AWS Database Blog
Validate database objects after migrating from IBM Db2 LUW to Amazon Aurora PostgreSQL or Amazon RDS for PostgreSQL
Heterogeneous database migration is a multistage process, which usually includes assessment, database schema conversion, data migration, functional testing, performance tuning, and many other steps spanning across multiple teams. Migration from IBM Db2 LUW to Amazon Aurora PostgreSQL-Compatible Edition or Amazon Relational Database Service (Amazon RDS) for PostgreSQL is heterogeneous in nature, and traditionally follows similar phases.
AWS provides tools and services like AWS Schema Conversion Tool (AWS SCT), which simplifies schema conversion for heterogeneous database migration, and AWS Database Migration Service (AWS DMS), which helps you migrate data to AWS quickly and securely while minimizing downtime.
AWS SCT generates an assessment report showing the percentage of Db2 code that is converted to PostgreSQL automatically and the percentage of code that requires manual effort for conversion with detailed action items. Because schema migration with AWS SCT isn’t a fully automated process, there is always a chance of missing objects or key object features in the target database. Schema validation is a crucial milestone that prevents slippage of any issues from the schema conversion process to other stages of the database migration.
In this post, we walk you through how to validate database schema objects migrated from Db2 LUW to Amazon RDS for PostgreSQL or Aurora PostgreSQL.
When and what objects to validate
You should perform schema validation after you successfully convert your schema from Db2 LUW and deploy the converted schema in PostgreSQL using AWS SCT or other conversion tools.
The following list shows the database objects in Db2 LUW (source) and Aurora PostgreSQL (target) that you should validate during database migration:
- Schemas
- Tables
- Views
- Primary keys
- Foreign keys
- Indexes
- Materialized query tables
- User-defined data types
- Triggers
- Sequences
- Procedures
- Functions
In the following sections, we go through validation scenarios for each object type in detail to ensure that the number of objects for each object type remains consistent between source and target databases. These validation scenarios do not cover the accuracy of the conversion.
Schemas
Schemas represent a collection of database objects that serve a related functionality in an application or microservice. You can validate the schemas at the source and target databases using SQL queries.
| DB2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
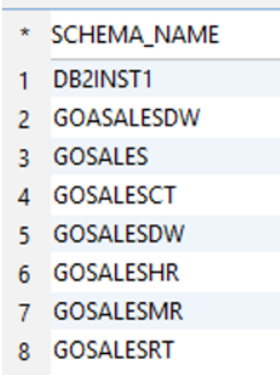 |
PostgreSQL example output:
 |
When you convert your Db2 LUW schema, AWS SCT adds additional schemas (aws_db2_ext and aws_db2_ext_data) to your target database. These schemas implement SQL system functions of the Db2 LUW database that are required when writing the converted schema to your Aurora PostgreSQL database. These additional schemas are called the AWS SCT extension pack.
We exclude schemas related to system or catalog tables (SYS%,’SQLJ‘, ‘NULLID‘) in Db2 LUW and in PostgreSQL (‘pg_catalog‘,’information_schema‘, ‘public‘). We also exclude schemas related to specific functionality in Aurora PostgreSQL (aws_commons, aws_lambda).
You should verify the number of schemas in the source and target database matches. If any differences are found, you should look at the AWS SCT logs to identify reasons for failure or create it manually.
Tables
AWS SCT converts source Db2 LUW tables to the equivalent target (PostgreSQL) tables. If required, we can use custom mapping rules to include or exclude specific tables from migration. The following scripts return the counts and detail-level information for all the tables:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
We added the condition C.RELISPARTITION = 'f' to filter out the partition table in PostgreSQL because IBM Db2 doesn’t list table partitions as separate tables. It’s important to note that PostgreSQL has several restrictions on partition tables that might impact object counts for primary keys, foreign keys, and indexes.
For detail-level information, use the following queries:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |

Verify the results from the source and target databases. If you see any differences, identify the reason from the AWS SCT or manual logs and rerun the failed statement after fixing the problem.
Views
You can validate the views count converted by AWS SCT with the following queries on the source and target databases:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
You should verify the count and details between the source and target using this SQL. If any differences are found, identify the cause and fix the differences.
Primary keys
Along with database object validation, you need to ensure the data is consistent and bound to integrity. Different types of constraints provide you with the flexibility to control and check the data during insertion to avoid runtime data integrity issues.
Primary keys allow you to have unique values for columns, which prevent information from being duplicated, following the normalization process. This key helps improve the search based on the key values and avoid table scans.
The following queries help you extract the counts and details of primary keys in the source and target databases:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
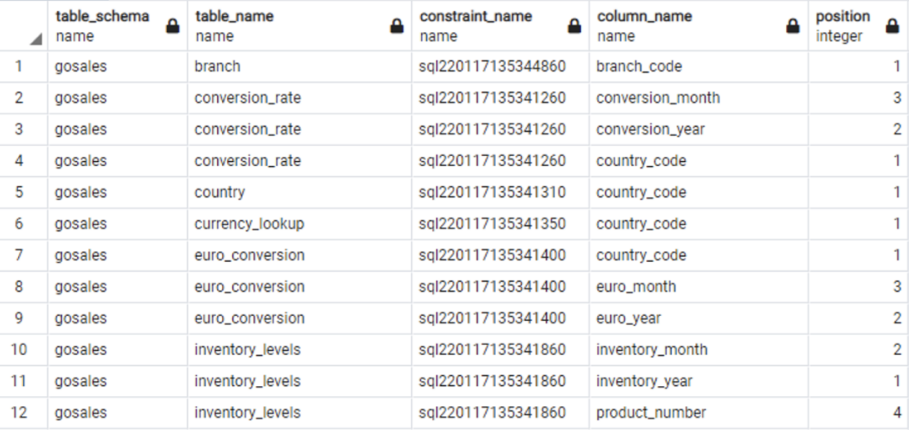 |
You should verify the count and details of the primary keys between the source and target using this SQL. If any differences are found, identify the cause through the deployment logs and fix the differences.
Foreign keys
Foreign keys help you maintain referential integrity between tables. These keys should be turned off on the target before performing data migration using AWS DMS full load migration. For more information, see Using a PostgreSQL database as a target for AWS Database Migration Service.
With the following queries, you get the counts and detail-level information about the foreign keys in both the source and target databases. You validate the foreign keys after completing the full load data migration using AWS DMS.
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
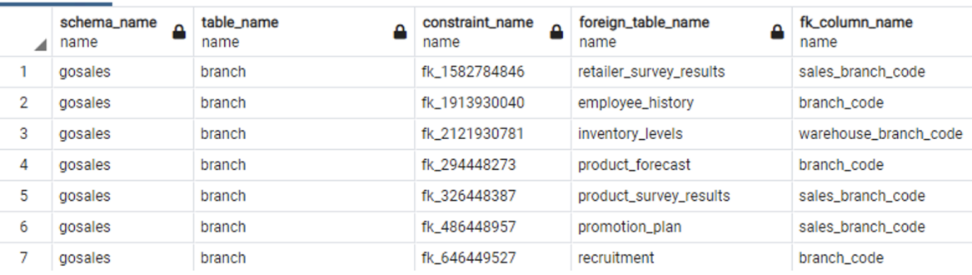 |
PostgreSQL version 11 has limitations with respect to foreign keys on partitioned tables, but many of those limitations are overcome in version 12 and onwards. You should keep these limitations in mind when verifying the count and detail of foreign keys between the source and target database.
Indexes
Indexes are the database objects created based on one or more columns of a table. Indexes are used to improve the query performance and ensure uniqueness of data when defined as unique indexes.
Unique indexes
With unique keys, you can maintain the uniqueness of data in the column. With the following queries, you get the counts and detail-level information about the unique keys in both the source and target databases:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
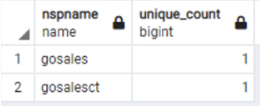 |
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
Non-unique indexes
Indexes play a key role in improving query performance. Because tuning methodologies differ from database to database, the number of indexes and their types vary between Db2 LUW and PostgreSQL databases based on different use cases, so index counts also may differ. The index count may also differ due to the limitation of partitioned tables in PostgreSQL.
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
You should verify the count and detail of indexes between the source and target database, and any differences should either be attributed to a known reason or investigated and fixed based on the deployment logs.
Materialized query tables
Materialized query tables from Db2 LUW are migrated as materialized views in PostgreSQL. They’re similar to regular views, except that the materialized query tables persist the results in a table-like form. This improves query performance because the data is readily available to be returned. You can use the following queries to compare the objects between source and target:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
You should verify the count and detail of materialized query tables and materialized views between the source and target database, and any differences should be investigated and fixed based on the deployment logs.
User-defined data types
AWS SCT migrates custom data types from Db2 LUW to PostgreSQL as types. You can use the following queries to compare the objects between source and target:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
You should verify the count and detail of user-defined types between the source and target databases, and any differences should be investigated and fixed based on the deployment logs.
Triggers
Triggers can help you audit databases, implement a business rule, or implement referential integrity. They can also impact performance based on usage in appropriate areas. The following queries give you the count and details of triggers for both the source and target databases:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
The trigger count between Db2 LUW and PostgreSQL could vary because of the way triggers are implemented in PostgreSQL. You should verify the count and detail of triggers between the source and target databases, and any differences should either be attributed to a known reason or investigated and fixed based on the deployment logs.
Sequences
Sequences help you create and increment integer values for columns based on given ranges and order. Unlike identity columns, sequences aren’t associated with specific tables. Applications refer to a sequence object to retrieve its next value. The relationship between sequences and tables is controlled by the application. User applications can reference a sequence object and coordinate the values across multiple rows and tables.
The following queries help you get the counts and detail-level information of sequences available in the source and target databases:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
|
You should verify the count and details of sequences between source and target, but it’s also important that you set the sequence to the correct values after migration. Setting the sequence is important because after sequences are migrated from the source to target database, they start with the minvalue of the sequence and can cause duplicate key errors during insert and update statements.
Procedures
Db2 LUW stored procedures encapsulate business logic and run related DDL or DML operations in a single unit of work. In PostgreSQL, we use functions over stored procedures, owing to the limitations of procedures. This count gets added to the already existing function count in the source database. In both the source and target databases, the following queries provide counts and detail-level information about the procedures:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
Functions
In Db2 LUW, functions implement specific business or functional logic on input parameters and return certain types of predefined output. In PostgreSQL, because functions are the preferred choice to implement business and functional logic, their count is usually more than Db2 LUW. In both the source and target databases, the following queries provide counts and detail-level information about the functions:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
|
For detail-level information, use the following query:
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
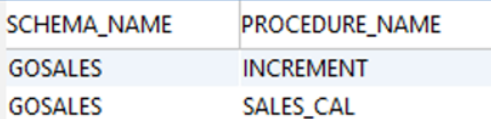 |
PostgreSQL example output:
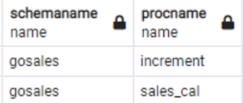 |
Useful PostgreSQL catalog tables
The following table summarizes some helpful Db2 LUW and their corresponding PostgreSQL system and catalog tables and views. These tables and views contain metadata with respect to various objects present in the database and are used for database object validation.
| Db2 LUW | PostgreSQL | Use Case |
| syscat.tables/ syscat.columns |
pg_tables /information_schema.tables |
Look for various table properties |
| syscat.tables/ syscat.columns | Pg_views/information_schema.views | Look for different properties of views |
| syscat.tables/ syscat.tabconst/ syscat.references/ syscat.keycoluse | pg_indexes/pg_index | Gather details about indexes |
| syscat.routines | pg_proc | Gather details about procedures, functions, and trigger functions |
| syscat.triggers | information_schema.triggers | Gather details about triggers |
| Syscat.sequences | pg_sequence/information_schema.sequences | Gather details about sequence, and identity or serial columns |
| Syscat.tables | pg_matviews | Find more details about materialized views |
| syscat.datatypes | pg_type | Gather more information about custom data types |
Handling objects not supported in PostgreSQL
You must manually perform migration of Db2 LUW objects not supported by PostgreSQL. You can use the queries provided in this post to iteratively validate the migrated objects to identify gaps and fix them accordingly.
Conclusion
In this post, we discussed validation of database objects with metadata queries for Db2 LUW and Aurora PostgreSQL or RDS for PostgreSQL databases. Database object validation is an essential step that provides an in-depth view into migration accuracy and confirms whether all database objects are migrated appropriately. The database validation phase also confirms the integrity of the target database and ensures business continuity of the dependent application processes.
You should do a few rounds of unit testing as well as functional testing irrespective of whether an object is automatically or manually converted. This saves a lot of rework when you conduct integration testing with your applications.
Let us know if you have any comments or questions. We value your feedback!
About the Authors
 Sai Parthasaradhi is a Database Migration Specialist with AWS Professional Services. He works closely with customers to help them migrate and modernize their databases on AWS.
Sai Parthasaradhi is a Database Migration Specialist with AWS Professional Services. He works closely with customers to help them migrate and modernize their databases on AWS.
 Rakesh Raghav is a Lead Database Consultant with the AWS Professional Services in India, helping customers have a successful cloud adoption and migration journey. He is passionate about building innovative solutions to accelerate their database journey to the cloud.
Rakesh Raghav is a Lead Database Consultant with the AWS Professional Services in India, helping customers have a successful cloud adoption and migration journey. He is passionate about building innovative solutions to accelerate their database journey to the cloud.
 Veeranjaneyulu Grandhi is a Database Consultant with Amazon Web Services. He works with customers to build scalable, highly available, and secure solutions in the AWS Cloud. His focus area is homogenous and heterogeneous database migrations.
Veeranjaneyulu Grandhi is a Database Consultant with Amazon Web Services. He works with customers to build scalable, highly available, and secure solutions in the AWS Cloud. His focus area is homogenous and heterogeneous database migrations.