Amazon Web Services ブログ
AWS RoboMaker を使用した強化学習の紹介
ロボット工学には、しばしば複雑な連続動作のトレーニングが含まれることがあります。たとえば、別のオブジェクトをフォローまたは追跡するように設計されたロボットについて考えてみましょう。目標については簡単に説明できますが (ロボットがオブジェクトに近いほど良いです)、タスクを達成するためのロジックを作成することははるかに難しいです。強化学習 (RL)、新しい機械学習技術は、まさにこのような問題のソリューションを開発する際に役立ちます。
この記事では RL を紹介するとともに、私たちが AWS RoboMaker を使用して TurtleBot Waffle Pi がTurtleBot Burgerを追跡するアプリケーションをどのように作成し、トレーニングした方法について説明しています。AWS RoboMaker のサンプルアプリケーション、オブジェクトトラッカーは、Intel Reinforcement Learning Coach と OpenAI の Gym ライブラリを使用します。Coach ライブラリは RL フレームワークを簡単に利用できるPython で書かれたライブラリです。TurtleBot が自律走行に使うモデルのトレーニングに使用されました。OpenAI の Gym は、自律判断を行う RL エージェントを開発および設計するために使用されたツールキットです。
サンプルオブジェクトトラッカーのアプリケーションを使用したい場合は、「強化学習を使用してロボットをトレーニングする方法」を参照してください。
RL の概要
RL では、トレーニングのコンポーネントが 2 つあります。
- ロボットが行うべきアクションを判断するエージェント
- ロボットの次の状態を判断するために、ロボットの力学および物理学とアクションを組み合わせた環境
簡潔に言えば、エージェントはモデルを使用してアクションを決定します。ロボットの現在の状態では、モデルは可能なアクションをマッピングして、各アクションがどれだけ優れているかを推測します (強化学習では、報酬といいます)。最初、モデルはどのアクションが最適なのか分からないため、通常、間違った推測を行います。エージェントが、受け取る可能性がある潜在的報酬を最大化することを学ぶと、モデルは改善され、改善されるアクションを推測します。次の図は、仕組みについて説明しています。
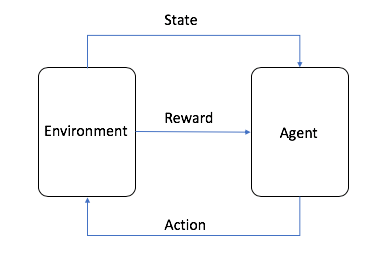
サンプルオブジェクトトラッカーのアプリケーションでは、RL は次のように機能します。
- ロボットがある開始位置にあるとき、エージェントはとるべき最善のアクションを推測します。
- 環境は新しい状態と報酬を計算します。報酬はエージェントに前回のアクションがどれほど良かったかを知らせます。
- エージェントと環境は相互作用して、新しいアクションを決定し、新しい状態を計算します。エージェントは、良いアクションに対する報酬と悪いアクションに対する罰を集めます。
- トレーニングが 1 回終了すると、ロボットは、全体的にどれだけうまく機能したかを表す報酬の合計を取得します。
- 多くのアクションをとることによって、エージェントはどのアクションが優れているか (より大きな報酬を得ているか) をゆっくり学び、判断するときにそれらのアクションを優先します。
AWS RoboMaker を使用した RL アプリケーションの構築
それでは、オブジェクトトラッカーのソースコードを見て、アプリケーションの実装方法を確認しましょう。読みながらコードを見ることをお勧めします。まだサンプルアプリケーションを実行していない場合は、Github リポジトリからコードをダウンロードできます。
ロボットのトレーニング
アプリケーションには、次の主要コンポーネントがあります。
- シミュレーションワークスペース – このワークスペースには、RL エージェントと環境を定義するコードが含まれています。
- ロボットワークスペース – RL モデルをトレーニングした後に、ロボットワークスペースが構築され、モデルが実際のロボットにデプロイされます。
- ロボットオペレーションシステム (ROS) – ロボットアプリケーション向けの開発フレームワーク。ROS は、ロボットのカメラやモーターと対話するための簡単なインターフェイスを提供します。
- Gazebo – ロボットの状態とアクションを取り、次の状態を計算するシミュレーター。また、Gazebo は RL エージェントに取り込まれるカメラ画像もシミュレートします。
- Intel Coach ライブラリ – TurtleBot が駆動に使用するモデルをトレーニングするために使用された Python RL フレームワーク。
- Open AI Gym – 回転、速度の制御などについて自律的な判断を下す RL エージェントを開発および設計するためのツールキット。
- TensorFlow – Google が書いた機械学習ライブラリで、エージェントが判断を下すために使用するモデルを保存およびトレーニングします。
開発環境で、simulation_ws フォルダに移動します。シミュレーションワークスペースのコードが RL モデルをトレーニングします。single_machine_training_worker.py という Python ファイルがアプリケーションのエントリポイントです。このファイルでは、MARKOV_PRESET_FILE などの環境変数がアプリケーションに渡され、実行されます。 アプリケーションは、新しい TensorFlow モデルを作成し、Amazon Simple Storage Service (Amazon S3) バケットに保存することで開始されます。Amazon S3 にすでにトレーニング済みのモデルがある場合、アプリケーションは代わりにそのモデルを使用します。そうすると、トレーニングを再開するたびに最初からやり直す必要がなくなります。その後、これらすべてのパラメータを渡してグラフマネージャーオブジェクトを作成します。グラフマネージャーはモデルのトレーニングを担当します。最終的に、グラフマネージャーオブジェクトのimproveメソッドを呼び出したときにトレーニングが始まります。
object_tracker.py ファイルには、RL 環境を構成するためのハイパーパラメータが含まれています。アプリケーションは ClippedPPO (Proximal Policy Optimization) として知られている学習戦略を使用します。PPO は、RL の優れた開始点として Open AI が推奨するアルゴリズムです。他の RL アルゴリズムより調整するパラメータは少ないですが、全体的に優れたパフォーマンスを提供します。 次のように、OpenAI Gym も、カスタムレベルの RoboMaker-ObjectTraker-v0 でこのファイルに設定されています。
TurtleBot3ObjectTrackerAndFollowerDiscreteEnv クラスには、ロボットが一連のトレーニングを完了したときに環境をリセットする方法、報酬機能、およびロボットが実行できる一連のアクションなど、RL を実行するために必要なその他の要素が含まれています。
アプリケーションが、カメラでキャプチャした画像を状態として使用していることにお気付きかもしれません。このため、最適なパフォーマンスを得るには、現実の世界を Gazebo のシミュレートされた世界とできるだけ似たようにする必要があります。たとえば、現在のシミュレートされた世界は暗灰色です。トレーニングされたモデルが物理的な TurtleBot Waffle Pi にデプロイされると、同様の環境で動作できるようになります。あなたの部屋のように現実の世界に近いシミュレーション環境でトレーニングしたい場合は、さらに詳細を追加することができます。たとえば、部屋の壁写真を撮り、それらをテクスチャとしてインポートして、現実の世界にできる限り一致させることができます。
このアプリケーションでは、Waffle Pi が移動するためにカメラを使用しています。実行するすべてのアクションに対して、実行するすべてのアクションの現在の状態としてカメラから画像を取得します。コードは TurtleBot3ObjectTrackerAndFollowerEnv クラスの infer_reward_state(self) メソッドで定義されています。
TurtleBot Waffle Pi が静止している TurtleBot Burger に到達することが目標だということを忘れないでください。TurtleBot Waffle Pi が静止している TurtleBot Burger に向かって進む正しいステップごとに、大きな報酬を受け取る必要があります。報酬の計算コードは、TurtleBot3ObjectTrackerAndFollowerEnv クラスの infer_reward_state(self) メソッドで定義されています。TurtleBot 間の現在の距離が前回の状態よりも短い場合、TurtleBot Waffle Pi が静止している TurtleBot Burger に近づいているため、報酬を取得します。TurtleBot Waffle Pi が目標に近づくほど、より大きな報酬が得られます。距離が 5 メートルより遠い場合、TurtleBot Waffle Pi が静止している TurtleBot Burger から遠すぎるところにあるため、エージェントはエピソードを終了して新しいエピソードを開始します。
エージェントがより早く、より正確にトレーニングできるように、報酬機能コードのロジックを最適化しようとすることができます。たとえば、Waffle Pi が前回の状態と比較して、静止している TurtleBot から遠くに移動した場合、負の報酬を与えてみることができます。また、静止している TurtleBot を見つけてさらに最適化するための距離を計算するために、オブジェクト検出などのコンピュータビジョン技術を使用することもできます。
ロボットが実行できるアクションは、object_tracker_env.py ファイルの最後にある TurtleBot3ObjectTrackerAndFollowerDiscreteEnv クラスで定義されています。 アクションには 0 から 4 までのラベルが付けられており、各アクションは TurtleBot に対する 1 つのステアリングおよびスロットルコマンドです。たとえば、アクションが 0 の場合、TurtleBot は毎秒 0.1 メートルの速度で左に曲がるはずです。
トレーニング済みモデルの使用
コードが TensorFlow でモデルをトレーニングすることを忘れないでください。TurtleBot Waffle Pi にデプロイするときは、Amazon S3 に保存されている TensorFlow モデルをダウンロードして、それを Waffle Pi に直接ロードできるようにする必要があります。robot_ws ワークスペースは、モデルを Waffle Pi にデプロイするために使用されます。robot_ws ワークスペースの download_model Python ファイルは、トレーニング済みモデルを Amazon S3 からダウンロードします。inference_worker Python ファイルのコードはモデルを TensorFlow セッションにロードし、カメラから供給された画像に基づいてアクション (ステアリング、スロットル) を実行するように Waffle Pi に指示します。
アプリケーションの実行
ROS は起動ファイルを使用してアプリケーションを起動します。local_training.launch ファイルには、アプリケーションの起動時に起動したいすべてのノード (プロセス) に関する詳細が含まれています。ノード要素は、起動時にシェルスクリプト run_local_rl_agent.sh を起動するように ROS ランタイムに指示します。
run_local_rl_agent.sh スクリプトで、ROS は single_machine_training_worker Python スクリプトを実行します。
roboMakerSettings.json ファイルは AWS RoboMaker 固有のものです。アプリケーションの起動に使用する AWS リソースとルールを定義します。たとえば、ROS フレームワークが実行時に起動するシミュレーション構成の launchFile パラメータに指定されたファイルなどです。
環境変数は設定ファイルで渡すことができます。たとえば、MARKOV_PRESET_FILE 環境変数は、主なアプリケーションコードが存在する場所にあります。アプリケーションはこの変数を使用して実行時にロードされます。roboMakerSettings.json ファイルの便利な機能の 1 つは、アプリケーションのシミュレーションジョブを自動的に構築し、まとめて、実行するためのワークフローを作成および設定できることです。これにより、変更が必要になったときに、手動で手順を実行する必要がなくなります。
まとめ
このブログが、サンプルオブジェクトトラッカーアプリケーションの仕組み、および RL などの複雑な機械学習技術を AWS RoboMaker で簡単に開発およびデプロイする方法を理解するのに役立つことを願っています。サンプルオブジェクトトラッカーのアプリケーションを使用したい場合は、「強化学習を使用してロボットをトレーニングする方法」を参照してください。
著者について
 Tristan Li は、アマゾン ウェブ サービスのソリューションアーキテクトです。米国内の企業顧客と連携して、AWS でスケーラブルでセキュアなソリューションを構築するためにクラウドテクノロジーを導入するお手伝いをしています。
Tristan Li は、アマゾン ウェブ サービスのソリューションアーキテクトです。米国内の企業顧客と連携して、AWS でスケーラブルでセキュアなソリューションを構築するためにクラウドテクノロジーを導入するお手伝いをしています。
 Wayne Davis は、アマゾン ウェブ サービスのエンタープライズソリューションアーキテクトです。Wayne は過去 24 か月の間、お客様が可能な限り迅速にクラウドテクノロジーについて詳しく理解できるように支援する仕事に携わっています。
Wayne Davis は、アマゾン ウェブ サービスのエンタープライズソリューションアーキテクトです。Wayne は過去 24 か月の間、お客様が可能な限り迅速にクラウドテクノロジーについて詳しく理解できるように支援する仕事に携わっています。
 Robert Meagher は、AWS RoboMaker のソフトウェア開発エンジニアです。彼は、オフィスの内外でロボット工学システムの設計と調整を楽しんでいます。
Robert Meagher は、AWS RoboMaker のソフトウェア開発エンジニアです。彼は、オフィスの内外でロボット工学システムの設計と調整を楽しんでいます。