この記事では、レポート作成ワークロードをオンライントランザクション処理 (OLTP) データベースから Amazon Athena および Amazon S3 にオフロードすることによってパフォーマンスを向上させ、コストを削減できる方法について説明します。説明するアーキテクチャはレポート作成システムを実装するもので、到着時にクエリできるようにして、受け取るデータを理解することを可能にします。このソリューションでは以下が行われます。
- ソース上で変更が行われるたびに、Oracle GoldenGate がターゲットに新しい行を生成し、緩やかに変化するディメンションのタイプ 2 (SCD タイプ 2) データを作成します。
- Athena が SCD タイプ 2 データでのアドホッククエリの実行を可能にします。
最新のレポート作成ソリューションの原則
高度なデータベースソリューションは、コスト効率の良いレポート作成ソリューションを構築できるように原則のセットを使用します。これらの原則には以下のようなものがあります。
- OLTP からレポート作成アクティビティを分離する。このアプローチは、リソースの分離を提供し、データベースがそれぞれのワークロードをスケールできるようにします。
- Hadoop Distributed File System (HDFS) および Amazon S3 などのクラウドプロジェクトストアといった分散ファイルシステムの上で実行されるクエリエンジンを使用する。オープンソース HDFS とクラウドオブジェクトストアの上で実行できるクエリエンジンの到来は、専用レポート作成システムの実装コストをさらに削減します。
また、レポート作成ソリューションの構築時にはこれらの原則を使用できます。
- 商用データベースのライセンスコストを削減するため、レポート作成アクティビティをオープンソースデータベースに移動させる。
- ソースシステムからの OLTP データをレプリケートでき (リアルタイムモードが望ましい)、データの現行ビューを提供する、ログベースでリアルタイムの変更データキャプチャ (CDC) を使用したデータ統合ソリューションシステムを使用する。ソースおよびターゲットのレポート作成システム間におけるデータレプリケーションは、CDC ソリューションを使用して有効化できます。トランザクションログベースの CDC ソリューションは、ソースデータベースから非侵襲的にデータベースの変更をキャプチャし、それらをターゲットデータストアまたはファイルシステムにレプリケートします。
前提条件
GoldenGate と Kafka を併用しており、クラウド移行を検討しているという場合は、この記事が役に立ちます。この記事では、GoldenGate に関する予備知識も前提としており、GoldenGate をインストールして設定する手順は詳しく説明しません。また、Java および Maven に関する知識も前提としています。手動デプロイメントのために、3 つのサブネットを持つ VPC が利用できることも確認してください。
このソリューションのアーキテクチャの理解
以下のワークフロー図 (図 1) は、この記事で説明するソリューションを解説するものです。
- Amazon RDS for Oracle がソースとして機能します。
- GoldenGate CDC ソリューションが Amazon Managed Streaming for Apache Kafka (Amazon MSK) のためのデータを生成します。GoldenGate がデータベースの CDC データをコンシューマーにストリームします。MSK クラスターの Kafka トピックが GoldenGate からデータを受け取ります。
- Amazon EMR で実行されている Apache Flink アプリケーションがそのデータを取り込み、それを S3 バケットに sink します。
- Athena がクエリを通じてデータを分析します。オプションとして、Amazon Redshift Spectrum からクエリを実行することができます。
データパイプライン

図 1
Amazon MSK は Apache Kafka 向けの完全マネージド型サービスで、サーバーやストレージをプロビジョニングしたり、Apache Zookeeper を手動で設定したりする必要なく、数回クリックするだけで Kafka クラスターを簡単にプロビジョニングできます。Kafka は、リアルタイムストリーミングデータのパイプラインとアプリケーションを構築するためのオープンソースプラットフォームです。
Amazon RDS for Oracle は完全マネージド型データベースで、プロビジョニング、バックアップ、ソフトウェアパッチの適用、モニタリング、ハードウェアスケーリングなどの時間のかかるデータベース管理タスクを管理して時間を節約し、ユーザーがアプリケーション開発に集中することを可能にします。
GoldenGate は、リアルタイムかつログベースの異種間データベース CDC ソリューションです。GoldenGate は、あらゆる対応データベースからのさまざまなターゲットデータベース、または Kafka のようなビッグデータプラットフォームへのデータレプリケーションをサポートします。区切りテキスト、JSON、および Avro などのソースから取得された異なる形式のトランザクションデータを書き込む GoldenGate の機能は、各種 BI ツールとのシームレスな統合を可能にします。各行には、データベースの操作タイプ (Insert/Update/Delete) を含めた追加のメタデータ列があります。
Flink はオープンソースのストリーム処理フレームワークで、バインドされたストリームとバインドされていないストリームのステートフルな計算のための分散ストリーミングデータフローエンジンを備えています。EMR は Flink をサポートするため、AWS マネジメントコンソールからマネージドクラスターを作成することができます。また、Flink は チェックポインティング機能での 1 回限りのセマンティクスもサポートします。これは、データベースの CDC データを処理する時に、データの正確性を確保するために欠かせません。Flink は、ストリーミングデータを行ごとに変換、またはウィンドウ生成機能を使用してバッチ単位で変換するためにも使用できます。
S3 は、優れたスケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを備えたオブジェクトストレージサービスです。Athena などの AWS インプレースクエリサービスを使って、S3 オブジェクト全体でビッグデータ分析を実行することができます。
Athena は、S3 にあるデータのクエリと分析を容易にするサーバーレスクエリサービスです。Athena、および S3 (データソース) では、標準 SQL を使用してスキーマを定義し、クエリを開始します。分析のためのデータの準備に複雑な ETL ジョブは必要ないため、SQL スキルを持つ人なら誰でも、簡単に大規模なデータセットを素早く分析できます。
以下の図は、データパイプラインをより詳しく説明したものです。
- 単一の AZ で実行される RDS for Oracle。
- Amazon EC2 インスタンスで実行される GoldenGate。
- 3 つのアベイラビリティーゾーンにまたがる MSK クラスター。
- MSK 内に設定される Kafka トピック。
- EMR クラスターで実行される Flink。
- Oracle DB および GoldenGate インスタンスのためのプロデューサーセキュリティグループ。
- Flink を使用する EMR のためのコンシューマーセキュリティグループ。
- S3 プライベートアクセスのためのゲートウェイエンドポイント。
- GoldenGate インスタンスにソフトウェアをダウンロードするための NAT ゲートウェイ。
- S3 バケットと Athena。
簡素化のため、このセットアップでは複数のサブネットを持つ単一の VPC を使ってリソースをデプロイします。
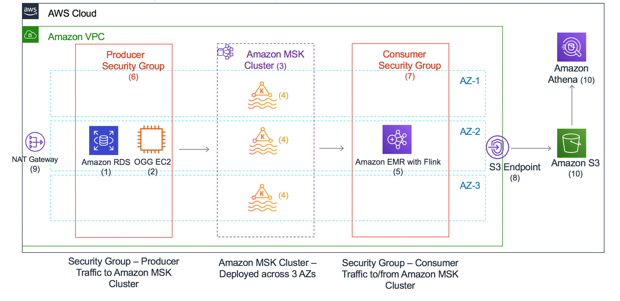
図 2
AWS CloudFormation を使ったシングルクリックデプロイメントの設定
この記事に含まれる AWS CloudFormation テンプレートは、このブログ記事で説明するエンドツーエンドソリューションのデプロイメントを自動化します。このテンプレートは、RDS for Oracle、MSK、EMR、S3 バケットを含めた必要なリソースのすべてをプロビジョニングすると共に、MSK 上の Kafka トピックからのメッセージを取り込むための JAR ファイルを伴う EMR ステップも追加します。テンプレートを起動して、ソリューションをテストするためのステップのリストは以下の通りです。
- us-east-1 で AWS CloudFormation テンプレートを起動します。

- スタックが正常に作成されたら、CloudFormation の [出力] タブから GoldenGate ハブサーバーのパブリック IP を取得します。
- ステップ 2 からの IP アドレスを使用し、ec2-user として GoldenGate ハブサーバーにログインしてから、Oracle ユーザーの
sudo su – oracle に切り替えます。
- sqlplus クライアントを使用してソースの RDS for Oracle データベースに接続し、パスワード (ソース) を提供します。
[oracle@ip-10-0-1-170 ~]$ sqlplus source@prod
- Oracle ユーザーのホームディレクトリで利用可能な SQL ステートメントを使用して、データベーストランザクションを生成します。
SQL> @s
SQL> @s1
SQL> @s2
- Amazon Athena コンソールから STOCK_TRADES テーブルをクエリします。Athena がデータベースの変更をクエリに使用できるようになるには、ソースデータベースにトランザクションをコミットしてから数秒かかります。
コンポーネントの手動でのデプロイメント
次のステップは、Oracle が変更したデータを MSK にストリーミングし、EMR で実行される Flink を使用してそのデータを S3 バケットに sink するために必要な設定を説明するものです。その後、Athena を使用して S3 バケットをクエリできます。以前のステップで説明したように AWS CloudFormation を使用してソリューションをデプロイした場合は、「ソリューションのテスト」セクションに進んでください。
- GoldenGate を使用して CDC 用の RDS ソースデータベースを準備します。RDS ソースデータベースのバージョンは Enterprise Edition 12.1.0.2.14 です。RDS データベースの設定手順については、「Amazon RDS での Oracle GoldenGate の使用」を参照してください。この記事では、データ定義言語 (DDL) のキャプチャは考慮しません。
- GoldenGate ハブサーバー用の EC2 インスタンスを設定します。us-east-1 リージョンに Oracle Linux Server 7.6 (ami-b9c38ad3) イメージを使って GoldenGate ハブサーバーを設定します。GoldenGate ハブサーバーは、データベースのトランザクションログファイルから変更をリアルタイムで抽出する GoldenGate の Extract プロセスを実行します。また、サーバーはデータベースの変更を MSK にパブリッシュする Replicat プロセスも実行します。GoldenGate ハブサーバーには、以下のソフトウェアコンポーネントが必要です。
- MSK を使用して Kafka クラスターを作成し、Kakfa トピックを設定します。MSK クラスターは、AWS マネジメントコンソールから AWS CLI を使用して、または AWS CloudFormation テンプレート経由で作成できます。
- クラスターを作成したら、list-clusters コマンド を使用して ClusterArn および Zookeeper 接続文字列を取得します。この情報は、GoldenGate Big Data アダプタと Flink コンシューマーの設定に必要です。以下のコードは、実行するコマンドを示しています。
$aws kafka list-clusters --region us-east-1
{
"ClusterInfoList": [
{
"EncryptionInfo": {
"EncryptionAtRest": {
"DataVolumeKMSKeyId": "arn:aws:kms:us-east-1:xxxxxxxxxxxx:key/717d53d8-9d08-4bbb-832e-de97fadcaf00"
}
},
"BrokerNodeGroupInfo": {
"BrokerAZDistribution": "DEFAULT",
"ClientSubnets": [
"subnet-098210ac85a046999",
"subnet-0c4b5ee5ff5ef70f2",
"subnet-076c99d28d4ee87b4"
],
"StorageInfo": {
"EbsStorageInfo": {
"VolumeSize": 1000
}
},
"InstanceType": "kafka.m5.large"
},
"ClusterName": "mskcluster",
"CurrentBrokerSoftwareInfo": {
"KafkaVersion": "1.1.1"
},
"CreationTime": "2019-01-24T04:41:56.493Z",
"NumberOfBrokerNodes": 3,
"ZookeeperConnectString": "10.0.2.9:2181,10.0.0.4:2181,10.0.3.14:2181",
"State": "ACTIVE",
"CurrentVersion": "K13V1IB3VIYZZH",
"ClusterArn": "arn:aws:kafka:us-east-1:xxxxxxxxx:cluster/mskcluster/8920bb38-c227-4bef-9f6c-f5d6b01d2239-3",
"EnhancedMonitoring": "DEFAULT"
}
]
}
- ClusterArn を使用して、Kafka ブローカーノードの IP アドレスを取得します。
$aws kafka get-bootstrap-brokers --region us-east-1 --cluster-arn arn:aws:kafka:us-east-1:xxxxxxxxxxxx:cluster/mskcluster/8920bb38-c227-4bef-9f6c-f5d6b01d2239-3
{
"BootstrapBrokerString": "10.0.3.6:9092,10.0.2.10:9092,10.0.0.5:9092"
}
- Kafka トピックを作成します。この記事のソリューションは、Kafka トピックにテーブルと同じ名前を使用します。
./kafka-topics.sh --create --zookeeper 10.0.2.9:2181,10.0.0.4:2181,10.0.3.14:2181 --replication-factor 3 --partitions 1 --topic STOCK_TRADES
- Flink を使用して EMR クラスターをプロビジョニングします。Flink 1.8.0 で EMR 5.25 クラスター (EMR クラスターの高度なオプション) を作成し、マスターノードへの SSH アクセスを有効にします。Flink コンシューマーが MSK クラスター内の Kafka トピックにアクセスできるように、ロールを作成して EMR マスターノードにアタッチします。
- GoldenGate ハブサーバーで Kafka 用の Oracle GoldenGate Big Data アダプタを設定します。Oracle GoldenGate ダウンロードリンクを使用して Oracle GoldenGate Big Data アダプタ (12.3.0.1.0) をダウンロードし、インストールします。詳細については、Oracle GoldenGate 12c (12.3.0.1) インストールドキュメントを参照してください。以下は、GoldenGate の Kafka プロデューサープロパティファイル (custom_kafka_producer.properties) です。
#Bootstrap broker string obtained from Step 3
bootstrap.servers= 10.0.3.6:9092,10.0.2.10:9092,10.0.0.5:9092
#bootstrap.servers=localhost:9092
acks=1
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
# 100KB per partition
batch.size=16384
linger.ms=0
以下は、GoldenGate の Kafka プロパティファイル (Kafka.props) です。
gg.handlerlist = kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
#The following resolves the topic name using the short table name
#gg.handler.kafkahandler.topicName=SOURCE
gg.handler.kafkahandler.topicMappingTemplate=${tableName}
#The following selects the message key using the concatenated primary keys
gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys}
gg.handler.kafkahandler.format=json_row
#gg.handler.kafkahandler.format=delimitedtext
#gg.handler.kafkahandler.SchemaTopicName=mySchemaTopic
#gg.handler.kafkahandler.SchemaTopicName=oratopic
gg.handler.kafkahandler.BlockingSend =false
gg.handler.kafkahandler.includeTokens=false
gg.handler.kafkahandler.mode=op
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
#gg.log.level=INFO
gg.log.level=DEBUG
gg.report.time=30sec
gg.classpath=dirprm/:/home/oracle/kafka/kafka_2.11-1.1.1/libs/*
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar
以下は、GoldenGate の Replicat パラメータファイル (rkafka.prm) です。
REPLICAT rkafka
-- Trail file for this example is located in "AdapterExamples/trail" directory
-- Command to add REPLICAT
-- add replicat rkafka, exttrail AdapterExamples/trail/tr
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
MAP SOURCE.STOCK_TRADES, TARGET SOURCE.STOCK_TRADES;
- 以下のディレクトリ名を使って、Flink が Oracle CDC データを保存 (sink) するための S3 バケットとディレクトリを作成します。
- CDC データを S3 バケットに書き込む Kafka トピックから読み込むように Flink コンシューマーを設定します。Maven アーキタイプを使用して Flink プロジェクトをセットアップするための手順については、Flink Project Build Setup を参照してください。以下のコード例は、Maven プロジェクトで使用した pom.xml ファイルです。詳細については、Getting Started with Maven を参照してください。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-quickstart-java</artifactId>
<version>1.8.0</version>
<packaging>jar</packaging>
<name>flink-quickstart-java</name>
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<slf4j.version>@slf4j.version@</slf4j.version>
<log4j.version>@log4j.version@</log4j.version>
<java.version>1.8</java.version>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.8.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.8.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-s3-fs-presto</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_2.11</artifactId>
<version>2.4.20</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-protobuf_2.11</artifactId>
<version>2.4.20</version>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<!-- Excludes here -->
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>org.apache.flink:*</artifact>
</filter>
</filters>
<transformers>
<!-- add Main-Class to manifest file -->
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>flinkconsumer.flinkconsumer</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
</transformers>
<relocations>
<relocation>
<pattern>org.codehaus.plexus.util</pattern>
<shadedPattern>org.shaded.plexus.util</shadedPattern>
<excludes>
<exclude>org.codehaus.plexus.util.xml.Xpp3Dom</exclude>
<exclude>org.codehaus.plexus.util.xml.pull.*</exclude>
</excludes>
</relocation>
</relocations>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
</execution>
</executions>
</plugin>
<!-- Add the main class as a manifest entry -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.5</version>
<configuration>
<archive>
<manifestEntries>
<Main-Class>flinkconsumer.flinkconsumer</Main-Class>
</manifestEntries>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<profiles>
<profile>
<id>build-jar</id>
<activation>
<activeByDefault>false</activeByDefault>
</activation>
</profile>
</profiles>
</project>
mvn クリーンインストールを使用して以下の Java プログラムをコンパイルし、JAR ファイルを生成します。
package flinkconsumer;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.TypeExtractor;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.util.serialization.DeserializationSchema;
import org.apache.flink.streaming.util.serialization.SerializationSchema;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.slf4j.LoggerFactory;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import akka.actor.ActorSystem;
import akka.stream.ActorMaterializer;
import akka.stream.Materializer;
import com.typesafe.config.Config;
import org.apache.flink.streaming.connectors.fs.*;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.runtime.fs.hdfs.HadoopFileSystem;
import java.util.stream.Collectors;
import java.util.Arrays;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.regex.Pattern;
import java.io.*;
import java.net.BindException;
import java.util.*;
import java.util.Map.*;
import java.util.Arrays;
public class flinkconsumer{
public static void main(String[] args) throws Exception {
// create Streaming execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setBufferTimeout(1000);
env.enableCheckpointing(5000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.0.3.6:9092,10.0.2.10:9092,10.0.0.5:9092");
properties.setProperty("group.id", "flink");
properties.setProperty("client.id", "demo1");
DataStream<String> message = env.addSource(new FlinkKafkaConsumer<>("STOCK_TRADES", new SimpleStringSchema(),properties));
env.enableCheckpointing(60_00);
env.setStateBackend(new FsStateBackend("hdfs://ip-10-0-3-12.ec2.internal:8020/flink/checkpoints"));
RollingSink<String> sink= new RollingSink<String>("s3://flink-stream-demo/STOCK_TRADES");
// sink.setBucketer(new DateTimeBucketer("yyyy-MM-dd-HHmm"));
// The bucket part file size in bytes.
sink.setBatchSize(400);
message.map(new MapFunction<String, String>() {
private static final long serialVersionUID = -6867736771747690202L;
@Override
public String map(String value) throws Exception {
//return " Value: " + value;
return value;
}
}).addSink(sink).setParallelism(1);
env.execute();
}
}
Hadoop ユーザーとして EMR マスターノードにログインし、Flink を起動して、JAR ファイルを実行します。
$ /usr/bin/flink run ./flink-quickstart-java-1.7.0.jar
- Athena コンソールから stock_trades テーブルを作成します。JSON ドキュメントは、それぞれ新しい行に配置する必要があります。
CREATE EXTERNAL TABLE `stock_trades`(
`trade_id` string COMMENT 'from deserializer',
`ticker_symbol` string COMMENT 'from deserializer',
`units` int COMMENT 'from deserializer',
`unit_price` float COMMENT 'from deserializer',
`trade_date` timestamp COMMENT 'from deserializer',
`op_type` string COMMENT 'from deserializer')
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION
's3://flink-cdc-demo/STOCK_TRADES'
TBLPROPERTIES (
'has_encrypted_data'='false',
'transient_lastDdlTime'='1561051196')
詳細については、「Hive JSON SerDe」を参照してください。
ソリューションのテスト
ソリューションが機能することをテストするには、以下のステップを完了してください。
- GoldenGate ハブサーバーからソース RDS インスタンスにログインし、stock_trades テーブルで insert、update、および delete 操作を実行します。
$sqlplus source@prod
SQL> insert into stock_trades values(6,'NEW',29,75,sysdate);
SQL> update stock_trades set units=999 where trade_id=6;
SQL> insert into stock_trades values(7,'TEST',30,80,SYSDATE);
SQL>insert into stock_trades values (8,'XYZC', 20, 1800,sysdate);
SQL> commit;
- 以下の stats コマンドを使用して、ソースデータベースからの GoldenGate キャプチャを監視します。
[oracle@ip-10-0-1-170 12.3.0]$ pwd
/u02/app/oracle/product/ogg/12.3.0
[oracle@ip-10-0-1-170 12.3.0]$ ./ggsci
Oracle GoldenGate Command Interpreter for Oracle
Version 12.3.0.1.4 OGGCORE_12.3.0.1.0_PLATFORMS_180415.0359_FBO
Linux, x64, 64bit (optimized), Oracle 12c on Apr 16 2018 00:53:30
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2018, Oracle and/or its affiliates.All rights reserved.
GGSCI (ip-10-0-1-170.ec2.internal) 1> stats eora2msk
- 以下を使用して Kafka トピックへの GoldenGate Replicat を監視します。
[oracle@ip-10-0-1-170 12.3.0]$ pwd
/u03/app/oracle/product/ogg/bdata/12.3.0
[oracle@ip-10-0-1-170 12.3.0]$ ./ggsci
Oracle GoldenGate for Big Data
Version 12.3.2.1.1 (Build 005)
Oracle GoldenGate Command Interpreter
Version 12.3.0.1.2 OGGCORE_OGGADP.12.3.0.1.2_PLATFORMS_180712.2305
Linux, x64, 64bit (optimized), Generic on Jul 13 2018 00:46:09
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2018, Oracle and/or its affiliates.All rights reserved.
GGSCI (ip-10-0-1-170.ec2.internal) 1> stats rkafka
- Athena コンソールを使用して stock_trades テーブルをクエリします。
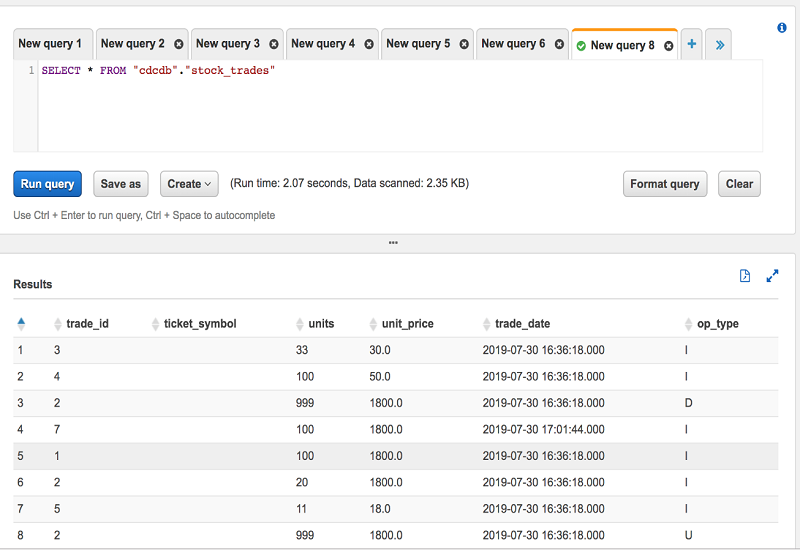
まとめ
この記事では、レポート作成アクティビティを Athena と S3 にオフロードして、レポート作成コストを削減し、ソースデータベースでの OLTP パフォーマンスを向上させる方法について説明しました。この記事は、ステージング環境でソリューションをセットアップするためのガイドとして機能します。
このソリューションの本番環境へのデプロイメントには、GoldenGate ハブサーバーの高可用性、最適なクエリパフォーマンスのための異なるファイルエンコーディング形式、およびセキュリティなどの追加の考慮事項が必要になる場合があります。また、データベースの CDC のために GoldenGate、および S3 sink のために Kafka Connect を使用する代わりに、AWS Database Migration Service といったテクノロジーを使用することで同様の結果を達成することも可能です。
著者について
 Sreekanth Krishnavajjala はアマゾン ウェブ サービスのソリューションアーキテクトです。
Sreekanth Krishnavajjala はアマゾン ウェブ サービスのソリューションアーキテクトです。
 Vinod Kataria はアマゾン ウェブ サービスのシニアパートナーソリューションアーキテクトです。
Vinod Kataria はアマゾン ウェブ サービスのシニアパートナーソリューションアーキテクトです。