今日からは、PyTorch の深層学習モデルのトレーニングとデプロイを Amazon SageMaker で簡単に行うことができます。PyTorch は、TensorFlow、Apache MXNet、Chainer に加え、Amazon SageMaker がサポートすることになった 4 番目の深層学習フレームワークです。 他のフレームワークとまったく同様、普段通りに PyTorch スクリプトを記述し、Amazon SageMaker のトレーニングに分散型トレーニングのクラスター設定、データ転送、さらにはハイパーパラメータのチューニングまで処理を任せることが可能になりました。推論の点では、Amazon SageMaker は、マネージド型で可用性が高く、また必要に応じて自動的にスケールアップ可能なオンラインのエンドポイントを提供します。
PyTorch に加え、最新の TensorFlow 安定版 (1.7 and 1.8) も追加しており、これらバージョンの新機能である tf.custom_gradient や、既成の BoostedTree 推定関数などを今日から活用していくことが可能です。Amazon SageMaker の TensorFlow 推定関数は、最新バージョンを使うようデフォルトで設定されているため、ユーザーはコードを更新する必要すらありません。
それぞれの深層学習フレームワークが得意とする分野は異なるため、開発者にとっては多くの深層学習フレームワークをサポートしていることが重要です。PyTorch は深層学習の研究者がよく使用するフレームワークですが、その柔軟性と使いやすさから開発者の間でも急速に普及してきています。TensorFlow は定評があり、リリースごとに素晴らしい機能を追加し続けています。私たちはこれらのエンジンのほか、MXNet や Chainer のような定評ある他のエンジンの開発も継続していきます。
Amazon SageMaker における PyTorch
PyTorch フレームワークは独特です。Pytorch が TensorFlow、MXNet、Caffe など他のフレームワークと異なるのは、リバースモード自動微分という技術を使用しているためで、これにより動的にニューラルネットワークを構築できます。また、Python とも密に統合されており、一般的な Python の制御フローを自身のネットワーク内で使用することや、Cython、Numba、NumPy などを使用して新しいネットワーク層を作ることが可能です。そして最後に、PyTorch は高速であり、MKL、CuDNN、NCCL のようなアクセラレーションをサポートしています。先日、DAWNBench Competition において優勝した研究チームは、PyTorch を使用する fast.ai で勝利を収めました。
Amazon SageMaker で PyTorch を使用するのは、他のビルド済み深層学習コンテナの使用と同程度に簡単です。トレーニングまたはホスティングのスクリプト (いくつかのヘルパー関数でラップされた一般的な PyTorch で構成) を準備して、Amazon SageMaker Python SDK で以下のような PyTorch 推定関数を使用するだけです。
estimator = PyTorch(entry_point="pytorch_script.py",
role=role,
train_instance_count=2,
train_instance_type='ml.p2.xlarge',
hyperparameters={'epochs': 10,
'lr': 0.01})
詳細については、ぜひ、こちらのサンプルのノートブックや文書を参照したり、下記の例に従って一緒に進めてみたりしてください。
PyTorch を使用したニューラルネットワークのトレーニングとデプロイ
ここで扱うサンプルでは、MNIST 手書き数字データセットに簡単な畳み込みニューラルネットワークを適合させていきます。このデータセットは、10 クラス (1 桁ずつ 0 から 9 まで) の 28×28 ピクセルのグレースケール画像が貼られた 70,000 件のデータ (トレーニング用 60,000 件、テスト用 10,000 件) で構成されています。Amazon SageMaker の PyTorch コンテナはスクリプトモードを使用しますが、フォーマットの入力スクリプトは SageMaker の外で通常実行するものと類似しているはずです。では、そのコードから見ていきましょう。ファイル全体としては、PyTorch が所有する MNIST のサンプルをベースに、分散型トレーニングを追加しています。ここでは最も重要な箇所だけを取り上げていきます。
エントリポイントのスクリプト
最初は ガード条件となる main で始め、ハイパーパラメータ内で読み込み用にパーサを使用します。これは、トレーニングジョブの作成時に Amazon SageMaker の推定関数に渡します。ハイパーパラメータは、トレーニングコンテナ内で入力スクリプトに対する引数として使用できるように作成します。ここでは、batch size、epochs、learning rate、momentum などのハイパーパラメータがあります。SageMaker の 推定関数の呼び出しでこれらの値を定義しない場合、私たちが提供しているデフォルトの値が入ります。また、 training_env() メソッドも使用します。これはカスタムの sagemaker_containers ライブラリから使用するもので、トレーニングとモデルのディレクトリおよびインスタンスの設定など、コンテナの詳細を提供します。また、特定の環境変数を介して、これらにアクセスすることも可能です。詳細については、SageMaker Containers GitHub repository で確認してください。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# Data and model checkpoints directories
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=100, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--backend', type=str, default=None,
help='backend for distributed training (tcp, gloo on cpu and gloo, nccl on gpu)')
# Container environment
env = sagemaker_containers.training_env()
parser.add_argument('--hosts', type=list, default=env.hosts)
parser.add_argument('--current-host', type=str, default=env.current_host)
parser.add_argument('--model-dir', type=str, default=env.model_dir)
parser.add_argument('--data-dir', type=str,
default=env.channel_input_dirs['training'])
parser.add_argument('--num-gpus', type=int, default=env.num_gpus)
train(parser.parse_args())
ハイパーパラメータを定義した後、これを train() 関数に渡します。この関数も入力スクリプトで定義するものです。さらに、 train() 関数はいくつかのタスクを引き受けます。まず、リソースを適切に設定します (GPU、分散コンピューティング等)。
def train(args):
is_distributed = len(args.hosts) > 1 and args.backend is not None
logger.debug("Distributed training - {}".format(is_distributed))
use_cuda = args.num_gpus > 0
logger.debug("Number of gpus available - {}".format(args.num_gpus))
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
device = torch.device("cuda" if use_cuda else "cpu")
if is_distributed:
# Initialize the distributed environment.
world_size = len(args.hosts)
os.environ['WORLD_SIZE'] = str(world_size)
host_rank = args.hosts.index(args.current_host)
dist.init_process_group(backend=args.backend,
rank=host_rank,
world_size=world_size)
logger.info(
'Init distributed env: \'{}\' backend on {} nodes. '.format(args.backend,
dist.get_world_size()) + \
'Current host rank is {}. Number of gpus: {}'.format(
dist.get_rank(), args.num_gpus))
# set the seed for generating random numbers
torch.manual_seed(args.seed)
if use_cuda:
torch.cuda.manual_seed(args.seed)
...
それから、データセットをロードします。
...
train_loader = _get_train_data_loader(args.batch_size,
args.data_dir,
is_distributed,
**kwargs)
test_loader = _get_test_data_loader(args.test_batch_size,
args.data_dir,
**kwargs)
...
そして、ネットワーク、モデル、オプティマイザを開始します。
...
model = Net().to(device)
if is_distributed and use_cuda:
# multi-machine multi-gpu case
model = torch.nn.parallel.DistributedDataParallel(model)
else:
# single-machine multi-gpu case or single-machine or multi-machine cpu case
model = torch.nn.DataParallel(model)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
...
次に、エポックを回してネットワークをトレーニングします。ここでは、ミニバッチでループを回し、誤差逆伝播法を使用してモデルの負の対数尤度損失を最小化し、ミニバッチ 100 件ごとにトレーニングの損失を評価した後、各エポックの最後でテストの損失を評価します。
...
for epoch in range(1, args.epochs + 1):
model.train()
for batch_idx, (data, target) in enumerate(train_loader, 1):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
if is_distributed and not use_cuda:
# average gradients manually for multi-machine cpu case only
_average_gradients(model)
optimizer.step()
if batch_idx % args.log_interval == 0:
logger.info('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.sampler),
100. * batch_idx / len(train_loader), loss.item()))
test(model, test_loader, device)
...
そして最後に、モデルを保存します。
...
save_model(model, args.model_dir)
多くのヘルパー関数とクラスを train() の中で使用しました。これには _get_train_data_loader() と _get_test_data_loader() が含まれています。この関数は、MNIST データのシャッフルされたミニバッチを読み取り、28×28 のメトリクスを PyTorch テンソルに変換し、ピクセルの値を正規化します。
def _get_train_data_loader(batch_size, training_dir, is_distributed, **kwargs):
logger.info("Get train data loader")
dataset = datasets.MNIST(training_dir,
train=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))]))
if is_distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset)
else:
train_sampler = None
return torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=train_sampler is None,
sampler=train_sampler,
**kwargs)
def _get_test_data_loader(test_batch_size, training_dir, **kwargs):
logger.info("Get test data loader")
dataset = datasets.MNIST(training_dir,
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))]))
return torch.utils.data.DataLoader(dataset,
batch_size=test_batch_size,
shuffle=True,
**kwargs)
また、ネットワークアーキテクチャとネットワークを通過する転送設定の意味を定義する Net クラスもあります。 このケースでは、Net クラスは畳み込み層と最大プーリング層の 2 つと正規化線形関数 (ReLU) のアクティベーションで、dropout が混在する完全に接続された 2 層が続きます。
class Net(nn.Module):
def __init__(self):
logger.info("Create neural network module")
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
勾配を平均するために、分散された CPU インスタンスでのトレーニング中にのみ使用される別の関数もあります。
def _average_gradients(model):
# Gradient averaging.
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM, group=0)
param.grad.data /= size
また、 test() 関数は、提供されたデータセットの正確さを報告するよう設計されています。
def test(model, test_loader, device):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
logger.info('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
最後に、 save_model() 関数で、組み込みの PyTorch の機能を利用し、モデルのパラメータをシリアライズします。
def save_model(model, model_dir):
logger.info("Saving the model.")
path = os.path.join(model_dir, 'model.pth')
torch.save(model.cpu().state_dict(), path)
Amazon SageMaker ノートブック – 設定
さて、PyTorch スクリプトの記述が終わったところで、Amazon SageMaker のビルト済み PyTorch コンテナを使用してこれを実行する Jupyter ノートブックが作成可能になりました。 ぜひ、このノートブックを実行することで、インタラクティブに流れを理解してください。
まず、データとモデルの産物を保管する Amazon S3 バケットと、データと Amazon SageMaker へのアクセスを許可する IAM ロールを設定することから始めます。
import sagemaker
bucket = sagemaker.Session().default_bucket()
prefix = 'sagemaker/DEMO-pytorch-mnist'
role = sagemaker.get_execution_role()
では、必要な Python のライブラリをインポートし、Amazon SageMaker セッションを作成していきます。
import os
import boto3
import sagemaker
from sagemaker.pytorch import PyTorch
sagemaker_session = sagemaker.Session()
次に、データセットをダウンロードし、Amazon S3 にアップロードします。
from torchvision import datasets, transforms
datasets.MNIST('data',
download=True,
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))]))
inputs = sagemaker_session.upload_data(path='data',
bucket=bucket,
key_prefix=prefix)
Amazon SageMaker ノートブック – トレーニング
これで、トレーニングデータと PyTorch スクリプトの準備が終わりましたので (スクリプトの名前を mnist.py とします)、 PyTorch のクラス (SageMaker Python SDK 内) により、Amazon SageMaker の分散型マネージドトレーニングインフラストラクチャで、トレーニングジョブとしてスクリプトを実行できるようになります。 また、IAM ロール、トレーニングクラスター設定、ハイパーパラメータの検索、およびスクリプトにあるデフォルト値とは別に設定したい値の検索に、推定関数を渡します。
このハイパーパラメータの 1 つが “backend” であることに留意してください。 PyTorch には多くの分散型トレーニング用のバックエンドがあります。 SageMaker の PyTorch コンテナは、CPU インスタンス用に TCP と Gloo を、また、GPU トレーニング用に Gloo + NCCL をサポートしています。 複数の GPU インスタンスでトレーニングしているので、ここでは “gloo” を指定します。
estimator = PyTorch(entry_point='mnist.py',
role=role,
train_instance_count=2,
train_instance_type='ml.p2.xlarge',
hyperparameters={'epochs': 5,
'lr': 0.02,
'backend': 'gloo'})
そして、 PyTorch 推定関数を構築した後、Amazon S3 にアップロードしたデータ内を通すことで、これを適合させることができます。Amazon SageMaker で、確実にデータがトレーニングクラスターのローカルファイルシステムで使用可能になりますので、PyTorch スクリプトは単純にディスクからデータを読み出せます。
estimator.fit({'training': inputs})
Amazon SageMaker ノートブック – デプロイ
トレーニングの後、 PyTorch 推定関数を使用して PyTorchPredictor をデプロイできます。これは、SageMaker エンドポイント、つまり、推論を行うのに使用可能なホストされている予測サービスを作成します。
デプロイするには、 mnist.py スクリプトはいくつかの異なる関数を必要とします。そのスクリプトを戻って、まず必要なのは model_fn() で、この関数は、そこから予測を行うために save_model() の出力をロードします。
def model_fn(model_dir):
logger.info('model_fn')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.nn.DataParallel(Net())
with open(os.path.join(model_dir, 'model.pth'), 'rb') as f:
model.load_state_dict(torch.load(f))
return model.to(device)
model_fn() は、 mnist.py スクリプトで実際に指定する必要がある唯一の関数です。他の関数のデフォルトバージョン (input_fn()、 predict_fn()、および output_fn()) は現在のユースケースに適用できるので、これらの定義は不要です。完全な状態にするために、デフォルトを簡単に紹介します。 input_fn() は、入力ペイロードを PyTorch テンソルに変換します。
def input_fn(input_data, content_type):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
np_array = encoders.decode(input_data, content_type)
tensor = torch.FloatTensor(np_array) if content_type in content_types.UTF8_TYPES else torch.from_numpy(np_array)
return tensor.to(device)
predict_fn() は、 input_fn() の戻り値をベースにしたモデルから予測を生成します。
def predict_fn(data, model):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
input_data = data.to(device)
model.eval()
with torch.no_grad():
output = model(input_data)
return output
output_fn() は、 predict_fn() から出力をシリアル化し、SageMaker エンドポイントから返されるようにします。
def output_fn(prediction, accept):
if type(prediction) == torch.Tensor:
prediction = prediction.detach().cpu().numpy()
return worker.Response(encoders.encode(prediction, accept), accept)
デフォルト実装に関する詳細は、SageMaker PyTorch container GitHub repository を参照してください。
この deploy() 関数への引数により、エンドポイントで使用するインスタンスの数とタイプを設定できます。これらの設定は、トレーニングジョブで使用した値と同じである必要はありません。たとえば、GPU ベースのインスタンス一式でモデルのトレーニングを行い、それから、エンドポイントを CPU ベースの全インスタンスにデプロイすることが可能です。ただし、その場合は、必ずモデルを mnist.py で示される CPU として戻すか、または保存しなければいけません。ここでは、モデルを単一の ml.m4.xlarge インスタンスにデプロイします。
predictor = estimator.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
Amazon SageMaker ノートブック – 予測と評価
今度は、予測関数を使用して手書き数字を分類してみます。イメージボックスに描画すると、ピクセルデータがノートブックの data 引数にロードされ、この引数を predictor に渡すことができます。 このセルには、この input.html ファイルが必要です。
from IPython.display import HTML
HTML(open("input.html").read())
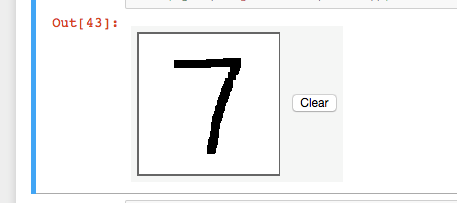
import numpy as np
image = np.array([data], dtype=np.float32)
response = predictor.predict(image)
prediction = response.argmax(axis=1)[0]
print(prediction)

この手書き数字の予測は、正確です。
Amazon SageMaker ノートブック – クリーンアップ
このサンプルが終了したら、関連するインスタンスをリリースするため、忘れずに予測エンドポイントを消去します。
estimator.delete_endpoint()
まとめ
このブログ投稿では、Amazon SageMaker にビルト済みの PyTorch コンテナを使って画像の深層学習モデルを構築する方法を紹介していますが、これはほんの手始めに過ぎません。 PyTorch を使うと途方もない柔軟性が手に入りますし、また、Amazon SageMaker は他にも CIFAR-10 での画像分類や再起型ニューラルネットワークを利用するセンチメント分析向けにサンプルのノートブックを提供しています。 また、最新バージョンのテストに使用可能な TensorFlow のサンプルのノートブックもあります。 ぜひ、自身のユースケースで実際に試してみましょう。
今回のブログ投稿者について
 David Arpin は AWS の AI Platforms Selection Leader で、データサイエンスチームと製品管理を統率してきた経歴があります。
David Arpin は AWS の AI Platforms Selection Leader で、データサイエンスチームと製品管理を統率してきた経歴があります。
 Nadia Yakimakha は AWS のソフトウェア開発エンジニアで、SageMaker で機械学習フレームワークに携わっています。
Nadia Yakimakha は AWS のソフトウェア開発エンジニアで、SageMaker で機械学習フレームワークに携わっています。