AWS Big Data Blog
Easy analytics and cost-optimization with Amazon Redshift Serverless
Amazon Redshift Serverless makes it easy to run and scale analytics in seconds without the need to setup and manage data warehouse clusters. With Redshift Serverless, users such as data analysts, developers, business professionals, and data scientists can get insights from data by simply loading and querying data in the data warehouse.
With Redshift Serverless, you can benefit from the following features:
- Access and analyze data without the need to set up, tune, and manage Amazon Redshift clusters
- Use Amazon Redshift’s SQL capabilities, industry-leading performance, and data lake integration to seamlessly query data across a data warehouse, data lake, and databases
- Deliver consistently high performance and simplified operations for even the most demanding and volatile workloads with intelligent and automatic scaling, without under-provisioning or over-provisioning the compute resources
- Pay for the compute only when the data warehouse is in use
In this post, we discuss four different use cases of Redshift Serverless:
- Easy analytics – A startup company needs to create a new data warehouse and reports for marketing analytics. They have very limited IT resources, and need to get started quickly and easily with minimal infrastructure or administrative overhead.
- Self-service analytics – An existing Amazon Redshift customer has a provisioned Amazon Redshift cluster that is right-sized for their current workload. A new team needs quick self-service access to the Amazon Redshift data to create forecasting and predictive models for the business.
- Optimize workload performance – An existing Amazon Redshift customer is looking to optimize the performance of their variable reporting workloads during peak time.
- Cost-optimization of sporadic workloads – An existing customer is looking to optimize the cost of their Amazon Redshift producer cluster with sporadic batch ingestion workloads.
Easy analytics
In our first use case, a startup company with limited resources needs to create a new data warehouse and reports for marketing analytics. The customer doesn’t have any IT administrators, and their staff is comprised of data analysts, a data scientist, and business analysts. They want to create new marketing analytics quickly and easily, to determine the ROI and effectiveness of their marketing efforts. Given their limited resources, they want minimal infrastructure and administrative overhead.
In this case, they can use Redshift Serverless to satisfy their needs. They can create a new Redshift Serverless endpoint in a few minutes and load their initial few TBs of marketing dataset into Redshift Serverless quickly. Their data analysts, data scientists, and business analysts can start querying and analyzing the data with ease and derive business insights quickly without worrying about infrastructure, tuning, and administrative tasks.
Getting started with Redshift Serverless is easy and quick. On the Get started with Amazon Redshift Serverless page, you can select the Use default settings option, which will create a default namespace and workgroup with the default settings, as shown in the following screenshots.

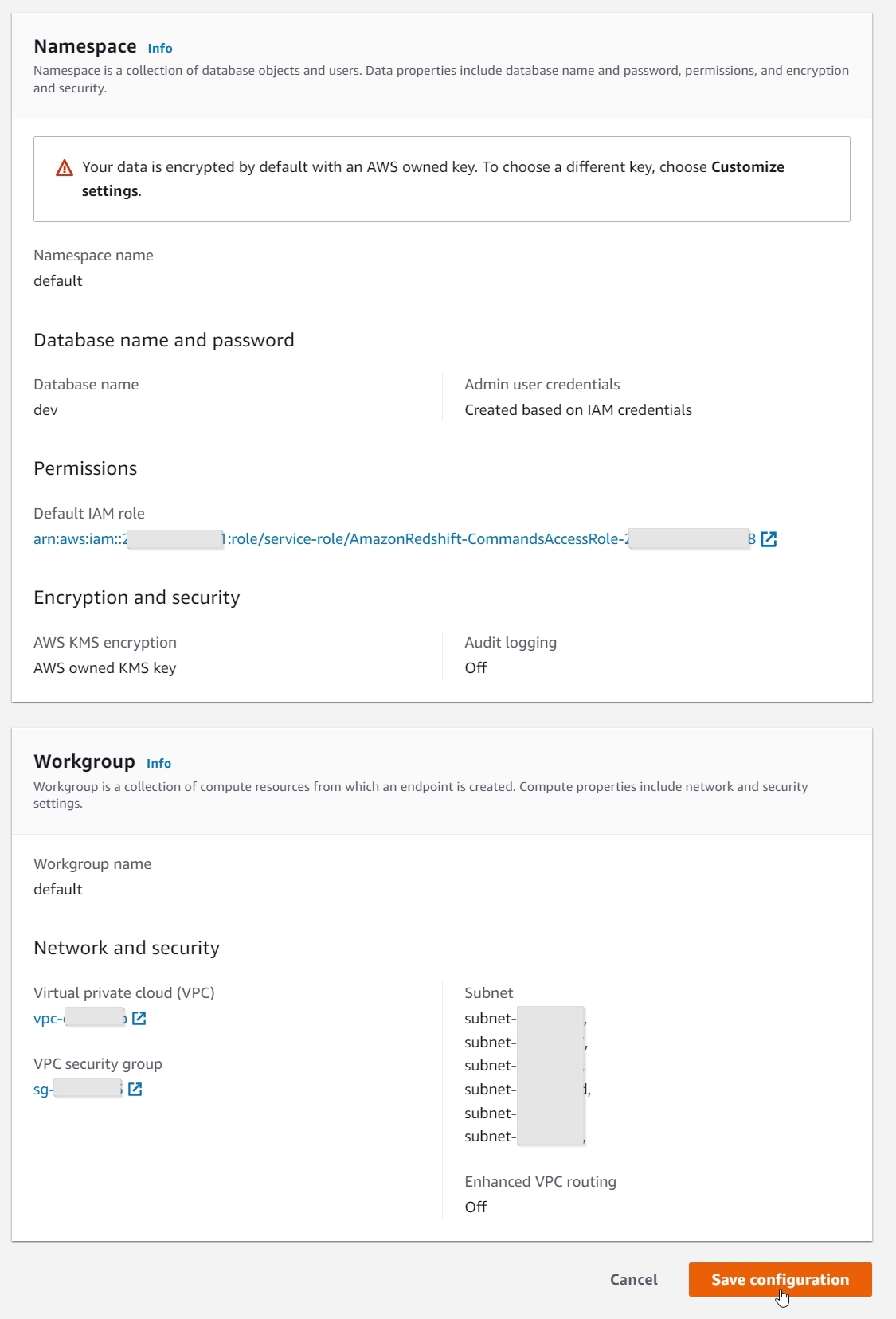
With just a single click, you can create a new Redshift Serverless endpoint in minutes with data encryption enabled, and a default AWS Identity and Access Management (IAM) role, VPC, and security group attached. You can also use the Customize settings option to override these settings, if desired.
When the Redshift Serverless endpoint is available, choose Query data to launch the Amazon Redshift Query Editor v2.
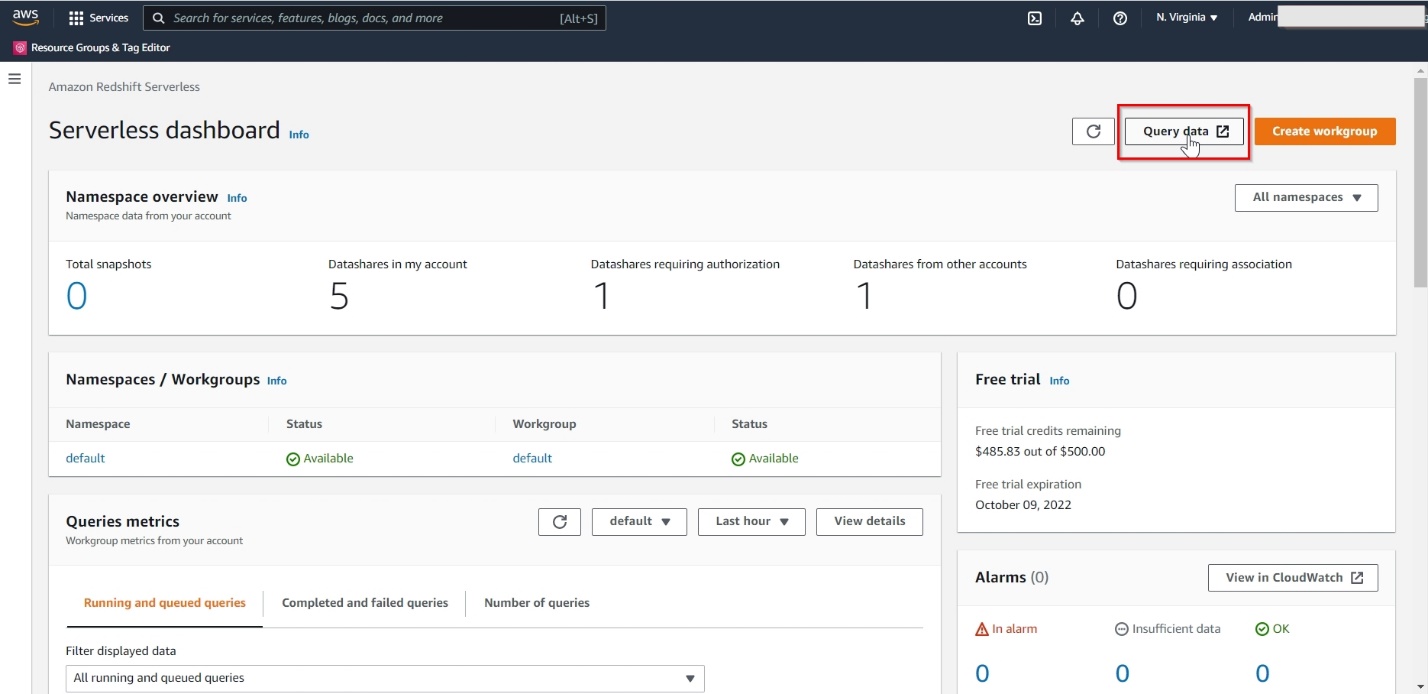
Query Editor v2 makes it easy to create database objects, load data, analyze and visualize data, and share and collaborate with your teams.
The following screenshot illustrates creating new database tables using the UI.
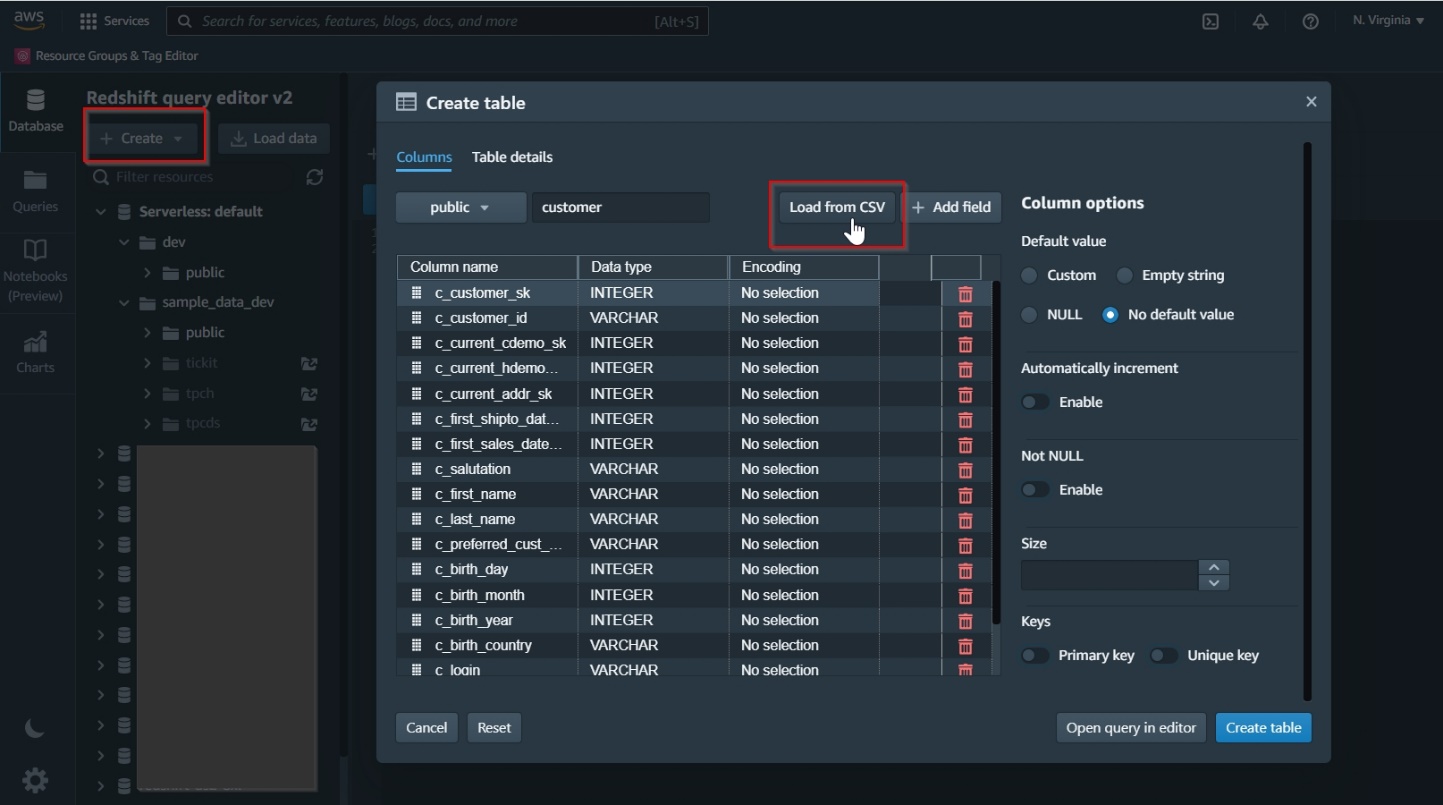
The following screenshot demonstrates loading data from Amazon Simple Storage Service (Amazon S3) using the UI.

The following screenshot shows an example of analyzing and visualizing data.

Refer to the video Get Started with Amazon Redshift Serverless to learn how to set up a new Redshift Serverless endpoint and start analyzing your data in minutes.
Self-service analytics
In another use case, a customer is currently using an Amazon Redshift provisioned cluster that is right-sized for their current workloads. A new data science team wants quick access to the Amazon Redshift cluster data for a new workload that will build predictive models for forecasting. The new team members don’t know yet how long they will need access and how complex their queries will be.
Adding the new data science group to the current cluster presented the following challenges:
- The additional compute capacity needs of the new team are unknown and hard to estimate
- Because the current cluster resources are optimally utilized, they need to ensure workload isolation to support the needs of the new team without impacting existing workloads
- A chargeback or cost allocation model is desired for the various teams consuming data
To address these issues, they decide to let the data science team create their own new Redshift Serverless instance and grant them data share access to the data they need from the existing Amazon Redshift provisioned cluster. The following diagram illustrates the new architecture.
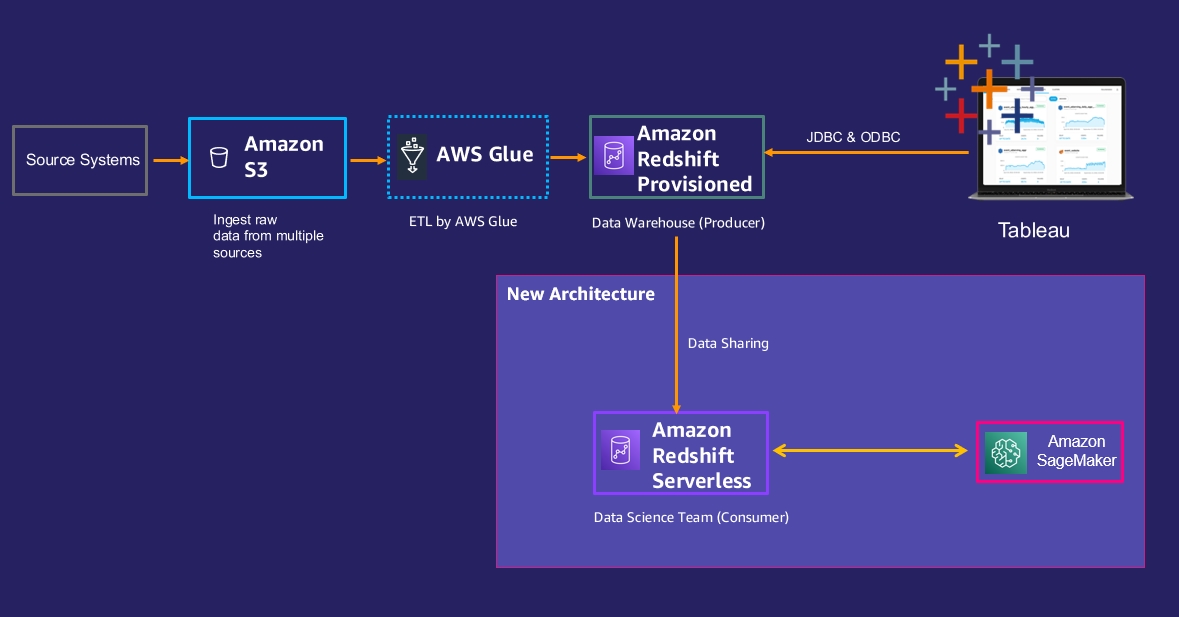
The following steps need to be performed to implement this architecture:
- The data science team can create a new Redshift Serverless endpoint, as described in the previous use case.
- Enable data sharing between the Amazon Redshift provisioned cluster (producer) and the data science Redshift Serverless endpoint (consumer) using these high-level steps:
- Create a new data share.
- Add a schema to the data share.
- Add objects you want to share to the data share.
- Grant usage on this data share to the Redshift Serverless consumer namespace, using the Redshift Serverless endpoint’s namespace ID.
- Note that the Redshift Serverless endpoint is encrypted by default; the provisioned Redshift producer cluster also needs to be encrypted for data sharing to work between them.
The following screenshot shows sample SQL commands to enable data sharing on the Amazon Redshift provisioned producer cluster.

On the Amazon Redshift Serverless consumer, create a database from the data share and then query the shared objects.
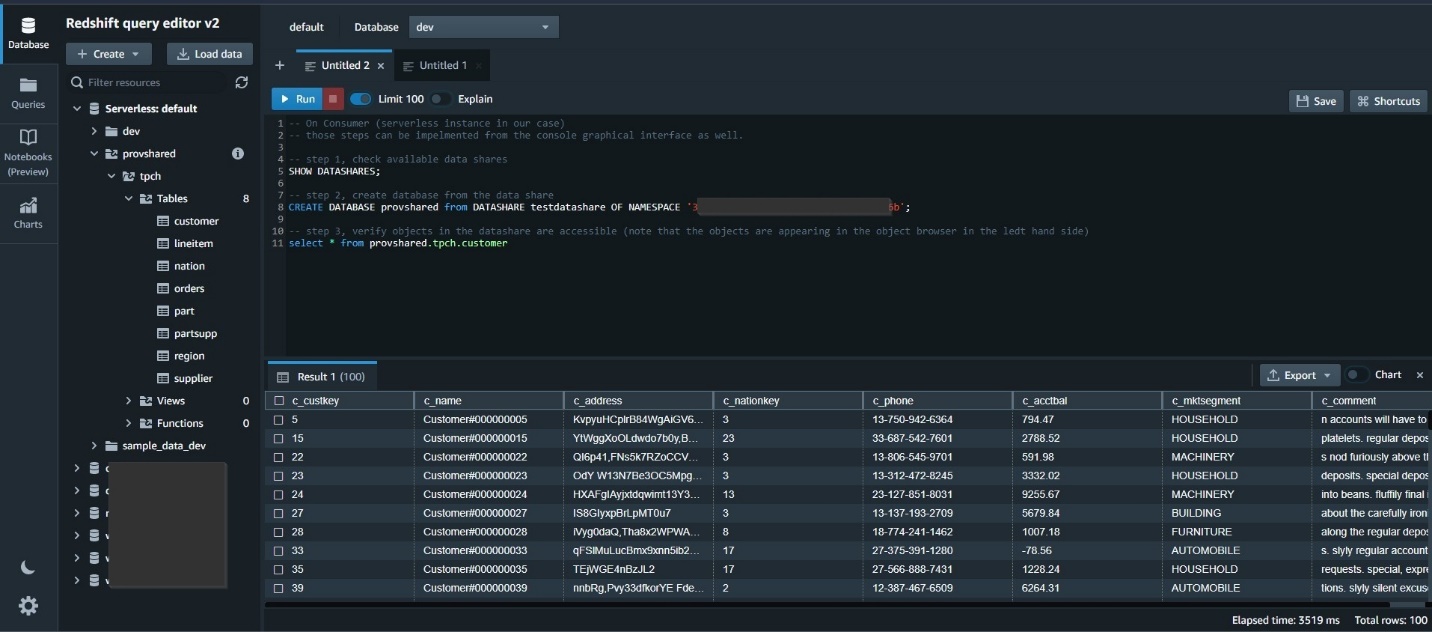
For more details about configuring Amazon Redshift data sharing, refer to Sharing Amazon Redshift data securely across Amazon Redshift clusters for workload isolation.
With this architecture, we can resolve the three challenges mentioned earlier:
- Redshift Serverless allows the data science team to create a new Amazon Redshift database without worrying about capacity needs, and set up data sharing with the Amazon Redshift provisioned producer cluster within 30 minutes. This tackles the first challenge.
- Amazon Redshift data sharing allows you to share live, transactionally consistent data across provisioned and Serverless Redshift databases, and data sharing can even happen when the producer is paused. The new workload is isolated and runs on its own compute resources, without impacting the performance of the Amazon Redshift provisioned producer cluster. This addresses the second challenge.
- Redshift Serverless isolates the cost of the new workload to the new team and enables an easy chargeback model. This tackles the third challenge.
Optimized workload performance
For our third use case, an Amazon Redshift customer using an Amazon Redshift provisioned cluster is looking for performance optimization during peak times for their workload. They need a solution to manage dynamic workloads without over-provisioning or under-provisioning resources and build a scalable architecture.
An analysis of the workload on the cluster shows that the cluster has two different workloads:
- The first workload is streaming ingestion, which runs steadily during the day.
- The second workload is reporting, which runs on an ad hoc basis during the day with some scheduled jobs during the night. It was noted that the reporting jobs run anywhere between 8–12 hours daily.
The provisioned cluster was sized as 12 nodes of ra3.4xlarge to handle both workloads running in parallel.
To optimize these workloads, the following architecture was proposed and implemented:
- Configure an Amazon Redshift provisioned cluster with just 4 nodes of ra3.4xlarge, to handle the streaming ingestion workload only. The following screenshots illustrate how to do this on the Amazon Redshift console, via an elastic resize operation of the existing Amazon Redshift provisioned cluster by reducing number of nodes from 12 to 4:


- Create a new Redshift Serverless endpoint to be utilized by the reporting workload with 128 RPU (Redshift Processing Units) in lieu of 8 nodes ra3.4xlarge. For more details about setting up Redshift Serverless, refer to the first use case regarding easy analytics.
- Enable data sharing between the Amazon Redshift provisioned cluster as the producer and Redshift Serverless as the consumer using the serverless namespace ID, similar to how it was configured earlier in the self-service analytics use case. For more information about how to configure Amazon Redshift data sharing, refer to Sharing Amazon Redshift data securely across Amazon Redshift clusters for workload isolation.
The following diagram compares the current architecture and the new architecture using Redshift Serverless.
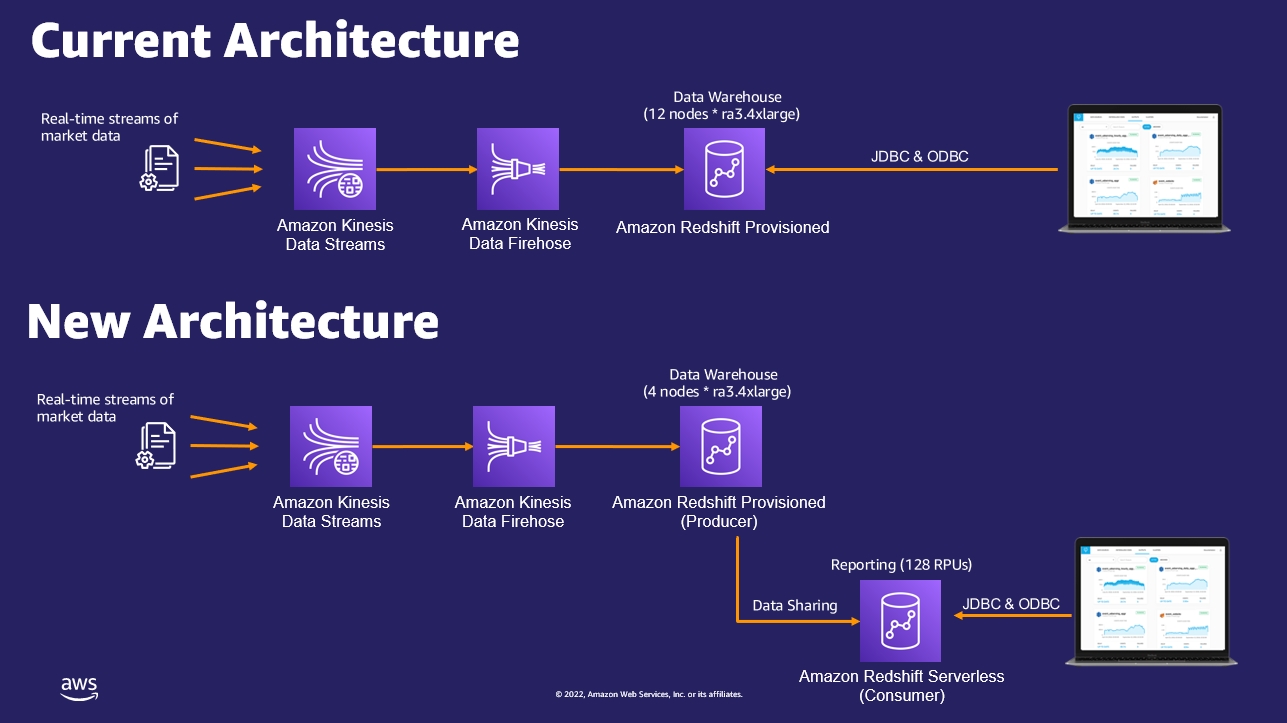
After completing this setup, the customer ran the streaming ingestion workload on the Amazon Redshift provisioned instance (producer) and reporting workloads on Redshift Serverless (consumer) based on the recommended architecture. The following improvements were observed:
- The streaming ingestion workload performed the same as it did on the former 12-node Amazon Redshift provisioned cluster.
- Reporting users saw a performance improvement of 30% by using Redshift Serverless. It was able to scale compute resources dynamically within seconds, as additional ad hoc users ran reports and queries without impacting the streaming ingestion workload.
- This architecture pattern is expandable to add more consumers like data scientists, by setting up another Redshift Serverless instance as a new consumer.
Cost-optimization
In our final use case, a customer is using an Amazon Redshift provisioned cluster as a producer to ingest data from different sources. The data is then shared with other Amazon Redshift provisioned consumer clusters for data science modeling and reporting purposes.
Their current Amazon Redshift provisioned producer cluster has 8 nodes of ra3.4xlarge and is located in the us-east-1 Region. The data delivery from the different data sources is scattered between midnight to 8:00 AM, and the data ingestion jobs take around 3 hours to run in total every day. The customer is currently on the on-demand cost model and has scheduled daily jobs to pause and resume the cluster to minimize costs. The cluster resumes every day at midnight and pauses at 8:00 AM, with a total runtime of 8 hours a day.
The current annual cost of this cluster is 365 days * 8 hours * 8 nodes * $3.26 (node cost per hour) = $76,153.6 per year.
To optimize the cost of this workload, the following architecture was proposed and implemented:
- Set up a new Redshift Serverless endpoint with 64 RPU as the base configuration to be utilized by the data ingestion producer team. For more information about setting up Redshift Serverless, refer to the first use case regarding easy analytics.
- Restore the latest snapshot from the existing Amazon Redshift provisioned producer cluster into Redshift Serverless by choosing the Restore to serverless namespace option, as shown in the following screenshot.
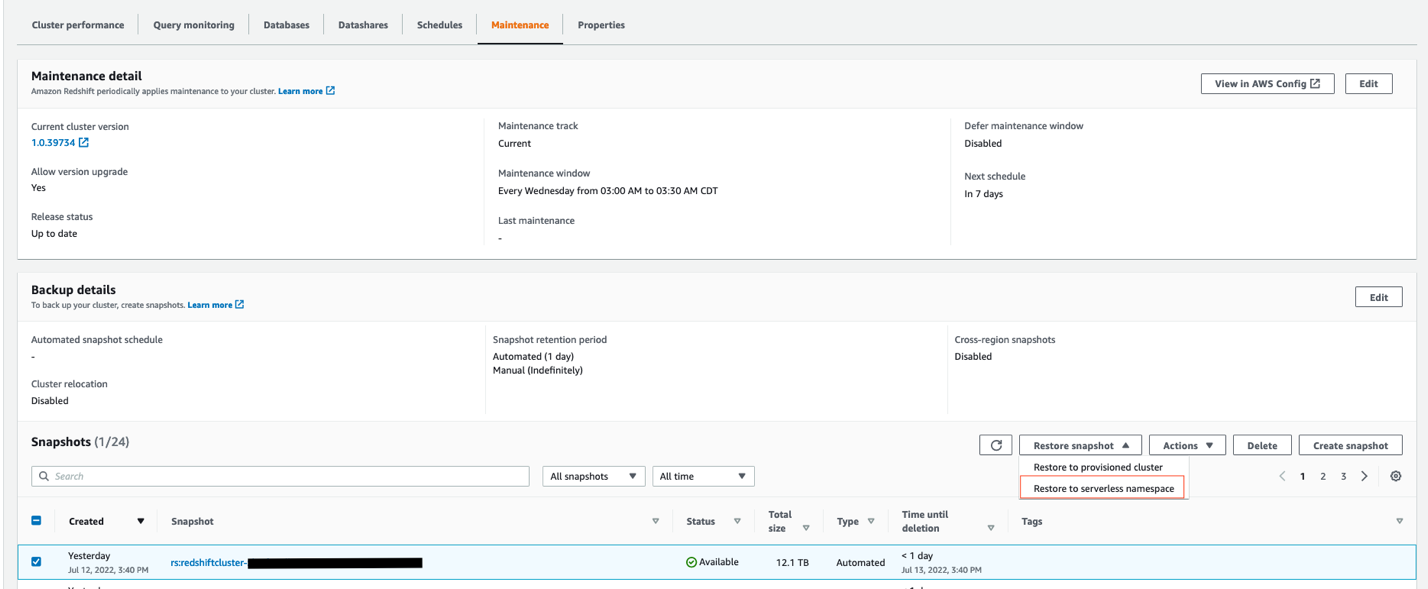
- Enable data sharing between Redshift Serverless as the producer and the Amazon Redshift provisioned cluster as the consumer, similar to how it was configured earlier in the self-service analytics use case.
The following diagram compares the current architecture to the new architecture.
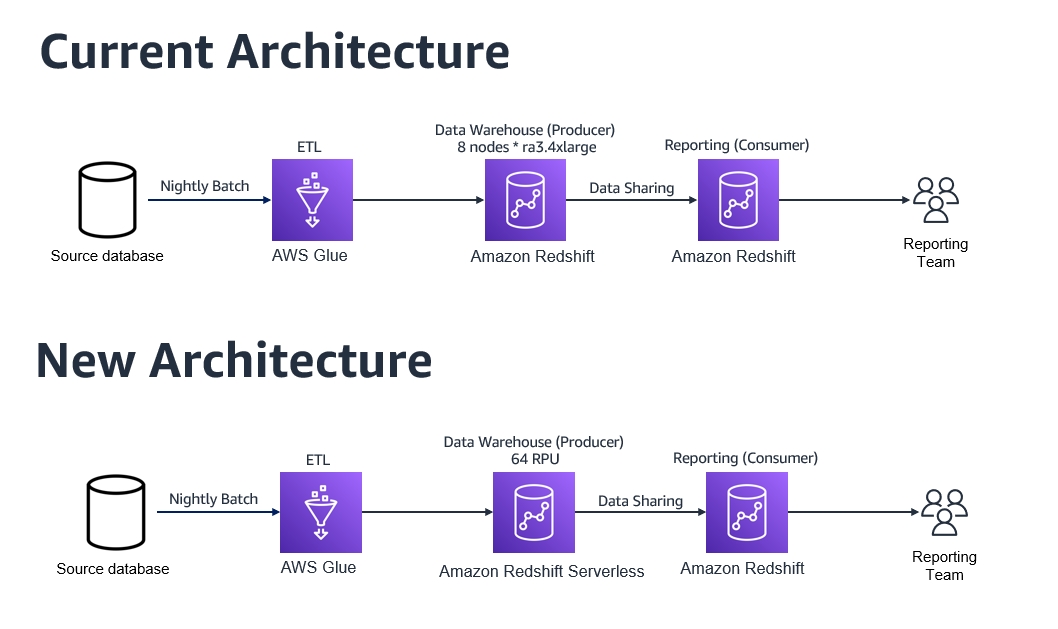
By moving to Redshift Serverless, the customer realized the following benefits:
- Cost savings – With Redshift Serverless, the customer pays for compute only when the data warehouse is in use. In this scenario, the customer observed a savings of up to 65% on their annual costs by using Redshift Serverless as the producer, while still getting better performance on their workloads. The Redshift Serverless annual cost in this case equals 365 days * 3 hours * 64 RPUs * $0.375 (RPU cost per hour) = $26,280, compared to $76,153.6 for their former provisioned producer cluster. Also, the Redshift Serverless 64 RPU baseline configuration offers the customer more compute resources than their former 8 nodes of ra3.4xlarge cluster, resulting in better performance overall.
- Less administration overhead – Because the customer doesn’t need to worry about pausing and resuming their Amazon Redshift cluster any more, the administration of their data warehouse is simplified by moving their producer Amazon Redshift cluster to Redshift Serverless.
Conclusion
In this post, we discussed four different use cases, demonstrating the benefits of Amazon Redshift Serverless—from its easy analytics, ease of use, superior performance, and cost savings that can be realized from the pay-per-use pricing model.
Amazon Redshift provides flexibility and choice in data warehousing. Amazon Redshift Provisioned is a great choice for customers who need a custom provisioning environment with more granular controls; and with Redshift Serverless, you can start new data warehousing workloads in minutes with dynamic auto scaling, no infrastructure management, and a pay-per-use pricing model.
We encourage you to start using Amazon Redshift Serverless today and enjoy the many benefits it offers.
About the Authors
 Ahmed Shehata is a Data Warehouse Specialist Solutions Architect with Amazon Web Services, based out of Toronto.
Ahmed Shehata is a Data Warehouse Specialist Solutions Architect with Amazon Web Services, based out of Toronto.
 Manish Vazirani is an Analytics Platform Specialist at AWS. He is part of the Data-Driven Everything (D2E) program, where he helps customers become more data-driven.
Manish Vazirani is an Analytics Platform Specialist at AWS. He is part of the Data-Driven Everything (D2E) program, where he helps customers become more data-driven.
 Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He has nearly two decades of experience helping customers modernize their data platforms. He is passionate about helping customers build scalable, cost-effective data and analytics solutions in the cloud. In his spare time, he enjoys spending time with his family, travel, and road cycling.
Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He has nearly two decades of experience helping customers modernize their data platforms. He is passionate about helping customers build scalable, cost-effective data and analytics solutions in the cloud. In his spare time, he enjoys spending time with his family, travel, and road cycling.