Amazon Web Services ブログ
Amazon EKS を数千ノードにスケールするまでの Mobileye の軌跡
この記事は Mobileye’s journey towards scaling Amazon EKS to thousands of nodes (記事公開日 : 2022 年 6 月 1 日) の翻訳です。原文は Mobileye 社の AI エンジニアリング部 DevOps スペシャリスト David Peer 氏と、AWS のコンテナスペシャリストソリューションアーキテクト Tsahi Duek 氏による共著です。
このブログ記事では、Mobileye の AI エンジニアリング部が Amazon Elastic Kubernetes Service (Amazon EKS) 上でシームレスにワークフローを実行し、毎日約 250 のワークフローをサポートしている様子を報告します。
Mobileye とは?
Mobileye では、最先端のカメラ、コンピューターチップ、およびソフトウェアを使用して、自動運転技術と先進運転支援システム (ADAS) を開発しています。Mobileye の AI エンジニアリング部は、ワークフロー、DAG、ML/DL の学習ワークフロー、基本的なバッチジョブなど、多様なタイプのワークロードを実行する様々なエンジニアリングチームをサポートしています。エンジニアリングチームとそのワークロードをサポートするプラットフォームを最初に設計する際、以下のような、主要な設計指針とプラットフォームに必要な機能を整理しました。
- エンジニアリングチームのためのプラットフォームの抽象化 – エンジニアリングチームにはインフラストラクチャを触って欲しくなかったですし、むしろ構成を深く理解することなくプラットフォームを使用してほしいと考えていました。(必要であれば良いですが、プラットフォームを使うための必須条件ではないはずです)
- 多様なワークロードの同時実行をサポートする実戦的なソリューション – 様々なチームによる多様なワークロードの要件が存在するため、プラットフォームの管理、デプロイ、運用に共通性を持たせながら、特定のワークロードに合わせて簡単に構成できるプラットフォームが必要でした。
- スケーラブルなプラットフォームソリューション – Mobileye では、1 時間あたり数十のデータ処理を行っています。それぞれのデータ処理は、数百から数千の Pod を同時に起動します。このような処理の例としては、数千の Spark エグゼキューターを起動する Spark クラスターが挙げられます。したがって、拡張性の高いソリューションというのが、エンジニアリングチームをサポートするための基本的な要件でした。
- 費用対効果の高いソリューション – 可能な限りコストを削減できるソリューションが必要でした。
- ネットワーク構成をサポートするソリューション – Mobileye では、セキュリティと規制上の理由から、インターネットにアクセスできないプライベートネットワーク上でワークロードを実行しています。
- 様々なタイプのワークロードをサポートするために、異なるインスタンスタイプをスケールし、使用できること – GPU や Habana Gaudi アクセラレーターなど、必要な時に利用できるだけの計算能力を利用したいと考えていました。
上記の要件をすべて考慮した結果、本番ワークロードの実行に Amazon EKS を採用することに決定しました。オンプレミスやクラウドのバッチ処理システムなどの選択肢も検討しましたが、Mobileye の他のサービスは Kubernetes 上で動かすことがすでに決まっていました。つまり、Kubernetes をベースとしないソリューションやプラットフォームは、複数の異なるプラットフォームのデプロイ、構成、運用方法を習得しなければならないため、運用の負担が大きくなってしまうのです。
Amazon EKS をメイン、そしてゆくゆくは唯一のコンテナワークロードプラットフォームとして選択することで、スケーラビリティ、信頼性、可用性、セキュリティ、モニタリング、およびその他の Day 2 の運用すべてを、単一のインフラストラクチャ上でより適切に設計できるようになるでしょう。これにより、開発者とエンジニアは、デプロイと実行を抽象化し、ワークロードを実行するのに重要な側面に集中できます。
ソリューションの構成
マネージド型サービスである Amazon EKS と Amazon EKS マネージド型ノードグループを使用し、私たちのニーズに基づいてよく設計された構成を用いることで、インフラストラクチャではなくワークロードに集中することが可能となりました。私たちは、Kubernetes と Amazon EKS をコンテナワークロードのための OS として扱いたいと考えています。そうすることで、以下が実現可能になります。
- クリティカルなサービスをデプロイ、実行すること。
- Amazon EC2 Spot インスタンスなどの異なる価格オプションを使用しながら、ワークロードとインフラストラクチャをスケールし、インスタンスタイプ、ニーズ、価格によってフォールバックすること。
- アプリケーションのニーズに応じていくつかの種類のストレージシステムを要求できる CSI (Container Storage Interface) を使用して、Amazon Elastic Block Store (Amazon EBS) や Amazon Elastic File System (Amazon EFS) などのストレージシステムと容易に統合すること。
- 責任共有モデルを遵守しながら、ワークロードとインフラストラクチャの安全を維持すること。
以下の図では、私たちの Amazon EKS クラスターの構成を示します。簡単のため、1 つのアベイラビリティゾーンがどのように構成されているかを示しています。ワークロードが実行している他のすべてのアベイラビリティゾーンでも、同一の構成が適用されています。
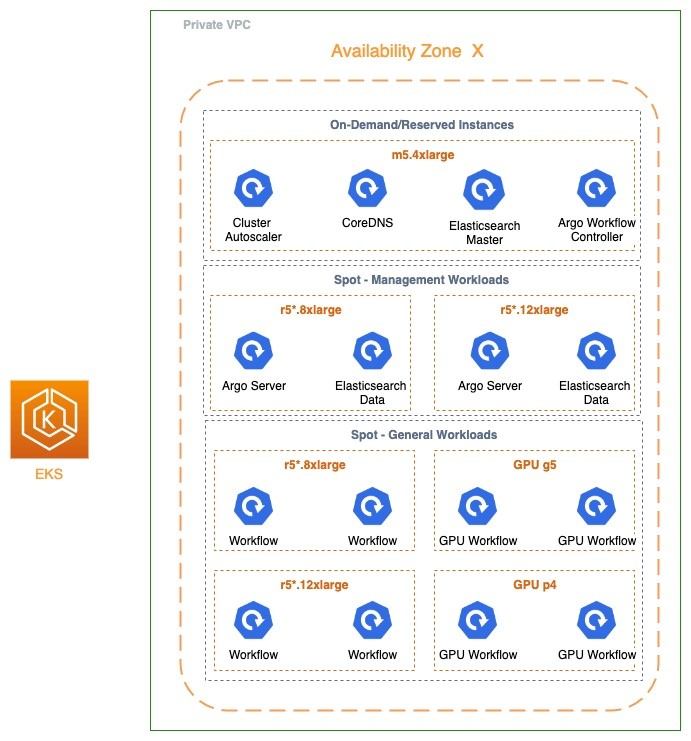
この図では、Spot インスタンスのベストプラクティスに従って、異なるノードグループを使用し、インスタンスタイプをできる限り多様化していることが分かります。この構成により、クラスターのデータプレーンの 95% 以上で Spot インスタンスを使用しながら、1 つのクラスターで、最大 40,000 Pod、100,000 以上の vCPU が存在する、最大 3,200 ノードまでスケール可能になりました。
また、完全なプライベートネットワークをサポートすることも重要な設計でしたが、プライベートクラスターに関する Amazon EKS の推奨は、その実現に役立ちました。
Argo Workflows – Kubernetes を公開する
前述の Amazon EKS の構成では、開発者はノードグループの設定、アベイラビリティゾーン、あるいはその他の側面を意識することはありませんし、そうすべきではありません。この抽象化を実現するために、私たちは Argo Workflows を使用しています。開発者は、Argo Workflows のマニフェストを宣言的に使用するか、Argo の Python SDK (Hera Workflows、Couler) を使ってコードを書くことで、処理を設計できます。これにより、彼らはアプリケーション固有の要件に集中でき、また Argo Workflows によってワークフローの実行完了が保証されます。その結果、多様なインスタンスタイプと GPU アクセラレーターにまたがって、様々なデータソースと相互作用するワークロードを実現できます。
以下の図では、開発者が生成する完全なワークフローを示します。前述のように、開発者はコンテナイメージ、リソース、使用する特定のノード、シークレット、アーティファクトなど、様々なタイプのワークロードステップに関する要件を指定できます。Argo Workflows は、リトライや再起動を含め、ワークフロー全体が実行完了することを確認します。Kubernetes は、Pod が適切な種類のインフラストラクチャにスケジュールされることを確認します。

次の章では、どのような構成によって、Amazon EKS クラスターを 3,000 ノード以上にスケールし、多様な種類のワークロードをサポートできるようになったのかについて、紹介します。
大規模なクラスターにおける考慮事項
Cluster Autoscaler を使用する
Cluster Autoscaler は、クラスター内で実行するワークロードに必要なインフラストラクチャのスケーリングをサポートする、よく知られたオートスケーリングのアドオンです。私たちの場合、Cluster Autoscaler は最適なアドオンであり、数十のマネージド型ノードグループをサポートできました。しかし、それでも以下のように、いくつかの設定に注意を払う必要がありました。
インスタンスタイプのリストの生成
Cluster Autoscaler は、サポートされているインスタンスタイプのリストを実行時に生成するのに、Amazon EC2 API に依存しています。インターネットに接続されていないプライベート VPC で Cluster Autoscaler を実行する場合、インスタンスリストを生成するために Amazon EC2 の VPC エンドポイントが必要です。
スポットとオンデマンドの価格提供を処理する priority expander の使用
大規模なクラスターを運用する場合、コストは非常に重要な要素です。そこで、私たちはワークロードのほとんどをAmazon EC2 Spot インスタンスで実行することにしました。そのため、Spot インスタンスのうち、一部のインスタンスタイプが一時的に利用できなくなった場合でも、本番環境に影響を与えないよう、priority expander を使用しました。以下の構成のように、spot-workflows.* が最も高い優先度となるように 3 種類の優先度を定義しました。(Cluster Autoscaler における priority expander の仕組みについては、GitHub のプロジェクトドキュメントを参照してください)
キャパシティ不足の場合のオンデマンドインスタンスの利用を最小限に抑えるため、オンデマンドノードグループのサイズを Spot ノードグループのサイズの 5% 程度に制限しました。また、Spot インスタンス上で稼働する管理システム (Argo サーバーや Elasticsearch データノードなど) とワークフローのワークロードを区別しました。これは、Cluster Autoscaler がすべてのノードグループにわたって Pod の binpack を行うことで、管理システムの Pod が退避される可能性を低減するためです。以下の Cluster Autoscaler の構成に示すように、spot-workflows ノードグループを spot-mgmt-workflows ワークロードから分離することで、それを実現しました。
注 : Amazon EKS 上でワークフロー処理を実行しているため、Spot インスタンスのキャパシティ不足が生じた後、オンデマンドから Spot インスタンスに再び戻すための処理は必要ありません。現在のワークロードはオンデマンドインスタンスで実行され続けますが、新しいワークロードは再び Spot インスタンスで実行しようとするからです。以下は、私たちの priority expander の構成です。
ノードグループにラベル付けすることで、ユーザーに柔軟なスケジューリングを提供する
前述のように、Mobileye では、異なるインスタンス構成が必要な複数のタイプのワークフローを実行しています。それには、ノードラベル、Traints と Toletations、node affinity が役に立ちます。第一に、適切なワークロードに適切なインフラストラクチャが割り当てられ、他のいかなるタイプのインフラストラクチャも使用されていないことを確認できます。第二に、ワークフローに誤ったインスタンスタイプを割り当ててしまうと、処理の遅延や不要なコストが生じる可能性があります。第三に、カスタムノードラベルが付与されたノードグループを設計することで、Pod マニフェストを変更せずに新しいインスタンスタイプのサポートを追加できます。以下は、eksctl を使用する際のノードグループの設定例です。
これは、マネージド型ノードグループの例です。
特定のインスタンスタイプが必要な場合は、nodeSelector パラメーターで指定するオプションがあります。例えば、Pod に NVIDIA A100 ベースのインスタンスが必要な場合は、次の Pod マニフェストで実現できます。
nodeSelector:
accel: " dl1.24xlarge"
tolerations:
- key: "Habana.ai/gaudi"
operator: "Exists"
effect: "NoSchedule"CoreDNS のデプロイを設定、監視する
大規模な DNS のクエリと名前解決も問題になることがあります。私たちは、Amazon Simple Storage Service (Amazon S3) バケットの名前解決にさえ失敗する状況に遭遇し、即座に CoreDNS の Deployment が提供するクラスター DNS サービスを疑ったことがあります。
まず、クラスター内で稼働している CoreDNS の Pod 数が不足していたため、レプリカ数を増やしました。これが最初の解決策でした。現在は Amazon EKS ベストプラクティスガイドの推奨事項に従って、CoreDNS のデプロイにオートスケーリングを実装することを検討しています。
2 つ目に、AWS は特定の ENI から発行される DNS クエリ数を制限しているため、CoreDNS Pod を異なるインスタンスに配置する必要があります。これは podAntiAffinity を使用することで実現できます。
3 つ目に、CoreDNS Pod のリソース割り当てがデフォルトでは 100 ミリコアなので、これを増やす必要がありました。CoreDNS Pod の再起動を何度か経験した後、CPU の割り当てを 1 CPU に増やしたところ、クラスターは期待通りに動作するようになりました。CoreDNS のレイテンシー、エラー、リソース消費を監視することは重要です。Amazon EKS ベストプラクティスガイドには、そのための推奨事項も記載されています。
今後の改善点 : 現在の CoreDNS のデプロイ設定は、3,200 ノードのクラスターではうまく機能していますが、ローカルノードの DNS キャッシュ機能の使用を検討しています。
クラスタークリティカルなワークロードには、オンデマンド (予約) キャパシティタイプを使用する
私たちは、ワークロードのほとんどで Spot インスタンスを使用していますが、少数のリザーブドインスタンスを使用することで、オンデマンドノードの大幅な価格削減も実現しています。前述の Cluster Autoscaler expander の構成を参考にしてください。(最も低い優先度の設定は 10 で、ノードグループ名に “spot” が含まれないノードグループすべてを意味します) 私たちは、主に Spot インスタンスの中断や Pod の退避シナリオがサービスの正常な運用や可用性に影響を与えるようなクリティカルなサービスに対して、この構成をとっています。
Amazon EKS のマネージド型ノードグループは、キー eks.amazonaws.com/capacityType と値 ON_DEMAND/SPOT で、ノードに自動的にラベル付けします。
CoreDNS、AWS Load Balancer Controller、Amazon EBS CSI Controller、Amazon EFS CSI Controller は、すべてこのインスタンスで動作しています。
Elasticsearch のプライマリノード (Elasticsearch では “マスターノード” と呼ばれる) や Argo のワークフローコントローラーなど、他の重要なサービスも同様にこのリザーブドインスタンスを使用します。
今後の改善点
安定した状態になれば終わりではなく、技術的なシステムは常に進化、改善し続けています。そのため、アーキテクチャに改善、拡張をもたらすためのタスクもバックログとして残っています。以下は、今後実装を検討しているトピックです。
Karpenter – Kubernetes のためのノードプロビジョニングプロジェクト
Karpenter は、Kubernetes クラスターの運用における効率とコストの改善を目的とした新しいプロジェクトです。Karpenter は、マネージド型ノードグループや ASG などの構成に頼らず、ワークロードに適したインフラストラクチャを迅速に作成します。Karpenter がもたらす大きな改善点の 1 つは、高速なスケーリング (Pod が作成されてから running 状態に達するまでの時間) と、私たちの構成の規模では管理が困難な、ノードグループを必要としない点です。
NodeLocal DNS キャッシュ
クラスターでの DNS のデプロイにおけるもう 1 つの改善点は、各ノードでの DNS リクエストのキャッシュを実装することです。Amazon EKS ベストプラクティスガイドは、このトピックもカバーしています。
Fluentd から Fluent Bit へ移行する
Fluentd は、統一されたロギングレイヤーを実現するオープンソースのデータコレクターです。Kubernetes で実行する場合、メタデータフィルターは Kubernetes API サーバーのログにメタデータを追加します。プラグインによって追加されるメタデータは、ラベル、アノテーション、Namespace などです。ただし、メタデータプラグインはデフォルトで API サーバーにある Pod の変更を監視するようになっているため、例外的に大規模なクラスターで実行すると、API サーバーの負荷が高くなり、API サーバーに対する他の API リクエストが遅延する可能性があります。こちらのブログ記事で説明されているように、この WATCH コマンドは無効化できます。さらに、API サーバーへの影響を最小限に抑えつつパフォーマンスを向上させるため、Fluentd から Fluent Bit への移行を検討中です。
クラスターのシャーディング
単一の Amazon EKS クラスターをメンテナンスしていくことは、結局のところ大変でしょう。開発者にとってのサービス品質の低下につながり得る、クラスターのアップグレードシナリオ、ノードグループの更新、アップグレード作業を想像してみてください。
私たちは、より多くの Amazon EKS クラスターをサポートし、より多くの Argo Workflows のデプロイを管理できるように、VPC の CIDR 範囲を拡張する予定です。そうすることで、クラスターの負荷、状態、または配置ポリシーで実装したその他の特性に基づいて、ワークフローの負荷分散やスケジュールを設定可能になります。ソリューションがより複雑になりますが、場合によっては、AWS と Amazon EKS のリソースをより良く利用し、より効率的にスケールできるようになるでしょう。
まとめ
新しいテクノロジーには、新しいチャレンジがつきものです。私たちは、マネージド型サービスから始める決断をすることで、使用開始に必要な労力を軽減できました。Amazon EKS を利用することで、クラスターを 1 から構築する場合に比べ、やるべきことが少なくなります。また、Amazon EKS ベストプラクティスガイドなどのリソースを利用したり、様々な GitHub プロジェクトを通じて Kubernetes や AWS のコンテナコミュニティとやり取りすることで、このようなスケールをサポートするのに必要な知識と経験を得ることができました。