Amazon Web Services ブログ
Amazon EC2 の新しい P2 インスタンスタイプ – 最大 16 GPU
私は長期に渡る技術やビジネスの動向を見ながら、自ら使用しブログに書くことができる製品やサービスの成り立ちを観察することが好きです。今回のブログを準備している時に、3 つのトレンドが頭に浮かびました。
- ムーアの法則 – 1965 年に予測されたムーアの法則は、半導体のトランジスタ数の集積度は毎年 2 倍になるというものです。
- 大量市場/大量生産 – 人類が生み出し、使用し、楽しんでいる技術は大量の半導体を消費しており、大きなマーケットシェアになっています。
- 専門化 – 上記の動向から、ニッチ市場ですら専門的な製品に関しては十分に大きい市場である場合があります。
このような動向に合わせて業界が進むに連れ、過去 10 年ほどの間に興味深いチャレンジがいくつか浮上しました。次のリストをご覧ください (箇条書きで考える癖がついていますね)。
- 光の速度 – トランジスタ密度が増加しても、光の速度には限界があります (コンピューターの先駆者 Grace Hopper が好んで言っていたように、電気は1ナノ秒の間に 1 フィート未満しか移動できません)。
- 半導体物理学 – トランジスタのタイム変換 (オンまたはオフ) の基本的限界により CPU が達成可能なサイクル時間の最低値を判断することができます。
- メモリボトルネック – 有名な von Neumann Bottleneck は CPU の追加能力値を制限します。
 GPU (グラフィックスプロセッシングユニット) はこうした動向から生まれたもので、いくつものチャレンジに対応しています。プロセッサがクロック速度の上限に達しても、設計者はムーアの法則でより多くのトランジスタを使用することができます。従来のアーキテクチャに対し、より多くのキャッシュやメモリを追加するためにトランジスタを使用することができますが von Neumann Bottleneck はそれを制限します。逆に、現在では専用ハードウェア (GPU 消費の先駆けとしてはゲームなど) が大きな市場になっています。これらをまとめると、GPU はスケールアップ (プロセッサ速度の上昇やボトルネックメモリ) の代わりにスケールアウト (より多くのプロセッサと平行する蓄積したメモリ) を行っていることが分かります。Net-net: GPU は多くのトランジスタを使用して大量の処理能力を提供する上で効率的な方法です。
GPU (グラフィックスプロセッシングユニット) はこうした動向から生まれたもので、いくつものチャレンジに対応しています。プロセッサがクロック速度の上限に達しても、設計者はムーアの法則でより多くのトランジスタを使用することができます。従来のアーキテクチャに対し、より多くのキャッシュやメモリを追加するためにトランジスタを使用することができますが von Neumann Bottleneck はそれを制限します。逆に、現在では専用ハードウェア (GPU 消費の先駆けとしてはゲームなど) が大きな市場になっています。これらをまとめると、GPU はスケールアップ (プロセッサ速度の上昇やボトルネックメモリ) の代わりにスケールアウト (より多くのプロセッサと平行する蓄積したメモリ) を行っていることが分かります。Net-net: GPU は多くのトランジスタを使用して大量の処理能力を提供する上で効率的な方法です。
こうしたバックグランドを踏まえた上で最新の EC2 インスタンスタイプ、P2 についてご説明します。このインスタンスは大規模な機械学習、深層学習、計算流体力学 (CFD)、耐震解析、分子モデリング、ゲノム、金融工学のワークロードに対応できるように設計されています。
新しい P2 インスタンスタイプ
この新しいインスタンスタイプは NVIDIA Tesla K80 アクセラレーター を8つまで組み込むことが可能です。それぞれ NVIDIA GK210 GPU ペアを実行します。各 GPU はそれぞれ 12 GB のメモリ (メモリ帯域幅 240 GB/秒 経由でアクセス可能) と、2,496 の並列処理コアを提供します。ECC メモリ保護も含んでいるため、シングルビットエラーの修正とダブルビットエラーの検出を可能にします。ECC メモリ保護と倍精度の浮動操作の組み合わせにより、こうしたインスタンスは上記のワークロードすべてにおいて最適です。
インスタンスのスペックは次をご覧ください。
| インスタンス名 | GPU カウント | vCPU カウント
|
メモリ | 並列処理コア
|
GPU メモリ
|
ネットワークパフォーマンス
|
| p2.xlarge | 1 | 4 | 61 GiB | 2,496 | 12 GiB | 高 |
| p2.8xlarge | 8 | 32 | 488 GiB | 19,968 | 96 GiB | 10 ギガビット |
| p2.16xlarge | 16 | 64 | 732 GiB | 39,936 | 192 GiB | 20 ギガビット |
インスタンスはすべて 2.7 GHz で実行している Intel の Broadwell プロセッサで AWS 固有バージョンを使用しています。p2.16xlarge は C ステートと P ステートのコントロールを可能にするほか、1 コアまたは 2 コアで実行している場合に 3.0 GHz まで高速化することができます。
GPU は CUDA 7.5 以上、 OpenCL 1.2 と GPU コンピューティング API をサポートします。p2.8xlarge と p2.16xlarge の GPU は一般的な PCI fabric 経由で接続します。これにより低レイテンシーのピアツーピア でのGPU間の転送を可能にします。
インスタンスはすべて新しい Enhanced Network Adapter を使用します (ENA – 詳しくは「Elastic Network Adapter – Amazon EC2 のハイパフォーマンスネットワークインターフェイス」をご覧ください)。また、上記の表のようにプレイスメントグループ内で使用した場合は低レイテンシーで 20 Gbps までサポートすることができます。
単一インスタンス上での、パワフルな複数 vCPU プロセッサと、適切に接続されている複数 GPU と、加えて同じ機能を持つ別のインスタンスへの低レイテンシーアクセスがあるので、スケールアウト処理での非常に優れた階層を作成することができます。
- 1個の vCPU
- 複数の vCPU
- 1 個の GPU
- 単一インスタンスで複数の GPU
- プレイスメントグループ内の複数のインスタンスで複数の GPU
P2 インスタンスは VPC のみを対象にしており、64 ビット、HVM 形式、EBS-backed AMI を使用する必要があります。この機能は US East (Northern Virginia)、US West (Oregon)、Europe (Ireland) リージョンにてオンデマンドインスタンス、スポットインスタンス、リザーブドインスタンス、専用ホストとして今日からご利用いただけます。
下記は私が P2 インスタンスで NVIDIA ドライバと CUDA ツールキットをインストールした時の例です。その前に CUDA ツールキットと関連のサンプル用に十分な余裕(10 GiBもあれば十分です)を持った EBS ボリュームを作成、フォーマット、アタッチ、(/ebsに)マウントしてから実行しました 。
$ cd /ebs
$ sudo yum update -y
$ sudo yum groupinstall -y "Development tools"
$ sudo yum install -y kernel-devel-`uname -r`
$ wget http://us.download.nvidia.com/XFree86/Linux-x86_64/352.99/NVIDIA-Linux-x86_64-352.99.run
$ wget http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_linux.run
$ chmod +x NVIDIA-Linux-x86_64-352.99.run
$ sudo ./NVIDIA-Linux-x86_64-352.99.run
$ chmod +x cuda_7.5.18_linux.run
$ sudo ./cuda_7.5.18_linux.run # Don't install driver, just install CUDA and sample
$ sudo nvidia-smi -pm 1
$ sudo nvidia-smi -acp 0
$ sudo nvidia-smi --auto-boost-permission=0
$ sudo nvidia-smi -ac 2505,875
以下の点に注意してください。 NVIDIA-Linux-x86_64-352.99.run と cuda_7.5.18_linux.run はインタラクティブプログラムです。ライセンス契約に同意しオプションをいくつか選択してパスを入力する必要があります。私が設定した CUDA ツールキットと実行時のサンプルは次の通りです。 cuda_7.5.18_linux.run:
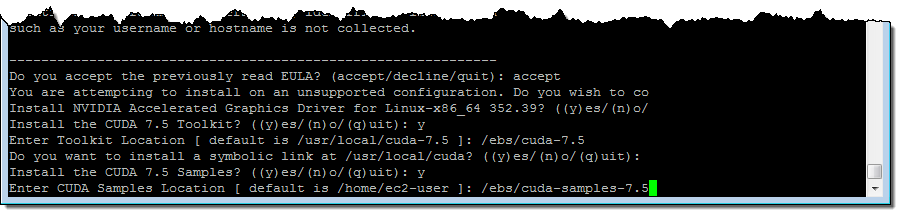
P2 と OpenCL の一例
設定をすべて完了してから、この Gist を p2.8xlarge インスタンスでコンパイルしました。
[ec2-user@ip-10-0-0-242 ~]$ gcc test.c -I /usr/local/cuda/include/ -L /usr/local/cuda-7.5/lib64/ -lOpenCL -o testレポートは次の通りです。
[ec2-user@ip-10-0-0-242 ~]$ ./test
1. Device: Tesla K80
1.1 Hardware version: OpenCL 1.2 CUDA
1.2 Software version: 352.99
1.3 OpenCL C version: OpenCL C 1.2
1.4 Parallel compute units: 13
2. Device: Tesla K80
2.1 Hardware version: OpenCL 1.2 CUDA
2.2 Software version: 352.99
2.3 OpenCL C version: OpenCL C 1.2
2.4 Parallel compute units: 13
3. Device: Tesla K80
3.1 Hardware version: OpenCL 1.2 CUDA
3.2 Software version: 352.99
3.3 OpenCL C version: OpenCL C 1.2
3.4 Parallel compute units: 13
4. Device: Tesla K80
4.1 Hardware version: OpenCL 1.2 CUDA
4.2 Software version: 352.99
4.3 OpenCL C version: OpenCL C 1.2
4.4 Parallel compute units: 13
5. Device: Tesla K80
5.1 Hardware version: OpenCL 1.2 CUDA
5.2 Software version: 352.99
5.3 OpenCL C version: OpenCL C 1.2
5.4 Parallel compute units: 13
6. Device: Tesla K80
6.1 Hardware version: OpenCL 1.2 CUDA
6.2 Software version: 352.99
6.3 OpenCL C version: OpenCL C 1.2
6.4 Parallel compute units: 13
7. Device: Tesla K80
7.1 Hardware version: OpenCL 1.2 CUDA
7.2 Software version: 352.99
7.3 OpenCL C version: OpenCL C 1.2
7.4 Parallel compute units: 13
8. Device: Tesla K80
8.1 Hardware version: OpenCL 1.2 CUDA
8.2 Software version: 352.99
8.3 OpenCL C version: OpenCL C 1.2
8.4 Parallel compute units: 13
ご覧のように、すぐに使用できる膨大な処理能力があることが分かりました。
新しい深層学習AMI
このブログの冒頭で触れましたが、これらインスタンスは機械学習、深層学習、計算流体力学 (CFD)、構造計算、分子モデリング、ゲノム、金融工学のワークロードに最適です。
1 つ以上の P2 インスタンスの活用を助けるために、本日 深層学習AMI をリリースしました。深層学習は、もっと複雑でより大量な計算トレーニングプロセスを要するレベルの低い機械学習での予測に比べ、より信頼性が高い予測 (スコアや推論とも呼ばれます) を生成できる可能性を備えています。幸い、新世代の深層学習ツールは単一インスタンスにおける複数の GPU や、複数の GPU を含む複数のインスタンスに渡り、トレーニングワークを分散させることができます。
新しい AMI には次のフレームワークが含まれています。いずれもインストールおよび設定済みで、人気の MNIST データベースに対してテストも行われています。
MXNet – 柔軟性に優れポータブルな、深層学習において効率的なライブラリです。C++、Python、R、Scala、Julia、Matlab、JavaScript を含む幅広いプログラミング言語に渡り宣言型プログラミングや命令型プログラミングをサポートします。
Caffe – 表現力、速度、モジュール性を念頭に設計された深層学習のフレームワークです。Berkeley Vision and Learning Center (BVLC) と様々なコミュニティの協力者により開発されました。
Theano – この Python ライブラリは多次元配列に関する数式を定義、最適化、評価します。
TensorFlow™ – データフローグラフ (グラフの各ノードが算術演算、各エッジがノード間の多次元データの通信を表現) を使用した数値計算のオープンソースライブラリです。
Torch – 機械学習アルゴリズムのサポートを備えた GPU 指向の科学計算フレームワークです。すべて LuaJIT 経由でアクセスすることができます。
次の README ファイル ( ~ec2-user/src ) でフレームワークの詳細をご覧ください。
AMIs from NVIDIA
興味があれば次の AMI も合わせてご覧ください。
- NVIDIA ドライバ使用の Windows Server 2012
- Amazon Linux の NVIDIA CUDA ツールキット 7.5
- Ubuntu 14.04 の NVIDIA DIGITS 4
— Jeff;