¿Cuál es la diferencia entre los procesos de ETL y ELT?
¿Cuál es la diferencia entre los procesos de ETL y ELT?
El proceso de extracción, transformación y carga (ETL) y el de extracción, carga y transformación (ELT) son dos enfoques de procesamiento de datos para el análisis. Las grandes organizaciones tienen varios cientos (o incluso miles) de orígenes de datos de todos los aspectos de sus operaciones, como aplicaciones, sensores, infraestructura de TI y socios externos. Tienen que filtrar, clasificar y limpiar este gran volumen de datos para que sea útil para el análisis y la inteligencia empresarial. El enfoque de ETL utiliza un conjunto de reglas empresariales para procesar datos de varios orígenes antes de la integración centralizada. El enfoque de ELT carga los datos tal como están y los transforma en una etapa posterior, según el caso de uso y los requisitos de análisis. El proceso ETL requiere más definición al principio. Se debe incluir el análisis desde el principio para definir los tipos de datos de destino, las estructuras y las relaciones. Los científicos de datos utilizan principalmente ETL para cargar bases de datos heredadas en el almacenamiento de datos, y el proceso de ELT se ha convertido en la norma en la actualidad.
¿Cuáles son las similitudes entre los procesos de ETL y ELT?
Tanto el proceso de extracción, transformación y carga (ETL) como el de extracción, carga y transformación (ELT) son secuencias de procesos que preparan los datos para su posterior análisis. Capturan, procesan y cargan datos para su análisis en tres pasos.
Extracción
La extracción es el primer paso tanto del proceso de ETL como del de ELT. Este paso consiste en recopilar datos sin procesar de diferentes orígenes. Pueden ser bases de datos, archivos, aplicaciones de software como servicio (SaaS), sensores de Internet de las cosas (IoT) o eventos de aplicaciones. Puede recopilar datos semiestructurados, estructurados o no estructurados en esta etapa.
Transformación
En el proceso de ETL, la transformación es el segundo paso, mientras que en el de ELT es el tercero. Este paso se centra en cambiar los datos sin procesar de su estructura original a un formato que cumpla con los requisitos del sistema de destino en el que planea almacenar los datos para su análisis. Estos son algunos ejemplos de transformación:
- Cambio de tipos o formatos de datos
- Eliminación de datos incoherentes o inexactos
- Eliminación de la duplicación de datos
Aplica reglas y funciones para limpiar y preparar los datos para su análisis en el sistema de destino.
Carga
En esta fase, almacena los datos en la base de datos de destino. El proceso de ETL procesa los datos de carga como paso final, de modo que las herramientas de informes puedan utilizarlos directamente para generar informes e información procesables. Sin embargo, en el proceso de ELT sigue siendo necesario transformar los datos extraídos después de cargarlos.
¿En qué se diferencian los procesos de ELT y ETL entre sí?
A continuación, describimos los procesos de extracción, transformación y carga (ETL) y extracción, carga y transformación (ELT). También puede leer información sobre el contexto histórico.
Proceso de ETL
El proceso de ETL consta de tres pasos:
- Extracción de datos sin procesar de varios orígenes
- Uso de un servidor de procesamiento secundario para transformar esos datos
- Carga de esos datos en una base de datos de destino
La etapa de transformación garantiza el cumplimiento de los requisitos estructurales de la base de datos de destino. Los datos solo se mueven una vez que estén transformados y listos.
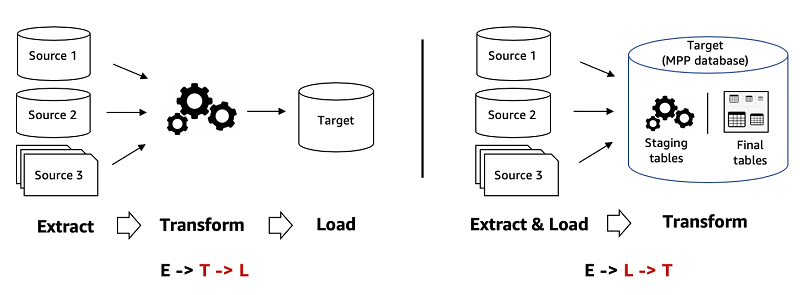
Proceso de ELT
Estos son los tres pasos del proceso de ELT:
- Extracción de datos sin procesar de varios orígenes
- Carga de los datos en su estado natural en un almacenamiento o lago de datos
- Transformación de los datos según sea necesario mientras estén en el sistema de destino
Con ELT, toda la limpieza, la transformación y el enriquecimiento de los datos se producen dentro del almacenamiento de datos. Puede interactuar con los datos sin procesar y transformarlos tantas veces como sea necesario.
Historia de los procesos de ETL y ELT
El proceso de ETL existe desde la década de 1970 y se hizo especialmente popular con el auge de los almacenamientos de datos. Sin embargo, los almacenamientos de datos tradicionales requerían procesos de ETL personalizados para cada origen de datos.
La evolución de las tecnologías en la nube cambió lo que era posible. Las empresas ahora podían almacenar datos sin procesar ilimitados a escala y analizarlos posteriormente según fuera necesario. El proceso de ELT se convirtió en el método moderno de integración de datos para un análisis eficiente.
Diferencias clave: ETL frente a ELT
El proceso de extracción, carga y transformación (ELT) ha mejorado el proceso de extracción, transformación y carga (ETL) de varias maneras.
Ubicación de transformación y carga
La transformación y la carga se producen en diferentes ubicaciones y utilizan procesos distintos. El proceso de ETL transforma los datos en un servidor de procesamiento secundario.
Por el contrario, el proceso de ELT carga los datos sin procesar directamente en el almacenamiento de datos de destino. Una vez allí, puede transformar los datos cuando los necesite.
Compatibilidad de datos
El proceso de ETL es ideal para datos estructurados que se pueden representar en tablas con filas y columnas. Transforma un conjunto de datos estructurados en otro formato estructurado y, a continuación, lo carga.
Por el contrario, el proceso de ELT gestiona todo tipo de datos, incluidos los datos no estructurados, como imágenes o documentos, que no se pueden almacenar en formato tabular. Con ELT, el proceso carga los distintos formatos de datos en el almacenamiento de datos de destino. A partir de ahí, puede transformarlos aún más en el formato que necesite.
Velocidad
El proceso de ELT es más rápido que el de ETL. El proceso de ETL tiene un paso adicional antes de cargar los datos en el destino que es difícil de escalar y ralentiza el sistema a medida que aumenta el tamaño de los datos.
Por el contrario, el proceso de ELT carga los datos directamente en el sistema de destino y los transforma en paralelo. Utiliza la potencia de procesamiento y la paralelización que ofrecen los almacenamientos de datos en la nube para ofrecer una transformación de datos en tiempo real o casi real para llevar a cabo análisis.
Costos
El proceso de ETL requiere la participación de los analistas desde el principio. Necesita que los analistas planifiquen con antelación los informes que desean generar y definan las estructuras y el formato de los datos. El tiempo necesario para la configuración aumenta, lo que aumenta los costos. La infraestructura de servidores adicional para las transformaciones también puede costar más.
El proceso de ELT tiene menos sistemas que el de ETL, ya que todas las transformaciones se producen dentro del almacenamiento de datos de destino. Con menos sistemas, hay menos que mantener, lo que implica una pila de datos más simple y con menores costos de configuración.
Seguridad
Cuando trabaja con datos personales, debe cumplir con las normas de privacidad de datos. Las empresas deben proteger la información de identificación personal (PII) del acceso no autorizado.
En el proceso de ETL, los desarrolladores tienen que crear soluciones personalizadas, como enmascarar la PII para supervisar y proteger los datos.
Por otro lado, las soluciones de ELT ofrecen muchas características de seguridad, como el control de acceso granular y la autenticación multifactor, directamente dentro del almacenamiento de datos. Puede invertir más tiempo en análisis y menos tiempo en cumplir con los requisitos de regulación de datos.
Cuándo usar el proceso de ETL en lugar del de ELT
El proceso de extracción, carga y transformación (ELT) es la opción estándar para los análisis modernos. Sin embargo, podría considerar el uso del proceso de extracción, transformación y carga (ETL) en los siguientes escenarios.
Bases de datos heredadas
A veces es más beneficioso utilizar el proceso de ETL para integrarlo con bases de datos antiguas u orígenes de datos de terceros con formatos de datos predeterminados. Solo tiene que transformar y cargar los datos una vez en su sistema. Una vez completada la transformación, puede usarlos de manera más eficiente para todos los análisis futuros.
Experimentación
En las grandes organizaciones, los ingenieros de datos llevan a cabo experimentos, como la detección de orígenes de datos ocultos para el análisis y la realización de pruebas de nuevas ideas para responder a las consultas empresariales. El proceso de ETL es útil en experimentos con datos para comprender la base de datos y su utilidad en un escenario particular.
Análisis complejos
Tanto el proceso de ETL como el de ELT se pueden usar juntos para llevar a cabo análisis complejos que utilizan múltiples formatos de datos de diversos orígenes. Los científicos de datos pueden configurar canalizaciones de ETL a partir de algunos de los orígenes y utilizar el proceso de ELT con el resto. Esto mejora la eficiencia de los análisis y, en algunos casos, aumenta el rendimiento de las aplicaciones.
Aplicaciones de IoT
Las aplicaciones de Internet de las cosas (IoT) que utilizan flujos de datos de sensores suelen beneficiarse del proceso de ETL en lugar del de ELT. Por ejemplo, estos son algunos casos de uso comunes de ETL en la periferia:
- Desea recibir datos de diferentes protocolos y convertirlos en formatos de datos estándar para usarlos en cargas de trabajo en la nube.
- Desea filtrar los datos de alta frecuencia, realizar funciones de promedio en conjuntos de datos grandes y, a continuación, cargar los valores promediados o filtrados a una velocidad reducida.
- Desea calcular valores a partir de distintos orígenes de datos en el dispositivo local y enviar los valores filtrados al backend de la nube.
- Desea limpiar, deduplicar o completar los elementos de datos de series temporales que faltan.
Resumen de las diferencias: ETL frente a ELT
| Categoría |
ETL |
ELT |
|
Qué significa |
Extracción, transformación y carga |
Extracción, carga y transformación |
|
Proceso |
Toma datos sin procesar, los transforma en un formato predeterminado y, a continuación, los carga en el almacenamiento de datos de destino. |
Toma datos sin procesar, los carga en el almacenamiento de datos de destino y, a continuación, los transforma justo antes del análisis. |
|
Ubicaciones de transformación y carga |
La transformación se produce en un servidor de procesamiento secundario. |
La transformación se lleva a cabo en el almacenamiento de datos de destino. |
|
Compatibilidad de datos |
Se recomienda el uso de datos estructurados. |
Puede gestionar datos estructurados, no estructurados y semiestructurados. |
|
Velocidad |
El proceso de ETL es más lento que el de ELT. |
El proceso de ELT es más rápido que el de ETL, ya que puede utilizar los recursos internos del almacenamiento de datos. |
|
Costos |
La configuración puede llevar mucho tiempo y ser costosa en función de las herramientas de ETL utilizadas. |
Más rentable según la infraestructura de ELT utilizada. |
|
Seguridad |
Es posible que sea necesario crear aplicaciones personalizadas para cumplir con los requisitos de protección de datos. |
Puede utilizar las características integradas de la base de datos de destino para administrar la protección de datos. |
¿Cómo puede AWS satisfacer los requisitos de sus procesos de ETL y ELT?
Analytics on AWS describe la amplia selección de servicios de análisis de Amazon Web Services (AWS) que se adaptan a todas sus necesidades de análisis de datos. Con AWS, las organizaciones de todos los tamaños y sectores pueden reinventar sus negocios con datos.
Estos son algunos de los servicios de AWS que puede utilizar para satisfacer los requisitos de sus procesos de ETL y ELT:
- Amazon Aurora admite la integración sin ETL con Amazon Redshift. Esta integración permite el análisis y el uso de machine learning casi en tiempo real a través de Amazon Redshift en petabytes (PB) de datos transaccionales de Aurora.
- AWS Glue es un servicio de integración de datos sin servidor para trabajos de ETL basados en eventos y de ETL sin código.
- AWS IoT Greengrass apoya sus casos de uso de ETL en el borde al llevar el procesamiento y la lógica de la nube de forma local a los dispositivos periféricos.
- Amazon Redshift le permite configurar todos los flujos de trabajo de ELT y consultar directamente conjuntos de datos de diferentes fuentes.
Comience a utilizar ELT y ETL en AWS creando una cuenta gratuita hoy mismo.