Amazon Web Services ブログ
ディープラーニングネットワーク (GAN と Siamese) を組み合わせハイクオリティでリアルなイメージを生成
ディープラーニングはトレーニングに使用するデータの量と質に依存するため、企業は優れたイメージデータを得ようと多額の費用を投資をしています。通常、そうした企業はコストの掛かる人間による注釈を使ったり、製品や人物の写真を撮るなど、多大な作業を要しています。けれども、このアプローチはコストが掛かる上に拡張性もありません。コンピュータをトレーニングしてハイクオリティなイメージを生成すれば、コストを大幅に削減しビジネスの成長を促進することができます。
このブログ記事では、Amazon の私の同僚数人がまとめた「Semantically Decomposing the Latent Spaces of Generative Adversarial Networks」という学術論文で取り上げられているコンセプトを分かりやすく説明します。この論文は、Semantically Decomposed GANs (SD-GANs) の使用を可能にするため、Generative Adversarial Networks (GANs) と Siamese Networks (SNs) を実際に適用する場合について説明しています。
GANs と SNs は比較的高度なディープラーニングシンボルで、現実的な問題を解決するために各自または他のディープラーニングシンボルと組み合わせて使用することができます。こうしたシンボルを組み合わせると、AI アプリケーションは難しく複雑なビジネス上の問題をより多く解決できるようになります。たとえば、AI の主なチャレンジの 1 つは注釈やタグ付けしたデータの欠如です。ハイクオリティな注釈データには多大なコストが掛かるため、これを利用できるのは大規模で経済的に余裕のある企業に限られています。この論文で説明されているようなディープラーニングの方法を使うと、より多くの企業が質の高いデータを少ないサンプルから生成することが可能になります。
リアルなイメージを分析するために作成者が GANs や SNs そして SD-GANs をどのように使用し、同じ人物やオブジェクトのコントロールしたバリエーションで「偽」のイメージを生成する方法を説明します。パラメータやあなたが設定した「監視プロパティ」により、偽のイメージを別の視点から作成したものに見せたり、別の照明や、より良質な解像度を使用、もしくはそれに似たようなバリエーションを使用したかのように見せることができます。この論分で説明されているイメージ分析を使用すると、プロがフォトショップで加工したもの、または 3D モデルを使用して作成したかのように、実にリアルなイメージを作成することができます。

図 1: 論文で説明されている方法を使用して生成したサンプル各行は同じ顔のバリエーションを示しています。各列は同じ監視プロパティを使用しています。
Generative Adversarial Networks とは?
Generative Adversarial Networks (GANs) は、ニューラルネットワークの比較的新しいディープラーニングアーキテクチャです。これは 2014 年にカナダのモントリオール大学の Ian Goodfellow 氏と同僚達により開発されました。GAN は 2 つの異なるネットワークを敵対的にトレーニングするため、敵対的 (adversarial) と呼ばれています。ネットワークの 1 つが、実像を撮りできる限りの変更を加えることで、イメージ (またはテキストやスピーチなど他のサンプル) を生成します。そして、もう 1 つのネットワークは、そのイメージが「偽」か「本物」かを予測しようとします。G ネットワークという最初のネットワークは、より優れたイメージを生成することを学びます。D ネットワークという 2 つめのネットワークは偽のイメージと本物のイメージを見分けることを学びます。この判別力は徐々に改善されていきます。
たとえば、G ネットワークが人物の顔にサングラスを追加したりすることもあります。D ネットワークはサングラスをかけた人物のイメージや、G ネットワークがサングラスを追加した人物のイメージなど、一連のイメージを取得します。D ネットワークが、どちらのイメージが偽でどちらが本物かを判別することができたら、G ネットワークはそのパラメータを更新して、よりリアルな偽のサングラスを生成します。D ネットワークが偽のイメージを判別できなかった場合は、偽のサングラスと本物のサングラスをより見分けやすくするためにパラメータを更新します。このように競り合うことでどちらのネットワークも改善されていきます。
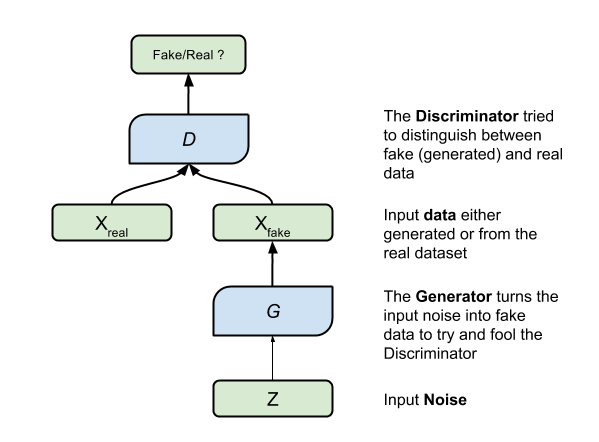
ここでは主に G ネットワークに注目します。人間や AI アプリケーションに本物だと思わせる「偽」のイメージを生成できることは、ビジネスの大きな成功の 1 つと言えます。
Siamese ネットワークとは?
Siamese Networks (SNs) でも 2 つのネットワークが共に作用します。けれども、ネットワークが競い合う GANs とは異なり、この 2 つのネットワークは同一で共に作用します。SNs はネットワーク出力を 2 つの異なる入力で比較し、その類似点を比べます。
たとえば、SN は 2 つの署名を同一人物が書いたことを検証することができます。また、SN は同じ質問を別の文章で表しているか確認することもできます。たとえば「今何時ですか? (What is the time?)」という質問は「現在の時刻は? (Do you have the time?)」と同じですが、「私と結婚してくれますか? (Will you marry me?)」は「ちょっと頼ってもいいですか? (Will you carry me?)」とは意味が違います。SN は最初の入力 X1 (この例では文章) を取り上げて数字のベクトルに変換し、2 つめの入力 X2 との距離を測ります。
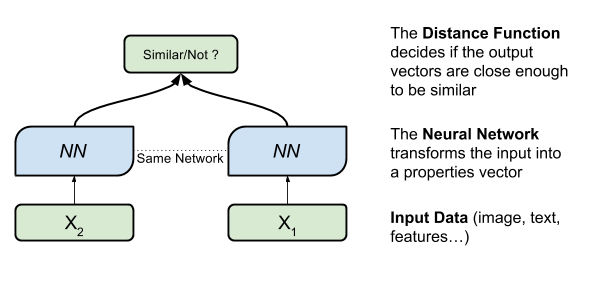
テキストを入力したり、イメージのような他のタイプのデータを入力することができます。先述した論文では、研究者達が 2 つのイメージのバリエーションから同じ人物 (またはオブジェクト) を表現できるか判断するために SN アーキテクチャを使用しています。
Semantically Decomposed GANs とは?
たとえば、あるオブジェクトまたは人物の特定のイメージを使用し、そのイメージの外観を変更したい場合はどうすれば良いと思いますか?つまり、偽のイメージは生成したくないが、オリジナルのイメージの何かを変更したい場合です。スタンダード GAN はオリジナルとは異なるアングルで撮ったように見せた偽の靴のイメージを生成することができます。Semantically Decomposed GAN (SD-GAN) は、コントロールした別のアングルからオリジナルの靴のイメージを生成することができます。SD-GANs は無制限の数のクラスに渡りイメージ (例: アイデンティティ、オブジェクト、人物など)、その様々なバリエーション (例: 視点、照明、カラー vs. 白黒、アクセサリーなど) を生成する方法を学ぶことができます。データセットにこうした多数のクラスやバリエーションが含まれている限り、SD-GAN はオリジナルイメージのリアルな描写を取り入れたバリエーションの生成を学ぶことができます。たとえば、この論文の著者達は異なるバリエーションから成る複数のイメージを含んだ有名人のイメージ 100 万件のデータセットを使用しています。

図 2: 同じ個人 (Zi) と別の視点 (Zo) を含む SD-GAN アーキテクチャは Siamese ジェネレーター (G) に渡されてから、Siamese ディスクリミネーター (De) に送られます。出力は、そのイメージが同じ人物を表しているかを示すバイナリ結果に変換されます。
こうしたアーキテクチャを使い始めるには?
基本的なディープラーニングネットワークをすでに利用したことがないと、こうした高度なネットワークアーキテクチャをすぐに使い始めるのは難しいかもしれません。でも、だからといって物怖じする必要はありません。まず、最近の GAN アーキテクチャで使われている、より基本的なディープラーニングシンボルに慣れることをお勧めします。手始めに Apache MXNet GitHub リポジトリにあるようなノートブックチュートリアルを実行します。GAN チュートリアルは特に参考になります。ビデオの方がよければ fast.ai や twitch のライブコーディングなどのオンラインコースをご覧ください。
その他の参考資料
Apache MXNet や Apple Core ML を使用して iOS アプリに Machine Learning を導入する方法についてはこちらをご覧ください。

今回のブログの投稿者について
 Guy Ernest 氏は Amazon AI のプリンシパルソリューションアーキテクトです。マインドシェア構築の戦略に携わり、Amazon の AI、Machine Learning、ディープラーニングのユースケースのクラウドコンピューティングプラットフォームを幅広く使用しています。時間がある時は家族との時間を楽しみ、面白くちょっと恥ずかしい話しを集めたり、Amazon や AI の今後について話し合ったりしています。
Guy Ernest 氏は Amazon AI のプリンシパルソリューションアーキテクトです。マインドシェア構築の戦略に携わり、Amazon の AI、Machine Learning、ディープラーニングのユースケースのクラウドコンピューティングプラットフォームを幅広く使用しています。時間がある時は家族との時間を楽しみ、面白くちょっと恥ずかしい話しを集めたり、Amazon や AI の今後について話し合ったりしています。