Artificial Intelligence
Amazon SageMaker BlazingText: Parallelizing Word2Vec on Multiple CPUs or GPUs
Today we’re launching Amazon SageMaker BlazingText as the latest built-in algorithm for Amazon SageMaker. BlazingText is an unsupervised learning algorithm for generating Word2Vec embeddings. These are dense vector representations of words in large corpora. We’re excited to make BlazingText, the fastest implementation of Word2Vec, available to Amazon SageMaker users on:
- Single CPU instances (like the original C implementation by Mikolov and fastText)
- Single instances with multiple GPUs, P2 or P3
- Multiple CPU instances (distributed CPU training)
On a single p3.2xlarge (1 Volta V100 GPU) instance, BlazingText can be 21 times faster and 20% cheaper than fastText on a single c4.2xlarge instance. For distributed training across multiple CPU nodes, BlazingText can achieve a training speed of up to 50 million words/sec on eight c4.8xlarge instances. This is a speedup of 11 times over one c4.8xlarge fastText CPU implementation, with minimal effect on the quality of the embeddings.
Word2Vec
How do you make search engines tell you about soccer or Barcelona when you search for Messi? How do you make machines understand text data without explicitly defining the relationships between words, so that they can more efficiently perform classification or clustering? The answers lie in creating representations for words that capture their meanings, semantic relationships, and the different types of contexts they’re used in.
Word2Vec is a popular algorithm used for generating dense vector representations of words in large corpora by using unsupervised learning. The resulting vectors have been shown to capture semantic relationships between the corresponding words. The vectors are used extensively for many downstream natural language processing (NLP) tasks like sentiment analysis, named entity recognition, and machine translation.
In the next section, we describe the implementation details. You can jump directly to the Getting started section for examples on how to use the algorithm for three different architectures.
Modeling
Word2Vec is a neural network implementation that learns dense vector representations for words. Other deep or recurrent neural network architectures have also been proposed for learning word representations. However, they take a lot longer to train compared to Word2Vec. It directly tries to predict a word from its neighbors, in terms of learned dense embedding vectors (considered parameters of the model), in an unsupervised way.
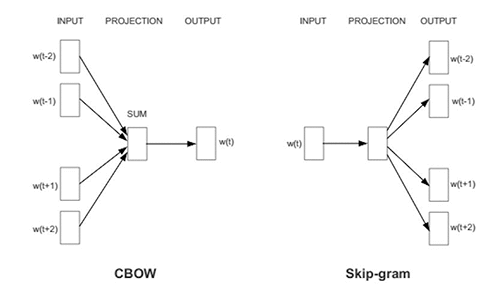
Word2Vec comes in two distinct model architectures: Contextual Bag-Of-Words (CBOW) and Skip-Gram with Negative Sampling (SGNS). The objective of CBOW is to predict a word given its context, whereas skip-gram tries to predict the context given a word. In practice, skip-gram gives better performance but is slower.
The optimization in Word2Vec is done using Stochastic Gradient Descent (SGD), which solves the problem iteratively. At each step, it picks a pair of words, an input word and a target word, either from its window or from a random negative sample. It then computes the gradients of the objective function with respect to the two chosen words, and updates the word representations of the two words based on the gradient values. The algorithm then proceeds to the next iteration, choosing a different word pair.
Distribution on multi-core and many-core architectures
One of the main issues with SGD is that it’s inherently sequential. Because there is a dependency between the update from one iteration and the computation in the next iteration (they might happen to touch the same word representations), each iteration must potentially wait for the update from the previous iteration to complete. This doesn’t allow us to use the parallel resources of the hardware.
HogWild parallel SGD
Hogwild is a scheme where different threads process different word pairs in parallel and ignore any conflicts that might arise in the model update phases. In theory, this can reduce the rate of convergence of algorithms as compared to a sequential run. However, the Hogwild approach has been shown to work well in the case where updates across threads are unlikely to be to the same word. Indeed, for large vocabulary sizes, conflicts are relatively rare and convergence isn’t typically affected.
HogBatch parallel SGD
Most of the Word2Vec implementations are optimized for single node, multi-core CPU architectures. However, these are based on vector-vector operations with Hogwild updates that are memory-bandwidth intensive and don’t efficiently use computational resources.
Shihao Ji and others introduced the idea of HogBatch to improve reuse of various data structures in the algorithm. This is done through the use of minibatching and negative sample sharing. This enables us to express the problem using matrix multiply operations (level 3 BLAS). To scale out Word2Vec on CPUs, BlazingText uses HogBatch and can distribute its computation across nodes in a compute cluster.
Scaling Word2Vec on GPUs
The success of Hogwild/Hogbatch approaches for Word2Vec in case of multi-core and many-core architectures makes this algorithm a good candidate for exploiting GPUs. GPUs provide orders of magnitude more parallelism than CPUs. Amazon SageMaker BlazingText provides an efficient parallelization technique for accelerating Word2Vec using GPUs. The implementation is designed to utilize CUDA multi-threading capabilities optimally, without hurting the output accuracy by over-exploiting GPU parallelism. Careful consideration is given to manage the tradeoff between levels of parallelism and synchronization, so that many threads are not allowed to perform concurrent reads and writes of the same word vectors. This maintains good accuracy while speeding up the training process.
BlazingText also scales out Word2Vec to leverage multiple GPUs by using the data parallelism approach. It does efficient synchronization of model weights across GPUs. For details about the GPU implementation, see the BlazingText paper.
Single-instance modes in BlazingText support both HogWild (CBOW and skip-gram) and HogBatch (batch_skipgram), whereas the distributed CPU mode supports HogBatch Skipgram (batch_skipgram).
The following table summarizes the supported modes on different architectures for Amazon SageMaker BlazingText.
| Hardware type / Mode | CBOW | skip-gram | batch_skipgram |
| Single Instance (CPU) | ✔ | ✔ | ✔ |
| Distributed (CPU) | ✔ | ||
| Single Instance (1 or more GPUs) | ✔ | ✔ |
BlazingText performance on Amazon SageMaker
We benchmark Amazon SageMaker BlazingText against fastText CPU implementation (without subword embeddings). We report the throughput (in million words/sec) and accuracy of learned embeddings on a standard word similarity test set, WS-353.
Hardware: We performed all our experiments on Amazon SageMaker. For BlazingText, we report the performance numbers on single GPU instances (p3.2xlarge, p2.xlarge, p2.8xlarge, and p2.16xlarge) and single/multiple CPU instances (c4.2xlarge and c4.8xlarge). BlazingText was run using CBOW and skip-gram modes on GPU instances and batch_skipgram on CPU instances. We ran fastText using CBOW and skip-gram on single CPU instances.
Note that BlazingText performance is comparable to fastText on single-CPU instances using CBOW and skip-gram. Therefore, we don’t report those numbers here.
Training corpus: We trained our models on the One Billion Word benchmark dataset.
Hyperparameters: For all our experiments, we report the results using CBOW, skip-gram, and batch_skipgram modes (with negative sampling), and fastText’s default parameter settings (vector dimension = 100, window size = 5, sampling threshold = 1e-4, initial learning rate = 0.05).

Throughput Comparison on One Billion Word Benchmark Dataset (Million Words/Sec)
As you can see from the plot, on the same type of hardware, CBOW is the fastest, followed by batch_skipgram and skip-gram. However, CBOW doesn’t give the best accuracy. This is evident when you look at the bubble chart below.

BlazingText Benchmarking – One Billion Words Benchmark Dataset is used for training and WS-353 dataset is used for evaluation
Each circle in the bubble chart represents the performance of a BlazingText or fasttext training job with different algorithm modes and hardware configurations. The radius of the circle is directly proportional to the throughput. The following table captures the details of different jobs that correspond to the job numbers shown in the chart. Because BlazingText can leverage multiple GPUs and distributed computation across multiple CPU instances, it can be several times faster than fasttext. However, to choose the best instance configuration, we need to achieve a balance among the quality of embeddings (accuracy), throughput, and cost. The bubble chart above captures these dimensions.
| Job No. | Implementation | Instance | Instance Count | Mode | Throughput in Million words/s | Accuracy | Cost ($) |
| 1 | fastText | ml.c4.2xlarge | 1 | skip-gram | 1.05 | 0.658 | 1.24 |
| 2 | fastText | ml.c4.8xlarge | 1 | skip-gram | 3.49 | 0.658 | 1.67 |
| 3 | fasttext | ml.c4.2xlarge | 1 | CBOW | 3.62 | 0.6 | 0.41 |
| 4 | fasttext | ml.c4.8xlarge | 1 | CBOW | 12.36 | 0.599 | 0.63 |
| 5 | blazingtext | ml.p2.xlarge | 1 | skip-gram | 2.58 | 0.655 | 1.25 |
| 6 | blazingtext | ml.p2.8xlarge | 1 | skip-gram | 11.82 | 0.635 | 3.1 |
| 7 | blazingtext | ml.p2.16xlarge | 1 | skip-gram | 23.52 | 0.613 | 4.49 |
| 8 | blazingtext | ml.p3.2xlarge | 1 | skip-gram | 22.16 | 0.658 | 0.97 |
| 9 | blazingtext | ml.p2.xlarge | 1 | CBOW | 9.92 | 0.602 | 0.44 |
| 10 | blazingtext | ml.p2.8xlarge | 1 | CBOW | 44.93 | 0.576 | 1.69 |
| 11 | blazingtext | ml.p2.16xlarge | 1 | CBOW | 79.16 | 0.562 | 2.89 |
| 12 | blazingtext | ml.p3.2xlarge | 1 | CBOW | 32.65 | 0.601 | 0.82 |
| 13 | blazingtext | ml.c4.2xlarge | 1 | batch_skipgram | 2.65 | 0.647 | 0.53 |
| 14 | blazingtext | ml.c4.2xlarge | 2 | batch_skipgram | 4.1 | 0.637 | 0.74 |
| 15 | blazingtext | ml.c4.2xlarge | 4 | batch_skipgram | 7.15 | 0.632 | 0.95 |
| 16 | blazingtext | ml.c4.2xlarge | 8 | batch_skipgram | 12.54 | 0.621 | 1.36 |
| 17 | blazingtext | ml.c4.8xlarge | 1 | batch_skipgram | 9.96 | 0.641 | 0.77 |
| 18 | blazingtext | ml.c4.8xlarge | 2 | batch_skipgram | 15.6 | 0.637 | 1.15 |
| 19 | blazingtext | ml.c4.8xlarge | 4 | batch_skipgram | 28.26 | 0.63 | 1.75 |
| 20 | blazingtext | ml.c4.8xlarge | 8 | batch_skipgram | 52.41 | 0.628 | 2.9 |
Performance highlights
While the table presents a more comprehensive view of the trade-offs, below we highlight a few.
- Job 1 versus Job 8: BlazingText on a p3.2xlarge (Volta GPU) instance gives the best performance both in terms of accuracy and cost. It is almost 21 times faster and 20% cheaper than fastText (on c4.2xlarge), and gives the same accuracy.
- Job 2 versus Job 17: BlazingText using batch_skipgram on CPU can be more than 2.5 times faster and 50% cheaper than FastText skipgram, with a small drop in accuracy.
- Jobs 17–20: Use BlazingText with batch_skipgram on multiple CPU instances if the dataset size is extremely large (> 50 GB). Increasing the number of instances results in almost linear speedup with small drops in accuracy. These drops might lie within acceptable limits, depending on the downstream NLP application.
Getting started
BlazingText trains a model based on a text document and returns a file containing the words-to-vectors mapping. Just like other Amazon SageMaker algorithms, it relies on Amazon Simple Storage Service (Amazon S3) to store the training data and the resulting model artifacts. Amazon SageMaker automatically starts and stops Amazon Elastic Compute Cloud (Amazon EC2) instances on behalf of customers during training.
After the model is trained, you can download the resulting word embeddings dictionary from Amazon S3. Unlike other Amazon SageMaker algorithms, you can’t deploy the model to an endpoint, because in this case, the inference is just a vector lookup. For a general, high-level overview of the Amazon SageMaker workflow, see the Amazon SageMaker documentation.
Data formatting
BlazingText expects a single preprocessed text file with space-separated tokens, with each line of the file containing a single sentence. You should concatenate multiple text files into a single file. BlazingText will not perform any text preprocessing steps. Therefore, if the corpus contains “apple” and “Apple”, two different vectors will be generated for them.
Training setup
To start a training job, customers can use either the low-level AWS SDK for Python (Boto3) or the AWS Management Console. After you specify the hardware configuration and hyperparameters, you need to specify the location of the training data on Amazon S3. BlazingText requires that the training data is contained in the “train” channel.
Additional resources
For more information, see the BlazingText documentation. Or for a hands-on walkthrough using this new algorithm from an Amazon SageMaker notebook instance, see the BlazingText example notebook. The notebook shows various modes in which you can use the algorithm and provides some customizable hyperparameters.
About the Authors
 Saurabh Gupta is an Applied Scientist with AWS Deep Learning. He did his MS in AI and Machine Learning from UC San Diego. He is currently working on building Natural Language Processing algorithms for Amazon SageMaker.
Saurabh Gupta is an Applied Scientist with AWS Deep Learning. He did his MS in AI and Machine Learning from UC San Diego. He is currently working on building Natural Language Processing algorithms for Amazon SageMaker.
 Vineet Khare is a Sciences Manager for AWS Deep Learning. He focuses on building Artificial Intelligence and Machine Learning applications for AWS customers using techniques that are at the forefront of research. In his spare time, he enjoys reading, hiking and spending time with his family.
Vineet Khare is a Sciences Manager for AWS Deep Learning. He focuses on building Artificial Intelligence and Machine Learning applications for AWS customers using techniques that are at the forefront of research. In his spare time, he enjoys reading, hiking and spending time with his family.