最新の Amazon Neptune リリースでは、グラフによって開発者の生産性を強化する多数の新機能をご用意しました。本記事では、今回発表した重要機能と、それらを使用する際のヒントをまとめ、詳しくご紹介します。
開始方法
この新しいエンジンリリースは、既存のクラスターには自動適用されません。リリースノートに記載された手順に従って、既存のクラスターのアップグレードを選択することができます。または、エンジンの最新バージョンを受信する既存のクラスターのクローンを作成できます。
Amazon Neptune クラスターが現時点で存在しない場合は、バージョン 1.0.1.0.200463.0 のデータベースを作成します。Neptune Streams は、テストする前にラボモードで有効化する必要があります。Neptune では、お客様からのフィードバックに基づいて、初期段階の機能をプレビュー版としてリリースしています。実際のユースケースで試験使用、検証することができます。そうしたプレビュー版機能は今後のリリースで製品化されるまではラボモードです。ラボモードでは、neptune_lab_mode クラスターパラメータを使用して、Neptune エンジンの実験機能を有効 (または無効) にできます。ラボモードの設定には、AWS コンソールまたは CLI を使用します。
AWS コンソール
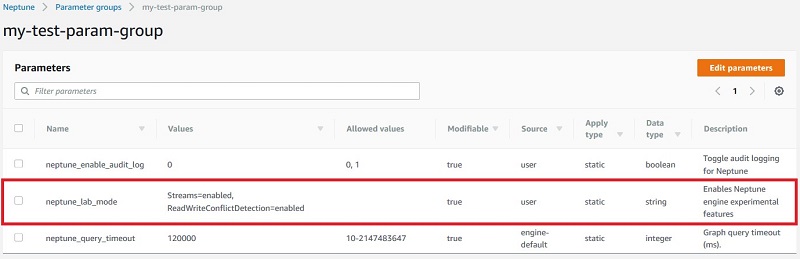
Neptune 用 AWS コンソールで、左側のナビゲーションメニューから [パラメータグループ] を選択します。Neptune クラスターに関連付けられたクラスターパラメータグループに移動し、[パラメータの編集] を選択します。 neptune_lab_mode パラメータでは、以下を追加して、ストリームおよびトランザクションのセマンティクスを有効にします。
Streams=enabled, ReadWriteConflictDetection=enabled
AWS CLI
コンソールではなく CLI を使用して、クラスターパラメータグループの値をチェックし、ラボモードのパラメータを設定することもできます。次の 2 つのコマンドをそれぞれに使用します。
aws neptune describe-db-cluster-parameters --db-cluster-parameter-group-name my-test-param-group --region us-east-1
aws neptune modify-db-cluster-parameter-group --db-cluster-parameter-group-name my-test-param-group --region us-east-1 –parameters "ParameterName=neptune_lab_mode,ParameterValue=\"Streams=enabled, ReadWriteConflictDetection=enabled\",ApplyMethod=pending-reboot"
これらの変更が正しくパラメータグループに対してなされたか確認します。
aws neptune describe-db-cluster-parameters --db-cluster-parameter-group-name my-test-param-group --region us-east-1
Output:
PARAMETERS 0,1 pending-reboot static boolean Toggle audit logging for Neptune True neptune_enable_audit_log 0 user
PARAMETERS pending-reboot static string Enables Neptune engine experimental features True neptune_lab_mode Streams=enabled, ReadWriteConflictDetection=enabled user
PARAMETERS 10-2147483647 pending-reboot static integer Graph query timeout (ms). True neptune_query_timeout 120000 engine-default
注 1: Neptune クラスターがデフォルトのクラスターパラメータグループ (通常は default.neptune1) に関連付けられている場合は、クラスターパラメータグループを新規作成して Neptune クラスターに関連付ける必要があります。
注 2: ラボモードのクラスターパラメータが変更されるたびに、クラスター内のインスタンスを再起動してからプレビュー版機能を使用する必要があります。
Neptune Streams プレビュー
Neptune Streams を使用すると、簡単にグラフの変化をキャプチャできます。プレビューで有効になると、Neptune Streams はグラフに変化が発生するたびにログを記録します。Streams は、SPARQL および Gremlin 向けとしてそれぞれ、REST API https://Neptune-DNS:8182/sparql/stream または https://Neptune-DNS:8182/gremlin/stream を介してご利用になれます。
たとえば、プロパティとして名前を持つ人物に頂点が追加された場合は、Gremlin 用の REST エンドポイントにクエリを実行するとグラフの変化の一覧が JSON 形式で返されます。SPARQL 用の同様のクエリでは、N-Quads 形式で返されます。
gremlin> g.addV('person').property('name','karthik').next()
==>v[feb6e536-a9c4-d9fd-57aa-dbb8f94328d6]
ストリームでは頂点のオペレーションを示すことがあります。ストリームのプロパティでは、以下の結果が得られます。
curl -s http://myneptune:8182/gremlin/stream?limit=3&commitNum=1&opNum=1&iteratorType=AT_SEQUENCE_NUMBER
{
"lastEventId": {
"commitNum": 1,
"opNum": 2
},
"lastTrxTimestamp": 1571059225504,
"format": "GREMLIN_JSON",
"records": [
{
"eventId": {
"commitNum": 1,
"opNum": 1
},
"data": {
"id": "feb6e536-a9c4-d9fd-57aa-dbb8f94328d6",
"type": "vl",
"key": "label",
"value": {
"value": "person",
"dataType": "String"
}
},
"op": "ADD"
},
{
"eventId": {
"commitNum": 1,
"opNum": 2
},
"data": {
"id": "feb6e536-a9c4-d9fd-57aa-dbb8f94328d6",
"type": "vp",
"key": "name",
"value": {
"value": "karthik",
"dataType": "String"
}
},
"op": "ADD"
}
],
"totalRecords": 2
}
SPARQL フェデレ―テッドクエリ
Neptune では今回、SPARQL 1.1 フェデレ―テッドクエリのサポートを開始しました。SPARQL1.1 SERVICE キーワードを使用すると、あるクエリを複数の部分に分けて Virtual Private Cloud (VPC) 内の異なる SPARQL エンドポイントで実行し、その結果をまとめてユーザーに返すことができます。
たとえば、あるクラスター内の人物データセットでサンプルクエリが “John” というファーストネームを持つ人物を取得し、2 番目のクエリが別のクラスター上で “Abercrombie” というラストネームを持つ人物を取得したとします。SPARQL 1.1 を使用してクエリをフェデレーションすると、”John” というファーストネームおよび “Abercrombie” というラストネームを持つ人物を取得できます。
以下は、neptune_cluster_1 上で実行されている RDF4J および neptune_cluster_2 に対するフェデレーションクエリのサンプルです。
> open neptune
Opened repository 'neptune'
neptune> sparql
Enter multi-line SPARQL query (terminate with line containing single '.')
SELECT ?person WHERE {
?person foaf:givenname "JOHN" .
SERVICE <http://neptune_cluster_2:8182/sparql>
{
?person foaf:surname "ABERCROMBIE" .
}
}
.
注: 複数の Neptune クラスターが同じ VPC に存在する場合は必ず、各クラスターのセキュリティグループによって Neptune クラスターが別のクラスターとポート 8182 (または設定されたポート) 経由で相互通信できるようにしてください。
Gremlin セッション
Gremlin のセッションでは、トランザクションの開始と終了が定義されます。トランザクションはセッションが終了する際にのみ、自動的にコミットされます。Neptune によって各リクエストのトランザクション境界が自動管理されるセッションレスのアプローチとはこの点で異なります。セッションを使用するには、セッションパラメータをリモート接続に渡します。下表では、同じ Neptune クラスターに接続された 2 つのクライアントの動作が示されています。ご覧のとおり、セッションからの更新はセッション終了までは目視できません。
Step |Gremlin connection 1 without Session |Gremlin connection 2 with Session
------------------------------------- -------------------------------------------------
1 |remote connect tinkerpop.server |
|conf/neptune-remote.yaml |
---------------------------------------------------------------------------------------
2 |g.addV('person').property(id, 'vertex |
|without session').next() |
|==>v[vertex without session] |
---------------------------------------------------------------------------------------
3 | |remote connect tinkerpop.server
| |conf/neptune-remote.yaml session
---------------------------------------------------------------------------------------
4 |g.V() |g.V()
|==>v[vertex without session] |==>v[vertex without session]
---------------------------------------------------------------------------------------
5 | |g.addV('person').property(id, 'vertex
| |added in session').next()
| |==>v[vertex added in session]
---------------------------------------------------------------------------------------
6 |g.V() |
|==>v[vertex without session] |
---------------------------------------------------------------------------------------
7 |g.addV('person').property(id, 'another |
|vertex without session').next() |
|==> fails due to conflicting |
|concurrent operation |
---------------------------------------------------------------------------------------
8 | |g.V()
| |==>v[vertex added in session]
| |==>v[vertex without session]
---------------------------------------------------------------------------------------
9 | |remote close
| |==> Removed - Gremlin Server
---------------------------------------------------------------------------------------
10 |g.V() |
|==>v[vertex added in session] |
|==>v[vertex without session] |
Java を使用して Neptune にアクセスしている場合は、Cluster.connect コール内のセッション名を使用して、セッションを作成します。このセッションはクライアントが終了されるまで続きます。
Cluster cluster = Cluster.open(config);
Client client = cluster.connect("mysession1"); // creates the Client.SessionedClient
...
client.submit(gremlin_query); // queries as above
...
client.close(); // session closed
Gremlin explain クエリ
Gremlin explain クエリを使用すると、クエリ実行プランを把握し、ボトルネックを検出できます。Gremlin explain クエリは、以下に示すパラメータを使用して得られたクエリによって、/gremlin/explain の REST クエリとしてご利用になれます。
curl -X POST https://myneptune:8182/gremlin/explain -d '{"gremlin":"g.E()"}'
*******************************************************
Neptune Gremlin Explain
*******************************************************
Query String
============
g.E()
Original Traversal
==================
[GraphStep(edge,[])]
Converted Traversal
===================
Neptune steps:
[
NeptuneGraphQueryStep(Edge) {
JoinGroupNode {
PatternNode[(?3, ?2, ?4, ?1) . project ?1 .IsEdgeIdFilter(?1) .]
}, annotations={path=[Edge(?1):GraphStep], maxVarId=5}
},
NeptuneTraverserConverterStep
]
Optimized Traversal
===================
Neptune steps:
[
NeptuneGraphQueryStep(Edge) {
JoinGroupNode {
PatternNode[(?3, ?2, ?4, ?1) . project ?1 .IsEdgeIdFilter(?1) .], {estimatedCardinality=INFINITY}
}, annotations={path=[Edge(?1):GraphStep], maxVarId=5}
},
NeptuneTraverserConverterStep
]
Predicates
==========
# of predicates: 1
まとめ
駆け足でしたが、Neptune の最新リリース (1.0.1.0.200463.0) の機能をご紹介しました。ぜひテストクラスターをスピンアップして、最新リリースの機能を試験使用してみてください。各機能の詳細については、ドキュメントをご覧ください。本ブログ記事でご紹介した機能の多くについては、さらに踏み込んでご説明する記事を近日中に掲載する予定です。ご期待ください。
皆さまからのご意見をお待ちしております。下のボタンから送信していただくか、またはサポートフォーラムにお寄せください。
著者について

Karthik Bharathy は Amazon Neptune 向け製品を主導しています。