Amazon Web Services ブログ
動的なDeepLearningによる時系列データの予測
時間の経過とともに展開していくイベントを予測することは、オプション価格決定や、病気の進行、音声認識、サプライチェーン管理などを扱う多くのアプリケーションにとって不可欠な機能です。と同時に、こうした予測は難しいことでも知られています。 全体的な結果を予測するのではなく、特定の時刻に発生するイベントの一連の動き ( シーケンス ) を正確に予測することを目指します。物理学のノーベル賞受賞者である Niels Bohr 氏は、「予測は非常に難しいもので、未来については特にそうです。」と述べています。 このブログ記事では、AWS での深層学習アプローチを使用した時系列予測の高度なテクニックについて見ていきます。この投稿では、任意の時系列値予測に注目します。ですので、時系列を研究している読者にとって興味深い内容になるでしょう。またこの投稿では、読者が機械学習の分野で基礎的な技術知識をすでに持っていることを仮定しています。
Amazon SageMaker (Bring-Your-Own-Algorithm を使用 ) を活用して、複数の要因の過去の傾向に基づく時系列を予測する、独自の RNN ( リカレントニューラルネットワーク ) 深層学習アルゴリズムを開発していきます。Amazon SageMaker は完全マネージド型の機械学習プラットフォームで、データサイエンティストや開発者が機械学習モデルを素早くかつ簡単に構築し、大規模な実稼動アプリケーションとなるようにトレーニングするのををサポートします。これにより、ビルトインアルゴリズムとビルトインフレームワークの両方を使用できるようになり、Docker コンテナを使ったカスタムコードをインポートすることも可能になります。
カスタムアルゴリズムの開発後は、ベンチマーク分析を実行し、パフォーマンスを評価する方法を説明します。余因子の組み入れに対応した ARIMA (Auto Regressive Integrated Moving Average) のバージョンを実装します。ARIMA は、標準的な線形予測法で ( 時系列分析との関連における線形回帰に相当します。詳細は、「可視化とベンチマークの予測」のセクションを参照ください。) 、時系列予測の基準ベンチマークとしてよく使用されます。SageMaker では、DeepAR と呼ばれる RNN に基づくビルトインの時系列予測方法の最初のバージョンがリリースされました。ですので、カスタムモデルと DeepAR のパフォーマンスも比較していきます。
このブログの目的は、ある予測方法が他の予測方法よりも優れていることを証明することではありません。よりよいパフォーマンスの方法が一般化するまで、カスタムモデルを開発し、標準的方法に対してベンチマークする方法を示すことを目指します。利便性と制御の間にはトレードオフがあります。カスタムの深層学習アルゴリズムを開発すると、そのネットワークアーキテクチャ ( 例えば、複数のサブネットワークの組み合わせ ) やパラメータ化 ( 回帰ユニットの種類や損失関数、活性化機能など ) を細部に渡って完全に制御することが可能となります。一方で DeepAR は事前に構築されているため、深層学習技術に基づいた時系列を予測するには、最も容易かつ迅速な方法と言えます。独自のカスタムモデルを開発するには時間がかかる一方で、パフォーマンスを微調整するオプションが無限にあります。

図 1: 関連コードの概要と構造
データでは、$ を金融時系列とみなし、例えば、収益、利益、費用、株式、利息などを表すことができます。次の 5 つの要因に基づいて、10 日間にわたる一連の A の 毎日の値を予測することを目指します。 (1) 自身の値の過去の動向、(2) 自身の取引量の過去の動向、(3) もう一つの系列値の過去の動向、(4) 他の系列量の過去の動向、(5) 毎日のトップニュースの見出しから推測する市場センチメントの過去の傾向。もちろん、このコードは調整可能で、他の関連要因の過去の傾向に基づいて、時系列の将来の傾向を予測することもできます。ですがこのブログでは、独自のカスタム RNN モデルを開発し、ARIMA を実装し、DeepAR を使って、同じ SageMaker ノートブック内の 5 つの要因に基づいた金融時系列を予測するというパフォーマンスを評価する方法をご紹介します。それでは、始めましょう。
時系列分析と動的深層学習について
一連に起こるイベントの動力学、すなわち時系列を予測するには、予測しようとするデータの確率分布に関する詳細がどれだけあるかによって、異なる方法を使用します。確率分布をデータに当てはめることにより、パラメトリック方程式の結果として、時系列の過去および未来の傾向を簡単に定式化することが可能になります。与えられた初期値に関し、予測しようとする全ての量に対して完全な確率関数が分かっていれば、あらゆる解を常に見つけることができます ( 図 2) 。例えば、株価を予測しようとする時、この株式に影響を与える要因が全て分かっており、これらの要因全ての関係を左右する確率関数を定式化できれば、この関数で知りたいことは何でも分かるのです。もちろん、このような関数はまず存在しません。したがって、数値近似 ( 図 2) を使って、時間を小さな間隔で離散化し、利用できる情報に基づいて値 ( 状態と呼ばれる ) の動きを順に計算していきます。将来予測に一般的に使用される情報には、過去の状態の進化の傾向、ランダム性 ( 傾向の変動性 ) および境界条件 ( 例えば、流行の起源、オプションの行使価格 ) が含まれます。
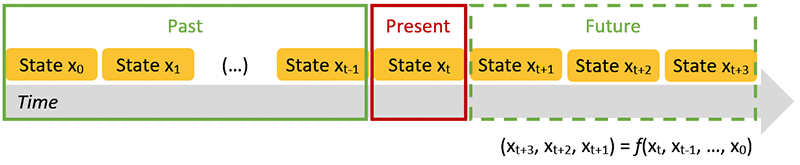
図 2 : 動的システムの有限状態への離散化、および過去に見られた傾向の関数に関する将来の傾向の定式化
金融サービス部門での従来のアプローチは、特定の株式の過去の傾向か、またはあらかじめ定義された確率定式化の有限差分あるいは確率的 ( ランダム ) サンプリングに依存していました。対照的に、動的な深層学習 ( リカレントニューラルネットワーク、RNN ) は、複数の相関変数 ( 例えば、株式、市場センチメント ) の傾向に基づいて、確率分布を仮定することなく、推論を行います。これを行うため、深層学習は、過去に起こった短期的および長期的なミクロ / マクロサイクルでの出来事を活用し、モデルをトレーニングして、大量のデータのこれらの傾向のうち、何が重要で何が重要でないかを学習します。 RNN の鍵となるものは、図 3 に示す遅延ユニットの存在です。これは、与えられた時間ステップで状態を記憶し、次のステップで深いレイヤーに再投入する、ということを、選んだ時間周期 ( ラグと呼ばれる ) の中で反復するものです。アルゴリズムは、与えられたラグに基づいて将来値 ( 時間区間 (horizon) と呼ばれる ) のシーケンスを推論することを学習します。これは、利用できるタイムラインにわたって取得した複数のラグ – 時間区間のペアを学習することで可能となります。これは、Sequence To Sequence 学習と呼ばれます。再帰方程式は、各ステップにて隠れたネットワーク全体を複製し、消えていくメモリにつながります。そのため、ネットワークを非常に深くすることができます ( つまり、最深のレイヤーの影響が、勾配最適化のプロセス中、これらのレイヤーに達するのに必要である少数の導関数が反復乗算を行うため、ゼロとなります ) 。図 3 にある GRU のようなメモリが消失する問題を避けるため、より高度なゲート付きシステムがいくつかあります。GRU の背後にあるアイデアは、長期間および短期間の両方のメモリから恩恵を受けるために、より最近のタイムステップ学習を以前のタイムステップ学習に再投入することです。
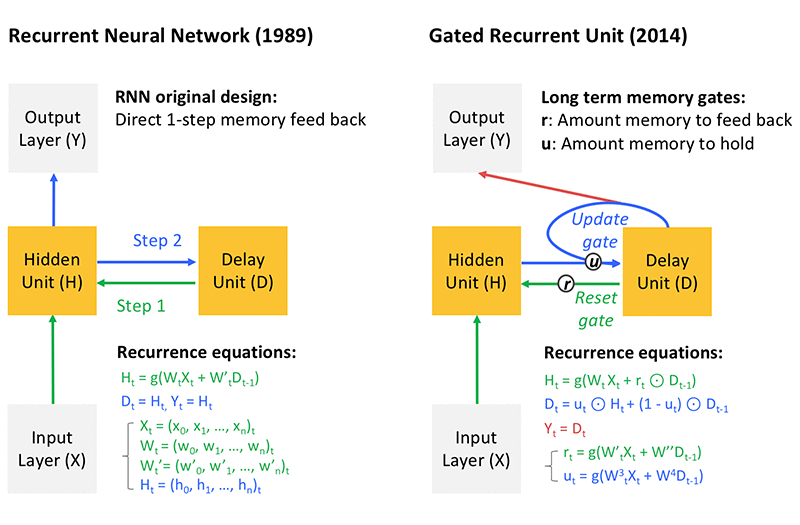
図 3 : 上記で説明したようなメモリの問題を解決するための、リカレントニューラルネットワーク、およびゲート付き回帰ユニット (GRU) のアーキテクチャ
時系列データを準備する
このブログ記事では、パブリックリポジトリである Yahoo Finance から 2010 年から 2016 年の間の利用可能な時系列をランダム化することで得られる、毎日の時系列値を使用します。下のコードでは、4 つの関連する時系列 ( シリーズ A の値とボリューム、シリーズ B の値とボリューム ) のタイムライン全体を抽出します。
上記コードでは、次数 1 で系列がほぼ定常になる ( 現在の系列は時間の経過とともに増加する傾向があります ) ように差をつけ、重なり合ったラグ – 時間区間のペアにおいて正規化および分割しています。The horizon was chosen to be 10 days, and since a rule of thumb in sequence-to-sequence learning is to choose a lag larger than the horizon, the lag was set to 3 weeks (note this could be further optimized through hyperparameter optimization (HPO)).タイムラインの 90% を、トレーニングのためのラグ – 時間区間のペアをサンプリングするために使用しました。残りの 10% は後でラグ – 時間区間の重複しないペアを定義し、モデルのパフォーマンスを評価するのに使用しました ( セクション 5 を参照 ) 。
市場センチメント全体は、ビジネスの取引 ( 個人の支出レベルや大量取引など ) に影響を与えることが知られており、毎日の金融時系列に影響を与える可能性があります。したがって、上記 4 つの時系列に加え、Kaggle 上で公開されているデータセットも使用し、2008 年から 2016 年のトップニュースをいくつか収集し、各見出しに対して -1 ( とても残念なニュース ) と 1 ( とても喜ばしいニュース ) の範囲でセンチメントの極性を抽出します。そして、毎日の見出し全てに対するこの指標を合計して、市場センチメント全体を日々の時系列で表示します。前述の 4 つの時系列と同じフォーマットを適用します。これは、仮定を立てた 5 つ目の時系列が、シリーズ A および B に関連し、これによって予測を潜在的にサポートすることを定義しています。
5 つの時系列全てを、第 3 次元が時間である 3D テンソルとして RNN に入力します。
この記事の残りの部分では、RNN を使用して、過去の動向 ( ボリュームを含む ) とシリーズ B の過去の傾向、および市場センチメントに基づいて、シリーズ A 値の未来の時間動向を推測するモデルをトレーニングする方法を説明します。次に、その結果を ARIMAx および DeepAR から得られた結果と比較します。
カスタム深層学習 RNN を開発する
以下に示す抜粋では、RNN アーキテクチャーは、TensorFlow バックエンドを持つ Keras API を使って設計されています。この API は 2 つのサブ RNN を合併しており、それぞれに 256 個のゲート付き回帰ユニットのレイヤーがあります。1 つ目のサブ RNN は、それ自体の過去に基づいてターゲットシリーズの未来の傾向 ( シリーズ A 値 ) を予測することを目的とする一方で、2 つ目のサブ RNN は同じターゲットシリーズを予測することを目的とします。ですが、後者は他の 4 つの時系列 ( シリーズ A のボリューム、シリーズ B の値とボリューム、および市場センチメント ) に基にしています。2 つのサブ RNN は、1 つのサブ RNN に割り当てられた重み w、およびもう一つのサブ RNN に割り当てられたその補完的な (1-w) を通って最終密集層に分岐することで、一つに結合されます。これは、予測を行う際に、主時系列と余因子時系列をどれだけ使用するかを制御するハイパーパラメータになります。異なる w 値を、簡単にテストしました。0.5 から 0.8 の範囲の値 ( これはターゲットシリーズでトレーニングしたサブ RNN からの情報に有利となっています ) は、最良の結果をもたらす傾向にあります (HPO によってさらに最適化できることに留意ください ) 。
SageMaker で RNN をトレーニングする
データパイプラインと RNN 設計を実装後 ( ファイル名は Train)、SageMaker ノートブックを用いてセッションに必要なパッケージを全てインポートし、セッションを定義し、Amazon S3 でデータをアップロードします。そして Docker コンテナを構築し、それを Amazon ECR にプッシュし、最後に RNN モデルをトレーニングします。SageMaker を使用すると、モデルを用いてエスティメーターが作成され、特定の Amazon EC2 のリソースを 1 行だけでリクエストされることに注意してください。
推論アプリケーションを導入する
モデルをトレーニングする時と同じように、SageMaker を使うと、エンドポイントを作成し、推論アプリケーションにモデルをデプロイするのに、簡単な設定で済みます ( たった 1 行でできます ) 。バックエンドで実行している EC2 インスタンスの種類と数にも、柔軟に対応します。このブログ記事では、汎用の EC2 インスタンスを使用します。CSV シリアライザを使用すれば、様々なデータ形式を CSV 形式でエンドポイントの背後にあるモデルに渡すこともできます。
未来の シリーズ A の値を予測する
推論エンドポイントから予測を生成するには、コードはトレーニング中に実装するデータパイプラインと同じように、5 つの時系列 ( シリーズ A の値とボリューム、シリーズ B の値とボリューム、市場センチメント ) を区別し、ラグ – 時間区間の重なり合ったペアにおいて正規化および分割して、それらがほぼ定常になるようにします ( 詳細はセクション 1 を参照ください ) 。大きく違う点が 2 つあります。(i) 新しい時系列 (2D ML の専門用語においては、新しい観測 ) のスケーリング / 正規化のステップは、個々に行うのではなく、元のトレーニングデータのスケールを参照して行います。ここで、トレーニングしたモデルが入力装備ごとに独自の座標系を定義しているのだから、新しい観測はどれも同じ座標系に変換する必要があるのでは、と思うかもしれません。このブログの例では、トレーニングデータがそれほど大きくなく、すぐに利用可能のため、新しい観測をスケーリングする際にこのセットを再インポートするだけで大丈夫です。(ii) 予測を生成後、結果を元のスケールに戻す予測ステップ自体は、前述のようにフォーマットしたデータを使用して、事前にトレーニングしたモデルを呼び出すだけです。
データを準備し適切なフォーマットにした後にモデルをトレーニングする際、SageMaker では、前述で作成したエンドポイントを呼び出すことによって、モデルをオンラインで使用できるようにする設定が簡単にできます。シリーズ A のボリュームの最新のトレンド ( ラグ ) 、シリーズ B の値とボリューム、および市場センチメントに基づいて、シリーズ A の値を予測します。ここでも、バックエンドで実行する EC2 インスタンスの種類と数に柔軟性を持たせています。
視覚化およびベンチマーク予測
時系列予測モデルの性能を評価するのに、他の機械学習アプローチと同じ原則に従います。つまり、予測値と観測値を比較します。これにより、今後どのような予測を行うかについての信頼水準が得られるわけです。一般化するには、モデルをパラメータに適合させるためのトレーニングを行う時には現れなかったラグ – 時間区間ペアのサンプルに対して、この検証フェーズを実行する必要があります。なぜなら、モデルは以前には現れなかったラグデータに使用することを最終的に目標としているためです。このサンプルには多くの観測値が含まれている必要もありますが、Sequence-To-Sequence 学習では、動的ではない ML アプローチとは異なり、時間区間に複数の時間ステップがあるため、観測値は複数の予測値から得ます。
このブログの例では、元のタイムラインのうち 10% (2016 年 5 月から 12 月の期間に相当 ) を検証目的で保存し、この期間中に 4 つの重複していないラグ – 時間区間ペアを均等にサンプリングして、観察された様々な傾向を入手しました。各サンプルについて、10 日間の予測された時間区間と実際の観測値とを比較した結果が図 4 です。平均絶対誤差 (MAE) は、それが示すものとは無関係に、誤差の大きさに対しペナルティを課すのに使用され、平均二乗誤差 ( MSE ) が好ましいとされます。なぜなら、特定の点の誤差の大きさよりも、複数点にわたる傾向に関心があるからです。各サンプルの MAE は、それぞれ 10 USD 、24 USD 、14 USD 、15 USD です。平均で 16 USD となり、シリーズ A 値と比較して MAE <3% に相当します。ヘッドラインニュースのデータは Kaggle では 2016 年 7 月 1 日以降のデータセットが使用できなかったため、最初のサンプルではこちらの機能が使用されていることに留意ください。これは、RNN コンボが提供するうまくまとまった機能で、アーキテクチャの設計を変更する必要がありません。
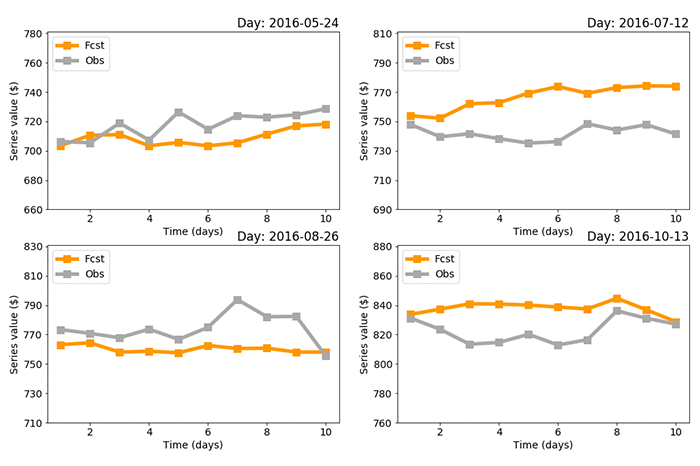
図 4 : 重なり合わないラグ – 時間区間中のサンプルのうち 4 つのにわたっての、カスタム RNN コンボのパフォーマンス。各サンプルの MAE は、それぞれ 10 USD 、24 USD 、14 USD 、15 USD です。
時系列予測モデルのパフォーマンスをきちんと評価するには、他の方法を適用し、異なる方法で得られた結果をお互いにベンチマークすることが最善です。ARIMAx と DeepAR を実装し、これらの 2 つの方法をカスタム RNN コンボと同じデータに適用するためのコードは、添付ファイルで提供されています。
余因子の組み入れに対応した ARIMA である ARIMAx の場合、 次の 2 つのターゲット時系列を逆行することで予測 t を行うことがあります。(i) 時系列そのものとその他の関連する時系列のいくつかのラグ p ( 決定論的部分 AR ) 、および (ii) 時系列そのものとその他の関連する時系列に沿った移動平均の近辺で不規則変動するいくつかのラグ q 、( 確率論的部分 MA ) 。方程式では、次のようになります。
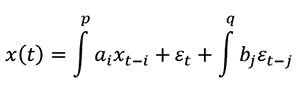
ここでは、x は時系列の集合、e は時系列移動平均の周りでの不規則変動、および (a、b) の重みパラメータ ( 標準回帰モデルにおける重みと同じ概念 ) を表します。AR と MA を適用する前にそれらを定常にする任意の順序によって、時系列を差分 ( すなわち、統合 ) することができ、よって、AR-I-MA という名前が付けられます。接尾辞の x は外因的な変数を表します。ここでは単に、時間区間に対応する多くのタイムステップによって過去の日付を変えた後の、その他の 4 つの関連する時系列 ( シリーズ A のボリューム、シリーズ B の値とボリューム、および感情センチメント ) のことです。添付ファイルにあるコードを参照してください。図 5 が示すように、シリーズ A の値は前の 2 つのタイムステップと自己相関していないように見えますが、シリーズ A のボリュームと変動性 ( 前述の式の MA 項によってモデル化され、部分自己相関関数 (PACF) 曲線で説明されます ) はどちらも、ホワイトノイズの届かない 3 つのタイムステップまで自己相関されます。
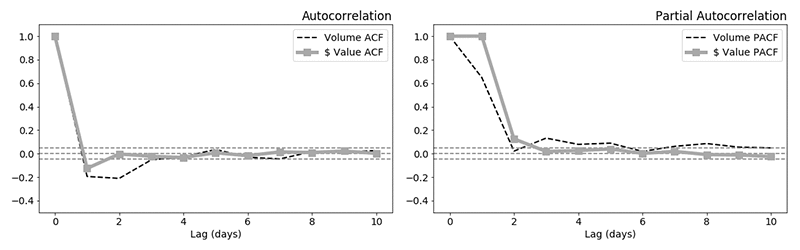
図 5 : 利用可能な全期間にわたるシリーズ A の値およびボリュームの自己相関関数 (ACF、左 ) 、および部分自己相関関数 (PACF、右 )
図 5 の ACF と PACF は、パラメータ p と q の適切な値を選ぶ手がかりとなります。サンプル 1 の [2,6] の範囲内の (p 、q) の可能なあらゆる組み合わせに対しグリッド検索を実行し、(p 、d 、q) = 4,0,4) で最良の結果が得られることが分かりました。添付ファイルの、コード / 結果を参照してください。図 6 および図 7 は、(p 、d 、q) = (4,0,4) を使って RNN コンボに使用されたものと同じデータを適用した ARIMAx の結果を表しています。
図 6 では、予測時系列における ARIMA の主な利点を示しています。ここで、入力と出力の間の直線的なマッピングに、各入力時系列の重要度を評価するのに利用する一連の重みを加えているのが見られます ( 列 Estimate を参照 ) 。特に、シリーズ B 値はシリーズ A 値の予測に大きな影響を与えていることが分かります。ARIMAx でシリーズ A の値を予測するという目的においては、市場センチメント (s) も影響はありますが、さほど大きなものではなく、また、ボリュームはそれほど重要ではありません。図 7 に、ARIMA の重要な制限を示しています。 これは線形予測アプローチであり、傾向が著しく非線形である場合には、一般化するのは難しいでしょう。このブログの例では、ARIMAx の予測は 10 日後も定量的には妥当な数値ですが、毎日やその他の微小周期の傾向が完全に失われていることがわかります。そのため、これらの微小周期がより顕著になった場合や、ターゲットの時間区間が 10 日以上の場合に、より多くのエラーを引き起こす可能性があります。
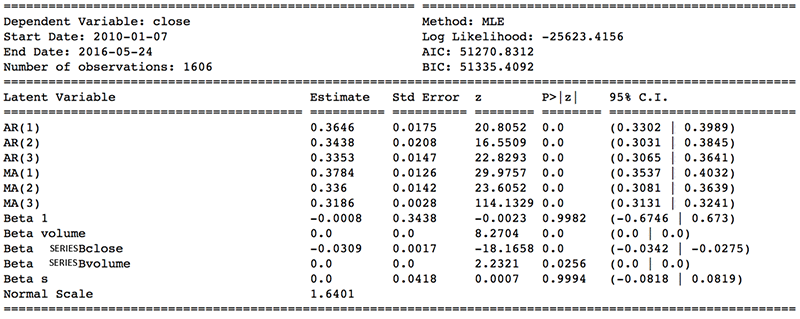
図 6 : トレーニングをした後、最善のパフォーマンスを見せる ARIMAx モデルについて
Amazon SageMaker は、DeepSAR と呼ばれる RNN に基づいたビルトインの時系列予測方法の最初のバージョンを最近リリースしました。現在のリリースにおいて、ここで開発した ARIMAx と RNN コンボの間には利点がいくつかあります。Amazon SageMaker DeepAR は、あらかじめ構築済みという大きな利点があるのはもちろんのこと、その結果、SageMaker 上で利用するのが最も早くて簡単でもあります。限られた時間では、これが SageMaker での推奨アプローチです。しかしながら、冒頭で説明したように、利便性と制御のどちらを選択するかはトレードオフの関係です。DeepAR の場合、ユーザーは、レイヤー数、各レイヤーの回帰ユニット数、学習率などのハイパーパラメータを設定することができます。ユーザーは、異なるニューロンにおける活性化関数の性質、オプティマイザー / 損失関数の種類、回帰ユニットの種類 ( 例えば、GRU 対LSTM) 、および、より普及しているネットワークアーキテクチャそのものを含む、ハイパーパラメータを制御しません。したがって、ユーザーはネットワーク上で異なる時系列がどのように導入されるかを制御しません。実際に、現リリースにおいて、製品チームは、その値が時間区間の間にわたって分からない場合、余因子を使用しないことを推奨しています。Amazon が今後 10 日間に投稿するプレスリリースの数など、余因子の値を前もって知ることができることは時折あります。しかし、ここにあるユースケースのように、異なる製品収益あるいは異なる株式、その値が過去のものは分かっていても未来のものは分からない市場センチメントといった余因子を活用できれば、と思うこはよくあります
このような状況で、この記事が目指すものは、ある予測方法が他の方法よりも優れていることを証明することではなく、カスタムの深層学習 RNN モデルを開発し、それを利用可能な時系列を使ってパフォーマンスが向上するまで ARIMAx や DeepAR などの標準的な方法でベンチマークする方法を示すことにあります。DeepAR 製品チームは過去における余因子の使用を推奨していません。そのため、主に説明を目的として、シリーズ A とシリーズ B の値および市場センチメントを用いて DeepAR をトレーニングしました。DeepAR の新しいバージョンがもうすぐにリリースされることに留意ください。この新バージョンでは、余因子を扱う際の柔軟性が向上しています。
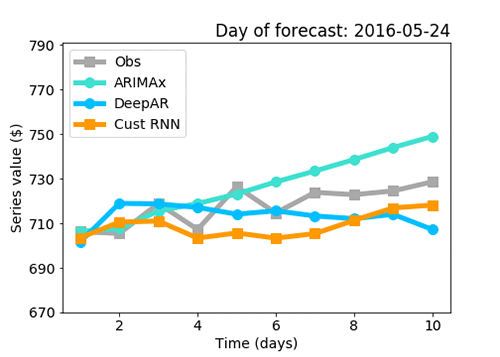
図 7: ベンチマーク分析 RNN コンボ、ARIMAx および DeepAR を用いて生成した予測の視覚化と、シリーズ A 値に対して実際に観察されたもの
図 7 の結果は、前に説明したように ある方法が他の方法よりも優れていることを証明するものではありません。ですが、カスタム RNN コンボが DeepAR よりも優れたパフォーマンスを行う可能性があることを示唆しています。なぜなら前述の通り、DeepAR は ARIMAx よりも少ない機能を持ちながら、ARIMAx よりも確かに優れたパフォーマンス結果を出しているからです。図 7 から、RNN コンボは、ARIMAx よりも毎日の傾向により近いことが明らかです (ARIMAx からの予測は直線に近い ) 。
まとめ
このブログ記事では、深層学習 RNN アーキテクチャを開発し、特定のユースケースに合わせてカスタマイズする方法、ARIMAx と DeepAR の 2 つの追加の予測方法を実装する方法、および Amazon SageMaker の弾性的にスケーラブルで本番に対応した環境を用いてパフォーマンス結果をベンチマークする方法を説明しました。ここで選んたユースケースでは、このシリーズの過去のトレンドと、その他の複数の要因、すなわち他の時系列値や市場センチメント全体といった過去の傾向に基づいて、金融時系列の未来の時間展開を予測しています。添付ファイル内のコードを使えば、変更を最小限に押さえて、他のユースケースや時系列に適合することができます。
今回のブログ投稿者について
alt altJeremy David Curuksu は、Amazon の Machine Learning Solutions Lab のデータサイエンティスト、およびコンサルタントです。応用数学で修士号と博士号を取得し、スイス連邦工科大学ローザンヌ校 ( スイス ) とマサチューセッツ工科大学 ( 米国 ) でリサーチサイエンティストを務めました。科学に関する審査を受けた論文の著作が数多くあり、彼の『 Data Driven 』という著作では、データサイエンスの新時代における経営コンサルティングを紹介しています。