Amazon Web Services ブログ
Amazon SageMaker で NVIDIA Triton Inference Server を使用してモデルサーバのハイパースケールパフォーマンスを実現する
機械学習 (ML) アプリケーションはデプロイが複雑で、多くの場合、1 つの推論リクエストを処理するために複数の ML モデルが必要です。典型的なリクエストは、前処理、データ変換、モデル選択ロジック、モデル集約、後処理などの複数モデルに渡る場合があります。これにより、シリアル推論パイプライン、アンサンブル (scatter gather)、ビジネスロジックワークフローなどの一般的な設計パターンが進化し、リクエストのワークフロー全体が有向非巡回グラフ (DAG) として実現されるに至りました。しかしながら、ワークフローがより複雑になるにつれて、これらのアプリケーションの全体的なレスポンス時間またはレイテンシが増加し、全体的なユーザーエクスペリエンスに影響を与えます。さらに、これらのコンポーネントが異なるインスタンスでホストされている場合、インスタンス間の追加のネットワークレイテンシにより、全体的なレイテンシが増加します。カスタマーサポートにおける仮想アシスタントの一般的な ML ユースケースの例を考えてみましょう。典型的なリクエストとして、音声認識、自然言語処理 (NLP)、ダイアログ状態の追跡、ダイアログポリシー、テキスト生成、そして最後にテキスト読み上げを含むいくつかのステップを経なければならない場合があります。さらに、ユーザーインタラクションをよりパーソナライズするために、さまざまなバージョンの BERT、BART、GPT などの最先端のトランスフォーマーベースの NLP モデルを使用することもできます。その結果、これらのモデルアンサンブルのレスポンス時間が長くなり、カスタマーエクスペリエンスが低下します。
全体的なスループットを犠牲にすることなくレスポンス時間を短縮する一般的なパターンは、軽量なビジネスロジックをモデルに組み込みつつ、それらのモデルを同じインスタンス上でホストすることです。これらのモデルは、実行中のプロセスを分離し、レイテンシを低く抑えるために、同じインスタンス上の単一または複数のコンテナ内にさらにカプセル化できます。さらに、全体的なレイテンシは、推論アプリケーションロジック、モデルの最適化、基盤となるインフラストラクチャ (コンピューティング、ストレージ、ネットワークを含む)、および推論リクエストを受け取る基盤となる Web サーバにも依存します。 NVIDIA Triton Inference Server は、極めて低い (1 桁ミリ秒) 推論レイテンシでスループットとハードウェア使用率を最大化する機能を備えたオープンソースの推論サービングソフトウェアです。 ML フレームワーク (TensorFlow、PyTorch、ONNX、XGBoost、NVIDIA TensorRT など) と、GPU、CPU、AWS Inferentia などのインフラストラクチャ バックエンドを幅広くサポートしています。さらに、Triton Inference Server は、フルマネージド型のエンドツーエンド ML サービスである Amazon SageMaker と統合されており、単一および複数モデルのホスティングを含むリアルタイムの推論オプションを提供します。これらの推論オプションには、単一のエンドポイントの背後にある同じコンテナ内で複数のモデルをホストすること、および単一エンドポイントの背後にある複数のコンテナを使用して複数のモデルをホストすることが含まれます。
2021 年 11 月、SageMaker での Triton Inference Server の統合を発表しました。 AWS は NVIDIA と緊密に連携して、両方の長所を活用し、AWS で Triton を使用してモデルより簡単にデプロイできるようにしました。
この投稿では、SageMaker で Triton Inference Server を使用して GPU 上で大規模にトランスフォーマーモデルをデプロイするためのベストプラクティスを見ていきます。 まず、SageMaker のレイテンシに関する主要な概念、パフォーマンスチューニングのガイドラインの概要から始めます。 次に、Triton とその機能の概要、また SageMaker にデプロイするためのコード例を示します。 最後に、SageMaker Inference Recommender を使用して負荷テストを実施し、Hugging Face が提供する一般的なトランスフォーマーモデルの負荷テストからの洞察と結論をまとめます。
モデルのデプロイに使用したノートブックを確認し、GitHub のコードを使用して自分で負荷テストを実行できます。
SageMaker で提供するモデルのパフォーマンスチューニングと最適化
多くの場合、パフォーマンスのチューニングと最適化は、何度も試行錯誤を繰り返す経験的なプロセスです。調整すべきパラメータ数は組み合わせであり、一連の設定パラメータ値は互いに独立していません。ペイロードサイズ、タイプ、推論リクエストフローグラフ内の ML モデルの数、ストレージタイプ、コンピューティングインスタンスタイプ、ネットワークインフラストラクチャ、アプリケーションコード、推論サービングソフトウェアのランタイムとその他設定など、さまざまな要因が最適なパラメータチューニングに影響します。
ML モデルのデプロイに SageMaker を使用している場合、最高のコストパフォーマンスを備えたコンピューティングインスタンスを選択する必要があります。これは複雑で反復的なプロセスであり、数週間の実験が必要になる場合があります。まず、モデルのリソース要件と入力データのサイズに基づいて、70 を超えるオプションから適切な ML インスタンスタイプを選択する必要があります。次に、選択したインスタンスタイプにモデルを最適化する必要があります。最後に、最適なパフォーマンスとコストを実現するために、負荷テストを実行し、クラウド構成を調整するためのインフラのプロビジョニングと管理を行う必要があります。これらすべてが、モデルのデプロイと市場投入までの時間を遅らせる可能性があります。さらに、最適なデプロイメント構成を選択するには、待機時間、スループット、およびコストの間のトレードオフを評価する必要があります。 SageMaker Inference Recommender は、適切なコンピューティングインスタンスタイプ、インスタンス数、コンテナパラメータ、モデル最適化を自動的に選択して、スループットを最大化し、レイテンシを削減し、コストを最小化します。
SageMaker でのリアルタイム推論とレイテンシ
SageMaker リアルタイム推論は、リアルタイム、インタラクティブ、低レイテンシの要件がある推論ワークロードに最適です。 SageMaker 推論エンドポイントの推論リクエストのレイテンシをモニタリングするために最も一般的に使用されるメトリクスは 4 つあります。
- コンテナのレイテンシ – リクエストの送信、モデルのコンテナからのレスポンスの取得、およびコンテナでの完全な推論にかかる時間。このメトリクスは、SageMaker によって発行される Invocation Metrics の一部として Amazon CloudWatch で利用できます。
- モデルのレイテンシ – 推論パイプライン内のすべての SageMaker コンテナにかかった合計時間。このメトリクスは、SageMaker によって発行された Invocation Metrics の一部として Amazon CloudWatch で利用できます。
- オーバーヘッドレイテンシ – SageMaker がリクエストを受信してからクライアントにレスポンスを返すまでの時間から、モデルのレイテンシを差し引いて測定されます。このメトリクスは、SageMaker によって発行される Invocation Metrics の一部として Amazon CloudWatch で利用できます。
- エンドツーエンドのレイテンシ – クライアントが推論リクエストを送信してから、レスポンスを受信するまでの時間を測定します。お客様は、Amazon CloudWatch でこれをカスタム メトリクスとして発行できます。
次の図は、これらのコンポーネントを示しています。

コンテナのレイテンシは、いくつかの要素に起因します。 以下は最も重要なものです。
- 推論サーバとの通信に使用される基になるプロトコル (HTTP(s)/gRPC)
- 新しい TLS 接続の作成に関連するオーバーヘッド
- リクエスト/レスポンスペイロードのデシリアライズ時間
- 推論サーバによって提供されるリクエストのキューイングおよびバッチ機能
- 推論サーバによって提供されるリクエストスケジューリング機能
- 推論サーバの基本的なランタイムパフォーマンス
- モデル Prediction 関数を呼び出す前の前処理および後処理ライブラリのパフォーマンス
- ML フレームワークのバックエンドパフォーマンス
- モデル固有およびハードウェア固有の最適化
この記事では、全体的なスループットとコストとともに、コンテナのレイテンシを最適化することに主に焦点を当てています。 具体的には、SageMaker コンテナ内で実行されている Triton Inference Server のパフォーマンス チューニングについて説明します。
ユースケースの概要
本番環境で NLP モデルをデプロイしてスケーリングすることは非常に困難な場合があります。多くの場合、NLP モデルはサイズが非常に大きく、数百万のモデルパラメータが含まれています。本番グレードの NLP アプリケーションの厳しいパフォーマンスとスケーラビリティの要件を満たすには、最適なモデル構成が必要です。
この投稿では、Triton Inference Server コンテナに基づく SageMaker リアルタイムエンドポイントを使用して NLP ユースケースのベンチマークを行い、ML ユースケースのパフォーマンスチューニングの最適化を推奨します。約 3 億 3600 万個のモデルパラメータを持つ、事前学習済みの transformer ベースのHugging Face BERT large uncased モデルを使用しています。二値分類モデルに使用される入力文は、最大入力シーケンス長 512 トークンまでパディングもしくは切り詰められます。推論負荷テストでは、秒間 500 回の呼び出し (1 分に最大 30,000 回の呼び出し) と 0.5 秒 (500 ミリ秒) 未満の ModelLatency をシミュレートしています。
次の表は、ベンチマーク構成を要約したものです。
| モデル名 | Hugging Face bert-large-uncased |
| モデルサイズ | 1.25 GB |
| レイテンシ要件 | 0.5 秒 (500 ミリ秒) |
| 1 秒当たりの呼び出し | 500 リクエスト (1 分あたり 30,000) |
| 入力シーケンス長 | 512 トークン |
| ML タスク | 二値分類 |
NVIDIA Triton 推論サーバ
Triton Inference Server は、本番環境でモデルをスケーラブルで迅速かつ簡単にデプロイできるように特別に設計されています。 Triton は、TensorFlow、TensorRT、PyTorch、XGBoost、ONNX など、主要な AI フレームワークをサポートしています。 Python と C++ のカスタムバックエンドを使用すると、よりカスタマイズされたユースケースのために推論ワークロードを実装することもできます。
最も重要なことは、Triton がモデルをホストするためのシンプルな構成ベースのセットアップを提供することです。これにより、少しコーディングするだけで豊富なパフォーマンス最適化機能群を体験することができます。
Triton は、さまざまな最適化手法を使用してハードウェアの使用率を最大化することで、推論のパフォーマンスを向上させます (モデルの同時実行と動的バッチ処理が最も頻繁に使用されます)。 ダイナミックバッチサイズと同時実行モデルインスタンス数の様々な組み合わせから最適なモデル構成を見つけ出すことが、Triton を使用して低コストでリアルタイム推論を実現するための鍵となります。
動的バッチ処理
サーバが複数の独立したリクエストで呼び出されると、多くの実行処理の仕組みでは推論を順次実行する傾向があります。 セットアップは簡単ですが、通常、GPU の計算能力を非効率に利用することはベストプラクティスではありません。 これに対処するために、Triton は動的バッチ処理の組み込みの最適化を提供し、サーバ側でこれらの独立した推論リクエストを組み合わせてより大きなバッチを動的に形成し、スループットを向上させます。 次の図は、Triton ランタイムアーキテクチャを示しています。

上述のアーキテクチャでは、すべてのリクエストは、実際のモデルスケジューラキューに入る前に、最初に動的バッチャーに到達し推論を待機します。 モデル構成の preferred_batch_size 設定を使用して、動的バッチ処理の優先バッチサイズを設定できます。 (形成されたバッチサイズは、モデルがサポートする max_batch_size 未満である必要があることに注意してください。) max_queue_delay_microseconds で、レイテンシ要件に基づいて、他のリクエストがバッチに参加するのを待つための、 バッチャーの最大遅延時間を指定します。
次のコードスニペットは、モデル構成ファイルを使用してこの機能を追加し、実際の推論に優先バッチサイズ 16 で動的バッチ処理を設定する方法を示しています。 現在の設定では、16 の優先バッチサイズが満たされるか、最初のリクエストが動的バッチャーに到達してから 100 マイクロ秒経過すると、モデル インスタンスが即座に呼び出されます。
モデルの同時実行
レイテンシオーバーヘッドを追加することなくハードウェアを最大限に活用するために、Triton が提供するもう一つの重要な最適化は、複数のモデルまたは同じモデルの複数のコピーを並行して実行するコンカレントモデル実行です。 この機能により、Triton は複数の推論リクエストを同時に処理できるようになり、ハードウェアでアイドル状態のコンピューティングパワーを利用することで、推論のスループットが向上します。
次の図は、コードを数行変更するだけで、さまざまなモデルの展開ポリシーを簡単に設定する方法を示しています。 たとえば、構成 A (左) は、bert-large-uncased の 2 つのモデルインスタンスの同じ構成を、使用可能なすべての GPU にブロードキャストできることを示しています。 対照的に、構成 B (中央) は、他の GPU のポリシーを変更せずに、GPU 0 のみが異なる構成を示しています。 構成 C (右) に示すように、単一の GPU に異なるモデルのインスタンスをデプロイすることもできます。

構成 C では、コンピューティング インスタンスは、DistilGPT-2 モデルの 2 つの同時リクエストと、bert-large-uncased モデルの 7 つの同時リクエストを並行して処理できます。これらの最適化により、ハードウェアリソースをサービングプロセスにより有効に活用できるため、スループットが向上し、ワークロードのコスト効率が向上します。
TensorRT
NVIDIA TensorRT は、Triton とシームレスに連携する高性能ディープラーニング推論用の SDK です。すべての主要なディープラーニングフレームワークをサポートする TensorRT には、強力な最適化によって大量のデータで推論を実行するための低レイテンシと高スループットを実現する推論オプティマイザーとランタイムが含まれています。
TensorRT はグラフを最適化し、不要なメモリを解放して効率的に再利用することで、メモリフットプリントを最小限に抑えます。さらに、TensorRT コンパイルは、モデルグラフ内のスパース操作を融合してより大きなカーネルを形成し、複数の小さなカーネル起動のオーバーヘッドを回避します。カーネル自動チューニングは、対象とする GPU で最適なアルゴリズムを選択することにより、ハードウェアを最大限に活用するのに役立ちます。 CUDA ストリームを使用すると、モデルを並行実行して GPU の使用率を最大化し、最高のパフォーマンスを得ることができます。最後になりましたが、量子化手法は、Tensor コアの混合精度アクセラレーションを完全に使用して、モデルを FP32、TF32、FP16、および INT8 で実行し、最高の推論パフォーマンスを達成できます。
SageMaker ホスティングでの Triton
SageMaker ホスティングサービスは、モデルのデプロイと提供をより容易にすることを目的とした SageMaker の一連の機能群です。さまざまなユースケースに合わせて調整された ML モデルを簡単にデプロイ、自動スケーリング、監視、および最適化するためのさまざまなオプションを提供します。これは、サーバーレスオプションで永続的かつ常に利用可能なものから、一時的、長時間実行、またはバッチ推論のニーズまで、あらゆる種類の使用パターンに対してデプロイを最適化できることを意味します。
SageMaker ホスティングの機能群の中には、対応するサポート対象の ML フレームワークに対応したモデルサーバソフトウェアが事前にパッケージ化された SageMaker 推論 Deep Learning Containers (DLC) のセットもあります。これにより、モデルサーバのセットアップを行わなくても、高い推論パフォーマンスを実現できます。モデルサーバのセットアップは、多くの場合、モデルデプロイの最も複雑な技術的側面であり、一般に、データサイエンティストのスキルセットの一部ではありません。 Triton 推論サーバが SageMaker Deep Learning Containers (DLC) で利用できるようになりました。
この幅広いオプション、モジュール性、およびさまざまなサービングフレームワークの使いやすさにより、SageMaker と Triton は強力な組み合わせになります。
テスト結果のベンチマークのための SageMaker Inference Recommender
SageMaker Inference Recommender を使用して実験を実行します。SageMaker Inference Recommender は、次の図に示すように、Default(デフォルト)と Advanced(アドバンスド) の 2 種類のジョブを提供します。

デフォルトのジョブは、モデルとベンチマークするサンプルペイロードのみを使用して、インスタンスタイプに関する推奨事項を提供します。インスタンスの推奨事項に加えて、サービスはパフォーマンスを向上させるランタイムパラメータも提供します。デフォルトジョブの推奨事項は、インスタンス検索を絞り込むことを目的としています。絞り込みの結果はインスタンスファミリーの場合もあれば、特定のインスタンスタイプの場合もあります。その後、デフォルトジョブの結果がアドバンスドジョブに渡されます。
アドバンスドジョブは、パフォーマンスをさらに微調整するためのより多くの制御を提供します。これらの制御は、実際の環境と本番要件をシミュレートします。これらの制御の中には、ベンチマークのリクエストパターンを段階化することを目的としたトラフィックパターンがあります。トラフィックパターンの複数のフェーズを使用して、ランプ(訳注:増減トラフィック)または定常トラフィックを設定できます。たとえば、InitialNumberOfUsers が 1、SpawnRate が 1、DurationInSeconds が 600 の場合、最初に 1 人の同時接続ユーザー、最後に 10 人の同時接続ユーザーによる 10 分のランプトラフィックが発生する可能性があります。さらに、制御では、MaxInvocations と ModelLatencyThresholds が本番のしきい値を設定するため、しきい値の 1 つを超えると、ベンチマークが停止します。
最後に、レコメンデーションメトリクスには、スループット、最大スループットでのレイテンシ、および推論あたりのコストが含まれるため、簡単に比較できます。
SageMaker Inference Recommender のアドバンスドジョブタイプを使用して実験を実行し、トラフィックパターンをさらに制御し、サービングコンテナの構成を微調整します。
実験のセットアップ
SageMaker Inference Recommender のカスタム負荷テスト機能を使用して、ユースケースで説明した NLP プロファイルのベンチマークを行います。 まず、NLP モデルと ML タスクに関連する次の前提条件を定義します。 SageMaker Inference Recommender はこの情報を使用して、Amazon Elastic Container Registry (Amazon ECR) から推論 Docker イメージをプルし、モデルを SageMaker モデルレジストリに登録します。
| ドメイン | NATURAL_LANGUAGE_PROCESSING |
| タスク | FILL_MASK |
| フレームワーク | PYTORCH: 1.6.0 |
| モデル | bert-large-uncased |
SageMaker Inference Recommender のトラフィックパターン設定により、カスタム負荷テストのさまざまなフェーズを定義できます。 次のコードに示すように、ロード テストは 2 人の初期ユーザーで開始し、合計 25 分 (1500 秒) の間、毎分 2 人の新しいユーザーを生成します。
2 つの異なる状態で同じモデルの負荷テストを実験します。 PyTorch ベースの実験では、標準の変更されていない PyTorch モデルを使用します。 TensorRT ベースの実験では、事前に PyTorch モデルを TensorRT エンジンに変換します。
次の表にまとめているように、これら 2 つのモデルには、パフォーマンス最適化機能のさまざまな組み合わせを適用しています。
| 構成名 | 構成説明 | モデル構成 |
pt-base |
PyTorch ベースライン | 基本 PyTorch モデル、変更なし |
pt-db |
動的バッチ処理を使用する PyTorch | dynamic_batching
{} |
pt-ig |
複数のモデルインスタンスを持つ PyTorch | instance_group [
{
count: 2
kind: KIND_GPU
}
] |
pt-ig-db |
複数のモデルインスタンスと動的バッチ処理を備えた PyTorch | dynamic_batching
{},
instance_group [
{
count: 2
kind: KIND_GPU
}
] |
trt-base |
TensorRT ベースライン | TensoRT trtexec ユーティリティでコンパイルされた PyTorch モデル |
trt-db |
動的バッチ処理を使用する TensorRT | dynamic_batching
{} |
trt-ig |
複数のモデルインスタンスを持つ TensorRT | instance_group [
{
count: 2
kind: KIND_GPU
}
] |
trt-ig-db |
複数のモデルインスタンスと動的バッチ処理を備えた TensorRT | dynamic_batching
{},
instance_group [
{
count: 2
kind: KIND_GPU
}
] |
テスト結果と観察
同じ g4dn ファミリー内の 3 つのインスタンスタイプ ml.g4dn.xlarge、ml.g4dn.2xlarge、ml.g4dn.12xlarge に対して負荷テストを実施しました。すべての g4dn インスタンスタイプは、NVIDIA T4 Tensor コア GPU、および第 2 世代 Intel Cascade Lake プロセッサにアクセスできます。(訳注:検証のための)インスタンスタイプを選択した背景には、利用可能な GPU が 1 つだけのインスタンスと、複数の GPU (ml.g4dn.12xlarge の場合は 4 つ) にアクセスできるインスタンスの両方を持つという理由がありました。さらに、使用可能な GPU が 1 つだけのインスタンスで vCPU 容量を増やすと、コストパフォーマンス比が向上するかどうかをテストしたいと考えました。
まず個別最適化による高速化について見ていきましょう。次のグラフは、TensorRT 最適化により、ml.g4dn.xlarge インスタンスの PyTorch の最適化をしないレイテンシと比較して、モデルレイテンシが 50% 削減されることを示しています。このレイテンシの削減は、ml.g4dn.12xlarge のマルチ GPU インスタンスでは 3 倍以上になります。一方、30% のスループット向上は両方のインスタンスで一貫しており、TensorRT 最適化を適用した後の費用対効果が向上しています。

動的バッチ処理を使用すると、ml.g4dn.xlarge、ml.g4dn.2xlarge、ml.g4dn.12xlarge のすべての実験インスタンスで同じハードウェアアーキテクチャを使用して、スループットを 2 倍近く向上させることができます。

同様に、モデルの同時実行により、ml.g4dn.xlarge インスタンスの GPU 使用率を最大化することでスループットを約 3 倍から 4 倍改善し、ml.g4dn.2xlarge インスタンスと ml.g4dn.12xlarge のマルチ GPU インスタンスの両方で約 2 倍の改善を得ることができます。このスループットの増加は、レイテンシのオーバーヘッドなしで実現します。

さらに良いことに、これらすべての最適化を統合して、ハードウェアリソースを最大限に活用することで最高のパフォーマンスを提供できます。 次の表とグラフは、実験で得られた結果をまとめたものです。
| 構成名 | モデル最適化 | 動的バッチ | インスタンスグループ設定 | インスタンスタイプ | vCPUs | GPUs |
GPU メモリ (GB) |
初期インスタンス数 [1] | インスタンスあたり 1 分あたりの呼び出し | モデルレイテンシ | 1 時間あたりのコスト [2] |
| pt-base | NA | No | NA | ml.g4dn.xlarge | 4 | 1 | 16 | 62 | 490 | 1500 | 45.6568 |
| pt-db | NA | Yes | NA | ml.g4dn.xlarge | 4 | 1 | 16 | 57 | 529 | 1490 | 41.9748 |
| pt-ig | NA | No | 2 | ml.g4dn.xlarge | 4 | 1 | 16 | 34 | 906 | 868 | 25.0376 |
| pt-ig-db | NA | Yes | 2 | ml.g4dn.xlarge | 4 | 1 | 16 | 34 | 892 | 1158 | 25.0376 |
| trt-base | TensorRT | No | NA | ml.g4dn.xlarge | 4 | 1 | 16 | 47 | 643 | 742 | 34.6108 |
| trt-db | TensorRT | Yes | NA | ml.g4dn.xlarge | 4 | 1 | 16 | 28 | 1078 | 814 | 20.6192 |
| trt-ig | TensorRT | No | 2 | ml.g4dn.xlarge | 4 | 1 | 16 | 14 | 2202 | 1273 | 10.3096 |
| trt-db-ig | TensorRT | Yes | 2 | ml.g4dn.xlarge | 4 | 1 | 16 | 10 | 3192 | 783 | 7.364 |
| pt-base | NA | No | NA | ml.g4dn.2xlarge | 8 | 1 | 32 | 56 | 544 | 1500 | 52.64 |
| pt-db | NA | Yes | NA | ml.g4dn.2xlarge | 8 | 1 | 32 | 59 | 517 | 1500 | 55.46 |
| pt-ig | NA | No | 2 | ml.g4dn.2xlarge | 8 | 1 | 32 | 29 | 1054 | 960 | 27.26 |
| pt-ig-db | NA | Yes | 2 | ml.g4dn.2xlarge | 8 | 1 | 32 | 30 | 1017 | 992 | 28.2 |
| trt-base | TensorRT | No | NA | ml.g4dn.2xlarge | 8 | 1 | 32 | 42 | 718 | 1494 | 39.48 |
| trt-db | TensorRT | Yes | NA | ml.g4dn.2xlarge | 8 | 1 | 32 | 23 | 1335 | 499 | 21.62 |
| trt-ig | TensorRT | No | 2 | ml.g4dn.2xlarge | 8 | 1 | 32 | 23 | 1363 | 1017 | 21.62 |
| trt-db-ig | TensorRT | Yes | 2 | ml.g4dn.2xlarge | 8 | 1 | 32 | 22 | 1369 | 963 | 20.68 |
| pt-base | NA | No | NA | ml.g4dn.12xlarge | 48 | 4 | 192 | 15 | 2138 | 906 | 73.35 |
| pt-db | NA | Yes | NA | ml.g4dn.12xlarge | 48 | 4 | 192 | 15 | 2110 | 907 | 73.35 |
| pt-ig | NA | No | 2 | ml.g4dn.12xlarge | 48 | 4 | 192 | 8 | 3862 | 651 | 39.12 |
| pt-ig-db | NA | Yes | 2 | ml.g4dn.12xlarge | 48 | 4 | 192 | 8 | 3822 | 642 | 39.12 |
| trt-base | TensorRT | No | NA | ml.g4dn.12xlarge | 48 | 4 | 192 | 11 | 2892 | 279 | 53.79 |
| trt-db | TensorRT | Yes | NA | ml.g4dn.12xlarge | 48 | 4 | 192 | 6 | 5356 | 278 | 29.34 |
| trt-ig | TensorRT | No | 2 | ml.g4dn.12xlarge | 48 | 4 | 192 | 6 | 5210 | 328 | 29.34 |
| trt-db-ig | TensorRT | Yes | 2 | ml.g4dn.12xlarge | 48 | 4 | 192 | 6 | 5235 | 439 | 29.34 |
[1] 上記の表の初期インスタンス数は、ワークロードのスループットとレイテンシの要件を維持するために、自動スケーリングポリシーで使用するインスタンスの推奨数です。
[2] 上記の表の 1 時間あたりのコストは、初期インスタンス数とインスタンス タイプの価格に基づいて計算されます。
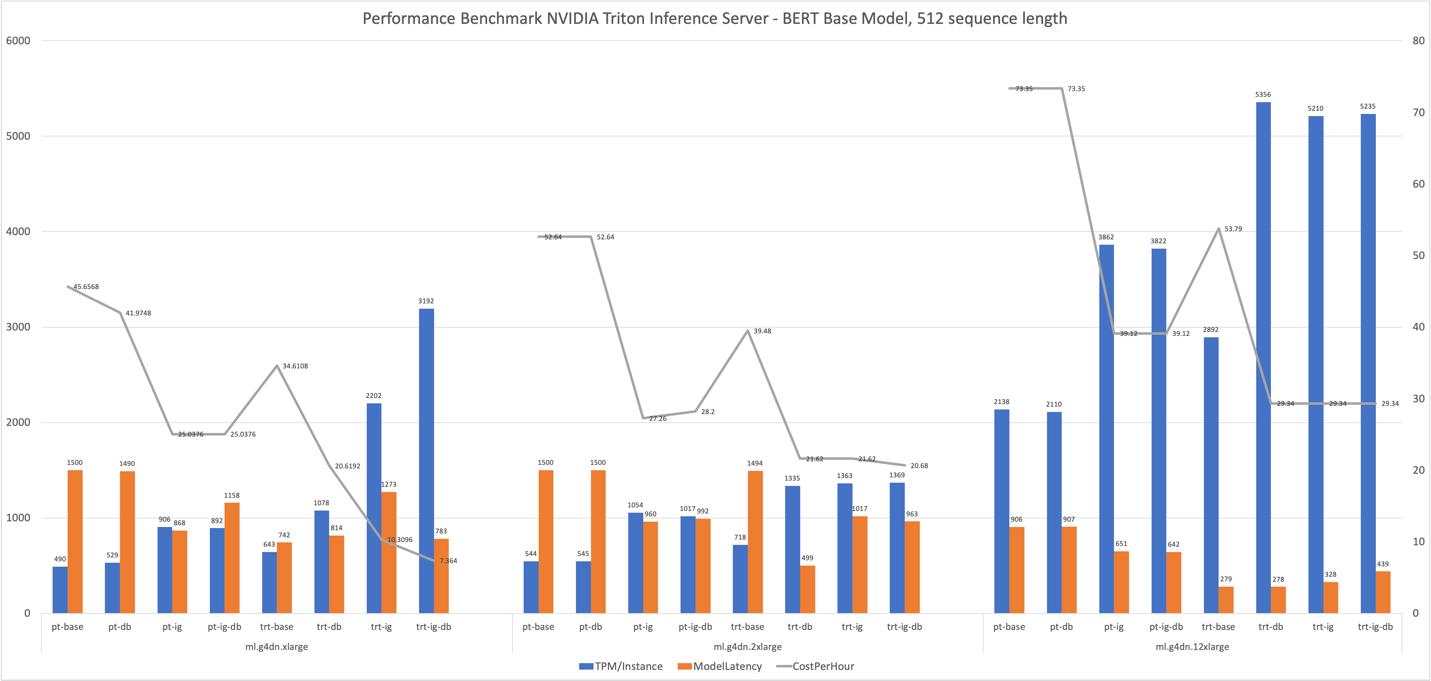
ほとんどの結果は、それぞれの性能最適化機能に期待する効果を示しています。
- TensorRT コンパイルは、すべてのインスタンスタイプで最も信頼性の高い影響を与えます。 TensorRT エンジンのパフォーマンスをデフォルトの PyTorch BERT (pt-base) と比較すると、インスタンスごとの 1 分あたりのトランザクション数(訳注:TPM)は 30 ~ 35% 増加し、一貫して約 25% のコスト削減が見られました。 TensorRT エンジンのパフォーマンスの向上は、テスト済みの他のパフォーマンスチューニング機能と組み合わされて活用されます。
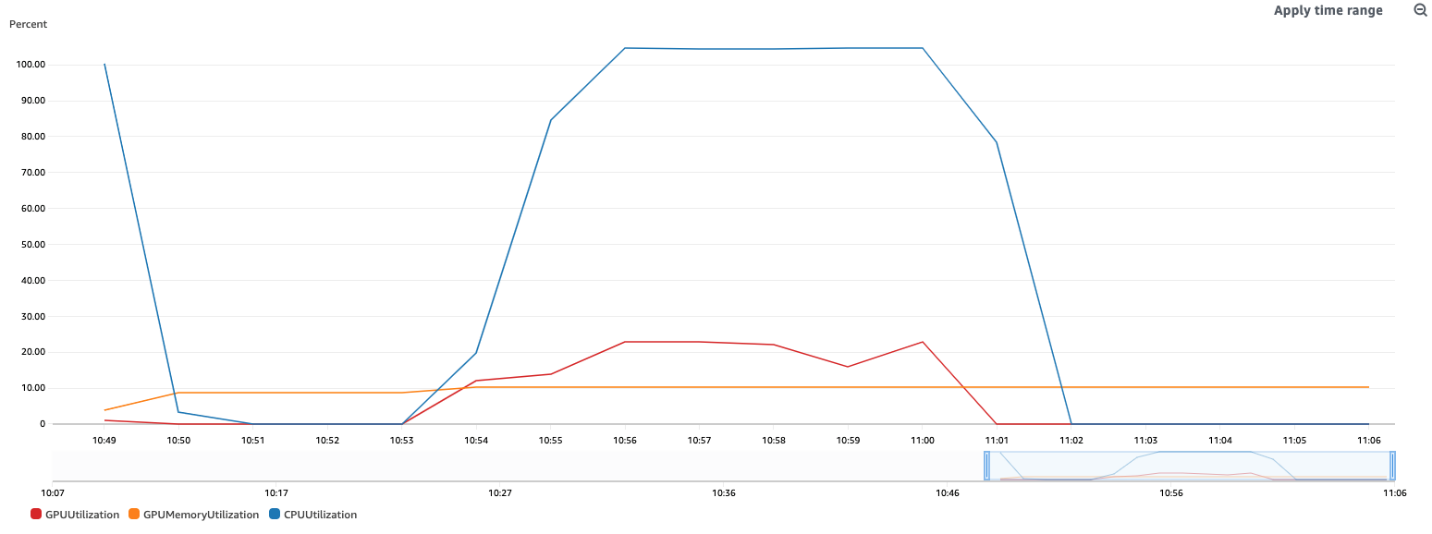
- 各 GPU (インスタンスグループ) に 2 つのモデルをロードすると、測定されたすべての指標がほぼ厳密に 2 倍になりました。 インスタンスごとの 1 分あたりの呼び出しは約 80 ~ 90% 増加し、2 つの GPU を使用しているかのように、50% の範囲でコストが削減されました。 実際、g4dn.2xlarge での実験 (例として) の Amazon CloudWatch メトリクスは、2 つのモデルのインスタンス ループを構成すると、CPU と GPU の両方の使用率が 2 倍になることを確認しています。

パフォーマンスとコストの最適化に関するその他のヒント
この投稿で紹介したベンチマークは、推論のパフォーマンスを向上させるために Triton で使用できる機能と手法の表面をなぞったにすぎません。 これらは、バイナリペイロードをモデルサーバに送信する、またはペイロードをより大きなバッチで送信するなどのデータ前処理から、次のようなネイティブの Triton 機能にまで及びます。
- モデルのウォームアップ。最初の推論リクエストを受信する前にモデルを完全に初期化することで、初回の推論リクエストで発生する遅延を防ぎます。
- レスポンスキャッシュ。繰り返し処理されるリクエストをキャッシュします。
- モデルのアンサンブル。これにより、1 つ以上のモデルのパイプラインと、それらのモデル間の入力テンソルと出力テンソルの接続を作成できます。 これにより、各リクエストの処理フローに前処理と後処理のステップを追加したり、他のモデルとの推論を追加したりする可能性が開かれます。
今後の投稿でこれらの手法と機能をテストし、ベンチマークする予定ですので、お楽しみに!
結論
この投稿では、Triton Inference Server で PyTorch BERT モデルを提供するための SageMaker リアルタイム エンドポイントのパフォーマンスを最大化するために使用できるいくつかのパラメータについて説明しました。 SageMaker Inference Recommender を使用してベンチマーク テストを実行し、これらのパラメータを微調整しました。これらのパラメータは本質的に TensorRT ベースのモデルの最適化に関連しており、最適化されていないバージョンと比較してレスポンス時間がほぼ 50% 改善されています。さらに、モデルを同時に実行し、Triton の動的バッチ処理を使用すると、スループットが約 70% 向上しました。これらのパラメータを微調整することで、推論コストも全体的に削減されました。
正しい値を導き出すには、実験するのが一番です。性能のチューニングや最適化の実践的な知見を得るはじめの一歩として、ML モデルや SageMaker ML インスタンス間で、さまざまな Triton 関連パラメータの組み合わせや性能への影響を観察するのがよいでしょう。
SageMaker は、ML ライフサイクル全体における、いわゆる「差別化されない重労働」を取り除くツールを提供するため、モデルのデプロイを完全に最適化するために必要な迅速な実験と調査が容易になります。
負荷テストとデプロイに使用されるノートブックは、GitHub で公開しています。 Triton 構成と SageMaker Inference Recommender 設定を更新してユースケースに最適化し、費用対効果が高く、最高のパフォーマンスの推論ワークロードを実現できます。
翻訳はソリューションアーキテクト赤澤が担当しました。原文はこちらです。