Amazon Web Services ブログ
Amazon Comprehend と Amazon SageMaker ノートブックを使ったコンテンツの分析
今日の「つながった」世界では、企業にとってソーシャルメディアチャネルを監視し、それぞれのブランドと顧客関係を保護することが重要です。企業はソーシャルメディア、E メール、およびその他のコミュニケーションを通じてその顧客、製品、およびサービスについて理解しようとしています。機械学習 (ML) モデルは、これらのニーズに対応するために役立ちますが、独自のモデルを構築して訓練するプロセスは、複雑で時間がかかるものになり得ます。Amazon Machine Learning プラットフォームは、Jupyter ノートブックを使用して Amazon SageMaker 内でアクセスできる事前に訓練されたモデルを提供します。Amazon SageMaker は、モジュラー設計の完全マネージド型エンドツーエンド ML プラットフォームですが、この例ではホストされているノートブックインスタンスのみを使用します。Amazon Comprehend は、テキスト内のインサイトと関係性を見つけるために機械学習を使用する自然言語処理 (NLP) サービスです。
このブログ記事では、ノートブック内で Twitter センチメントを分析するために Amazon Comprehend を使用する方法を説明します。
Amazon Comprehend の仕組み
Amazon Comprehend は、ソーシャルメディアの記事、E メール、ウェブページ、ドキュメント、およびトランスクリプションなどの非構造型データを入力として使用します。次に、NLP アルゴリズムの力を使ってその入力を分析し、キーフレーズ、エンティティ、およびセンチメントを自動的に抽出します。また、入力データの言語を検知したり、トピックモデリングアルゴリズムを使用してデータの関連グループを見つけたりすることもできます。以下の図は、Amazon Comprehend のワークフローを説明したものです。
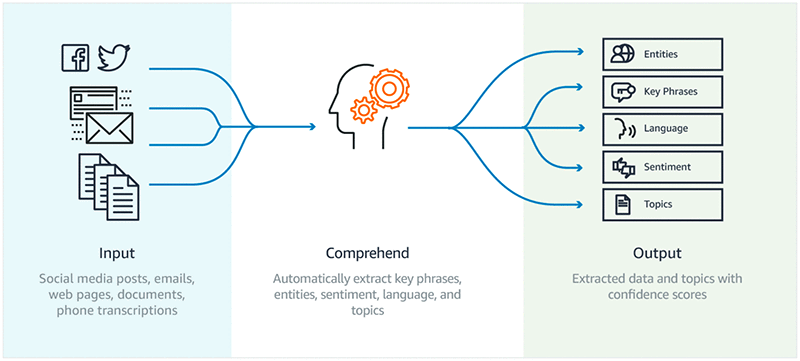
Amazon Comprehend Custom を使用すると、あらかじめ設定された汎用エンティティタイプとしてサポートされていない新しいエンティティタイプを識別する、またはビジネス固有の用語とフレーズについて顧客フィードバックを分析することができます。例えば、顧客がいつチャーン (解約) するか、またはいつ固有の製品 ID の 1 つに言及するかを学ぶことが可能です。
ステップ 1: Amazon SageMaker ノートブックをセットアップする
AWS マネジメントコンソールで [すべてのサービス] を選択してから、機械学習にある [Amazon SageMaker] を選択します。これはどの AWS リージョンからでも実行できますが、Amazon Comprehend API と Amazon SageMaker の両方が同じリージョンにあることを確実にする必要があります。AWS リージョンをメモしておいてください。この情報は Amazon Comprehend API への接続に必要になります。このブログ記事の例では、リージョンを米国東部 (バージニア北部) に設定しました。
Amazon SageMaker コンソールの [ノートブック] で、[ノートブックインスタンス] を選択します。ここで [ノートブックインスタンスの作成] を選択します。

まずノートブックインスタンスの名前を設定する必要があります。今回の例には、「comprehend-nb」を使用します。ノートブックインスタンスの名前には命名上の制約がいくつかあることに注意してください。これらの制約には、英数字最大 63 文字、ハイフンは使用可能でスペースは使用不可、およびインスタンス名が AWS リージョンのアカウント内で固有でなければならないことが含まれます。ノートブックには任意の名前を付けることができます。
デフォルトのインスタンスサイズ、そして他のデフォルト設定も、この練習には十分です。ただし、AmazonSageMakerFullAccess を使って IAM ロールを作成する必要があり、この IAM ロールには必要な Amazon Simple Storage Service (Amazon S3) バケットのすべてに対するアクセス権がなくてはなりません。コンソールの IAM ロールで、[新しいロールの作成] を選択します。
新しい IAM ロールを作成するときは、指定する S3 バケットで [特定の S3 バケット] を選択することで、このロールにアクセスさせたい Amazon S3 バケットを指定できます。[ロールの作成] を選択します。

ノートブックインスタンスの設定は、以下のようになっているはずです。

[ノートブックインスタンスの作成] を選択します。
数分後、ノートブックインスタンスの準備が完了します。ノートブックインスタンスから Amazon Comprehend にアクセスするには、IAM ロールに ComprehendFullAccess ポリシーをアタッチする必要があります。これを行うには、ノートブックインスタンスの名前を選択します。

ノートブックインスタンスの設定は、以下のスクリーンショットのようになります。[IAM ロール ARN] を選択して、ノートブックインスタンスにアタッチされた IAM ロールを開きます。

IAM ダッシュボードで [ポリシーをアタッチします] を選択します。

ポリシーは、ポリシー名を入力することでフィルタできます。ComprehendFullAccess と入力して、このポリシーがページにリストされたらチェックを入れます。[ポリシーをアタッチします] を選択します。

ポリシーが正常にアタッチされたら、安全に IAM コンソール を閉じて、Amazon SageMaker コンソールに戻ることができます。ノートブックインスタンスのステータスが InService になったら、[開く Jupyter] リンクを選択します。

ステップ 2: ノートブックを作成する
プロビジョニングしたノートブックインスタンスを開いたら、Jupyter コンソールで [New]、[conda_python3] と選択します。

これで、以下のスクリーンショットにあるような新しい空の Jupyter ノートブックが開きます。

[Untitled] を選択して Jupyter ノートブックに名前を付けてから、手順に従ってコードブロックを構築し、実行してください。その代わりに、ここにあるサンプルコードファイルを使うこともできます。このファイルは、ノートブックインスタンスにアップロードして直接実行することができます。
ステップ 3: 必要なパッケージをインポートする
この例になくてはならない必要なパッケージをインポートできます。
ステップ 4: Amazon Comprehend に接続する
AWS SDK for Python SDK (Boto3) を使って、Python コードベースから Amazon Comprehend に接続できます。以下のコマンドを使って boto3 をインポートし、boto3 クライアントを使って指定した AWS リージョン内の Amazon Comprehend に接続できます。AWS リージョンはノートブックと同じリージョンにする必要があります。例えば、今回は us-east-1 リージョンでノートブックを作成したことから、このリージョンを使用しました。
ステップ 5: Amazon Comprehend API を使ってツイートを分析する
Amazon Comprehend API を使用することで、単一のツイートを分析できます。キーフレーズ、エンティティ、およびセンチメントを抽出できるようになります。
ステップ 6: Twitter API を使ってハッシュタグ #BePeculiar が含まれるツイートを探す
「Be Peculiar」は、Amazon 文化の主な特徴のひとつです。では、ハッシュタグ #BePeculiar が含まれるツイートを抽出しましょう。
Twitter アプリケーション情報
Twitter からデータを引き出すには、Twitter アプリケーション情報が必要です。これは、apps.twitter.com で見つけられます。
apps.twitter.com にアクセスして、既存のアプリがある場合はそれをクリック、または [Create New App] ボタンを選択して新しいアプリを作成できます。

Create an application フォームに必要な情報を入力して、Developer Agreement に同意してから、[Create your Twitter application] を選択します。

[Keys and Access Tokens] タブを選択し、Consumer Key (API キー) と Consumer Secret (API シークレット) を記録します。
[Create my access token] を選択します。作成されたら、Your Access Token にある Access Token と Access Token Secret を記録します。
これで、Amazon SageMaker ノートブックに戻ることができます。コード内にある Twitter アプリの API キーと Access Token 情報を保存して、Twitter API を使用するためにこの情報を使用できるようにします。
Twitter API 用の Python ラッパー
Tweepy は Twitter API 用の Python ラッパーです。これは、以下のコードを使用することによって、Twitter API への接続用にインポートし、使用することができます。Tweepy は、ノートブックで使用する前にインストールしておく必要があります。
これで、Tweepy をインポートし、ツイートの抽出用に Tweepy 認証ハンドラオブジェクトを作成できるようになりました。
使用したいハッシュタグをタグ変数に保存して、Tweepy 認証ハンドラオブジェクトを使ってそのハッシュタグが含まれるツイートを検索できるようになります。この例では、以下のコマンドを使用することで、「#BePeculiar」ハッシュタグを使用し、抽出したツイートを「tweets」という名前の html オブジェクトに保存します。
注意: データプルを制限するため、このコードに count=50 を追加しました。
警告: Twitter からのデータへのアクセスは高額になる場合があります。Twitter の API にアクセスする前に、料金ガイドラインを参照してください。
ステップ 7: Comprehend API を使って抽出されたツイートデータを分析する
個々のツイートは、ユーザー、ユーザーのプロファイル、そしてタイムスタンプ、いいね、コメント、および元のツイートなどの記事属性に関するメタデータが大量に含まれた JSON オブジェクトです。
ここでは、ツイートコンテンツと共にこのメタデータの一部を抽出できます。ツイートコンテンツは、記事のセンチメントを理解するために、Amazon Comprehend API を使ってさらに分析することができます。
このブログ記事のために、タイムスタンプ、ロケーション、およびツイートを抽出し、各ツイートのセンチメントスコアを抽出しました。
ステップ 8: データを可視化する
データを可視化するには、データを適切にフォーマットすることが大切です。抽出した情報を組み合わせて DataFrame を構築し、データを表形式に整理できるようにします。
DataFrame を構築する
Python Pandas ライブラリを使用することで、DataFrame を構築して、抽出された情報を簡単な消費のために表形式に整理できます。
探索的なデータ分析を実行する
結果のデータセットで探索的なデータ分析を行い、重要なビジネス関連の質問に答えることができます。
例えば、より多くのポジティブセンチメントを生成したロケーションを見つけるには、以下のコードブロックを実行できます。
以下のコードブロックは、ツイートが最も多かったロケーションを明らかにするために役立ちます。
同様に、タイムスタンプフィールドをさらに break して、他の時間より多くのポジティブセンチメントを生成する特定の時間帯があるかどうかについて学ぶことも可能です。
Amazon S3 にデータを保存する
最後に、結果をコンマ区切りのファイル (CSV) で Amazon S3 に保存できます。これにより、Amazon SageMaker のネイティブアルゴリズムを使ってビジネスインテリジェンス (BI) ダッシュボードを構築したり、その他関連する機械学習モデルを構築するために Amazon Comprehend API からのセンチメント分析結果を再利用したりすることができるようになります。
まとめ
このブログ記事では、ソーシャルメディアから関連データを取得するために Twitter API を使ってツイートを抽出する方法について学びました。また、Amazon Comprehend API を使って Twitter フィードを分析し、有用な情報を抽出する方法も学びました。さらに、Amazon Comprehend からの結果を関連する Amazon SageMaker アルゴリズムへの入力として使用し、推論を構築することもできます。Amazon Comprehend の詳細については、AWS ドキュメントを参照してください。
Ben Snively と Viral Desai がサーバーレステクノロジーを使ってソーシャルメディアダッシュボードを構築する方法を説明するブログ記事、機械学習と BI サービスを使用してソーシャルメディアダッシュボードを構築するを参照することも可能です。このソーシャルメディアダッシュボードは、#AWS ハッシュタグが付いたツイートを読み込み、Amazon Translate および Amazon Comprehend などの機械学習サービスを使って翻訳を行い、自然言語処理 (NLP) を使ってトピック、エンティティ、およびセンチメントを抽出します。最後に、Amazon Athena を使って情報を集約し、Amazon QuickSight ダッシュボードを構築してツイートからキャプチャした情報を可視化します。
著者について
 Pranati Sahu は AWS プロフェッショナルサービスおよび Amazon ML Solutions Lab チームのデータサイエンティストです。Pranati はテンピ市のアリゾナ州立大学からオペレーションズリサーチの理学修士号を得ており、ソーシャルメディア、コンシューマーハードウェア、および小売りなどの様々な産業で機械学習の問題に取り組んできました。現在の役割では、AWS における業界の複雑な機械学習ユースケースを解決するためにお客様と連携しています。
Pranati Sahu は AWS プロフェッショナルサービスおよび Amazon ML Solutions Lab チームのデータサイエンティストです。Pranati はテンピ市のアリゾナ州立大学からオペレーションズリサーチの理学修士号を得ており、ソーシャルメディア、コンシューマーハードウェア、および小売りなどの様々な産業で機械学習の問題に取り組んできました。現在の役割では、AWS における業界の複雑な機械学習ユースケースを解決するためにお客様と連携しています。