Amazon Web Services ブログ
Amazon SageMaker BlazingText を使用して強化されたテキスト分類と単語ベクトル
本日、Amazon SageMaker BlazingText アルゴリズム用のいくつかの新機能を発表します。感情分析、固有表現抽出、機械翻訳などの多くの下流工程での自然言語処理 (NLP) タスクではテキストデータを実数値ベクトルに変換する必要があります。お客様は数百ギガバイトのテキストドキュメントからこれらのベクトルを学習するために、BlazingText の高度に最適化された Word2Vec アルゴリズムの実装を使用してきました。 結果として得られるベクトルは、私たちが単語を読むときに認識する豊かな意味とコンテキストを捉えます。 BlazingText は fastText や Gensim のようなそれ以外に広く利用されているものより 20 倍以上高速であり、お客様は GPU や複数の CPU マシンを使用して数十億単語を含む独自のデータセットでこれらのベクトルをトレーニングできるため、これによって数日間かかっていたトレーニング時間を数分に短縮することができます。
これまでに BlazingText を使用して作業をしたことがない場合には、このアルゴリズムについて、ドキュメントや以前のブログ記事を参照することができます。
BlazingText には次の新機能と機能拡張が追加されました。
- 単語ベクトルにサブワード情報を持たせて豊かな表現にするための文字 n-gram のベクトル表現の学習。 私たちが用いるトレーニングデータセットでは、推論時に出現するすべての単語を持つことは不可能であるため、これらの単語をすべて無視したり、ランダムベクトルを使用するよりも、これらの単語の意味表現を生成する方がはるかに役立ちます。BlazingText は文字 n-gram (サブワード) ベクトルの和としてベクトルを表すことで、未定義 (OOV) 語の意味のあるベクトルを生成することが可能です。
- 高速マルチクラスとマルチラベルテキスト分類を実行する能力。 テキスト分類の目的は、テキスト文書を 1 つまたは複数の定義されたカテゴリー (スパム検出、感情分析、ユーザーレビュー分類) に自動的に分類することです。BlazingText は fastText テキスト分類器を拡張し、最適化された CUDA カーネルを使用して GPU アクセラレーションを活用します。深層学習テキスト分類モデル (Conneau et al., 2016, Zhang and LeCun (2015)) はトレーニングに数時間から数日かかることがありますが、BlazingText は同程度の精度を達成しながら 100 倍以上高速であるため、数分でトレーニングを行うことができます。
- リアルタイムの推論のために BlazingText または fastText が提供する事前トレーニングされたモデルを使用してトレーニングされたモデルをホスティングします。これらのモデルは教師ありテキスト分類器または教師なし Word2Vec モデルのどちらかです。後者はサブワードの埋め込みでトレーニングしたときに、OOV 単語の表現をリアルタイムで計算するために使用することもできます。NLP モデルのトレーニングデータセットは、すべての可能な単語を含めることができないため、Alexa の意図分類など、リアルタイム推論時に特に有用です。
より広範なレベルで、BlazingText はテキスト分類 (教師ありモード) と Word2Vec ベクトル学習 (Skip-gram、CBOW、batch_skipgram モード) をサポートするようになりました。Skip-gram と CBOW の両方とも、サブワードの埋め込み学習をサポートしています。
BlazingText のさまざまなトレーニングモードが異なるハードウェア構成をサポートしているため、次の表に EC2 インスタンスの互換性をまとめました。
| Word2Vec (教師なし学習) | Text Classification (教師あり学習) | |||
| モード | Skip-gram (サブワードサポート) | CBOW (サブワードサポート) | batch_skipgram | 教師あり |
| シングル CPU インスタンス | ✔ | ✔ | ✔ | ✔ |
| シングル GPU インスタンス (1 つまたは複数の GPU) | ✔ | ✔ | ✔* | |
| 複数の CPU インスタンス | ✔ | |||
* 1 つだけの GPU を利用
それぞれの機能について、詳しく説明します。
サブワード情報を持たせ、豊かな単語ベクトルにする
個々の単語に個別のベクトルを割り当てて単語表現を生成することには、一定の制限があります。未定義 (OOV) 語、つまりトレーニング時に出現しなかった単語は扱うことができません。通常、そのような単語は未知 (UNK) トークンに設定され、同じベクトルが割り当てられますが、OOV 単語が多い場合には、効果的な選択肢ではありません。さらに、これらの表現は単語の形態を無視しており、これによって特にドイツ語、トルコ語、フィンランド語のような形態が豊かな言語では表現力を制限します。
Bojanowski らは文字 n-gram ベクトルの表現を学習し、文字 n-gram ベクトルの和として単語ベクトルを表すことを提案しました。彼らはサブワード情報を考慮した Skip-gram と CBOW モデルの拡張を導入しました。例えば、Skip-gram モデルの中心単語 w は文字 n-gram の袋として表されます。 彼らは単語の最初と最後に特別な境界記号 <and> を追加し、接頭辞と接尾辞を他の文字列と区別できるようにしました。単語 w 自体は n-gram のセットに含まれ、(文字 n-grams に追加して) 各単語の表現を学習します。
例として単語「fast」を取り上げます。最小の文字 n-gram 長さ (アルゴリズム中の min_char パラメータ) を 3、最大の文字 n-gram 長さ (アルゴリズム中の max_char パラメータ) を 6 とすると、「fast」は次の文字 n-gram のベクトルの和として表されます。
‘fast’, ‘<fa’, ‘<fas’, ‘<fast’, ‘<fast>’, ‘fas’, ‘fast>’, ‘ast’, ‘ast>’, ‘st>’
fastText はマルチコア CPU 上でこのメソッドを実装するため、スケーラビリティが制限されます。BlazingText では、カスタム CUDA カーネルを使用して GPU アクセラレーションを活用するためにこのメソッドを拡張しました。
使用
サブワードの埋め込み学習を有効にして調整するために、新たに 3 つのハイパーパラメータを追加しました。
サブワードの埋め込み学習を有効化するには、 subwords パラメータを「true」に設定します。デフォルトでは、 min_char と max_char は Bojanowski et al が提案するようにそれぞれ 3 と 6 に設定されています。
現在、この機能は単一の CPU インスタンスまたは 1 GPU (p3.2xlarge または p2.xlarge) を使用した GPU インスタンスの Skipgram と CBOW モードでサポートされています。速度、精度、コストの点で最高のパフォーマンスを達成するには、p3.2xlarge インスタンスを使用することをお勧めします。
パフォーマンスベンチマーク
p3.2xlarge と c4.2xlarge インスタンスで同じパラメータを使用して BlazingText と fastText の両方をそれぞれトレーニングします。 Stanford rare word dataset (RW) と WS-353 データセットを使用して、単語の類似性/関連性のタスクについての学習された表現の質を評価します。 単語類似度タスクは、与えられた単語に類似する単語を検索します。これらのデータセットには、人間が割り当てた類似性の判断と共に単語ペアが含まれます。学習された単語表現はコサイン類似度に従ってペアを順位付けし、人間の判断を使用して Spearmans 順位相関係数を測定することで評価されます。
10 億語のベンチマークデータセットでトレーニングされた埋め込みの場合、同コストおよび同レベルの精度で、BlazingText は Skip-gram モードの fastText よりも 17 倍高速なことを確認しました。
さらに CBOW は、BlazingText より 14.5 倍高速で、1.5 倍のコストで FastText よりも 10% 以上正確です。BlazingText では Amazon SageMaker 上でコストを計算しますが、fastText ではジョブの期間 Amazon EC2 インスタンスを実行するコストを計算します。
独自のデータセットにサブワードの埋め込み学習を使用して、Word2Vec モデルをトレーニングするには、このノートブックを参照してください。
テキスト分類の高速化
テキスト分類は Web 検索、情報検索、順位付け、文書分類など多くのアプリケーションの自然言語処理で重要なタスクです。 テキスト分類の目的は、テキスト文書を 1 つまたは複数の定義されたカテゴリー (スパム検出、感情分析、ユーザーレビュー分類) に自動的に分類することです。近年、ニューラルネットワークに基づくモデルがますます普及してきています (Johnson et al., 2017, Conneau et al., 2016)。これらのモデルは実践で非常に優れたパフォーマンスを達成しますが、トレーニングとテスト時間の両方で比較的遅く、そのため非常に大きなデータセットで使用が制限されます。
スケーラビリティと精度のバランスを適切に取るため、BlazingText は技術の現状と同程度のパフォーマンスを達成しながら、10 分以内に 10 億語以上のトレーニングができる fastText テキスト分類モデルを実装しています。Amazon SageMaker の BlazingText は CUDA カーネルを使用した GPU アクセラレーションと、早期終了やモデルチューニングなどのアドオンを利用してこのモデルをさらに拡張しており、ユーザーは適切なハイパーパラメータの設定を心配する必要がありません。
次の図はシンプルでパワフルなテキスト分類モデルを示しています。
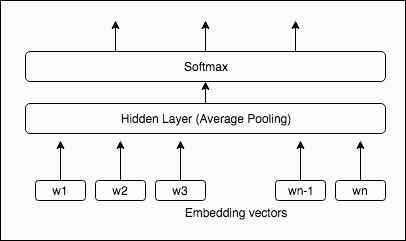
文書内の単語のベクトル表現を得るために、埋め込み行列に対してルックアップが実行されます。次に単語表現はテキスト表現に平均化され、それは線形分類器に提供されます。 テキスト表現は潜在的に再利用できる隠れた変数です。
bag-of-words は単語の順番とは関係がないため、このモデルはローカル語順についての部分的な情報を取得するために追加機能として bag-of-words の n-gram を使用します。 例えば、前図でトレーニングに 2 文字の n-gram を使用すると、ベクトル表現は w1w2、w2w3、….となります。wn-1wn は学習され、個々の単語ベクトルと一緒に隠れ層を計算するために使用されます。これは明らかにハッシュトリックを使用して制限されているメモリ使用量を増やします。単語 n-gram の埋め込み行列サイズは「バケット × vector_dim」に固定されています。バケットの数はデフォルトで 200 万に設定されています。 ハッシュ関数は、ベクトルルックアップ用にバケットインデックスに単語 n-gram をマッピングするために使用されます。
使用
次のハイパーパラメータは BlazingText を使用したテキスト分類用に定義できます。
連続 n 回のエポック後に妥当性精度が向上しない場合に、トレーニングを停止するには、(early_stopping パラメータを真に設定することで) 早期停止を有効化できます。ここで n は許容 (patience パラメータ) のことで、デフォルトでは 4 に設定されています。早期に動作を停止するには、「検証」チャネルで検証データを指定する必要があります。
BlazingText テキスト分類 (「教師あり」モード) は、単一の CPU インスタンスまたは 1 GPU (p3.2xlarge または p2.xlarge) を使用した単一の GPU インスタンスでサポートされています。
詳細については、『BlazingText ドキュメント』および『テキスト分類ノートブック』を参照してください。
事前トレーニングされた fastText モデルのホスティング
トレーニングされたモデルはリアルタイムの推論またはバッチ推論で使用されるまで、役に立ちません。BlazingText を使用してトレーニングされたテキスト分類と Word2Vec モデルのホスティングをサポートすることに加えて、BlazingText はまた、事前にトレーニングされた FastText モデルのホスティングもサポートします。FastText モデルは、数行のコードを使用して簡単にホスティングできます。 fastText モデルファイル (.bin または .vec) を .tar.gz 形式に圧縮し、Amazon S3 にアップロードして、次の行を実行する必要があります。
まとめ
Amazon SageMaker BlazingText ホスティングは、基礎となるテキスト分類または Word2Vec (サブワードあり/なし) モデルを自動的に識別し、リクエストのサービスを開始します。predictor は次の方法で使用できます。
事前トレーニングされた fastText モデルをホスティングする場合には、このノートブックを参照してください。
今回のブログの投稿者について
 Saurabh Gupta は、AWS ディープラーニングの応用科学者です。Saurabh はカリフォルニア大学サンディエゴ校で AI と機械学習の修士号を取得しました。現在、Amazon SageMaker の自然言語処理アルゴリズムの構築に携わっています。
Saurabh Gupta は、AWS ディープラーニングの応用科学者です。Saurabh はカリフォルニア大学サンディエゴ校で AI と機械学習の修士号を取得しました。現在、Amazon SageMaker の自然言語処理アルゴリズムの構築に携わっています。
 Vineet Khare は AWS ディープラーニングのサイエンスマネージャーです。Vineet は、研究最先端の手法を使用して AWS のカスタマーのために人工知能および機械学習アプリケーションを構築することに焦点を当てています。そのかたわらで、読書、ハイキング、家族との時間を楽しんでいます。
Vineet Khare は AWS ディープラーニングのサイエンスマネージャーです。Vineet は、研究最先端の手法を使用して AWS のカスタマーのために人工知能および機械学習アプリケーションを構築することに焦点を当てています。そのかたわらで、読書、ハイキング、家族との時間を楽しんでいます。