplica de lectura en la misma región de AWS que la instancia de origen, PostgreSQL de RDS utiliza la replicación “streaming” nativa de PostgreSQL. Cambios en los datos en la instancia de origen se transmiten a la réplica de lectura mediante la replicación streaming disponible en PostgreSQL. Si el proceso se retrasa por algún motivo, la replicación experimenta latencia. El siguiente diagrama ilustra cómo RDS PostgreSQL realiza la replicación entre una instancia de origen y una réplica en la misma región:
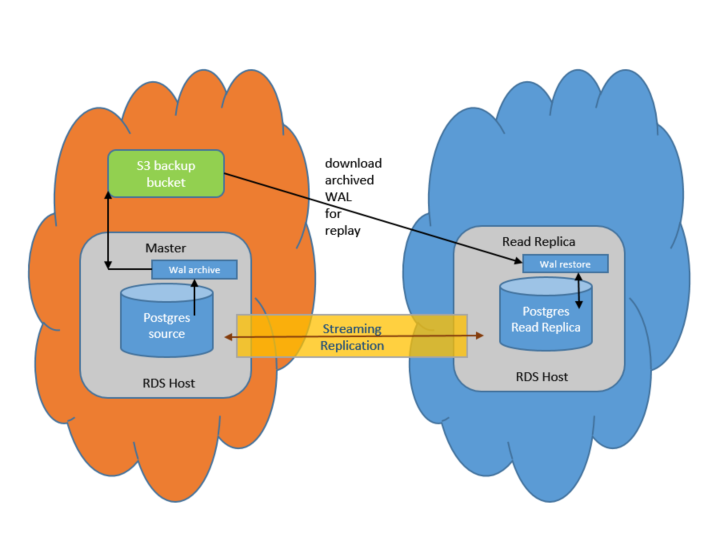
En las siguientes secciones, describo cómo ajustar las instancias de PostgreSQL para replicar las instancias de RDS PostgreSQL alojadas en la misma región de forma óptima.
Valor óptimo para wal_keep_segments
En Postgres, el parámetro wal_keep_segments especifica el número máximo de segmentos del archivo de registro WAL que se guardan en el directorio pg_wal. Postgres archiva cualquier segmento de WAL que supere este parámetro en los bucket de Amazon S3.
Si la réplica de lectura no encuentra un segmento WAL en la ubicación pg_wal, la réplica de lectura descarga el segmento del bucket de Amazon S3 correspondiente, luego lo restaura y lo aplica. En general, la restauración utilizando este proceso se realiza más lentamente que la replicación por streaming. Por lo tanto, cuantos más segmentos de WAL mantenga en la instancia, más rápida será la replicación.
Cuando la replicación streaming se detiene, debería ver el siguiente mensaje de error en la bitácora de eventos de la base de datos: Streaming replication has stopped. Si la replicación streaming se detiene durante más tiempo, es posible que vea este mensaje en la bitácora de eventos de la base de datos: Streaming replication has been terminated.
De forma predeterminada, RDS PostgreSQL establece wal_keep_segments en 32. Puede modificar el valor de este parámetro mediante el Grupo de parámetros de RDS. Este parámetro es dinámico y cambiar su valor no requiere el reinicio de la instancia.
Por ejemplo, el siguiente mensaje en la bitácora de eventos de Postgres sugiere que RDS está recuperando una réplica de lectura mediante la reproducción de archivos WAL archivados en Amazon S3:
2018-11-07 21:01:16 UTC::@:[23180]:LOG: restored log file "000000010000001A000000D3“ from archive
Después de que RDS logra reproducir suficientes segmentos WAL archivados en la réplica para ponerse al día, la réplica de lectura reanuda la replicación streaming. En este punto, RDS escribe una línea similar a la siguiente en la bitácora de eventos:
2018-11-07 21:41:36 UTC::@:[24714]:LOG: started streaming WAL from primary at 1B/B6000000 on timeline 1
Como práctica recomendada, intente evitar superar el número máximo de segmentos de archivos de registro de WAL del directorio pg_wal y, por lo tanto, el proceso más lento de restauración de segmentos desde el bucket de Amazon S3. Para ajustar este valor, vuelva a observar la actividad de escritura en la instancia de origen.
Antes de lanzar una nueva réplica de lectura, modifique el valor de wal_keep_segments. Establezca este parámetro lo suficientemente alto como para evitar que los archivos WAL se archiven al iniciar la replicación streaming. Por ejemplo, si establece wal_keep_segments en 500, puede mantener alrededor de 500 segmentos WAL en la instancia de origen.
Para PostgreSQL 10 y versiones anteriores, el tamaño de cada segmento WAL es de 16 MB. El espacio utilizado por los segmentos de WAL cuenta para el almacenamiento total asignado a la instancia RDS PostgreSQL.
Evite actividad de escritura intensa en la instancia de origen
En la instancia de origen, como parte de la actividad de escritura, WAL primero registra la transacción y, a continuación, escribe esos cambios en bloques de almacenamiento. Una actividad de escritura elevada en la instancia de origen puede generar una gran afluencia de archivos WAL. La multiplicación de archivos WAL y la reproducción de estos archivos en la réplica de lectura ralentiza el rendimiento general de la replicación.
Para realizar un seguimiento de la velocidad de creación de archivos WAL, consulte la métrica TransactionLogsGeneration en las métricas de AWS CloudWatch. Este parámetro muestra el tamaño de los registros de transacciones generados por segundo. Los siguientes diagramas describen cómo la alta actividad de escritura en el origen afecta al retraso de la replicación:
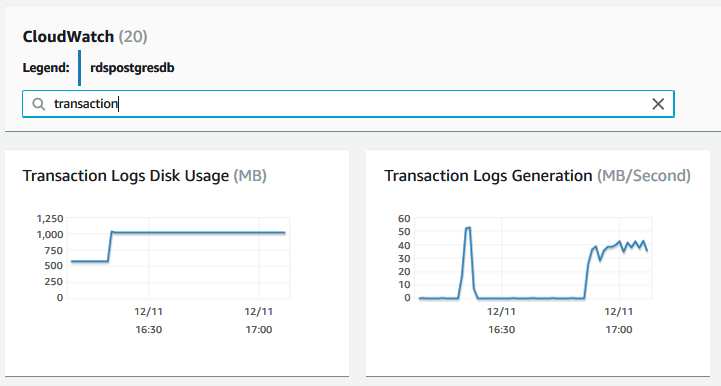
Las métricas TransactionLogsDiskUsage, TransactionLogsGeneration, WriteIOps, WriteThroughput y WriteLatency muestran que la instancia de origen estaba sometida a una fuerte presión de escritura entre las 16:20 y las 17:00. Esta presión aumentó el retraso de replicación en la réplica de lectura hasta 11 minutos en ese mismo rango de tiempo:
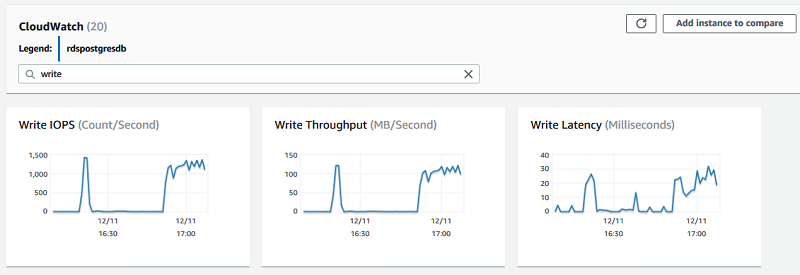

Para evitar esta situación, controle y distribuya la actividad de escritura en la instancia de origen. En lugar de realizar muchas actividades de escritura juntas, divídalas en pequeños paquetes de tareas y distribúyalas de manera uniforme en varias transacciones. Utilice alertas de AWS CloudWatch en métricas como WriteLatency y WriteIOPS para mantenerse alerta ante las escrituras intensas en la instancia de origen. Establezca wal_compression en ON para reducir la cantidad de WAL y, con el tiempo, reducir el retraso de replicación.
Evite el bloqueo exclusivo en las tablas de instancias de origen
En la instancia de origen, cuando se ejecutan comandos como DROP TABLE, TRUNCATE, REINDEX, CLUSTER, VACUUM FULL, and REFRESH MATERIALIZED VIEW (without CONCURRENTLY), Postgres procesa un Access Exclusive lock.
ACCESS EXCLUSIVE es el modo de bloqueo más restrictivo (entra en conflicto con todos los demás modos de bloqueo). Este bloqueo impide que todas las demás transacciones accedan a la tabla durante la duración de la retención del bloqueo. Por lo general, la tabla permanece bloqueada hasta que finaliza la transacción. Esta actividad de bloqueo se registra en WAL y se reproduce y se mantiene en las réplicas de lectura. Cuanto más tiempo permanezca la tabla bajo un bloqueo ACCESS EXCLUSIVE, mayor será el retraso de la replicación.
Para evitar estas situaciones, AWS recomienda monitorear esta situación consultando periódicamente las tablas de catálogo pg_locks y pg_stat_activity. Por ejemplo, la siguiente consulta supervisa los bloqueos en las instancias de Postgres 9.6 y posteriores de Postgres:
SELECT pid,
usename,
pg_blocking_pids(pid) AS blocked_by,
QUERY AS blocked_query
FROM pg_stat_activity
WHERE cardinality(pg_blocking_pids(pid)) > 0;Configuración de parámetros en réplicas de lectura
También puede afectar la replicación general si establece algunos parámetros en la instancia de réplica. El parámetro hot_standby_feedback especifica si la instancia de réplica envía comentarios a la instancia de origen sobre las consultas que se están ejecutando actualmente en la instancia de réplica.
Al habilitar este parámetro, se selecciona el siguiente mensaje de error en el origen y se pospone VACUUM en las tablas relacionadas (a menos que la consulta de lectura se haya completado en la réplica):
ERROR: canceling statement due to conflict with recovery
Detail: User query might have needed to see row versions that must be removed
De este modo, una instancia de réplica con la opción hot_standby_feedback habilitada puede servir consultas SQL de larga ejecución, pero también puede aumentar las tablas en la instancia de origen. Si no supervisa las consultas de larga duración en las instancias de réplica, es posible que se enfrente a problemas graves en la instancia de origen, como falta de almacenamiento y reciclamiento de IDs de transacción.
Como alternativa, puede habilitar parámetros como max_standby_archive_delay o max_standby_streaming_delay en la instancia de réplica, para permitir la finalización de consultas de lectura de larga duración. Ambos parámetros detienen la reproducción de WAL en la réplica si los datos de origen se modifican mientras se ejecutan consultas de lectura en la réplica. Un valor de -1 permite que la reproducción de WAL espere hasta que se complete la consulta de lectura. Sin embargo, esta pausa aumenta el retraso de replicación indefinidamente y provoca un alto consumo de almacenamiento en el origen debido a la acumulación de WAL.
Si modifica alguno de estos tres parámetros, preste atención a las consultas de lectura de larga duración en la instancia de réplica para mantener la instancia de origen en buen estado y gestionar cualquier retraso de replicación.
También puede resultarle útil la siguiente consulta SQL. Esta consulta elimina las transacciones de lectura que se ejecutan durante más de cinco minutos:
SELECT
pg_terminate_backend(pid)
FROM pg_stat_activity
WHERE (now() - pg_stat_activity.query_start) > interval '5 minutes';Configuración de la réplica de lectura
Configuraciones incorrectas de las instancias de réplicas de lectura también pueden afectar al rendimiento. Utilice réplicas de la misma clase de instancia y tipo de almacenamiento o superiores que la instancia de origen. Como la réplica debe reproducir la misma actividad de escritura que la instancia de origen, el uso de una réplica de clase de instancia inferior puede provocar una latencia alta en la réplica de lectura y aumentar el retraso de la replicación.
Réplicas de lectura gestionan una carga de trabajo de escritura similar a la de la instancia de origen, así como consultas de lectura adicionales. Es mejor tener réplicas de lectura que utilicen al menos la misma clase de instancia o una superior. Del mismo modo, también debe hacer coincidir los tipos de almacenamiento de instancias de origen y réplica. Configuraciones de almacenamiento no coincidentes aumentan el retraso de replicación.
Replicación entre regiones
RDS PostgreSQL también admite la replicación entre regiones. Además de escalar las consultas de lectura, las réplicas de lectura entre regiones ofrecen soluciones para la recuperación ante desastres y la migración de bases de datos entre regiones de AWS.
En lugar de mantener la retención de WAL basada en wal_keep_segments, la replicación entre regiones utiliza una ranura de replicación física en la instancia de origen. La métrica de CloudWatch OldestReplicationSlotLag muestra el retraso de replicación en términos de tamaño de WAL en MB. La métrica TransactionLogsDiskUsage muestra el tamaño de almacenamiento utilizado por los archivos WAL. A medida que las ranuras de replicación conservan WAL, el retraso de la replicación entre regiones provoca la acumulación de WAL en la instancia de origen y, en última instancia, puede provocar problemas graves, como dejar la instancia sin espacio en disco.
Como práctica recomendada, también debe supervisar el rendimiento de IOPS en la instancia de origen. Es decir, si la instancia de origen se queda sin IOPS, la alta latencia de lectura puede retrasar la lectura del archivo WAL y provocar un retraso elevado en la replicación entre regiones. Debido a las distancias geográficas más largas que implica la replicación entre regiones, recomendamos que supervise de cerca el retraso de la replicación entre regiones para evitar un alto consumo de almacenamiento en la instancia de origen debido a la retención de WAL.
Replicación Lógica
A partir de la versión 9.4 de Postgres, puede configurar ranuras de replicación lógica en la instancia de RDS PostgreSQL y transmitir los cambios de la base de datos a otras instancias. AWS Database Migration Service (AWS DMS) proporciona el caso de uso más común de replicación lógica.
La replicación lógica utiliza ranuras lógicas que ignoran al destinatario. Si la replicación se detiene o los WAL no se consumen, el almacenamiento de la instancia de origen se puede llenar rápidamente. Para evitar esta situación, asegúrese de comprobar la siguiente configuración:
- Establecer el parámetro rds.logical_replication: Si este parámetro permite el uso de la instancia de PostgreSQL de RDS como origen de DMS, supervise las tareas de DMS. Si la tarea de DMS se detiene o se interrumpe, o si descubre que la captura de datos de cambios no está habilitada, desactive este parámetro.
- Supervisar las ranuras de replicación: si habilita el parámetro anterior, los archivos WAL no consumidos se siguen acumulando en el origen. Como práctica recomendada, vigile de cerca las ranuras de replicación y elimine las inactivas. Con ese fin, aquí hay algunas consultas importantes para el mantenimiento de las ranuras:
- a. Encontrar ranuras de replicación inactivas:
SELECT slot_name FROM pg_replication_slots WHERE active='f'; - b. Eliminar ranuras de replicación inactivas:
SELECT pg_drop_replication_slot('slot_name'); - c. Combinar los dos comandos anteriores en un solo, como sigue:
SELECT pg_drop_replication_slot('slot_name') from pg_replication_slots where active = 'f';
- a. Encontrar ranuras de replicación inactivas:
A partir de la versión 10.4, RDS PostgreSQL soporta la replicación lógica nativa basada en el modelo de publicación y suscripción. A diferencia de la replicación física tradicional, que replica toda la instancia junto con todas las bases de datos, la replicación lógica le permite replicar un subconjunto de los datos, como cambios a nivel de tabla o base de datos. Por lo tanto, puede replicar entre versiones diferentes de Postgres o consolidar varias bases de datos en una sola.
Tenga en cuenta que la replicación lógica tiene ciertas limitaciones. Pueden surgir problemas relacionados con lo siguiente:
- Cambios en el esquema de base de datos: Como práctica recomendada, los cambios de esquema deben ser confirmados primero por el suscriptor y luego por el editor (publisher).
- Datos de secuencia: aunque la replicación lógica replica los datos de secuencia en columnas serie o identidad, en caso de switchover o failover a la base de datos del suscriptor, debe actualizar las secuencias a los valores más recientes.
- Truncamiento de objetos grandes: una solución alternativa a TRUNCATE podría ser DELETE. Para evitar operaciones TRUNCATE accidentales, puede revocar (REVOKE) los privilegios a a la operación TRUNCATE de las tablas.
- Tablas particionadas: la replicación lógica trata las tablas particionadas como tablas normales. Replique las tablas particionadas de forma individual.
- Tablas foráneas (foreign tables): la replicación lógica no replica tablas foráneas.
Sumario
En esta publicación, sugerí prácticas recomendadas para configurar réplicas de lectura. Hablé de los pros y los contras de varias opciones de replicación de RDS PostgreSQL, incluidas las operaciones de replicación intra-regional, entre regiones, y lógica.
Si bien RDS facilita la configuración y la administración de la replicación, las mejores prácticas descritas aquí siguen siendo esenciales para minimizar el retraso de la replicación. Estas prácticas también ayudan a optimizar la estrategia de DR, cargas de trabajo solo lectura, e instancias de origen en buen estado. Para obtener más información acerca de las limitaciones, la supervisión y la solución de problemas de las réplicas de lectura de RDS PostgreSQL, consulte Trabajando con réplicas de lectura de RDS PostgreSQL.
Como siempre, AWS agradece sus comentarios. Envíe sus comentarios o preguntas a continuación.
Este artículo fue traducido del Blog de AWS en Inglés
Acerca del autor
 Vivek Singh es un Technical Account Manager especializado en bases de datos en Amazon Web Services con un foco en RDS/Aurora PostgreSQL. Vivek trabaja con clientes empresariales proporcionando asistencia técnica sobre el rendimiento operativo de PostgreSQL y compartiendo mejores prácticas de bases de datos.
Vivek Singh es un Technical Account Manager especializado en bases de datos en Amazon Web Services con un foco en RDS/Aurora PostgreSQL. Vivek trabaja con clientes empresariales proporcionando asistencia técnica sobre el rendimiento operativo de PostgreSQL y compartiendo mejores prácticas de bases de datos.
Traductor
 Camilo Leon es un Arquitecto de Soluciones Principal especializado en bases de datos en Amazon Web Services radicado en San Francisco. Camilo Trabaja con clientes de AWS para proporcionar orientación y asistencia técnica en servicios de bases de datos relacionales, ayudándoles a mejorar el valor de sus soluciones cuando utilizan AWS.
Camilo Leon es un Arquitecto de Soluciones Principal especializado en bases de datos en Amazon Web Services radicado en San Francisco. Camilo Trabaja con clientes de AWS para proporcionar orientación y asistencia técnica en servicios de bases de datos relacionales, ayudándoles a mejorar el valor de sus soluciones cuando utilizan AWS.