Analisi su AWS
Un set completo di funzionalità per ogni carico di lavoro di analisi, ottimizzato per prezzo, prestazioni e scalabilità
Panoramica
AWS offre un set completo di funzionalità per ogni carico di lavoro di analisi. Dall'elaborazione dei dati e dall'analisi SQL allo streaming, alla ricerca e alla business intelligence, AWS offre prezzi, prestazioni e scalabilità senza pari con una governance integrata. Scegli servizi su misura ottimizzati per carichi di lavoro specifici o semplifica e gestisci i tuoi dati e i flussi di lavoro di intelligenza artificiale con Amazon SageMaker. Se stai iniziando il tuo percorso verso l'utilizzo dei dati o stai cercando un'esperienza integrata, AWS mette a disposizione le funzionalità di analisi adatte per aiutarti a reinventare il tuo business attraverso i dati.
Ottieni risultati aziendali tangibili con l'analisi su AWS
Accelera i dati, l'analisi e l'intelligenza artificiale con un'esperienza integrata
Riunendo le funzionalità di machine learning (ML) e analisi di AWS ampiamente comprovate, la nuova generazione di Amazon SageMaker offre un'esperienza integrata per l'analisi e l'IA con accesso unificato a tutti i tuoi dati. Collabora e crea più velocemente da uno studio unificato utilizzando strumenti noti di AWS per lo sviluppo di modelli, la creazione di applicazioni basate sull'IA generativa, l'elaborazione dei dati e l'analisi SQL, con l'accelerazione offerta da Amazon Q Developer, l'assistente di IA generativa più avanzato per lo sviluppo di software. Accedi a tutti i tuoi dati, indipendentemente dal fatto che siano archiviati in data lake, data warehouse o origini dati federate o di terze parti, con una governance integrata per soddisfare le tue esigenze di sicurezza aziendale. Ulteriori informazioni su SageMaker.
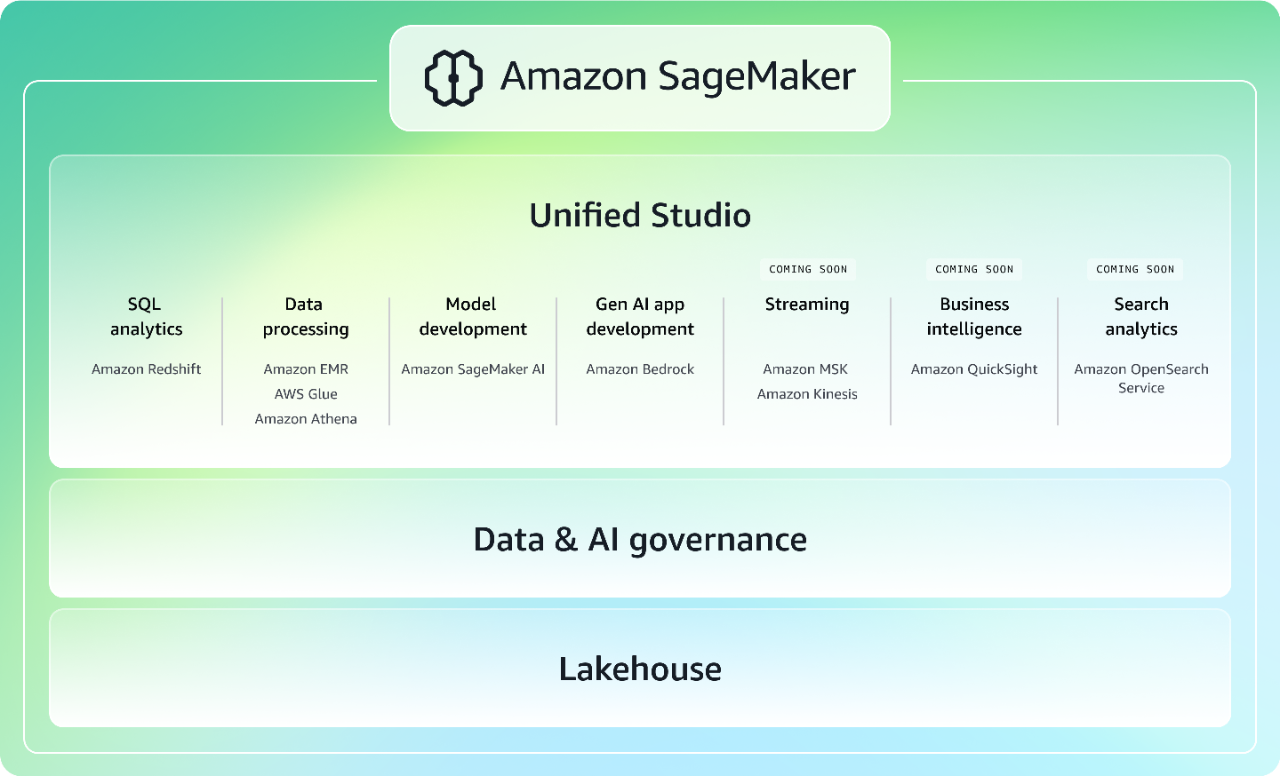
Abilitazione di strategie multicloud con AWS
AWS offre una raccolta completa di potenti servizi di analisi che consentono l'accesso e l'elaborazione senza interruzioni dei dati in ambienti multicloud e ibridi. Puoi ottenere questa flessibilità attraverso interrogazioni federate, integrazione dei dati, spostamento sicuro dei dati e compatibilità con standard aperti, che ti consentono di ottenere informazioni dettagliate da tutti i tuoi dati indipendentemente da dove risiedono.
Amazon Athena consente di interrogare e ottenere informazioni dettagliate dai dati archiviati in una varietà di origini dati esterne, tra cui Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server e molte altre, senza la necessità di copiare o trasformare i dati.
AWS Glue semplifica il rilevamento, la preparazione e l'integrazione di tutti i tuoi dati su qualsiasi scala, con connettori per oltre 100 diverse origini dati che comprendono archiviazione su cloud, database e servizi di analisi. Le integrazioni zero-ETL di Glue semplificano l'inserimento e la replica dei dati da applicazioni di terze parti come Salesforce, SAP, Facebook Ads e Instagram Ads direttamente nei tuoi lakehouse, data lake e data warehouse AWS. AWS Glue offre anche l'interoperabilità dei dati attraverso il supporto per standard aperti come Apache Hive, Apache Parquet e Apache Iceberg.
La nuova generazione di Amazon SageMaker è basata su un'architettura open data lakehouse, che fornisce un accesso unificato ai data lake e ai data warehouse su AWS, nonché a origini dati federate come Google BigQuery e Snowflake. Questa architettura lakehouse è completamente compatibile con Apache Iceberg e ti offre la flessibilità di accedere e interrogare i dati sul posto utilizzando qualsiasi strumento e motore compatibile con Iceberg.
Utilizzare l'analisi dei dati per gli utenti umani e l'intelligenza artificiale
Potenzia l'analisi su larga scala con servizi appositamente progettati per l'archiviazione, l'interrogazione, lo streaming, l'elaborazione e la gestione dei dati. Dagli Open Table Formats (OTF) all'infrastruttura agentica, AWS sta evolvendo motori e applicazioni di analisi per il panorama delle analisi in rapida evoluzione. In questa sessione scopri come AWS offre soluzioni ottimizzate create sia per utenti umani che per flussi di lavoro agentici.

Servizi
|
Categoria di analisi
|
Descrizione
|
Servizi e funzionalità AWS
|
|---|---|---|
|
Streaming
|
Crea, scala e gestisci pipeline di dati e applicazioni in tempo reale, senza il peso della gestione dell'infrastruttura. |
|
|
Data lakehouse, data warehouse, data lake
|
Accedi e analizza tutti i dati in data lakehouse, data warehouse e data lake. |
|
|
Elaborazione di dati
|
Analizza, prepara e integra i dati per l'analisi e l'IA utilizzando framework open source. |
|
|
Business intelligence
|
Crea, scopri e condividi approfondimenti significativi attraverso moderni pannelli di controllo interattivi, report pixel-perfect, query in linguaggio naturale e analisi integrate. |
|
|
Analisi della ricerca
|
Abilita in modo sicuro la ricerca, il monitoraggio e l’analisi in tempo reale dei dati aziendali e operativi. |
|
|
Governance dei dati e dell'IA
|
Cataloga, rileva, condividi e gestisci i dati archiviati su AWS, on-premises e su origini di terze parti. |
L'impatto economico totale di una moderna strategia di dati AWS
Risparmi sui costi e vantaggi aziendali resi possibili da una moderna strategia di dati Amazon Web Services, come riportato da Forrester.
Statistiche
Hai trovato quello che cercavi?
Facci sapere la tua opinione per aiutarci a migliorare la qualità dei contenuti delle nostre pagine