Amazon Web Services ブログ
Amazon Redshift でデータの取り込みとレポートのパフォーマンスを最大化する
これは ZS のゲスト投稿です。ZS の言葉を借りると、「ZS は企業と緊密に連携して、製品とソリューションの開発および提供を支援し、顧客価値と企業成果を押し上げるプロフェッショナルサービス企業です。ZS は、テクノロジー、コンサルティング、分析、運用も併せて行い、クライアントの商業体験を改善することを目指しています」
ZS は、MicroStrategy ベースの BI アプリケーションのセットアップと運用に関わりました。これは、Amazon がホストするバックエンドアーキテクチャのデータウェアハウスとして Amazon Redshift から 700 GB のデータを供給するものです。ZS は、Amazon S3 バケットや FTP システムなどのさまざまなシステムのさまざまな製薬データベンダーから医療データをデータレイクに供給しました。一時的な Amazon EMR クラスターを使用してこのデータを処理し、消費をレポートするために Amazon S3 に保存しました。レポート固有のデータは、COPY コマンドを使用して Amazon Redshift に移動させ、MicroStrategy はそれを使用してフロントエンドダッシュボードを更新します。
ZS には、利用可能な Amazon Redshift インフラストラクチャに対応するための厳格なクライアント設定 SLA があります。利用可能な小さな Amazon Redshift クラスターを使用して、大量のデータを処理するアプローチを見出すための実験を行いました。
この記事では、S3 から Amazon Redshift に大量のデータを読み込み、効率的な分散技術を適用して、比較的小さな Amazon Redshift クラスターでクエリのレポートのパフォーマンスを向上させるためのアプローチを示します。
データ処理方法
ZS インフラストラクチャは AWS でホストされています。そこでは、MicroStrategy BI レポートツールでデータをレポートする前に、AWS のサービスを利用してさまざまなベンダーの製薬業界データを保存および処理しています。次の図は、フラットファイルからエンドユーザー向けの MicroStrategy に示されるレポートまでの全体的なデータフローを示しています。
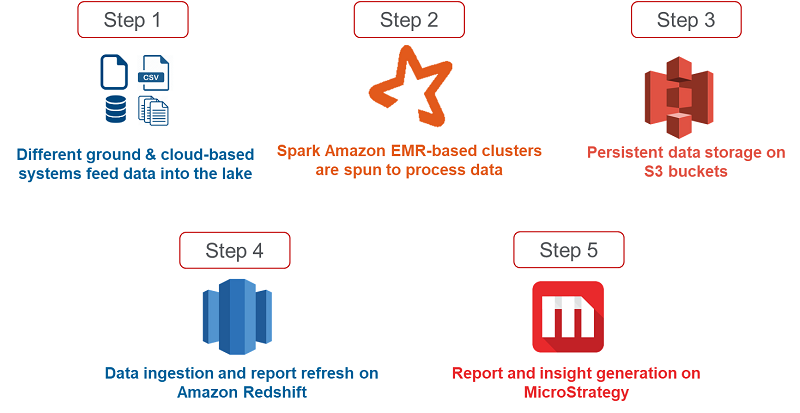
ステップ 1: 製薬データが、さまざまなベンダーや FTP ロケーション、個々のシステム、Amazon S3 バケットなどのさまざまなシステムから供給されます。
ステップ 2: pyspark コードを実行するための計算能力を実現するために、必要に応じて費用対効果の高い一時的なクラスターがスピンされます。
ステップ 3: 処理後、データは Amazon S3 バケットに保存され、ダウンストリームアプリケーションが消費されます。
ステップ 4: その後、700 GB のデータが MSTR の消費のために Amazon Redshift に取り込まれます。
ステップ 5: このデータは Amazon Redshift から読み取られ、洞察は MicroStrategy のレポートの形式でエンドユーザーに表示されます。
検討中のデータセット
この特定のシナリオでは、ZS は製薬ドメインのデータを使用していました。次のテーブルは、データの典型的な構造を示しています。これには、医師、患者、治療に関連する ID、および医療メトリクスがいくつか含まれています。
| テーブル 1 | ||
| 列名 | EMR データタイプ | Amazon Redshift データタイプ |
| 時間 ID | 整数 | int |
| 地理 ID | 整数 | int |
| 製品 ID | 整数 | int |
| マーケット ID | 整数 | int |
| 医師 ID | 整数 | int |
| 医師属性 1 ID | 整数 | int |
| 医師属性 2 ID | 整数 | int |
| 医師属性 3 ID | 整数 | int |
| 医師属性 4 ID | 整数 | int |
| 医師ランク | 整数 | int |
| メトリクス 1 | ダブル | 小数 (18,6) |
| メトリクス 2 | ダブル | 小数 (18,6) |
| メトリクス 3 | ダブル | 小数 (18,6) |
| メトリクス 4 | ダブル | 小数 (18,6) |
| メトリクス 5 | ダブル | 小数 (18,6) |
| メトリクス 6 | ダブル | 小数 (18,6) |
| メトリクス 7 | ダブル | 小数 (18,6) |
| メトリクス 8 | ダブル | 小数 (18,6) |
| メトリクス 9 | ダブル | 小数 (18,6) |
| メトリクス 10 | ダブル | 小数 (18,6) |
| メトリクス 11 | ダブル | 小数 (18,6) |
| メトリクス 12 | ダブル | 小数 (18,6) |
| メトリクス 13 | ダブル | 小数 (18,6) |
| メトリクス 14 | ダブル | 小数 (18,6) |
| メトリクス 15 | ダブル | 小数 (18,6) |
| メトリクス 16 | ダブル | 小数 (18,6) |
| メトリクス 17 | ダブル | 小数 (18,6) |
| メトリクス 18 | ダブル | 小数 (18,6) |
| メトリクス 19 | ダブル | 小数 (18,6) |
| メトリクス 20 | ダブル | 小数 (18,6) |
| メトリクス 21 | ダブル | 小数 (18,6) |
| メトリクス 22 | ダブル | 小数 (18,6) |
| メトリクス 23 | ダブル | 小数 (18,6) |
| データスナップショットの日付 | タイムスタンプ | タイムスタンプ |
| データ更新日 | タイムスタンプ | タイムスタンプ |
| データ更新 ID | ストリング | varchar |
各テーブルには約 35〜40 の列があり、約 200〜2 億 5,000 行のデータを保持しています。ZS はこのようなテーブルを 40 個使用しました。これらのテーブルのデータは、さまざまな医療データベンダーから供給され、レポートのニーズに応じて処理しました。
データセット全体のサイズは、CSV 形式で約 2 TB、Parquet 形式で約 700 GB です。
課題と制約
前述のデータ更新と洞察生成の 5 段階のプロセスは、規定の時間枠内で週末に行われます。デフォルトでは、S3 から Amazon Redshift への最適化されていない状態データのロードおよび MicroStrategy の更新 (前の図のステップ 4) には、2 ノード ds2.8xlarge クラスターでほぼ 13〜14 時間かかり、週末全体の実行 SLA に影響していました (1.5 時間)。
次の図は、クライアントのニーズを満たすために ZS が解決しなければならなかった 3 つの制約の概要を示しています。

週単位の時間ベースの SLA – 1 時間以内にロードし、MSTR のデータを 1.5 時間以内にフェッチします
クライアントの IT およびビジネスチームは、厳格な SLA を設定して、700 GB の Parquet データ (2 TB の CSV に相当) を Amazon Redshift にロードし、MicroStrategy BI ツールのレポートを更新します。このシナリオでは、クライアントチームは別のベンダーから AWS に移行しており、クライアントが全体的に期待していたことは、パフォーマンスを大幅に低下させることなくコストを削減することでした。
固定クラスターサイズ – 事前に決定された 2 ノード ds2.8xlarge クラスター
クライアント IT チームは、クラスターのサイズと設定を決定し、コスト、データ量、ロードパターンを考慮しました。これらは 2 ノード ds2.8xlarge クラスターに固定されており、調整できません。ZS は PoC を実行して、これらの制約を受ける環境を最適化しました。
大量のデータ – Parquet 形式の 700GB のデータロードを切り捨てます
ZS が使用したデータは、製薬ドメインに関係していました。このシナリオで検討していたのは、Parquet 形式の 700 GB のデータセットでした。この特定のユースケースでは、更新ごとに履歴データも更新されたため、大量のデータを追加できませんでした。そのため、切り捨てと読み込みのプロセスに従いました。
反復最適化
ZS は、時間、データ量、クラスターサイズに制約があるため、さまざまな実験を行い、パフォーマンスを評価する 2 つの重要な側面である Amazon Redshift データのロードと読み取り時間を最適化しました。ZS は、次のことを支援する反復フレームワークを作成しました。
- ファイル形式を決定する
- 配布およびソートキーを介して最適なデータ配布を定義する
- データ読み込みプロセスを並列化する手法を特定する
次の図は、Amazon RedShift クラスターで最高のデータロードと読み取りパフォーマンスを実現するための主要な手順を示しています。
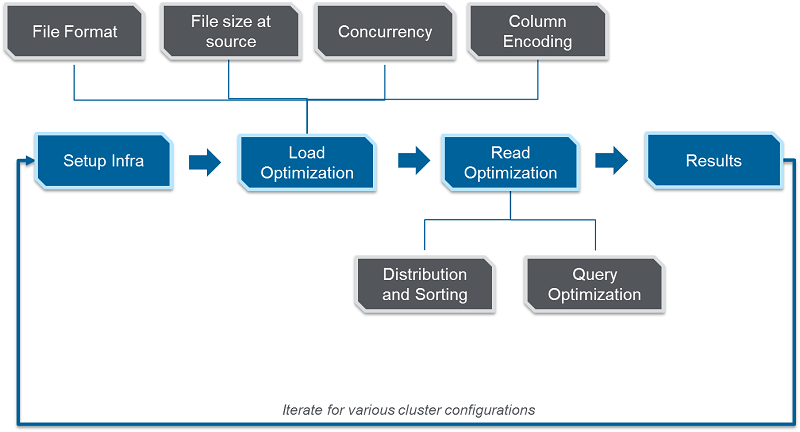
データロードの最適化
データロードのパフォーマンスに影響を与える 4 つの重要な要素 (ファイル形式、ソースでのファイルサイズ、同時実行、列エンコード) を特定し、最適化しました。
ファイル形式
多くのプロジェクトは通常、S3 から Amazon Redshift に CSV 形式でデータをロードします。ZS には、Spark プロセスの出力として、Snappy 圧縮を使用した Parquet 形式のデータがありました。(Spark プロセスは、この組み合わせで最適に機能します)。
Amazon Redshift の効率的な形式を特定するために、Parquet を一般的に使用されている CSV および GZIP 形式と比較しました。Spark プロセスで生成された 2 億行のデータを含むテーブルを S3 からロードしました。これは CSV で 41 GB、Parquet で 11 GB、GZIP で 10 GB に相当し、ロード時間と CPU 使用率を比較しました。次の図は、異なるファイル形式で保存された同じデータのロード時間と CPU 使用率を示しています。
使用していたデータセットと制約について、Parquet 形式のファイルを読み込むには、CSV や GZIP と比較して CPU 使用率が低く、I/O が少なく、またメモリを集中的に使用する CSV 形式に比べて S3 のメモリフットプリントが小さくて済みました。CPU 使用率が低いため、このシナリオではより多くの並列ロードが可能になり、Parquet ファイルのロードに必要な全体的な実行時間が削減されています。

ソースのファイルサイズ
次の側面は、Parquet ファイルを分割して S3 に保存するブロックサイズを選択することでした。通常、128 MB のブロックサイズが Spark ジョブに使用され、データ処理に最適であると考えられています。ただし、Amazon Redshift は大きなファイルで最適に機能します。
10 GB の Parquet データをロードして、250 MB、750 MB、1 GB、1.5 GB、3 GB のブロックサイズの小さな等サイズファイルに分割し、それぞれのパフォーマンスを記録しました。次のグラフは、さまざまなロード時間を示しています。
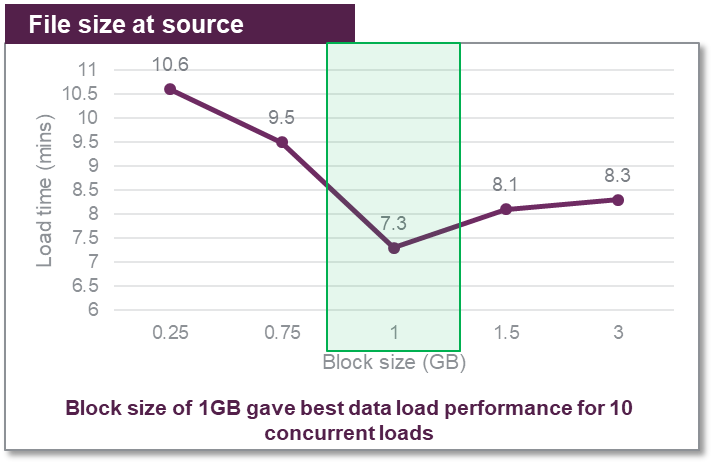
(最適なロードタイミングで) ブロックサイズが 1 GB に達するまでデータのロード時間は徐々に改善されました。1GB を超えると、大きなファイルでパフォーマンスの低下が見られ、Amazon Redshift は大きなファイルの処理に時間がかかりました。
これらの数値は、作業していたデータの種類に固有のものです。推奨事項は、データの形式と形状により異なります。
ベストプラクティスとして、ブロックサイズを特定し、ファイル数を Amazon Redshift クラスターのスライス数の倍数にします。これにより、各スライスが同じ量の作業を行い、アイドルスライスがないことが保証され、効率が向上し、パフォーマンスが改善されます。詳細については、「Amazon Redshift を使用した高性能 ETL 処理のトップ 8 ベストプラクティス」を参照してください。
同時実行性
COPY コマンドのメモリは比較的少なくなっています。負荷が平行になるほど、パフォーマンスが向上します。ZS は、個別の同時実行設定で約 7.3 GB のテーブルを複数回ロードしました。1〜20 の同時ロードでファイルを Amazon Redshift に移動するのにかかる 1 GB あたりの平均時間でスループットを測定しました。次のテーブルに結果をまとめます。
| テスト | 並列にロードされたテーブルの数 (同時実行) | ロードした合計データ (GB) |
| テスト 1 | 1 | 7.3 |
| テスト 2 | 5 | 36.5 |
| テスト 3 | 10 | 73 |
| テスト 4 | 15 | 109.5 |
| テスト 5 | 20 | 146 |
次の図は、1GB のデータのロードにかかる時間と、さまざまな同時実行設定の CPU 使用率を示しています。
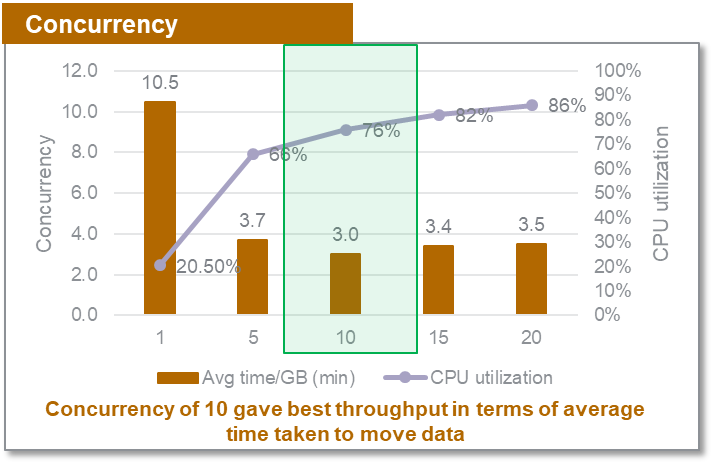
作業していたデータセットと制約については、同時実行数 10 で特定のデータセットのスループットが最大になり、25% の CPU 可用性バッファーが約 25% になりました。リリースごとのデータとボリュームの変動の性質に応じて、異なるバッファーを選択できます。
列エンコード
最高のパフォーマンスを提供し、ストレージフットプリントが少ない Amazon Redshift での列エンコードと圧縮を識別するために、ZS は (ANALYZE COMPRESSSION コマンドが推奨する) ZSTD、LZO、および Amazon Redshift テーブルのエンコードなし形式を比較し、ロードパフォーマンスを評価しました。以下の図は、同じデータボリュームをテーブルにロードし、列にエンコードなし、ZSTD および LZO エンコーディングを適用するのにかかる時間を示しています。
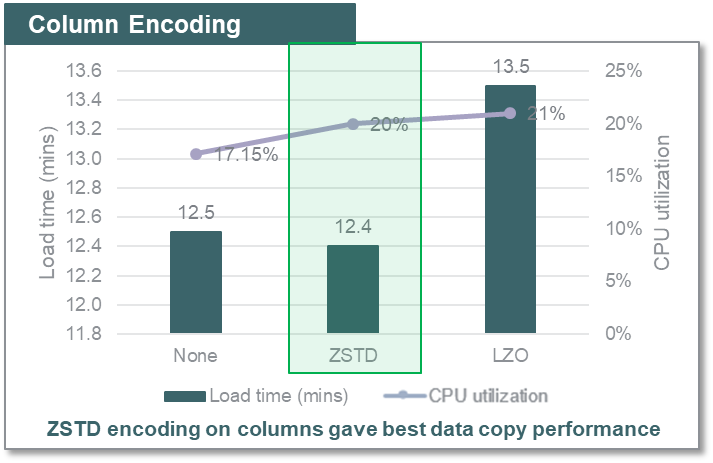
作業していたデータセットと制約について、列の ZSTD エンコーディングは、圧縮率が高く (圧縮が使用されていないときよりも 3 倍近く)、このユースケースに対して Amazon Redshift で最高のデータコピーパフォーマンスと低いストレージフットプリントを実現しました。データタイプとデータのカーディナリティに応じて、さまざまな結果を得ることができます。
注: このソリューションは AZ64 エンコーディングの機能リリースより前に実装されたため、その影響は考慮されていません。このブログ記事で説明しているアプローチは、Amazon Redshift がサポートするすべての圧縮エンコーディングのうち AZ64 圧縮エンコーディングを考慮して使用できます。
データ読み取りの最適化
ZS は、分散およびソートキーと SQL 最適化 (MicroStrategy 自動生成 SQL クエリのフィルターの最小化) を使用して、Amazon Redshift から MicroStrategy を使ってデータを読み取るパフォーマンスも改善しました。
SQL クエリ
MicroStrategy はビジネスインテリジェンスツールで、独自の SQL をインテリジェントに構築することでデータベースからデータを読み取っています。MSTR SQL (SELECT、GROUP BY や一時テーブルなどの一般的な DW クエリ) のパフォーマンスをフィルターありとなしで比較しました。そしてデータセットのフィルターありとフィルターなしのクエリは、ほぼ同時に実行され、同じリソースを使用していることがわかりました。けれども、フィルタリングされていないクエリは、4 倍のデータを提供しました。次のテーブルに結果をまとめます。
|
フィルター? |
フェッチされた行 | クエリ実行時間 | CPU 使用率 |
|
Y |
50 万 |
5.1 (分) |
15 % |
| N | 2M | 5.1 (分) |
15 % |
SQL を調整してフィルターを最小限またはゼロにすると、より多くのフィルターを使用してデータを読み取る場合に比べて、処理時間をわずかに増やすだけで大幅に多くの行をフェッチできます。データセット全体を使用する必要がある場合は、個別のフィルターで複数の SQL を使用し、それらを並行して実行するよりも、1 つのクエリを使用して完全なデータをフェッチすることをお勧めします。
分散キーとソートキー
次のテーブルは、このユースケースで分散キーとソートキーを使用した場合と使用しない場合の、テーブルのロードと読み取りのパフォーマンスを分析したものです。
| 分散スタイル | 分散キー | ソートキー | ロード時間 (分) | クエリ実行時間 (分) | クエリ CPU 使用率 |
| なし | – | – | 16.7 | 59.5 | 59% |
| キー | 均等に分散するクエリに応じた最適な分散キー | SQL の group by 句の順に、where 句に表示される 6 列 | 17.5 | 36.1 | 32% |
分散キーのないテーブルのロードは少し速くなりました。ただし、2 つのクエリ間のデータ読み取り時間と CPU 使用率には大きな違いがあります。つまり、全体的な CPU 使用率が大幅に減少したため、キーが適切に設定されたときに、より多くの並列ロードが効率的に実行できます。重要なポイントは、自動、均等、または手動の分散スタイルを使用して、Amazon Redshift から読み取ったデータを最適化し、より多くの並列処理を可能にすることです。ZS は手動の分散スタイルを使用し、データとリフレッシュケイデンスの広範な理解に基づいて分散キーとソートキーを選択しました。
Amazon Redshift インスタンスから最適な出力を取得するための次のステップ
複数の POC 結果により、最適なファイル形式、圧縮技術、再パーティション化された Parquet ファイルブロックサイズ、分散およびインターリーブされたソートロジックを特定しました。これにより、Amazon Redshift をデータベースとして使用した MicroStrategy でレポートするためのデータセットから最高のパフォーマンスを引き出すことができます。これにより、利用可能な固定 2 ノード ds2.8xlarge クラスターを使用して、クライアントセット 2.5 時間の SLA 内で最適なデータロードと読み取りの組み合わせを特定し、700 GB の Parquet データ (2 TB の CSV データに相当) をロードできました。
次の図は、Amazon Redshift クラスター設定に適した最適なデータロードと読み取り手法を特定するために実行できる反復プロセスを示しています。

重要なポイントは次のとおりです。
- Parquet と Amazon Redshift はうまく連携しました。Parquet 形式のデータの CPU 使用率と I/O 要件は低く、より多くの並列ロードが可能になりました。
- ZSTD エンコードは、数値のエンコードも手伝いこの特定のデータセットに最適に機能しました。
- テーブルのソートキーと分散キーは、分散およびソートロジックが適用されていないテーブルと比較して、読み取り時間を約 80% 短縮できます。
- Amazon Redshift でのデータのフィルタリングは、一般的なデータベースと同じようには機能しません。適切なソートキーを使用して、データフィルタリングのパフォーマンスを改善できます。
- ソースのファイルサイズと同時実行性は相互に関連しているため、それに応じて選択する必要があります。より大きなブロック (この特定のデータセットに対して最大 1 GB) は、Amazon Redshift により高速にロードされます。
著者について
 Vasu Kiran Gorti は、結果重視の専門家で、主に営業およびマーケティングコンサルティング分野のテクノロジーと機能/ドメインの経験を持っています。ZS アソシエイツのアソシエイトコンサルタントの役割を評価し、ライフサイエンスとヘルスケアクライアントと共にそのビジネス目標と期待に沿って協働した経験もあります。彼は、MicroStrategy、ビジネスインテリジェンス、分析、およびレポートを専門としています。積極的かつ革新的な Vasu は、テクノロジーとビジネスのギャップを埋める刺激的なイニシアチブを楽しんでいます。彼はベータ版であり続け、常に学習し、臨機応変な対応をし、そして進化しています。
Vasu Kiran Gorti は、結果重視の専門家で、主に営業およびマーケティングコンサルティング分野のテクノロジーと機能/ドメインの経験を持っています。ZS アソシエイツのアソシエイトコンサルタントの役割を評価し、ライフサイエンスとヘルスケアクライアントと共にそのビジネス目標と期待に沿って協働した経験もあります。彼は、MicroStrategy、ビジネスインテリジェンス、分析、およびレポートを専門としています。積極的かつ革新的な Vasu は、テクノロジーとビジネスのギャップを埋める刺激的なイニシアチブを楽しんでいます。彼はベータ版であり続け、常に学習し、臨機応変な対応をし、そして進化しています。
 Ajit Pathak は ZS Associates のテクノロジーコンサルタントで、製薬会社の BI とデータ管理プロジェクトをリードしています。彼が興味を持ち、得意とする分野には、MSTR、Redshift、AWS スイートがあります。彼は、複雑なアプリケーションを設計し、効率的で簡潔なダッシュボードにつながる最適なアーキテクチャのプラクティスを推奨するのが大好きです。資格を持った技術コンサルタントである Ajit は、明確なデータのやり取りを通じて情報に基づいたビジネス上の意思決定を推進することに注力しています。データの視覚化とアプリケーションの分野以外では、読書、バドミントンを楽しみ、政治からスポーツまでのさまざまな議論に加わるのが大好きです。
Ajit Pathak は ZS Associates のテクノロジーコンサルタントで、製薬会社の BI とデータ管理プロジェクトをリードしています。彼が興味を持ち、得意とする分野には、MSTR、Redshift、AWS スイートがあります。彼は、複雑なアプリケーションを設計し、効率的で簡潔なダッシュボードにつながる最適なアーキテクチャのプラクティスを推奨するのが大好きです。資格を持った技術コンサルタントである Ajit は、明確なデータのやり取りを通じて情報に基づいたビジネス上の意思決定を推進することに注力しています。データの視覚化とアプリケーションの分野以外では、読書、バドミントンを楽しみ、政治からスポーツまでのさまざまな議論に加わるのが大好きです。