Sin servidor en AWS
Cree y ejecute aplicaciones sin preocuparse por los servidores
Descripción general
AWS ofrece tecnologías para ejecutar código, administrar datos e integrar aplicaciones, todo sin tener que administrar servidores. Las tecnologías sin servidor incluyen escalado automático, alta disponibilidad integrada y un modelo de facturación de pago por uso para aumentar la agilidad y optimizar los costos. Estas tecnologías también eliminan las tareas de administración de infraestructura, como el aprovisionamiento de capacidad y la aplicación de parches, de manera que pueda enfocarse en escribir el código que sirva a sus clientes.
Lea la publicación de blog sobre la recapitulación trimestral sin servidor
Beneficios de la tecnología sin servidor de AWS
-
Elimine el exceso de tareas operativas para que sus equipos puedan efectuar lanzamientos rápidamente, obtener retroalimentación e iterar para llegar al mercado más rápido.
-
Con un modelo de facturación de pago por valor, la utilización de los recursos se optimiza de forma automática y nunca deberá pagar por exceso de aprovisionamiento.
-
Con tecnologías que se escalan automáticamente de cero a las demandas máximas, puede adaptarse a las necesidades del cliente más rápido que nunca.
-
Las aplicaciones sin servidor incluyen integraciones de servicios, por lo que puede centrarse en construir su aplicación en lugar de configurarla.
Servicios sin servidor en AWS
Las aplicaciones modernas se crean sin servidor, una estrategia que favorece la adopción de servicios sin servidor, con lo que podrá aumentar la agilidad en toda la pila de aplicaciones. Hemos desarrollado servicios sin servidor para las tres capas de la pila: computación, integración y almacenes de datos. Considere comenzar con los siguientes servicios:
Casos de uso
Cree aplicaciones web
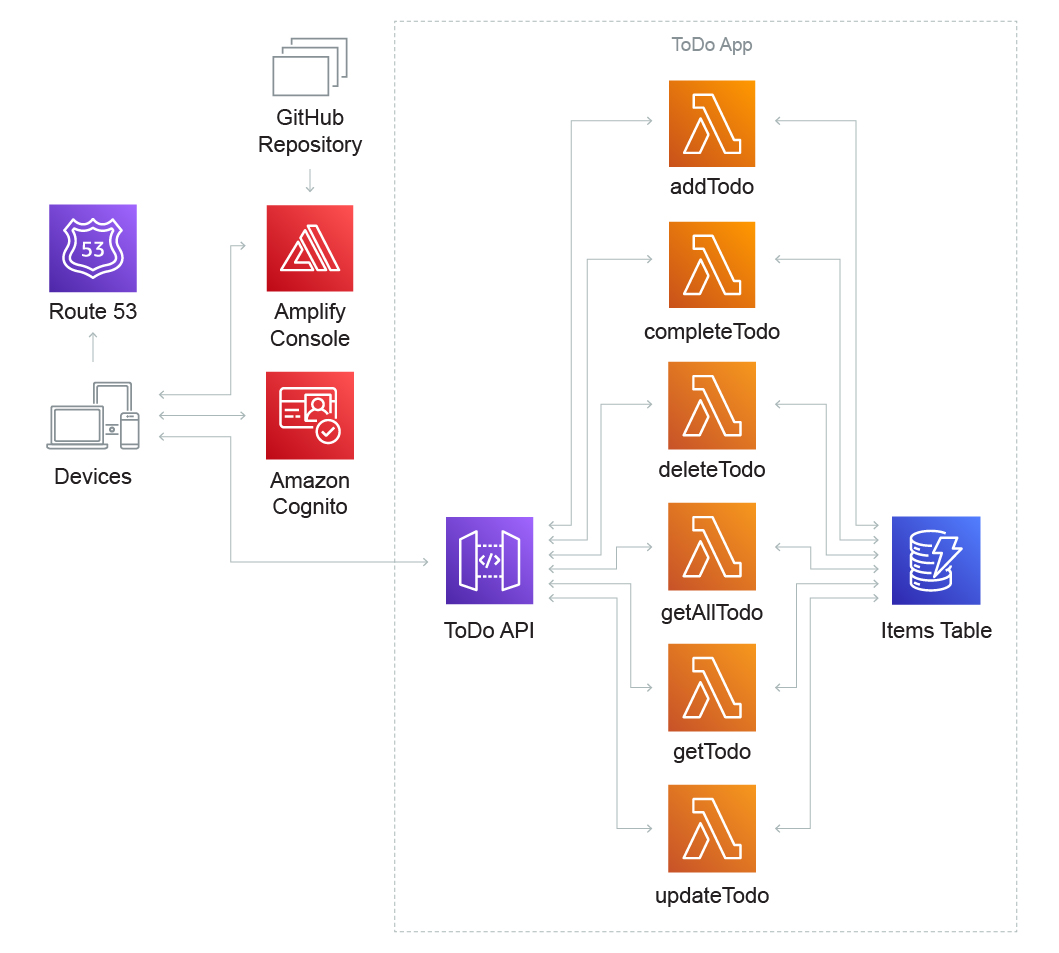
Cree una aplicación web simple de “lista de cosas por hacer” que permita que un usuario registrado cree, actualice, visualice y elimine elementos. Una aplicación web basada en los eventos puede usar AWS Lambda y Amazon API Gateway para su lógica empresarial, Amazon DynamoDB como su base de datos y la consola de AWS Amplify para alojar todo el contenido estático.
Procesamiento de datos casi a cualquier escala
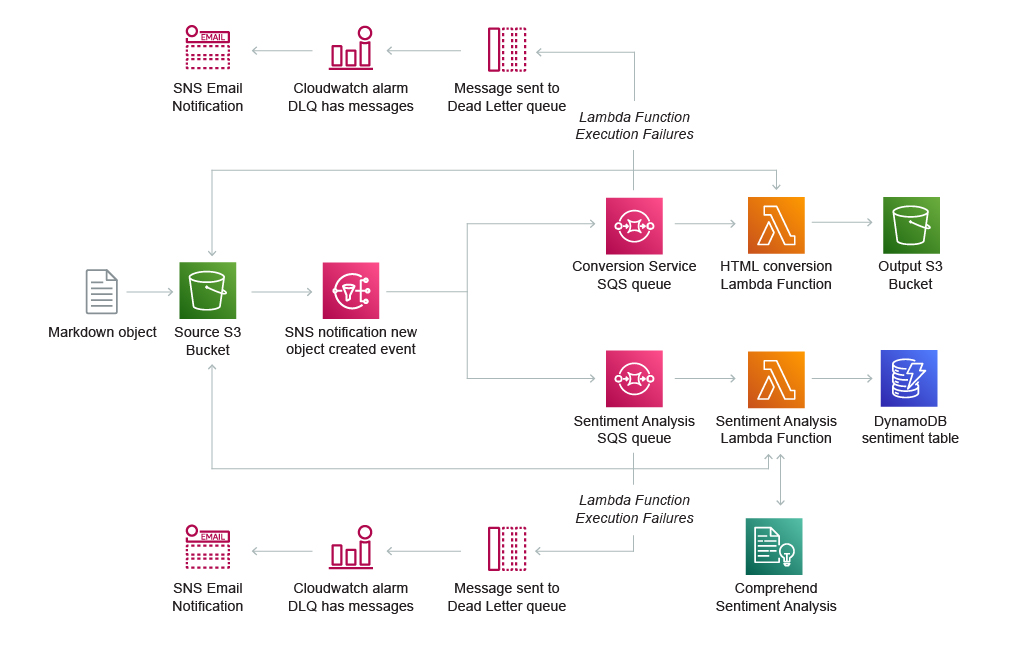
Aporte notas de una entrevista en formato Markdown a Amazon S3. Utilice los eventos de S3 para desencadenar varios flujos de procesamiento: uno para convertir los archivos Markdown a HTML y conservarlos, y otro para detectar y conservar el sentimiento.
Automatización del procesamiento por lotes
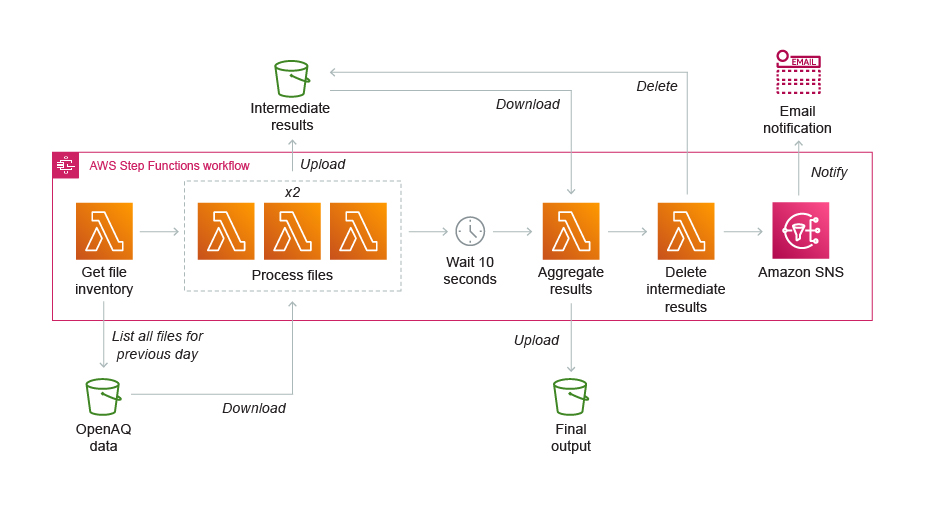
Programe flujos de trabajo de forma recurrente con una regla de Amazon EventBridge. Por ejemplo, puede generar las mediciones mínimas, máximas y promedio de la calidad del aire mediante la orquestación de un flujo de trabajo de extracción, transferencia y carga (ETL) con AWS Step Functions y AWS Lambda.
Indexación y almacenamiento automáticos de documentos e imágenes
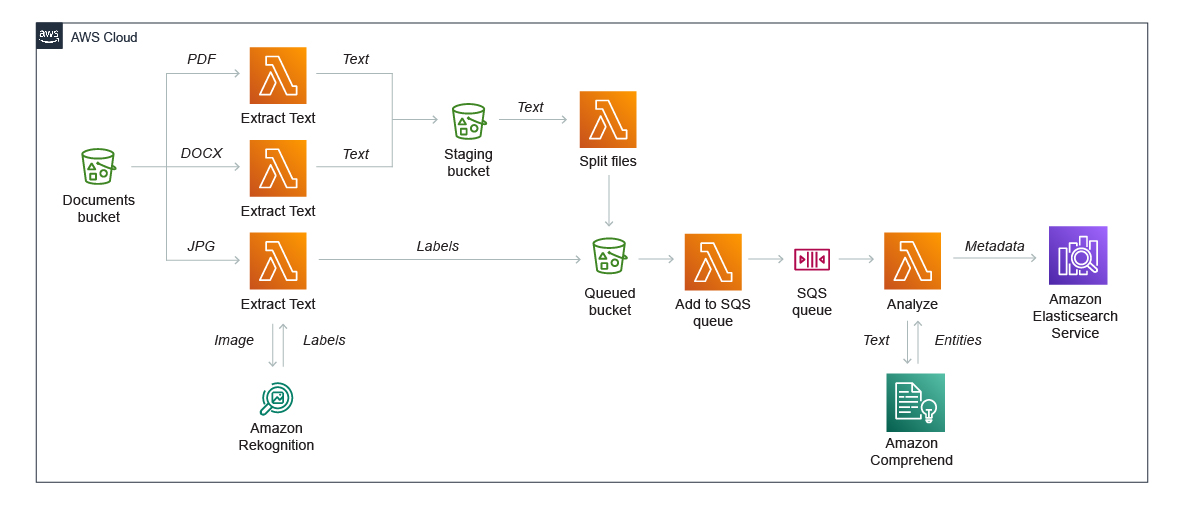
Utilice los servicios de machine learning (ML) de Amazon, como Amazon Comprehend y Amazon Rekognition, para descubrir información en los datos no estructurados y enviar los resultados a Amazon OpenSearch (sucesor de Amazon Elasticsearch Service) para una indexación rápida. Los patrones como este funcionan bien en las aplicaciones de comercio electrónico para las tareas que apoyan las experiencias personalizadas de los clientes, como el análisis de secuencias de clics.
Comience a utilizar la tecnología sin servidor en AWS
¿Ha encontrado lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios