Amazon Web Services ブログ
Amazon SageMaker Object2Vec が、自動ネガティブサンプリングをサポートし、トレーニングをスピードアップする新機能を追加
本日は、Amazon SageMaker Object2Vec の 4 つの新機能を紹介いたします。ネガティブサンプリング、スパース勾配更新、重み共有、比較演算子のカスタマイズです。Amazon SageMaker Object2Vec は、汎用のニューラル埋め込みアルゴリズムです。Object2Vec についてまだ良く知らない場合は、ブログ記事 Amazon SageMaker Object2Vec の概要を参照してください。この記事は、この新機能 (Object2Vec を使用して、ドキュメント埋め込みを学習する) の一部として追加された 4 つのノートブックの例へのリンクを使用して、アルゴリズムの概要を説明します。また、技術的な詳細を提供するドキュメンテーションページ Object2Vec アルゴリズムへのリンクも提供します。これらの新機能には、Amazon SageMaker コンソールからアルゴリズムのハイパーパラメータとして、そして高レベルの Amazon SageMaker Python API を使用して、アクセスすることができます。
このブログ記事では、以下の新機能のそれぞれについて説明し、それがどのように顧客の問題点をターゲットにしているかを示します。
- ネガティブサンプリング: 以前は、ポジティブにラベル付けされたデータだけが使用可能であるユースケース (この記事の後半で説明しているドキュメント埋め込みのユースケースなど) では、データ前処理の一部として手動でネガティブサンプリングを実装する必要がありました。新しいネガティブサンプリング機能により、Object2Vec は観測される可能性が低いデータを自動的にサンプリングし、トレーニング中にこのデータをネガティブとラベル付けします。
- スパース勾配更新: 以前は、アルゴリズムのトレーニング速度はマルチ GPU に対応して拡張することができず、入力語彙サイズが大きくなるにつれて遅くなりました。これは、デフォルトでは、勾配のほとんどの行がゼロ値であっても MXNet オプティマイザがフル勾配を計算するためです。そのため、不要な計算が行われるだけでなく、マルチ GPU 設定での通信コストも増加します。スパース勾配更新を使用する Object2Vec は、パフォーマンスを低下させることなくシングル GPU トレーニングを高速化します。さらに、トレーニング速度はマルチ GPU でさらに向上させることができ、現在は語彙サイズとも無関係になっています。
- 重み共有: Object2Vec には、2 つの入力ソースからのデータをエンコードするために、それぞれ独自のトークン埋め込みレイヤーを持つ 2 つのエンコーダーがあります。両方のソースが同じトークンレベルのユニットの上に構築されているユースケースでは、トークン埋め込みレイヤーを共同でトレーニングすることは一般的なやり方です (深層学習コミュニティでは、重み共有と呼んでいます)。新しい重み共有機能により、このオプションが提供されます。
- 比較演算子のカスタマイズ: Object2Vec ネットワークアーキテクチャの比較演算子は、2 つのエンコーダーによって生成された符号化ベクトルを 1 つにまとめます。以前は、この演算子が固定されていたため、一部のユースケースではアルゴリズムのパフォーマンスを低下させる可能性がありました (ドキュメント埋め込みについて観察したように。表 1 を参照)。新しい comparator_list パラメーターは、比較演算子を特定のユースケースに合わせてカスタマイズする柔軟性を提供します。
このブログ記事に、ドキュメント埋め込みユースケースのすべての新機能を活用する方法を示す新しいノートブックの例 (Object2Vec を使用して、ドキュメント埋め込みを学習する) が付随しています。このユースケースでは、顧客には大量のドキュメントがあります。こうしたドキュメントをそのままの形式で、あるいはスパースな「 bag-of-words 」ベクトルとして保存するのではなく、すべてのドキュメントを共通の低次元空間に埋め込むことで、これらのドキュメント間の意味的な距離が保たれるようにします。このようにドキュメントを埋め込むことは、効率的な最近傍検索のようないくつかの有用な用途があり、また局所分類のような下流タスクにおける特徴もあります。
ネガティブサンプリング機能
単語の埋め込みで広く使用されている Word2Vec アルゴリズムと同様に、ドキュメントを埋め込むための自然な方法は、文とその文脈が同じドキュメントに由来するようにドキュメントを (文、文脈) のペアとして前処理することであり、文脈は与えられた文を取り除いた文書全体になります。このアイデアは、文章とその文脈の両方を低次元空間に埋め込むようにエンコーダーをトレーニングすることであり、それらは同じドキュメントに属し、したがって意味的に関連しているはずなので、それらの相互類似性が最大になります。 コンテキストを学習したエンコーダーは、新しいドキュメントを同じ埋め込みスペースにエンコードするために使うことができます。 文章とドキュメントについてエンコーダーをトレーニングするには、モデルが意味的に類似したペアと異なるペアを区別することを学習できるように、ネガティブ (文章、文脈) ペアも必要です。文章をそれが属していないとドキュメントを組み合わせることで、このようなネガティブな要素を簡単に生成できます。自然に発生するデータにはポジティブペアよりもネガティブペアが多くあるため、通常は、ランダムサンプリング手法を使用して、トレーニングデータのポジティブペアとネガティブペアのバランスをとります。次の図は、ドキュメント (および文章) の埋め込みを学習する目的で、ラベルなしデータからポジティブペアとネガティブペアを生成する方法を示しています。
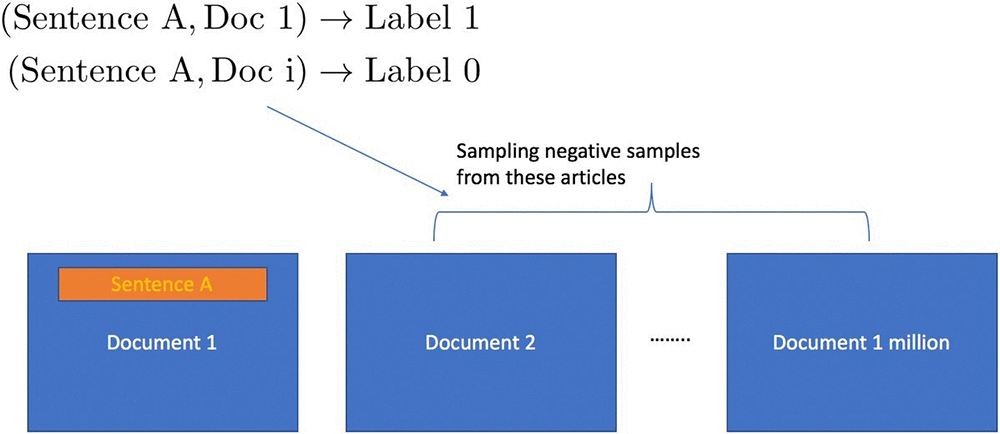
通常は、アルゴリズムをトレーニングする前に、前処理ステップとしてネガティブペアの作成とサンプリングを行う必要があります。Object2Vec の新しい negative_sampling_rate ハイパーパラメータを使用すると、ユーザーはポジティブにラベル付けされたデータペアを入力するだけでよく、アルゴリズムがトレーニング中に自動的にネガティブデータを生成してサンプリングします。ネガティブサンプリングレートの値は、ユーザが望むポジティブな例に対するネガティブな例の比を表します。
ノートブックでは、negative_sampling_rate ハイパーパラメータを 3 に設定します。
ノートブックを実行すると、トレーニングコンソールの出力から、ネガティブサンプリングが有効になっていること、およびサンプリングレートが実際に 3 であることを確認できます。
![]()
一般に、最良の negative_sampling_rate を決定するには、異なる値を試し、検証セットに対して最良のメトリクス (例えば分類のためのクロスエントロピー) を示すものを選択する必要があります。
スパース勾配更新
新しいスパース勾配更新のサポートは、Object2Vec のスパース入力形式を利用し、ミニバッチ勾配降下トレーニングを 2〜20 倍高速化します。vocab_size が大きいほど、さらに高速化が見られます。
ノートブックの例では、token_embedding_storage_type を設定してスパース勾配更新をオンにしました。
トレーニングコンソール出力のパラメーター要約テーブルを見ることによって、スパース勾配が本当に有効になっていることを確認できます。
![]()
次のテーブルは、Amazon EC2 P2 インスタンスでスパース勾配更新機能をオンにした場合の GPU 数の関数としてのトレーニングスピードを示しています (p2 インスタンスの詳細については、ここを参照してください)。スパース勾配更新を使用するもう 1 つの利点は、フル勾配更新とは対照的に、語彙サイズを大きくしてもトレーニング速度が影響を受けないことです。
スパース勾配更新による速度の向上
| num_gpus | 密な埋め込みによるスループット (サンプル/秒) | 疎な埋め込みによるスループット | max_seq_len (in0/in1) | X 倍の速度向上 | |
| 1 | 1 | 5k | 14k | 50 | 2.8 |
| 2 | 2 | 2.7k | 23k | 50 | 8.5 |
| 3 | 3 | 2k | 24k | 50 | 10 |
| 4 | 4 | 2k | 23k | 50 | 10 |
| 5 | 8 | 1.1k | 19k | 50 | 20 |
| 6 | |||||
| 7 | 1 | 1.1k | 2k | 500 | 2 |
| 8 | 2 | 1.5k | 3.6k | 500 | 2.4 |
| 9 | 4 | 1.6k | 6k | 500 | 3.75 |
| 10 | 6 | 1.3k | 6.7k | 500 | 5.15 |
| 11 | 8 | 1.1k | 5.6k | 500 | 5 |
埋め込みレイヤーの重み共有
Object2Vec には 2 つのエンコーダーがあります。トレーニング中、以前は、アルゴリズムは各エンコーダーに対して別々に入力埋め込みを学習しました。新しい tied_token_embedding_weight ハイパーパラメーターは、両方のエンコーダでトークン埋め込みレイヤーを共有できる柔軟性を提供します。ドキュメント埋め込みユースケースでは、重み共有によるドキュメント埋め込みユースケースの方がパフォーマンスが向上しています。
ノートブックでは、tied_token_embedding_weight ハイパーパラメータを True に設定します。
トレーニングコンソールの出力を見て、重み共有機能がオンになっていることを確認できます。
![]()
比較演算子のカスタマイズ
Object2Vec アーキテクチャの比較演算子は、2 つのエンコーダーからの出力を集約します。以前は、比較演算子は固定されていました。新しい comparator_list ハイパーパラメーターを使用すると、ユーザーは自分のアプリケーションに最適なパフォーマンスに向けてアルゴリズムを調整できるように、独自の比較演算子をカスタマイズすることができます。利用可能な二項演算子は、「hadamard」 (要素ごとの積)、 「concat」 (連結)、「abs_dipp」 (絶対差) です。3 つを組み合わせて使用することもできますし、単にそのうちの 1 つをそのまま使用することもできます。
ノートブックでは、要素ごとの積だけを使用するように比較演算子をカスタマイズします。
トレーニングコンソールの出力を見て、比較演算子の設定を確認することができます。
![]()
デフォルトの比較演算子は、3 つの演算子すべての結果を連結します。hadamard と abs_di の演算子を組み合わせたい場合は、単に次のように書く必要があります。
異なる問題については、ユーザーがデフォルトを使用するか、検証セットを使用して (または相互検証を使用して) 最適な組み合わせを見つけることをお勧めします。
ドキュメント埋め込みと検索下流タスクに関する実験
ドキュメント埋め込みノートブックでは、前述のようにラベルなしのウィキペディアの記事から作成されたトレーニングデータについて、文章とドキュメントの両方に対する単純なプール埋め込みベースのエンコーダーを使用して Object2Vec モデルをトレーニングします。バイナリラベル付きデータがあるので、トレーニング誤差として標準のクロスエントロピー関数を使用します。同じ誤差関数を使用するか、バイナリラベル付きテストデータの精度を使用して、モデルのパフォーマンスを評価することができます。次のテーブルは、同じデータ作成プロセスから得られたテストセットで評価されたこれら 2 つのメトリクスに対するこれらの機能の影響を示しています。
ネガティブサンプリングと埋め込みレイヤーの重み共有がオンになっているとき、およびカスタマイズされた比較演算子 (アダマール積) を使用しているとき、モデルのテスト精度が向上していることがわかります。これらの機能のすべてが組み合わされると (テーブルの最後の行)、精度とクロスエントロピーによって測定されるように、アルゴリズムは最高のパフォーマンスを示します。
Wikipedia250k データでの新機能の組み合わせによるテスト性能
|
negative_sampling_rate |
重み共有 |
比較演算子 | テストの精度 (高いほど良い) | テストのエントロピー (低いほど良い) | |
|
1 |
Off |
Off |
デフォルト (アダマール、連結、abs_diff) |
0.167 |
23 |
| 2 | 3 | Off | デフォルト | 0.92 | 0.21 |
| 3 | 5 | Off | デフォルト | 0.92 | 0.19 |
| 4 | Off | On | デフォルト | 0.167 | 23 |
| 5 | 3 | On | デフォルト | 0.93 | 0.18 |
| 6 | 5 | On | デフォルト | 0.936 | 0.17 |
| 7 | Off | On | カスタマイズ (アダマール) | 0.17 | 23 |
| 8 | 3 | On | カスタマイズ | 0.93 | 0.18 |
| 9 | 5 | On | カスタマイズ | 0.94 | 0.17 |
モデルをトレーニングした後、Object2Vec のエンコーダーを使用して、新しい記事や文章を共有埋め込みスペースにマッピングすることができます。次に、これらの埋め込みの品質を下流のドキュメント検索タスクで評価します。
検索タスクでは、文章のクエリが与えられた場合、トレーニングされたアルゴリズムは、そのプールに 10,000 件のグラウンドトルースでないドキュメントが含まれるドキュメントのプールから最も一致するドキュメント (グラウンドトゥルースドキュメントはそれを含むもの) を見つける必要があります。2 つのメトリクス hits@k と平均ランクを使用して、検索パフォーマンスを評価します。プール内のグラウンドトルースのドキュメントからはクエリの文章が削除されているため、そうでなければタスクは簡単になることに注意してください。
- hits@k: 最も一致する (グラウンドトルースの) ドキュメントが、アルゴリズムによって検索されたドキュメントの上位 k のドキュメントに含まれるクエリの一部を計算します。
- 平均ランク: アルゴリズムによって決定された、すべてのクエリに対して最も一致したドキュメントの平均ランクです。
250,000 のウィキペディアのドキュメントを使って、Object2Vec と StarSpace アルゴリズムの性能をドキュメント検索評価タスクで比較しました。次のテーブルの実験結果は、どちらのモデルも文章とドキュメントに同じ種類のエンコーダーを使用していますが、Object2Vec がすべてのメトリクスで StarSpace よりも大きく優れていることを示しています。
ドキュメント検索評価
| アルゴリズム | hits@1 | hits@10 | hits@20 | 平均ランク (小さいほど良い) | |
| 1 | StarSpace | 21.98% | 42.77% | 50.55% | 303.34 |
| 2 | Object2Vec | 26.40% | 47.42% | 53.83% | 248.67 |
著者について
 Cheng Tang は、AWS AI の業種およびアプリケーショングループのアプライドサイエンティストです。機械学習の研究とその自然言語処理分野への応用に幅広く興味を持っている、Cheng は機械学習/深層学習アルゴリズムの研究と産業化の両方に貢献することに大きな魅力を感じており、それらが顧客に届くのを見て非常に喜んでいます。
Cheng Tang は、AWS AI の業種およびアプリケーショングループのアプライドサイエンティストです。機械学習の研究とその自然言語処理分野への応用に幅広く興味を持っている、Cheng は機械学習/深層学習アルゴリズムの研究と産業化の両方に貢献することに大きな魅力を感じており、それらが顧客に届くのを見て非常に喜んでいます。
 Patrick Ng は、AWS AI の業種およびアプリケーショングループのソフトウェア開発エンジニアです。ディープニューラルネットワークと自然言語処理の分野を中心に、スケーラブルな分散機会学習アルゴリズムの構築に取り組んでいます。 Amazon に来る前は、コーネル大学でコンピュータサイエンスの博士号を取得し、機械学習システムを構築するスタートアップ企業にいました。
Patrick Ng は、AWS AI の業種およびアプリケーショングループのソフトウェア開発エンジニアです。ディープニューラルネットワークと自然言語処理の分野を中心に、スケーラブルな分散機会学習アルゴリズムの構築に取り組んでいます。 Amazon に来る前は、コーネル大学でコンピュータサイエンスの博士号を取得し、機械学習システムを構築するスタートアップ企業にいました。
 Ramesh Nallapati は、AWS AI の業種およびアプリケーショングループの主席アプライドサイエンティストです。主に自然言語処理の分野で、大規模な新しいディープニューラルネットワークの構築に取り組んでいます。深層学習に情熱を注いでおり、AI の最新動向を楽しく学んでいます。また、この分野で貢献できることに興奮しています。
Ramesh Nallapati は、AWS AI の業種およびアプリケーショングループの主席アプライドサイエンティストです。主に自然言語処理の分野で、大規模な新しいディープニューラルネットワークの構築に取り組んでいます。深層学習に情熱を注いでおり、AI の最新動向を楽しく学んでいます。また、この分野で貢献できることに興奮しています。
 Bing Xiang は、AWS AI の業種およびアプリケーショングループのプリンシパルサイエンティスト兼責任者です。彼は、さまざまな AWS のサービスのために深層学習、機械学習、自然言語処理に取り組んでいるサイエンティストおよびエンジニアのチームを率いています。
Bing Xiang は、AWS AI の業種およびアプリケーショングループのプリンシパルサイエンティスト兼責任者です。彼は、さまざまな AWS のサービスのために深層学習、機械学習、自然言語処理に取り組んでいるサイエンティストおよびエンジニアのチームを率いています。
謝辞
多大な協力と有益な議論をしていただいた、上級主席エンジニアの Leo Dirac に感謝いたします。