AWS Compute Blog
Hosting Hugging Face models on AWS Lambda for serverless inference
This post written by Eddie Pick, AWS Senior Solutions Architect – Startups and Scott Perry, AWS Senior Specialist Solutions Architect – AI/ML
Hugging Face Transformers is a popular open-source project that provides pre-trained, natural language processing (NLP) models for a wide variety of use cases. Customers with minimal machine learning experience can use pre-trained models to enhance their applications quickly using NLP. This includes tasks such as text classification, language translation, summarization, and question answering – to name a few.
First introduced in 2017, the Transformer is a modern neural network architecture that has quickly become the most popular type of machine learning model applied to NLP tasks. It outperforms previous techniques based on convolutional neural networks (CNNs) or recurrent neural networks (RNNs). The Transformer also offers significant improvements in computational efficiency. Notably, Transformers are more conducive to parallel computation. This means that Transformer-based models can be trained more quickly, and on larger datasets than their predecessors.
The computational efficiency of Transformers provides the opportunity to experiment and improve on the original architecture. Over the past few years, the industry has seen the introduction of larger and more powerful Transformer models. For example, BERT was first published in 2018 and was able to get better benchmark scores on 11 natural language processing tasks using between 110M-340M neural network parameters. In 2019, the T5 model using 11B parameters achieved better results on benchmarks such as summarization, question answering, and text classification. More recently, the GPT-3 model was introduced in 2020 with 175B parameters and in 2021 the Switch Transformers are scaling to over 1T parameters.
One consequence of this trend toward larger and more powerful models is an increased barrier to entry. As the number of model parameters increases, as does the computational infrastructure that is necessary to train such a model. This is where the open-source Hugging Face Transformers project helps.
Hugging Face Transformers provides over 30 pretrained Transformer-based models available via a straightforward Python package. Additionally, there are over 10,000 community-developed models available for download from Hugging Face. This allows users to use modern Transformer models within their applications without requiring model training from scratch.
The Hugging Face Transformers project directly addresses challenges associated with training modern Transformer-based models. Many customers want a zero administration ML inference solution that allows Hugging Face Transformers models to be hosted in AWS easily. This post introduces a low touch, cost effective, and scalable mechanism for hosting Hugging Face models for real-time inference using AWS Lambda.
Overview
Our solution consists of an AWS Cloud Development Kit (AWS CDK) script that automatically provisions container image-based Lambda functions that perform ML inference using pre-trained Hugging Face models. This solution also includes Amazon Elastic File System (EFS) storage that is attached to the Lambda functions to cache the pre-trained models and reduce inference latency.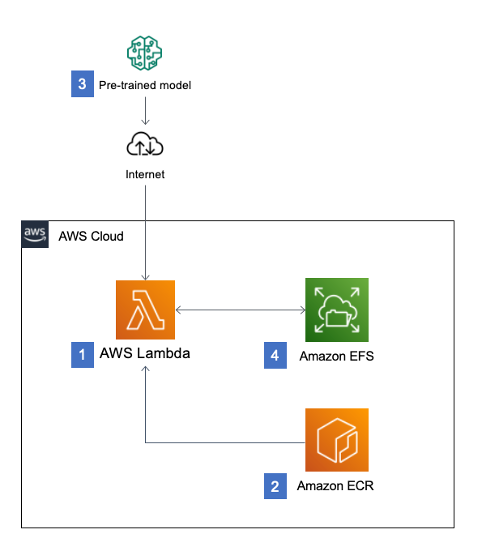
In this architectural diagram:
- Serverless inference is achieved by using Lambda functions that are based on container image
- The container image is stored in an Amazon Elastic Container Registry (ECR) repository within your account
- Pre-trained models are automatically downloaded from Hugging Face the first time the function is invoked
- Pre-trained models are cached within Amazon Elastic File System storage in order to improve inference latency
The solution includes Python scripts for two common NLP use cases:
- Sentiment analysis: Identifying if a sentence indicates positive or negative sentiment. It uses a fine-tuned model on sst2, which is a GLUE task.
- Summarization: Summarizing a body of text into a shorter, representative text. It uses a Bart model that was fine-tuned on the CNN / Daily Mail dataset.
For simplicity, both of these use cases are implemented using Hugging Face pipelines.
Prerequisites
The following is required to run this example:
- git
- AWS CDK
- Python 3.6+
- A virtual env (optional)
Deploying the example application
- Clone the project to your development environment:
git clone https://github.com/aws-samples/zero-administration-inference-with-aws-lambda-for-hugging-face.git - Install the required dependencies:
pip install -r requirements.txt - Bootstrap the CDK. This command provisions the initial resources needed by the CDK to perform deployments:
cdk bootstrap - This command deploys the CDK application to its environment. During the deployment, the toolkit outputs progress indications:
$ cdk deploy
Testing the application
After deployment, navigate to the AWS Management Console to find and test the Lambda functions. There is one for sentiment analysis and one for summarization.
To test:
- Enter “Lambda” in the search bar of the AWS Management Console:

- Filter the functions by entering “ServerlessHuggingFace”:

- Select the ServerlessHuggingFaceStack-sentimentXXXXX function:

- In the Test event, enter the following snippet and then choose Test:

{
"text": "I'm so happy I could cry!"
}The first invocation takes approximately one minute to complete. The initial Lambda function environment must be allocated and the pre-trained model must be downloaded from Hugging Face. Subsequent invocations are faster, as the Lambda function is already prepared and the pre-trained model is cached in EFS.
The JSON response shows the result of the sentiment analysis:
{
"statusCode": 200,
"body": {
"label": "POSITIVE",
"score": 0.9997532367706299
}
}Understanding the code structure
The code is organized using the following structure:
├── inference
│ ├── Dockerfile
│ ├── sentiment.py
│ └── summarization.py
├── app.py
└── ...
The inference directory contains:
- The Dockerfile used to build a custom image to be able to run PyTorch Hugging Face inference using Lambda functions
- The Python scripts that perform the actual ML inference
The sentiment.py script shows how to use a Hugging Face Transformers model:
import json
from transformers import pipeline
nlp = pipeline("sentiment-analysis")
def handler(event, context):
response = {
"statusCode": 200,
"body": nlp(event['text'])[0]
}
return responseFor each Python script in the inference directory, the CDK generates a Lambda function backed by a container image and a Python inference script.
CDK script
The CDK script is named app.py in the solution’s repository. The beginning of the script creates a virtual private cloud (VPC).
vpc = ec2.Vpc(self, 'Vpc', max_azs=2)Next, it creates the EFS file system and an access point in EFS for the cached models:
fs = efs.FileSystem(self, 'FileSystem',
vpc=vpc,
removal_policy=cdk.RemovalPolicy.DESTROY)
access_point = fs.add_access_point('MLAccessPoint',
create_acl=efs.Acl(
owner_gid='1001', owner_uid='1001', permissions='750'),
path="/export/models",
posix_user=efs.PosixUser(gid="1001", uid="1001"))>It iterates through the Python files in the inference directory:
docker_folder = os.path.dirname(os.path.realpath(__file__)) + "/inference"
pathlist = Path(docker_folder).rglob('*.py')
for path in pathlist:And then creates the Lambda function that serves the inference requests:
base = os.path.basename(path)
filename = os.path.splitext(base)[0]
# Lambda Function from docker image
function = lambda_.DockerImageFunction(
self, filename,
code=lambda_.DockerImageCode.from_image_asset(docker_folder,
cmd=[
filename+".handler"]
),
memory_size=8096,
timeout=cdk.Duration.seconds(600),
vpc=vpc,
filesystem=lambda_.FileSystem.from_efs_access_point(
access_point, '/mnt/hf_models_cache'),
environment={
"TRANSFORMERS_CACHE": "/mnt/hf_models_cache"},
)Adding a translator
Optionally, you can add more models by adding Python scripts in the inference directory. For example, add the following code in a file called translate-en2fr.py:
import json
from transformers
import pipeline
en_fr_translator = pipeline('translation_en_to_fr')
def handler(event, context):
response = {
"statusCode": 200,
"body": en_fr_translator(event['text'])[0]
}
return responseThen run:
$ cdk synth
$ cdk deployThis creates a new endpoint to perform English to French translation.
Cleaning up
After you are finished experimenting with this project, run “cdk destroy” to remove all of the associated infrastructure.
Conclusion
This post shows how to perform ML inference for pre-trained Hugging Face models by using Lambda functions. To avoid repeatedly downloading the pre-trained models, this solution uses an EFS-based approach to model caching. This helps to achieve low-latency, near real-time inference. The solution is provided as infrastructure as code using Python and the AWS CDK.
We hope this blog post allows you to prototype quickly and include modern NLP techniques in your own products.