Amazon Web Services ブログ
Amazon Comprehend Medicalを用いた臨床実体の抽出及び可視化
Amazon Comprehend Medicalは機械学習(ML)を用いて高精度で医療情報を抽出する、HIPAAの対象となっている新サービスです。これは大量の構造化されていない医療テキストを処理するためのコスト、時間、手間を低減します。薬、診断、投与量のような実体や関係を抽出することができ、またPHI(保護医療情報)も抽出することができます。Amazon Comprehend Medicalを利用することで、エンドユーザーは解析が困難な為ほとんど解析目的で利用されることのない生の臨床メモから価値を得ることが可能になります。これらのメモから情報を抽出して電子カルテ(EHR)や治験管理システム(CTMS)のような他の医療システムと統合することには計り知れない価値が存在します。本来なら廃棄されるような生のメモにある情報を考慮することで長期的な患者への視点の生成を可能にします。
他の全ての当社APIレベルサービスと同様、Amazon Comprehend Medicalの焦点は開発者にとっての使い勝手です。当社はAPIコールを利用することで、あるいはコンソールで呼び出すことができる事前訓練済みモデルを提供します。結果は、解析可能かつ他の構造臨床データセットとの統合が可能な、構造化されたJSONファイルとして返されますAmazon Comprehend Medicalについてもっと詳しく知るには、プロダクトマニュアルをご覧ください。
こちらの例では、Amazon Comprehend Medicalを使用してどのように臨床実体を抽出、Kibanaダッシュボード上で視覚化できるかをお見せします。このソリューションはAWS CloudFormationテンプレートとして提供されているのでご自身の環境で簡単にデプロイが可能です。
ソリューションのアーキテクチャ
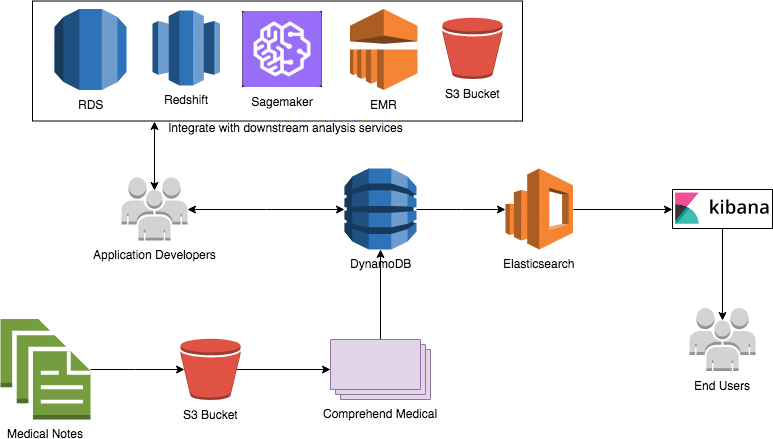
本アーキテクチャ図はソリューションの様々なコンポーネントをショーケースしています。以下は各コンポーネントの詳細です:
- あなたの生の臨床メモを格納するためAmazon S3をプラットフォームとして使用することができます。
- Amazon Comprehend Medical APIを利用して、メモをループスルーして様々な臨床実体や関係をメモから抽出しましょう。また抽出された要素をフィルタリングして、メモからPHI(保護医療情報)を除外することもできます。これは下流分析でメモ内の識別不可能な要素を必要とするユースケースにおいて有用です。
- 抽出された実体を含むJSONファイルは解析されAmazon DynamoDBテーブルに挿入されます。このテーブルは経時的な全臨床実体のリポジトリとして機能し開発者によって下流統合のため利用されることができます。
- DynamoDBテーブルはストリームが接続しています。このストリームはストリーム上のイベントによってトリガーされたAWS Lambda関数を利用して解析されます。
- Lambda関数はAmazon Elasticsearch Service (Amazon ES)ドメインにレコードを挿入します。このドメインは全臨床実体情報によって最新の状態を維持することができます。
- 臨床実体を可視化するためKibanaダッシュボードがAmazon ESの上に構築されています。これはメモに関する分析情報及び検索機能を求めるエンドユーザー向けエントリポイントとして機能します。
ソリューションのデプロイに関する說明
ここではソリューションのデプロイのためAWS CloudFormationスタックを利用します。CloudFormationスタックは本ソリューションによって必要となるリソースを作成します。次が含まれます:
- S3 バケット
- DynamoDB テーブル
- Lambda 関数
- 必要なAWS Identity and Access Management (IAM) のロール
この例では、us-east-1 (バージニア北部)のAWS リージョンを使用します。
IAMのユーザー名とパスワードを使って、AWS マネジメントコンソールにサインインしてください。下の「スタックをローンチ」アイコンを右クリックして新規タブで開きます。
![]()
[テンプレートの選択] ページで、[次へ] を選択します。
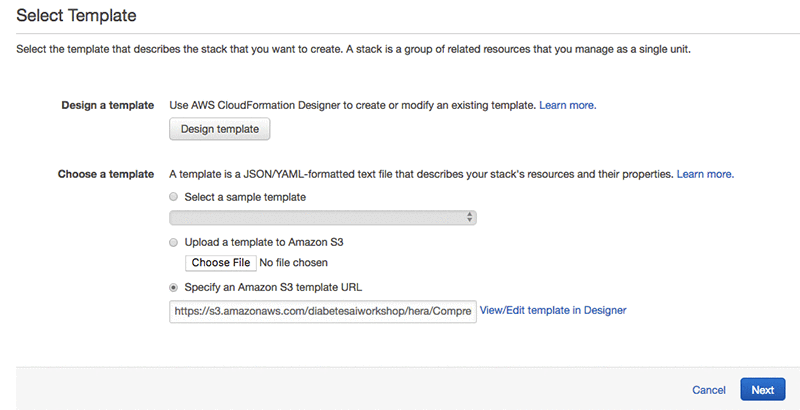
次のページでスタックの名前を提供してください。名前を入力し、 [次へ]を選択します。
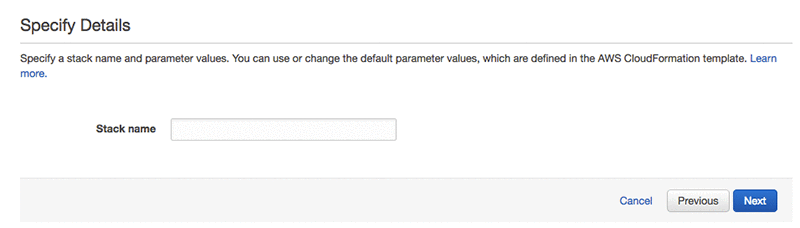
オプションのページでは、全てデフォルトのままにして次へを選択します。
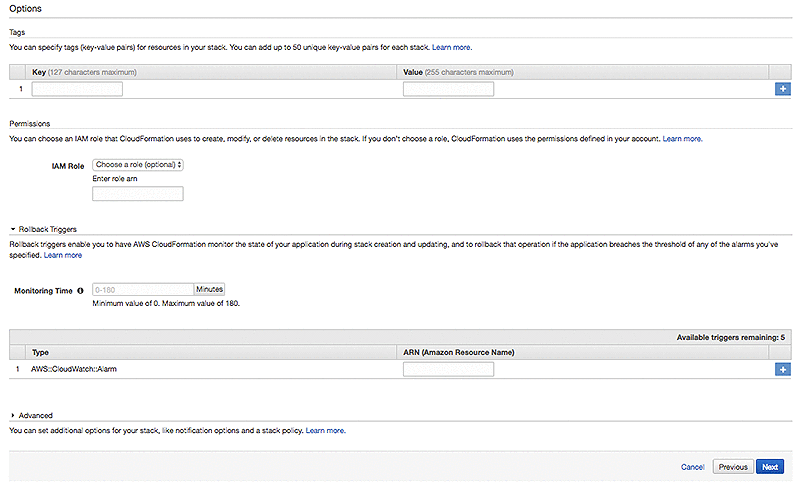
[確認] ページでスクロールダウンして「AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを承認します」のチェックボックスを選択します。 [作成] を選択します。
スタックの実行が完了するのを待ってください。イベント タブでスタック作成プロセスからの様々なイベントを調べることができます。スタック作成の完了後、リソース タブをチェックしてCloudFormationテンプレートによって作成された全リソースを確認することができます。アウトプットタブを開いてCloudFormationスタックのアウトプットを確認できます。
Amazon Elasticsearch ServiceとAWS Lambdaの設定
ここでAmazon Comprehend Medicalを使用して臨床メモの集合から実体を抽出、Kibanaダッシュボード上で視覚化します。
AWSマネジメントコンソールにログインして、こちらのステップに従ってワークショップのこの部分を完了してください。
- Amazon Elasticsearch Serviceを開きます。この例のためあなたが作成したドメインを確認できるはずです。選択して下さい。
- 概要のタブで、エンドポイントURLをコピーしてノートパッドに貼り付けてください。下のステップ10でこれを使用します。
- アクセスポリシーを変更するを選択してください

- テンプレートの選択のドロップダウンで、1つ以上のAWSアカウント及びIAMユーザーへのアクセスを許可または拒否を選択します。

- ポップアップウインドウで、アカウントIDまたはARNのテキストボックスでアカウントIDを貼り付けて下さい。Okをクリックしてください

- アクセスポリシーがあなたのため自動で生成されます。確認して、送信を選択して下さい。

- AWS Lambdaコンソールへ移動して下さい。
- 関数のリストで、ワークショップのため作成された関数を選択してください。
- 関数のコードを含むセクションへとスクロールダウンして下さい。
- 13行目で、hostという名前の変数がElasticsearchのホスト名に設定されているのを確認できます。前にステップ2でコピーしたホスト名でそれを置き換えてください。シングルクォートの間に配置するのを忘れないでください。

- [Save] を選択します。
ローカル環境の設定
Amazon Comprehend Medicalを使用して生のメモから実体を抽出するPythonプログラムを実行し、それらの実体をDynamoDBテーブルに挿入します。このプログラムを実行する前に環境の設定を行う必要があります。プログラムの実行に先立って、確実に次の各設定タスクを完了して下さい。
- AWS コマンドラインインターフェイス(CLI) のインストールを完了し管理者権限でIdentity and Access Management (IAM)ユーザーを設定 して下さい。AWS CLIを設定する各ステップを確認するにはこちらのリンクをクリックしてください。
- コンピュータ―上でフォルダを作成してその中に このZIPファイルをダウンロードして下さい。ファイルを解凍(Unzip)してください。
- 新しいフォルダ、Blog_Codeが作成されます。notesのフォルダに移動して、メモファイルの一つを開き、構造化されていないメモが実際にどのように見えるのか見るため内容を調べます。こちらはfile1.txtのスクリーンショットです。

- <> ディレクトリに戻って、下のスクリーンショットのようにpythonファイルを開いてあなたのDynamoDBテーブルの名前を7行目の“your_table_name_here”を置き換える形でシングルクォートの間に貼り付けます。

- pythonプログラムを実行する用意ができました。以下をタイピングしてプログラムを実行してください:
本プログラムはダウンロードされたメモから各実体を抽出してDynamoDBにそれらを挿入します。完了すると、次のメッセージが表示されます:

Kibanaでの各実体の可視化
- AWS マネジメントコンソールでDynamoDBコンソールに移動します。
- 左側ナビゲーションペインから テーブルを選択します。
- CloudFormationスタックによって自動であなたのため作成されたテーブル名を選択してください。CloudFormationコンソールで、CloudFormationスタックのアウトプットのタブにてテーブル名を取得できます。
- 概要のタブで最新ストリームARNという値を見ることができます。これはこのDynamoDBテーブルにストリームが関連付けられていることを表しています。
- アイテムを選択して下さい
- メモから抽出された実体を確認することができます。カテゴリ、タイプ、あるいは信頼スコアのような属性も取得することができます。加えて、各実体に関連した属性や特性のリストも取得できます。

- さあ、これらの実体をKibanaで視覚化しましょう。それを行うには、aws-es-kibanaと呼ばれるオープンソースプロキシを使用します。GitHubレポジトリ上にある各ステップに従ってあなたのコンピュータ上でプロキシをインストールして下さい。
- インストール完了後、次のコマンドを実行します:
CloudFormationスタックのアウトプットのタブでドメインエンドポイントを見つけることができます。以下のような出力を確認できるはずです:

- KibanaからURLをコピーして、ブラウザのウインドウに貼り付けてください。Kibanaダッシュボードが開きます。Index pattern のテキストボックスで、lambda-index とタイプして作成を選択します。

- Kibanaでフィールド名と属性名を見ることができ、ここで私達は視覚化を構築していきます。

- Kibanaはダッシュボードへの統合が可能な、複数の視覚化を構築するオプションを提供します。Kibaanの右ナビゲーションペインの視覚化とダッシュボードの各リンクでこれらのオプションを実験することができます。 始めやすいように、あなたのため、基本例としてダッシュボードをあらかじめ構築しました。ダッシュボードファイルをインポートして結果を視覚化するにはこれらの各ステップに従ってください。
- 左のナビゲーションペインで、マネジメント をクリックした後 保存されたオブジェクトをクリックしてください。

- 右上にある インポートをクリックして 、あなたが先ほどダウンロードして解凍したBlog_Codeフォルダ下のEntity_Dashboard.jsonのファイルに移動します。

- 上書きしたいかという質問のポップアップメッセージが現れます。はい、全て上書きするを選択してください。

- もう一つの、「一部のインデックスパターンが存在しません」というポップアップウインドウが現れます。ドロップダウンの新規インデックスパターンのリストでラムダインデックスが選択されていることを確認して、すべての変更を確認をクリックして下さい。EntityDashboardという名前の新しいダッシュボードを確認できます。

- 左のナビゲーションペインで、ダッシュボードをクリックしてEntityDashboardのリンクもクリックしてください。抽出された各実体から生成された視覚化をダッシュボードにて確認できます。

こちらはダッシュボードでの3つの視覚化です。左上の視覚化は異なるカテゴリのカウントを集めたものです。見ての通り、私達のサンプルメモでは最も上のカテゴリとして病状があります。右上の視覚化は実体のタイプの分布をキャプチャしたパイチャートです。下の視覚化はメモから抽出された最も一般的な用語を教える用語クラウドです。自分自身の視覚化ダッシュボードを構築するための異なる視覚化やオプションを試すことができます。
結論
ブログ投稿の例で、Amazon Comprehend Medicalを使用してどのように臨床実体を抽出、Kibanaダッシュボード上で視覚化できるかを見ました。当社はこの各実体を抽出する機能によって可能となる多数のユースケースを予想しています。一部の例にはこれらがあります:
- 患者と人工健康の分析: 構造化されていないデータはマイニングが困難です。
例:ICUの臨床チームは一日に120回以上ケアに関する決定を行いますーどうやって継続していくのか? - 収益サイクル管理: 医療用コーディング: コーディングのプロセス、あるいは国際疾病分類(ICD)に基づく患者記録の分類は最も複雑な取引のひとつです。
- ファーマコビジランス: 薬物有害反応または有害事象の報告の複数ルート。
- PHIコンプライアンス : HIPAA準拠及びPHIの技術的要件を維持するのは難しい。
- 臨床試験管理:臨床試験に適した患者を迅速に特定。
医療フォームから情報を抽出しそれをComrehend Medicalに分析目的で渡すためにAmazon Comprehend MedicalをOCR(光学式文字認識)システムのような上流サービスと組み合わせることも可能です。下流分析において、顧客は出力を臨床データウェアハウスへ統合しメディケアとメディケイドサービスセンター(CMS)の品質対策に関する報告を改善することができます。
Amazon Comprehend Medicalはまた、死亡リスクの予測や再入院の予測のような一般的な問題についてあなたがEHRシステムで生の臨床データの機械学習モデルを構築するのを可能にします。これらは構造化された臨床データを主に用いて構築されたモデルであり、生の臨床メモからの属性を追加することで結果を改善することができます。
多数の可能性が存在しており、Amazon Comprehend Medicalがいかに皆さん自身のユースケースのため利用されているかに私達は興奮しています。
免責事項: Amazon Comprehend Medicalの次のガイドラインと制限についてお見知り置き下さい。 https://docs.aws.amazon.com/comprehend/latest/dg/guidelines-and-limits-med.html
本ブログ投稿で使用されたメモはhttps://www.mtsamples.com/からのものです。
著者について
 ウジワルはアマゾンウェブサービスグローバルヘルスケア&生命科学チームのプリンシパル機械学習スペシャリストソリューションアーキテクトです。彼は医療用画像処理、非構造化臨床テキスト、ゲノミクス、精密医療、臨床試験、および医療の質の向上など、実社会の業界の問題への機械学習と深層学習の適用に取り組んでいます。また、加速されたトレーニングや推論のためのAWSクラウド上での機械学習/深層学習の学習アルゴリズムのスケーリングに関する専門知識を持っています。自由な時間には音楽の鑑賞(と演奏)そして家族との計画外のロードトリップを楽しんでいます。
ウジワルはアマゾンウェブサービスグローバルヘルスケア&生命科学チームのプリンシパル機械学習スペシャリストソリューションアーキテクトです。彼は医療用画像処理、非構造化臨床テキスト、ゲノミクス、精密医療、臨床試験、および医療の質の向上など、実社会の業界の問題への機械学習と深層学習の適用に取り組んでいます。また、加速されたトレーニングや推論のためのAWSクラウド上での機械学習/深層学習の学習アルゴリズムのスケーリングに関する専門知識を持っています。自由な時間には音楽の鑑賞(と演奏)そして家族との計画外のロードトリップを楽しんでいます。