Amazon Web Services ブログ
Precisely を用いた Data Replication 構成例
みなさん、こんにちは。現在メインフレームを利用されている方の中で、メインフレームシステム上の業務データを活用することで、ビジネス意思決定の高度化や新たなビジネス創出を行い、ビジネス価値を向上させる方法を検討されている方はいらっしゃいますでしょうか。こちらの検討をされている方は、多くのケースにおいて以下のような課題に直面されているのではないでしょうか。
- メインフレームの処理能力が限界に近づいており、現行処理に影響しないようにデータ分析やデータ加工を行うことは難しい。
- メインフレームからデータをエクスポートしたいが、データ構造や型変換に手間と時間がかかりデータ鮮度を高められない。
本ブログでは、これらの課題に対する一つの解決策である Precisely を用いたニアリアルタイムのデータ同期をご紹介します。この方法を使うことでデータ構造や形式を変換しながら、メインフレーム上の様々なデータソースから AWS 環境上のデータストアへ、ニアリアルタイムの同期を行うことで、外部システム上で鮮度の高いデータを用いてデータ活用を行うことが可能です。
Precisely を使用した AWS Mainframe Modernization Data Replication とは
AWS Mainframe Modernization Data Replication は、Precisely 社の Change Data Capture (以下、CDC) テクノロジーを活用した、メインフレームのデータを AWS クラウドへ同期するためのソリューションです。メインフレーム上の様々なデータソースから AWS 環境上のデータストアへ、ニアリアルタイムのレプリケーションを実現します。
このソリューションの特徴としては、以下のようなものがあります。
- CDC によるニアリアルタイムのレプリケーションの実現
- メインフレームのデータソースへの負荷の配慮
- Db2、IMS、VSAM などメインフレーム上の様々なデータソースへの対応
- Amazon Managed Streaming for Apache Kafka (以下、MSK) と統合することによる、AWS サービスを直接ターゲットとするレプリケーションの実現
このソリューションは、以下のような様々なデータ利活用のユースケースに適用可能です。
- AWS クラウド上のデータレイクやデータウェアハウスに同期したメインフレームデータを使った、BI による可視化や AI/ML による新たなデータの活用
- AWS クラウド上のデータストアにニアリアルタイムで同期されたメインフレームデータに対する、新規ビジネスアプリケーションからのデータ参照
- メインフレームのダウンタイムを最小化しながら、メインフレームアプリケーションおよびデータを AWS クラウドに移行する
アーキテクチャ概要
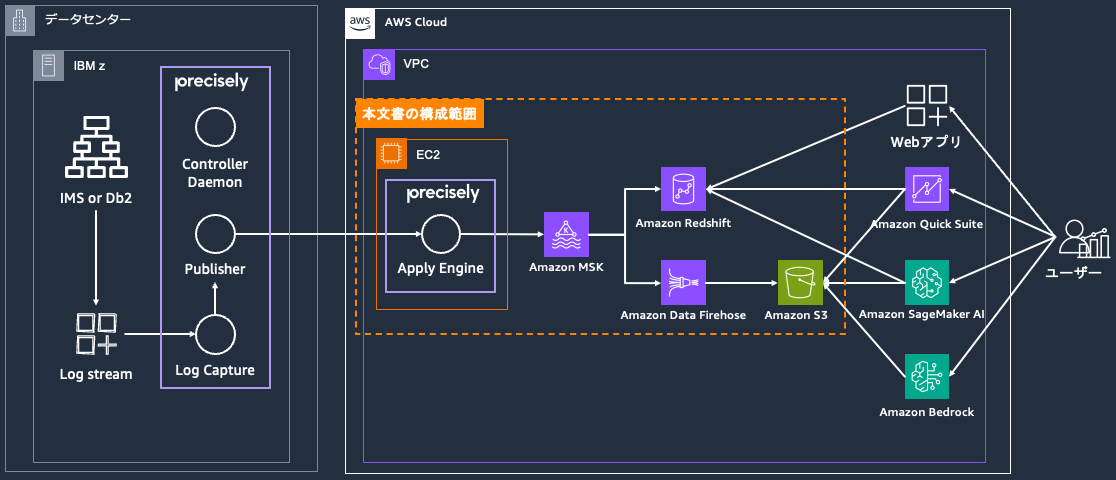
実際にメインフレームからAWS クラウド上にデータを同期する際の、推奨する基本構成は以下のようになります。
{kind=link}
このアーキテクチャは、Amazon EC2 インスタンスでデプロイされた Precisely Apply Engine を境目として、メインフレーム側と AWS クラウド側に分けられます。メインフレーム側から送信されたデータは、Apply Engine で処理・変換され、後続の AWS サービスに送られます。メインフレーム側にはログ収集用のエージェントがインストールされており、データを一定量蓄積した上でのバッチ送信またはログストリームのニアリアルタイム送信が可能です。AWSクラウド側には Apply Engine を構成することで、ホストから送信されたデータを後続のサービスで利用しやすい形式に加工しながら連携することが可能です。MSK と組み合わせることで、Amazon Redshift、Amazon S3、Amazon RDS、Amazon Aurora、AWS Lambda など、様々なサービスに対してニアリアルタイムなデータ連携が可能です。本ブログ上では、S3 と Redshift に連携するための構成方法を扱います。
データの活用シナリオ例
多くのメインフレーム上には、顧客情報、取引履歴、在庫データ、売上データなど、企業の基幹業務で扱われる重要な情報が含まれているかと思います。これらのデータを活用する例として、以下のようなシナリオを想定しながら今回の環境構築方法を紹介していきます。シナリオ例1としては、データの長期保存や機械学習での活用を主な目的として S3 にデータを格納する構成をご紹介します。シナリオ例2としては、より即時性を重視したニアリアルタイム分析やダッシュボード表示を可能とする Redshift にデータを格納する構成をご紹介します。
- シナリオ例1)月次の監査実施タイミングで取引データや顧客行動データを個別抽出して不正取引を検出している金融機関が存在する。この状況に対して、Precisely を用いて当該データをニアリアルタイムで抽出し S3 に蓄積するよう変更を行うことで、日々の最新データを用いて不正取引検出を行い、迅速に自動アラートを発信することが可能になる。
- シナリオ例2)製造ラインの各工程で生成される品質データや稼働データをメインフレームに蓄積し、日次レポートで品質傾向を把握している製造業企業が存在する。この状況に対して、Precisely を用いて、製造工程での品質データ・稼働データ生成と同時に Redshift に格納するよう変更を行うことで、品質異常や設備故障の兆候を数分以内に検知し、生産ライン停止前の予防保全を実現できるようになる。
詳細な設定方法
Precisely Connect Apply Engine の準備
Precisely の Apply Engine を利用するための最も簡単な方法は AWS マーケットプレイスに準備された、 Precisely Connect のアプライエンジンを構成するための EC2 の AMI を利用することです。この AMI には、「インストール済みのソフトウェアスタック」「作成・初期化済みのレプリケーションインスタンス」「Amazon CloudWatch と統合済みのプロセスとマーケットプレイスと統合済みのレプリケーションサービス」が導入済みのため、EC2 インスタンス起動後にすぐに利用を開始することができます。マーケットプレイスから「AWS Mainframe Modernization – Data Replication for IBM z/OS」を検索し、サブスクライブを行うことで、該当の AMI を利用した EC2 インスタンスを起動できるようになります。

上記 AMI を用いて EC2 インスタンスを起動した後には、インスタンスにログインを行い、レプリケーションを行うための構成を行います。構成のための詳細手順は、Precisely Connect の構成手順のドキュメントを参照してください。
本ブログでは、Apply Engine 以降の処理の確認に焦点を当てるため、メインフレーム環境は使用せずに、EC2 インスタンス上に配置したサンプルファイルをデータソースとして、後続のターゲットに対してレプリケーションを行うアプライスクリプトをご紹介します。
[売上明細のサンプル (CSV)]
データソースとして使用した CSV の各列の意味はstore_id: 店舗ID, product_id: 商品ID, amount: 数量, unit_price: 単価, total_price: 合計金額, timestamp: 売上日時であり、実際のファイルは以下となります。
[サンプルのアプライスクリプト]
実際に使用したアプライスクリプトは以下の通りです。
MSK の準備
次に、Apply Engine から送信されたデータを処理する MSK 部分を構築します。構築の最初のステップは、マネジメントコンソールで、MSK のコンソール画面に移動して、MSK クラスターを作成することから始まります。Apply Engine と MSK クラスターが安全に通信するために、今回は同じ VPC 内に両者が存在する構成を採用します。クラスタータイプは Provisioned を選び、Apply Engine の VPC へ配置していきます。Apache Kafka バージョンは要件によって変わりますが、今回は特殊要件は想定しないため最新版を選びます。
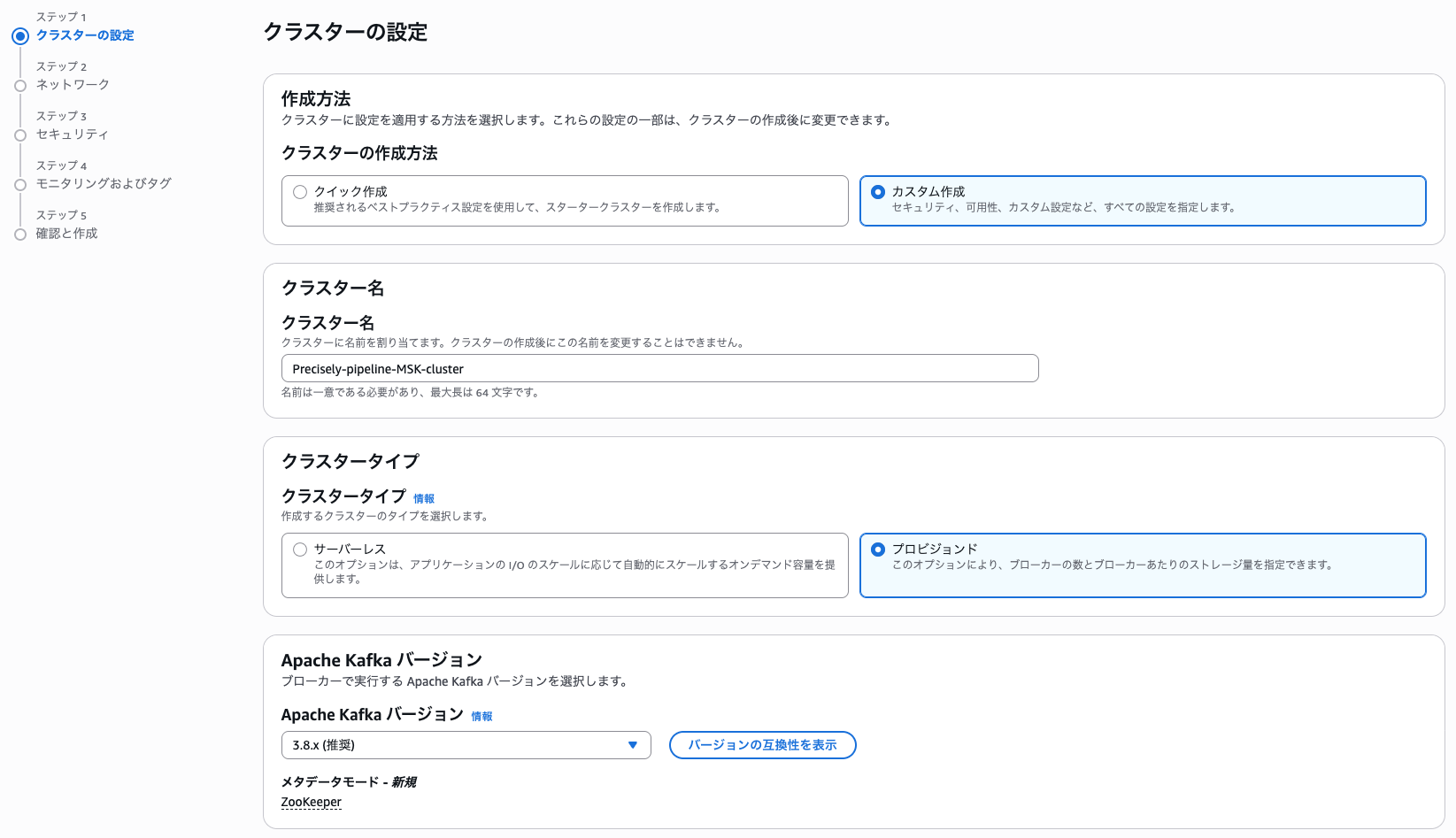
ブローカーは Standard を選択し、ブローカーサイズは、後続処理として VPC プライベート接続が必要な Amazon Data Firehose を利用するため、VPC プライベート接続が利用可能な m5.large インスタンスを利用します。ブローカーのゾーン数は配置先の VPC と合わせて数を選択します。今回は 2 を利用します。ゾーンあたりのブローカー数は、1つを選択します。要件に応じて一つのゾーン (AZ) に複数のブローカーを配置することも可能です。今回は、クラスターのストレージはデフォルト値を利用します。
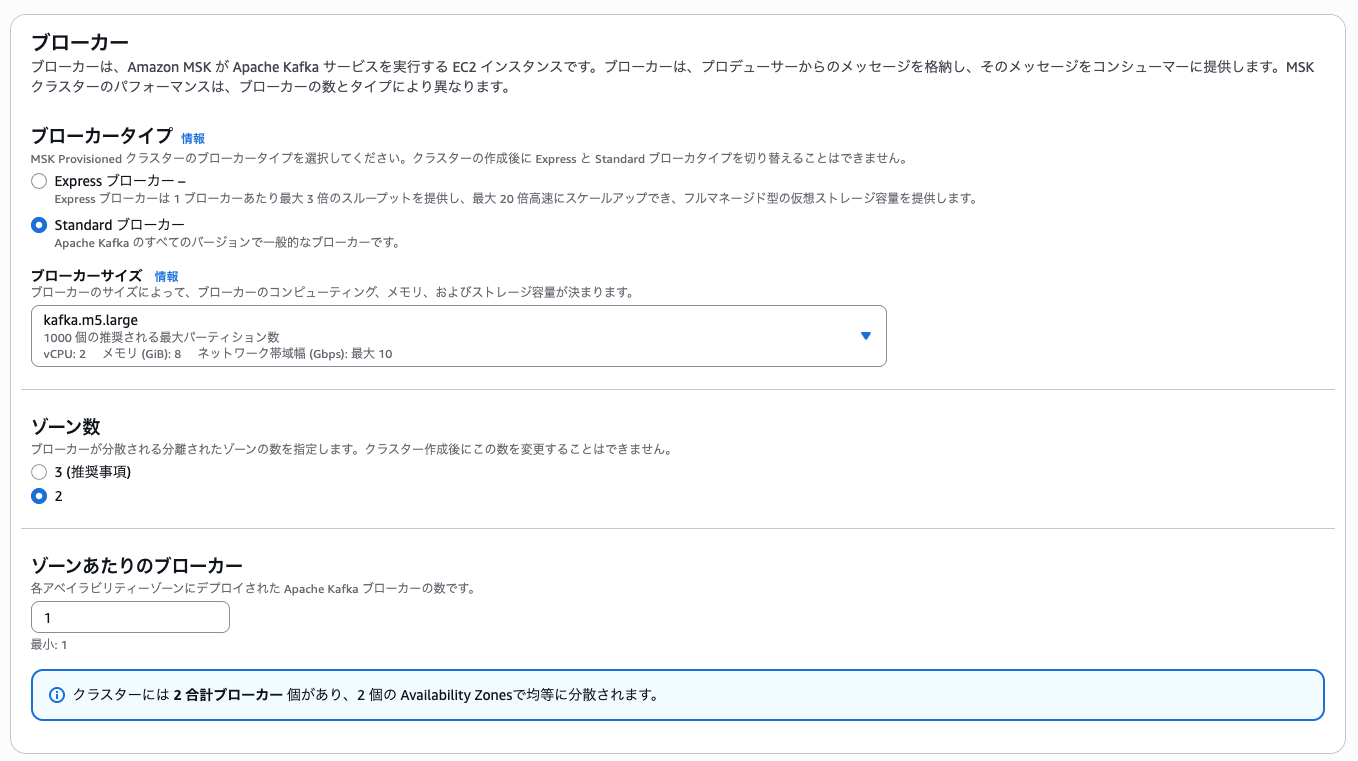
続いて、ネットワーク設定を行います。まずは対象として Apply Engine が展開された VPC を選択します。そして「最初のゾーン」として、指定した AZ それぞれに対応するサブネットを選択します。セキュリティグループについては、Apply Engine ホストと EC2 の両方に同一なセキュリティグループを使用するか、Kafka が利用するポートが開放され接続・疎通が可能なセキュリティグループを準備して指定してください。

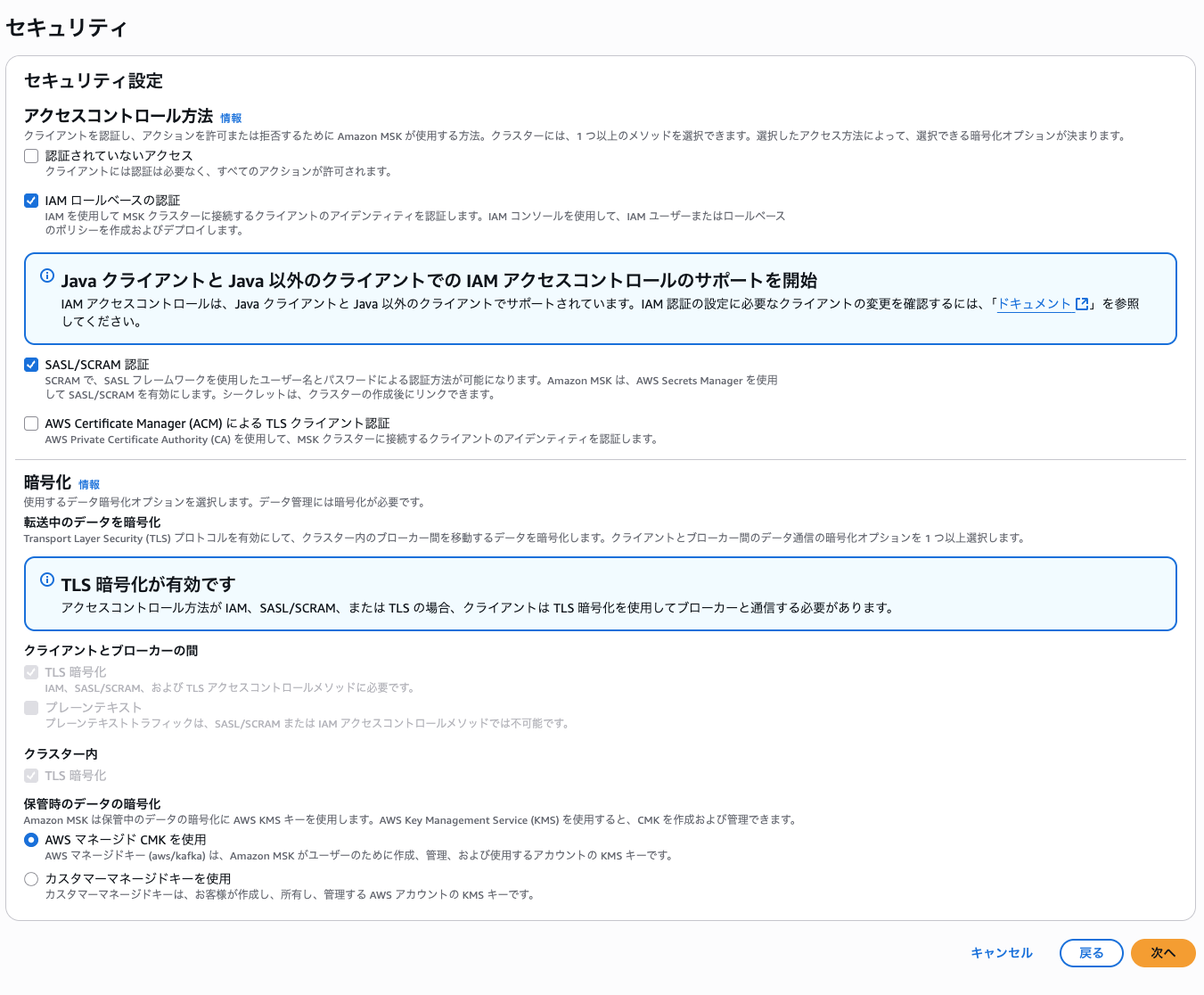
関連するリソースが MSK にアクセスできるように、必要な権限設定を許可します。今回は以下の設定を使用します。
- Apply Engine との接続はユーザー名とパスワードを用いるため、SASL/SCRAM 認証を有効にする。
- MSK から Data Firehose へ接続するため、IAM ロールベースの認証を有効にする。
 次にモニタリングに関する設定をして、クラスターをデプロイします。クラスターの立ち上げは 数十分程度かかる場合があります。立ち上げが完了してから、接続許可の変更および Apply Engine からデータを連携するために、MSK のトピックを作成し設定します。
次にモニタリングに関する設定をして、クラスターをデプロイします。クラスターの立ち上げは 数十分程度かかる場合があります。立ち上げが完了してから、接続許可の変更および Apply Engine からデータを連携するために、MSK のトピックを作成し設定します。
MSK でトピックを作成する方法はいくつかありますが、今回は Amazon MSK のDeveloper Guide に従って、クライアントとして利用している EC2 インスタンスから Kafka を操作する方法を採用します。詳細の設定手順は同 Developer Guide のこちらを参考してください。必要な作業ステップ概要は以下となります。ここで作成したトピック情報は、後続の送受信設定で使用します。
- MSK クラスターを操作する権限のある IAM ロールを作成する。
- 上記操作権限を持つロールが付与された EC2 インスタンスを立ち上げる。MSK クラスターと疎通できるように、セキュリティグループなどを設定する。(Apply Engine がホストされた EC2 で代用可能)
- EC2 にログインして、MSK クラスターで展開された Kafka のバージョンに対応した Kafka パッケージをダウンロードして設定する。
- 疎通を確認してから、MSK クラスターの BootstrapServer に対して、Apply Engine の出力連携用のトピックを作成する。
最後に、以下図のようにMSK クラスターのネットワーク設定でマルチ VPC 接続を有効にして、クラスターポリシーでも Data Firehose からの接続を許可します。
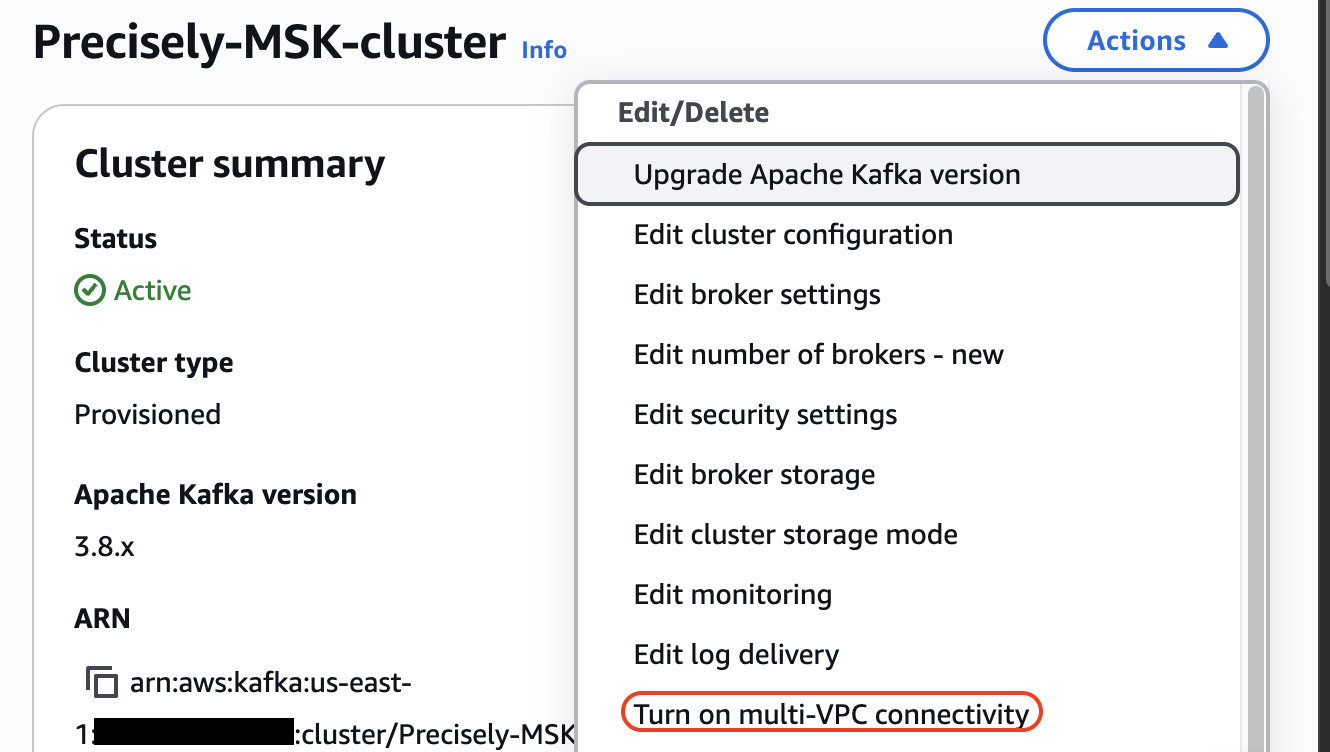
Apply Engine から MSK への接続
MSK クラスターの設定の後には、実際に Apply Engine から MSK の間でデータ送受信の確認を行います。具体的には、Apply Engine の設定時に利用したデータ変換スクリプトを書き換えて実際の通信を行います。設定変更のポイントは、送信先を指定する TARGET DATASTORE のセクションで、DATASTORE の部分をトピック名( kafka:///<topic名> )に指定することです。実際のスクリプト例は以下となります。なお、今回はデータのフォーマット変換は行わず、直接 MSK へ送信します。
次に、MSK 側にて Apply Engine の認証設定を行います。Apply Engine が利用するユーザー名とパスワードを以下図のように Secrets Manager に保管します。暗号化にはカスタムキーによる暗号化を利用します。カスタムキーは AWS Key Management Service (KMS) を用いて作成できます。AWS マネージドキーを利用すると MSK では関連付けできませんのでご注意ください。具体的にはシークレットを作成してから、以下図のように、MSK クラスターのセキュリティ設定で関連付けを行います。なお、シークレットを作成するとき、命名ルールとして、AmazonMSK_のプレフィックスが必須です。

最後に、Apply Engine がホストされたインスタンスで、Apply Engine の設定を変更します。Apply Engine のワーキングディレクトリ上で、データ送信用の設定ファイル ( sqdata_kafka_producer.conf ) を、作成した環境に合わせて以下のように書き換えます。
その後 Apply Engine でデータ変換スクリプトを以下のコマンドでコンパイルして実行すれば、MSK トピックに対してデータ送信が行われます。
Data Firehose を通した S3 への接続(シナリオ例1)
ここまでの作業により、メインフレームのデータが MSK トピックにニアリアルタイムで送信されるようになりました。後段の構成としてまずは、シナリオ例1を実現するために、MSK で受信されたデータを、Data Firehose を通して S3 データレイクに連携する構成方法をご紹介します。MSK から直接 S3 サービスへデータを連携することもできますが、今回は S3 に格納するデータを柔軟に加工できることを重視して Data Firehose に接続した上で S3 に連携する構成を利用します。Data Firehose を利用することで自動的なデータの圧縮、暗号化、パーティション分割を実現することが可能です。
IAM ロールとポリシーの作成
Data Firehose が MSK からイベントを取得するために、まずは MSK クラスター、トピック、グループへアクセスできる IAM ロールとポリシーを作成します。同時に、送信先である S3 バケットへのアクセス権限を付与します。IAM ロール例は以下となります。
MSK クラスターポリシーの設定
MSK 側のクラスターポリシーでも Data Firehose からのアクセスを許可しておく必要があります。具体的な設定方法は、Amazon MSK の Firehose 統合、Amazon MSK のソース設定を構成するを参照ください。
Data Firehose の作成
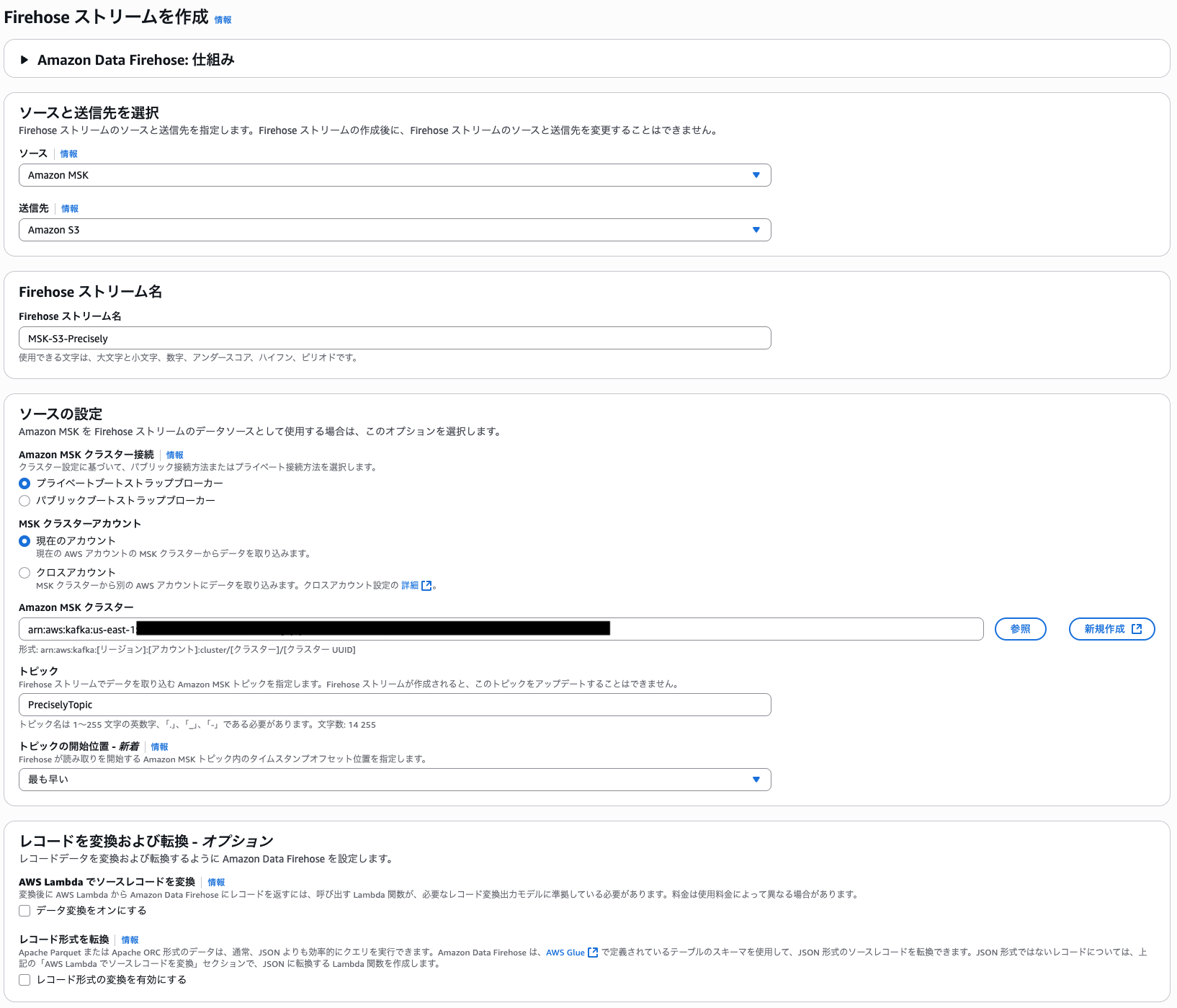
次に、データソースを MSK クラスター、送信先を S3 バケットとした Data Firehose の作成を行います。手順は以下の通りです。
- Amazon Data Firehose コンソールで「Create delivery stream」を選択
- Source として「Amazon MSK」を選択
- MSK クラスター、トピック名、開始位置を指定
- Destination として「Amazon S3」を選択
- S3 バケット名とプレフィックスを設定
- 作成した IAM ロールを指定
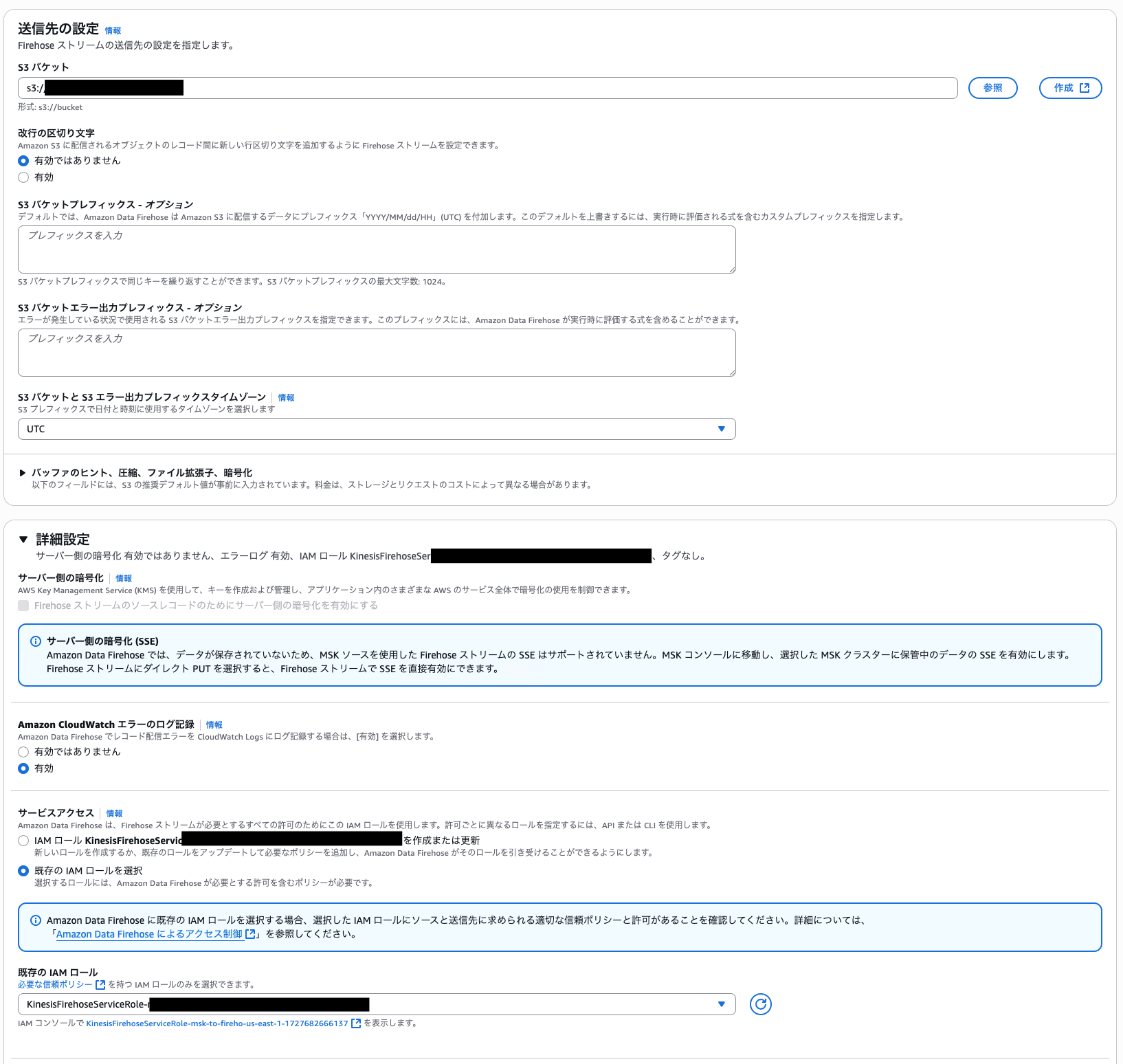
設定の完了後に状態がアクティブになれば、Apply Engine から MSK と Data Firehose を経由して S3 へのデータ送信が可能になります。Apply Engine でデータ送信を実施すれば、送信先の S3 バケットで新オブジェクトが作成されることを確認可能です。

Redshift への直接接続(シナリオ例2)
次に、シナリオ例2を実現するために、MSK で受信されたデータを Amazon Redshift に直接連携 (ストリーミング統合) する構成方法をご紹介します。この場合、Redshift のマテリアライズドビューを使用してニアリアルタイムデータ取り込みを実現します。
IAM ロールとポリシーの作成
まず準備として、Redshift 用の MSK クラスター、トピック、グループにアクセスしてデータを取得する権限を持つ IAM ポリシーが付与された IAM ロールを作成します。IAM ロール例は以下となります。
Redshift クラスターの作成
次に作成したロールを適応済みの、拡張された VPC ルーティングを有効にした Redshift クラスターを作成して、利用可能な状態にします。Redshift クラスターの作成の詳細については Amazon Redshift 管理ガイドを参照してください。
スキーマとマテリアライズドビューの作成
Redshift が利用可能な状態になってから、送信されたデータの受け皿となるデータベースを作成します。クエリエディターなどで作成したデータベースへアクセスして、データを受け入れる外部スキーマを例えば以下の SQL で作成します。
次に、受信したデータを集約するマテリアライズドビューを作成します。AUTO REFRESH を有効にすることで、MSK からの新しいデータが自動的に反映されます。ここまでできれば MSK と Redshift の間でデータ連携を行うことが可能です。
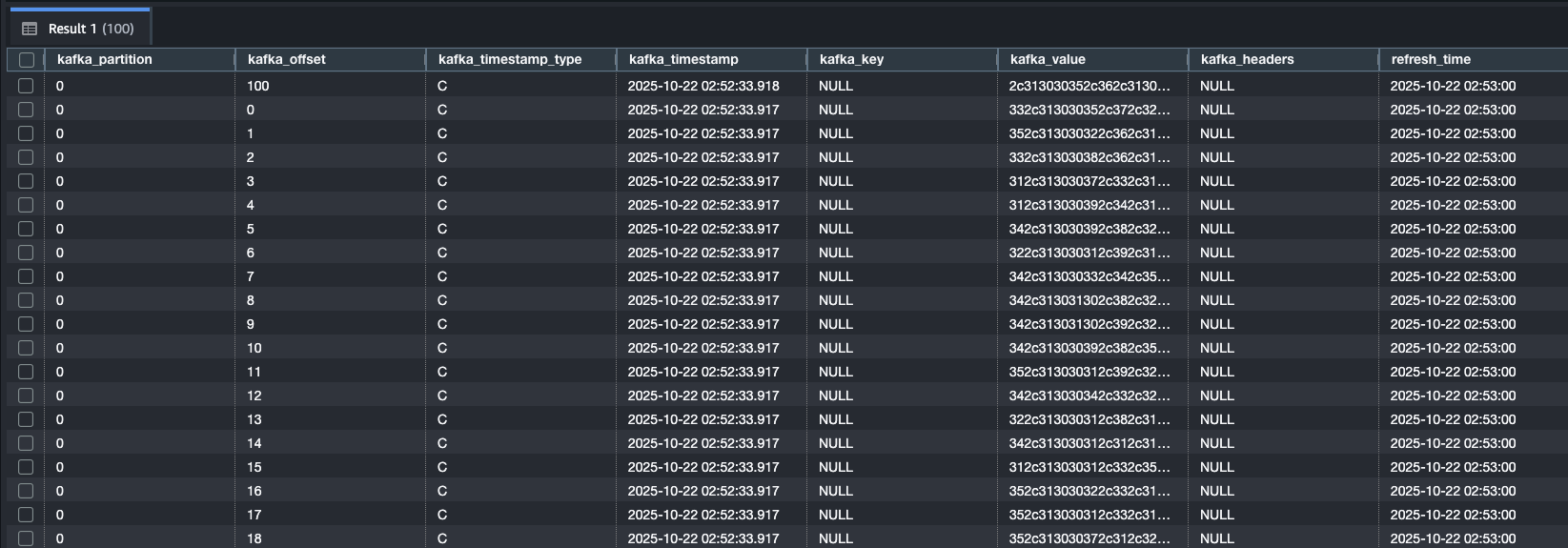
データ変換とビジネス分析用ビューの作成
実際にデータ連携を行うと、作成したビューの中では、kafka_value のカラムに受信したレコードのデータがそのまま保管されていることがわかるかと思います。このままではビジネス分析に必要なデータ参照がやりにくいため、受信したデータを整形処理したマテリアライズドビューを改めて作成します。今回のサンプルデータで売上データを集計するために、以下のような変換を行います。
実際にビューとして確認できるデータ内容は以下の通りです。

ニアリアルタイム分析の実行
その上で、作成したビューを使用して、ニアリアルタイムでの売上分析や異常検出クエリを実行できます。
この構成により、メインフレームでの取引発生から数分以内に Redshift での分析結果を取得でき、Amazon Quick Sight などの BI ツールと連携してニアリアルタイムダッシュボードを構築することも可能です。
構成の使い分け
ここで、代表的な2種類の構成を紹介しましたが、それぞれに適したユースケースは次のようにります。
- Data Firehose を経由した S3 への連携構成
- 長期保存、機械学習、大容量データ処理が必要な場合
- Redshift への直接連携構成
- ニアリアルタイム分析、ダッシュボード表示、即座の意思決定支援が必要な場合
用途に応じて両方の連携先を同時に設定することも可能で、包括的なデータ活用基盤を構築できます。MSK と Redshift についてより詳細に知りたい方は、以下のドキュメントを参照してください。
- Amazon Managed Streaming for Apache Kafka デベロッパーガイド: Amazon MSK の Amazon Redshift ストリーミングデータインジェスト
- Amazon Redshift データベース開発者ガイド: マテリアライズドビューへのストリーミング取り込み
- Amazon Redshift データベース開発者ガイド: Amazon Kinesis Data Streams からストリーミング取り込みを開始する方法
おわりに
本ブログでは、Precisely を用いた AWS Mainframe Modernization Data Replication により、メインフレームデータを AWS クラウドへニアリアルタイムで同期する方法をご紹介しました。この構成により、従来の日次バッチ処理では実現できなかった迅速なデータ活用が可能になり、S3 データレイクでの機械学習活用から Redshift でのニアリアルタイム分析まで、多様なユースケースに対応できます。メインフレームへの影響を最小限に抑えながら、クラウドの柔軟性とスケーラビリティを活用したデータドリブンな意思決定を実現することで、ビジネス価値の向上に貢献することが可能です。より詳細なご相談や具体的な実装支援については、AWS Professional Services までお気軽にお問い合わせください。
参考情報
著者について

安藤 亮一 (ANDO Ryoichi)
安藤 亮一は、AWS Japan プロフェショナルサービスチームのデリバリコンサルタントです。データプラットフォームの構築を検討されているお客様の構想策定の支援や、生成 AI のためのデータプラットフォームの構想策定・設計構築の支援などを行っています。データ基盤の構築や利活用でお困りのことがあれば、ぜひご相談ください。

賀 雲剣 (Yunjian He)
賀 雲剣は、AWS Japan プロフェショナルサービスチームのデリバリコンサルタントです。AWS認定試験全取得でゴールデンジャケットを保持しています。
高エネルギー物理学分野で博士(理学)の学位を取得、大規模データの分析で悩んでいた過去の自身のようなお客様に役立ちたいと思ってAWSに入社しました。最近は生成AI利活用のプラットフォーム構築支援プロジェクトに参画し、データに関わる側面でお客様の支援を行っています。

北川 裕介 (KITAGAWA Yusuke)
北川 裕介は、AWS Japan プロフェショナルサービスチームのデリバリコンサルタントです。主にメインフレームの活用や移行に関する活動を支援しています。