Amazon Web Services ブログ
Amazon SageMaker の自動モデルチューニングによるポートフォリオ値の最適化
信用貸しを行う金融機関は、各融資申請に関連する信用リスクを評価し、引き受けるリスクのレベルを定義するしきい値を決定するという二重のタスクに直面しています。信用リスクの評価は、機械学習 (ML) 分類モデルを一般的に当てはめて行います。ただし、分類のしきい値の決定は、多くの場合、副次的な関心事として扱われ、その場しのぎで原則のない方法で設定されます。その結果、金融機関はパフォーマンスの低いポートフォリオを作成し、リスク調整後のリターンをテーブルに残している可能性があります。
このブログ記事では、Amazon SageMaker の自動モデルチューニングを使用して、融資対象の借り手のサブセットを選択する貸し手のポートフォリオ値を最大化する分類しきい値を決定する方法について説明します。より一般的には、分類設定で最適なしきい値またはしきい値のセットを選択する方法について説明します。ここで説明する方法は、経験則や一般的なメトリクスに依存しません。これは、目前の問題に固有のビジネスの成功指標に依存する体系的かつ原則的な方法です。この方法は、効用理論と、合理的な個人は期待される効用または主観的価値を最大化するために意思決定を行うという考えに基づいています。
この記事では、貸し手は、融資申し込みを、受け入れた上で貸し出すグループと、受入れを拒否するグループの 2 つのグループに分ける分類のしきい値を選択することにより、ポートフォリオの期待ドル価値を最大化しようとしていると仮定します。言い換えれば、貸し手は、ポートフォリオ値を説明する関数の最高値となるしきい値を見つけるために、潜在的なしきい値のスペースを検索しています。
この記事では、Amazon SageMaker の自動モデルチューニングを使用して、最適なしきい値を見つけます。付随する Jupyter ノートブックは、このユースケースをサポートするコードを示しています。これは、モデルのパフォーマンスを最適化するハイパーパラメータを選択するために通常使用する自動モデルチューニング機能の新しい使用法です。この記事では、特定のパラメータ空間で関数を最大化する一般的なツールとして使用しています。
このアプローチには、一般的なしきい値決定アプローチに比べていくつかの利点があります。通常、分類しきい値は 0.5 に設定されます (またはデフォルトに設定されます)。このしきい値は、ほとんどのユースケースで可能な最大の結果を生成しません。対照的に、ここで説明するアプローチでは、対処する特定のビジネスユースケースの最大の結果を生成するしきい値を選択します。この記事のユースケースでは、説明した方法で最適なしきい値を選択すると、ポートフォリオ値が 2.1% 増加します。
また、このアプローチは、最適なしきい値を決定する際に一般的な経験則と専門家の判断を使用するだけではありません。分類問題に体系的に適用できる構造化されたフレームワークをレイアウトします。さらに、このアプローチでは、モデルの予測とその利点とコストに対して実行される特定のアクションに基づいて、ビジネスがコストマトリクスを明示的に提示する必要があります。この評価プロセスは、モデルの分類結果を単純に評価するだけではありません。このアプローチは、ビジネスにおける挑戦的な議論を促し、オープンな議論と合意のためにさまざまな暗黙の意思決定や評価を明らかにすることができます。これにより、単純な「この価値の最大化」から、より複雑な経済的トレードオフを可能にするより有益な分析に至る議論が促進され、ビジネスにより多くの価値がもたらされます。
| このブログ記事について | |
| 読む時間 | 20 分 |
| 完了するまでの時間 | 1.5 時間 |
| 完了するためのコスト | ~2 USD |
| 学習レベル | 高度 (300) |
| AWS のサービス | Amazon SageMaker |
背景
貸し手が潜在的なローンのプールからポートフォリオを構築しようとしていると仮定します。このユースケースに取り組むには、貸し手はまず、各ローンのデフォルトの確率を計算することにより、プール内の各ローンに関連する信用リスクを評価する必要があります。ローンに関連するデフォルトの可能性が高いほど、ローンに関連する信用リスクが高くなります。ローンのデフォルトの確率を計算するために、貸し手はロジスティック回帰やランダムフォレストなどの ML 分類モデルを使用します。
貸し手がデフォルトの確率モデルを推定したとすると、ローンが有し得る最大のデフォルト確率を設定し、ローンを貸し出す意思があるしきい値をどのように選択すればよいでしょうか? 分類モデルのユーザーは、多くの場合、しきい値の値を従来のデフォルト値の 0.5 に設定しています。ユースケース固有のしきい値を設定しようとしても、精度や再現率などのしきい値ベースのメトリクスを最大化することに基づいて設定します。メトリクスの問題の 1 つは、分類マトリクスに記述されている個別の結果の特定の部分を無視することです。たとえば、精度は真と偽の負の結果を見落とします。さらに、これらのメトリクスには、分類マトリクスの各セルに関連するコストと利点が組み込まれていません。たとえば、この記事で検討する場合、各ローンに関連付けられたデフォルトを考慮した金利と損失は、一般的なしきい値ベースの測定の計算では無視されます。最終的に、ビジネスの価値はそのモデルの精度や再現率ではなく、特定のモデルとしきい値を使用することによる増分利益のドル価値であるため、この状況は理想的ではありません。
したがって、一般的なメトリクスを使用する代わりに、目の前の特定のビジネスユースケースのコストと利益の構造を捉えたしきい値ベースのメトリクスを設計することが、ビジネスにとってより有益で有意義です。この記事で説明する貸し手は、特定の借り手に貸すかどうかを決定しています。そのため、予測されるデフォルトの確率を考慮して各ローンの予想利子と損失を組み込んだメトリクスは、精度や再現率などの一般的なメトリクスよりも、ビジネスとその意思決定プロセスにより関連性があります。具体的には、定義するポートフォリオ値メトリクスは、各ローンを真陽性 (TP)、偽陰性 (FN)、真陰性 (TN)、および偽陽性 (FP) の 4 つのバケットのいずれかに分類します。次のガイドラインを使用して、ローンの各バケットの値を計算します。
TP 値= -Fixed_Cost
FN 値= -Fixed_Cost – Loss_Given_Default * Outstanding_Principal_Balance
TN 値= -Fixed_Cost + Interest_Rate * Outstanding_Principal_Balance
FP 値= -Fixed_Cost
Fixed_Cost は、ローンの承認に関係なく、ローンの処理に関連するコストを捉えます。
Outstanding_Principal_Balance は、デフォルトまたは全額返済時に残っている元本です。
Interest_Rate は、特定のローン申し込みに関連するデフォルトの確率に加えて、貸し手が希望する期待リターンに基づいて設定される借り手固有のレートです。
Loss_Given_Default は、ローンがデフォルトになった場合に失われると予想される元本の割合です。
ローンの特定のバケットの合計値を計算するために、すべてのローンの値を合計します。この合計は、貸し手がしきい値を選択して最大化しようとするものです。
貸し手がポートフォリオ値の定量的尺度を明確に定義したら、その尺度を最大化するしきい値を選択する必要があります。Amazon SageMaker の自動モデルチューニングを使用して、最適なしきい値を見つけます。Amazon SageMaker 自動モデルチューニングは、ML モデルのハイパーパラメータを調整するだけでなく、任意の関数を最大化するための強力なツールです。この場合、次の 2 つの方法で自動モデルチューニングを使用します。
- 貸し手のポートフォリオ値を最大化するしきい値の選択を見つける方法。
- しきい値とポートフォリオ値の関係をより一般的にマッピングする方法。
しきい値の選択とポートフォリオの値との関係を理解することにより、しきい値の増減による経済的トレードオフをより完全に理解できます。貸し手は、単にポートフォリオのドル価値を最大化するだけでなく、追加の目標を検討することが多いため、これは重要です。貸し手の中には、特異な二次的な目標を持っているところもあります。たとえば、貸し手は、ポートフォリオ値を最大化すると同時に、経済の特定のセクターまたは人口全体の特定のサブグループへの貸付に力を入れたい場合もあるかもしれません。しきい値が変動したときにポートフォリオの値がどのように変化するかを知ることにより、貸し手は、ポートフォリオの最大化という主要な目標と追加の二次的な目標の双方に対処する合理的なしきい値を設定できます。
この作業ではいくつかの仮定を行います。ここでは、貸し手は、デフォルトの確率に関連するすべてのローンを、選択したしきい値以下で貸し出すために必要な資本にアクセスできると想定します。その意味で問題は制約されていません。さらに、ローンが承認された場合、申請者は、貸し手が提供する金利に関係なく、ローンの条件に同意すると想定します。最後に、貸し手はリスク中立である、つまり貸し手の効用関数は恒等関数であると仮定します。言い換えれば、特定のポートフォリオ値から貸し手が得る効用は、ポートフォリオ値そのものに等しいことになります。
実行可能コードを含む Amazon SageMaker ノートブックは、この GitHub repo で入手できます。Amazon SageMaker 自動モデルチューニングを使用するには、Amazon SageMaker ノートブックインスタンス内でこのノートブックを実行する必要があります。これを行うには、前述の GitHub リンクからこの記事に関連付けられている Jupyter ノートブックをダウンロードします。Amazon SageMaker ノートブックインスタンスを作成し、Jupyter ノートブックをこのノートブックインスタンスにアップロードします。最後に、ノートブックを開き、コードを手順に従って実行します。詳細については、「ノートブックインスタンスの作成」を参照してください。この記事では HTML バージョンを提供しているため、コードを実行する必要なく確認できます。
ソリューションの概要
次のセクションでは、以下の手順を順に説明します。
- モデルトレーニング用の一連のローンデータを用意します。
- Amazon SageMaker 組み込みの Scikit-learn Estimator を使用して、ランダムフォレスト分類子をトレーニングします。
- 初期モデルのパフォーマンスを分析します。
- 自動モデルチューニングを使用して、最高のポートフォリオ値をもたらすしきい値を見つけます。
- デフォルトのしきい値を使用するポートフォリオと比較したポートフォリオパフォーマンスを分析します。
- 追加のビジネス目標を組み込み、ポートフォリオへの影響を分析します。
ローンデータ
データは、1987 年から 2014 年までの一連の米国中小企業庁 (SBA) 保証ローンで構成されています。これらは、民間銀行によって米国に拠点を置く中小企業に行われたローンですが、米国 SBA は、債務者のデフォルトが発生した場合に元本の大部分を保証します。平均して、SBA はこのデータセットの各ローンの元本の約 70% を保証します。この大規模な保証は、各ローンに関連する信用リスクの大部分を相殺し、民間銀行が他の方法では行わなかったかもしれない中小企業への信用供与を奨励します。データ自体およびデータの詳細な説明については、Li、Mickel、Taylor の補足資料を参照してください。この研究論文の使用に関連するライセンスにも目を通してください。
私たちの目標は、特定のローンがデフォルトになる確率を予測するモデルを構築することです。したがって、ターゲット変数は MIS_Status です。MIS_Status は 2 つの値を取ります。ローンの全額が弁済された場合は「P I F」、ローンがデフォルトとなり銀行が結果として生じた損失を引き受けた場合は「CHGOFF」。
付属のノートブックには、ターゲット変数のバランスが取れていないことが示されています。観測の約 18% がデフォルトになっています。この不均衡に対処するための私たちのアプローチは、データをそのまま使用してモデルを推定し、その後、決定用のしきい値を設定して、信用ポートフォリオの経済的価値を最適化することです。
モデルのトレーニング
次に、Amazon SageMaker 組み込みの Scikit-learn Estimator を使用して、ランダムフォレスト分類子をトレーニングします。ロジスティック回帰と勾配ブースト分類子の両方のパフォーマンスと比較した後、ランダムフォレストを選択しました。Amazon SageMaker 組み込みの推定子を使用すると、カスタム Docker コンテナを作成および管理する必要なく、カスタム Scikit-learn モデルを構築およびデプロイできます。
詳細については、「Amazon SageMaker Python SDK での Scikit-learn の使用」を参照してください。
ランダムフォレストのトレーニングの詳細については、この記事に関連するノートブックの「モデルのトレーニング」セクションを参照してください。
モデルパフォーマンスの分析 (パート 1)
比較のために、単純なモデルを作成し、すべての観測値を多数派クラスに分類します。つまり、ローンがデフォルトにならないと予測します。ランダムフォレストのパフォーマンスは、単純なモデルよりも優れているのでしょうか?
ランダムフォレストモデルの予測をデフォルトクラスまたは非デフォルトクラスに分類するための最適なしきい値をまだ決定していません。したがって、上記の質問に答えるために利用できるパフォーマンスメトリクスは、モデルが出力する予測クラス確率に基づくものだけです。クラスの予測に基づくメトリクス、たとえば、正確性、精度、再現率は、未定義のしきい値に依存しています。したがって、最初にこの質問に答えるために、ランダムな予測と単純なモデルのログ損失を比較します。ログ損失は、予測されたクラス確率が実際のラベルからどれだけ乖離しているかを計算します。したがって、ログ損失は、しきい値を参照せずに決定できるメトリクスです。
最適なしきい値を計算した後、使い慣れたしきい値ベースのメトリクスを使用して、モデルのパフォーマンスをより徹底的に分析します。
ログ損失の計算
ランダムフォレストのパフォーマンスは、単純なモデルよりも優れているのでしょうか? ログ損失が少ないほど、エラーが少なくなり、パフォーマンスが向上することを覚えておいてください。モデル実行からの次の出力は、結果を示しています。
答えはイエスです。ランダムフォレストは、ナイーブモデルのログ損失を大幅に改善します。これは、ランダムフォレストモデルが、単純なモデルの予測よりも真実にはるかに近い予測クラス確率を各観測に割り当てたことを意味します。
モデル予測のプロット
次の各プロットセットでは、上部のヒストグラムは、すべての実際の陰性の予測スコアの分布、つまり、デフォルトにならない借り手の予測スコアの分布をプロットします。本質的には、特異性に関連付けられたスコア分布を表します。下のヒストグラムは、実際のポジティブの予測スコア、つまりデフォルトになる借り手の予測スコアをプロットすることにより、感度のスコア分布を表しています。
それぞれのプロットで正しく分類された観測値は青色で表示され、誤って分類された観測値はオレンジ色で表示されています。これらのプロットに色を付けるには、デフォルトのしきい値 0.5 を使用します。これは、分類モデルの結果を分類するために使用する一般的なしきい値であり、ユーザーの成功 (または価値) メトリクスを最大化しようとせずに選択されます。
しきい値の選択は、実際の予測スコア、形状、またはプロットのレベルには影響せず、色付けにのみ影響します。ただし、感度、特異性、および最も一般的に使用されるモデルパフォーマンスメトリクスを含むメトリクス結果に影響します。
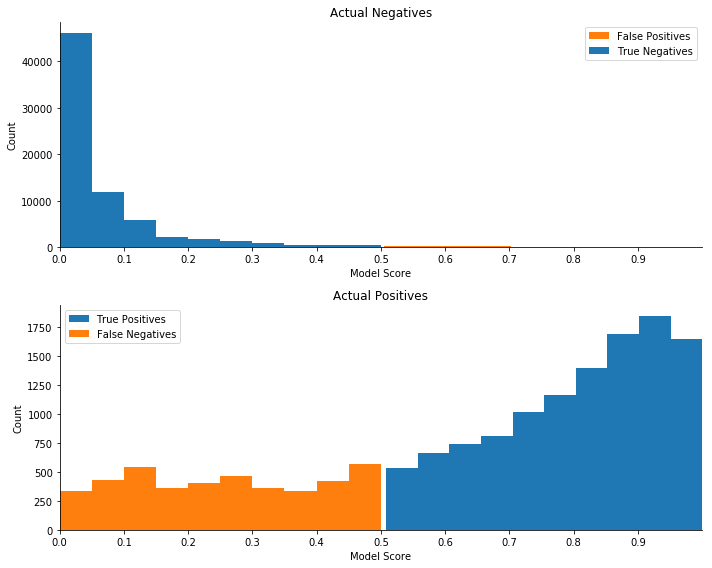
これらの 2 つのグラフは、真陰性のスコアが 0 近くにクラスター化されているのに対し、偽陰性のスコアは 0 から現在のカットオフの 0.5 まで比較的均等に分布していることを示しています。データセットには、真陰性と偽陰性を強力に区別できるデータ項目は含まれていません。
この分配は、承認および却下されたローンのこのポートフォリオから見落とされている潜在的な収益のかなりの量を指している可能性があります。ローンの承認にデフォルトのしきい値スコア 0.5 を使用することは、このデータセットには最適ではありません。しきい値を最適化することでポートフォリオ値をさらに高める方法を探ってみましょう。
0.5 のしきい値に基づいてポートフォリオ値を計算する
最後に、0.5 のしきい値に基づいて、単純なモデルとランダムフォレストモデルのポートフォリオ値を計算します。これらのポートフォリオ値は、最適なしきい値を選択することでローンポートフォリオの値が増加するかどうかを判断するための参照ポイントとして機能します。
すべてのローンのデフォルトの確率は 0 であるため、ゼロ以外のしきい値は、単純なモデルで同じポートフォリオ値になります。次の出力は、計算されたポートフォリオ値を示しています。
自動モデルチューニングを使用した最適な分類しきい値の決定
別のしきい値を選択することで、さらに改善できるでしょうか? そして、貸し手のリスクと報酬のバランスをとる最適なしきい値を見つけるにはどうしたらよいでしょうか?
このセクションでは、ローンをデフォルトまたはデフォルト以外に分類するための最適なしきい値は、Amazon SageMaker の自動モデルチューニングで決定します。最適なしきい値は、ユーザーの値のメトリクスを最大化するしきい値です。この場合、最大化されているメトリクスは、前述のようにポートフォリオの合計値です。
Amazon SageMaker の自動モデルチューニングを使用して分類しきい値を最適化するには、以前にトレーニングしたランダムフォレストモデルとテストセットを入力値として使用する Docker コンテナを構築します。貸し手がデフォルト以外として分類されたすべてのローンを貸し出し、借り手がそれらを受け入れた場合、しきい値を指定すると、コンテナはポートフォリオの合計値を計算します。Amazon SageMaker の自動モデルチューニングにより、0~1 の範囲のしきい値が生成され、ポートフォリオ値を最大化するしきい値が選択されます。自動モデルチューニングジョブの詳細なコードについては、この記事に関連するノートブックの「自動モデルチューニングによる最適な分類しきい値の決定」セクションを参照してください。
自動モデルチューニングジョブの実行
Amazon SageMaker 自動モデルチューニング機能を使用するには、まず Amazon SageMaker で最適化するメトリクス、チューニングジョブで最適なしきい値を見つけるために検索するパラメータスペース、およびチューニング作業中に計算が必要な追加のメトリクスを定義する必要があります。
このブログ記事に関連付けられたノートブックでは、各ジョブに返すメトリクスを定義します。生成されたポートフォリオの特性を詳細に調べたいので、承認されたローンと拒否されたローンを説明するメトリクスのリストを生成します。これらのメトリクスは、自動モデルチューニングを介して実行される各トレーニングジョブから報告されます。追加のメトリクスにより、最大化されたポートフォリオの特性を調査できます。
定義するすべてのメトリクスのうち、自動モデルチューニングジョブがしきい値を最適化するために使用するメトリクスを指定する必要があります。これを行うには、次の HyperparameterTuner オブジェクトで objective_metric_name を指定します。同じオブジェクトで、検索するハイパーパラメータの範囲を指定します。この場合、0 から 1 までのすべての連続値を指定して、最適なしきい値を検索します。
最後に、Amazon SageMaker で 200 の個別のトレーニングジョブを実行するように指定します。200 のトレーニングジョブはそれぞれ、特定のしきい値を使用して、異なるポートフォリオ値を計算します。Amazon SageMaker は、それぞれ異なるしきい値に基づいて 200 のポートフォリオ値を計算した後、ポートフォリオ値を最大化するしきい値を出力します。
このジョブの実行には最大 1 時間かかります。
モデルパフォーマンスの分析 (パート 2)
このセクションでは、単純なモデルとランダムフォレストモデルのパフォーマンスの分析を続けますが、最適なしきい値を決定したので、しきい値ベースのメトリクスを分析に組み込むことができます。
自動モデルチューニングジョブの結果のプロット
次の散布図の平坦度は、予測の精度によるものです。これは、ランダムフォレストモデルのツリー数の関数です。ランダムフォレストモデルには 100 本の木があるため、予測の精度は小数点以下 2 桁です。これは、すべてのしきい値 (たとえば、>.32 と <=.33) が同じ結果になることを意味します。
最適なしきい値が与えられた場合の予測分布のプロット
最適なしきい値がわかったので、ランダムフォレストモデルの確率予測をプロットし、それぞれを正しいか正しくないかを分類できます。上のヒストグラムは、すべての実際の陰性の予測スコアの分布、つまり実際の非債務不履行者の予測スコアのプロットです。下のヒストグラムは、実際の債務不履行者の予測スコアをプロットしたものです。それぞれのプロットで正しく分類された観測値は青色で、誤って分類された観測値はオレンジ色です。
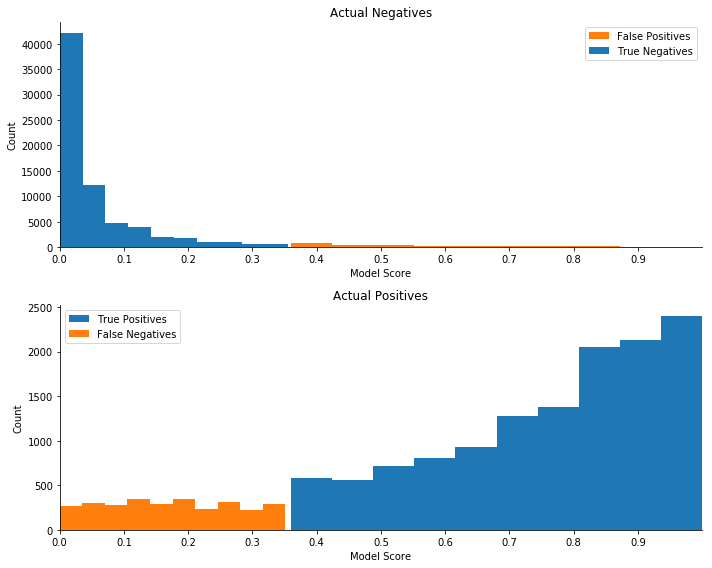
プロットは、最適なしきい値が 0.5 未満で、実際の陽性の大半の左側にあることを示しています。しきい値は、しきい値が増加するにつれて真陰性の変化率が遅くなり、偽陰性の変化率が速くなる地点にあるようです。自動モデルチューニングジョブは、2 つの変化率のバランスをとるしきい値を選択したようです。最適なしきい値の選択をよりよく理解するには、ポートフォリオ値の計算をより深く掘り下げ、しきい値の変更に伴うコストとメリットを理解する必要があります。
最大ポートフォリオ値の決定
次のグラフは、自動モデルチューニングジョブの出力をプロットしています。つまり、特定のしきい値 (x 軸) を考慮して、ポートフォリオ値 (y 軸) をプロットします。プロット上の各ポイントは、自動モデルチューニングジョブ全体からの単一のトレーニングジョブの結果を表します。目標は、ポートフォリオ値全体を最適化する分類しきい値を見つけることであることを思い出してください。各プロットで、最適なしきい値はオレンジ色の縦線です。
左端のグラフは、200 件すべてのトレーニングジョブの結果をプロットしています。中央のグラフは、ポートフォリオ値でランク付けされた上位 100 のトレーニングジョブをプロットし、右端のグラフは、これもポートフォリオ値でランク付けされた上位 50 のトレーニングジョブをプロットしています。
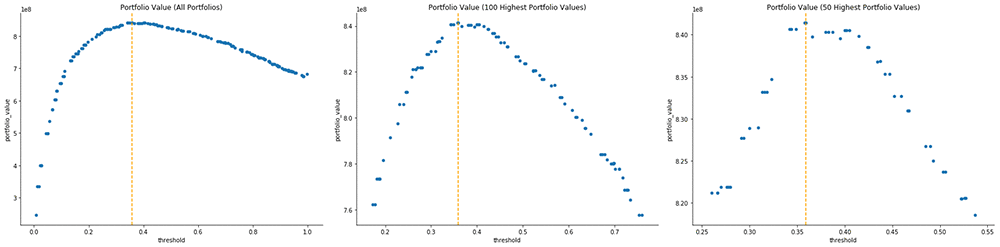
興味深いことに、しきい値を最適値を超えて増加させるときの変化率の大きさは、しきい値を 0 から最適値まで増加させるときの変化率の大きさよりも一般的にはるかに低くなります。この非対称性は、SBA の保証によるものです。この保証は、貸し手が借用基準を緩めるときに、貸し手が引き受ける下振れリスクを制限します。SBA の保証が設定されていなかった場合、このグラフの右側がさらに急激に減少することが予想されます。
右側の 2 つのグラフを見て、曲線のピークを拡大すると、最適なしきい値を中心に対称になっていることがわかります。さらに、曲線は最適なしきい値を超えた後、厳密に減少しません。時々、曲線は短時間増加します。次の出力は、各モデルのポートフォリオ値を示しています。
最適化されたしきい値を持つランダムフォレストモデルから返された最上位のポートフォリオ値は、0.5 しきい値で単純なモデルとランダムフォレストモデルによって生成された両方の値よりも高くなります。しきい値を調整することによるポートフォリオ値の増加は、1770 万 USD、つまり 2.1% であり、潜在的なリターンが大幅に増加しています。
興味深いことに、最適なしきい値は 0.5 未満であるため、貸し手はポートフォリオ内のローンの信用リスクを下げる (しきい値を下げる) ことでポートフォリオの全体的な価値を高めることができます。貸し手が 0.5 のしきい値 (通常のデフォルト値) を使用していた場合、おそらく、信用リスクが高くポートフォリオ値が低いポートフォリオを作成した可能性があります。SBA の保証がこれらのローンに適用されていなかった場合、0.5 のしきい値でのポートフォリオ値ははるかに低かったでしょう。
最大ポートフォリオ値に関連するリターンの分析
このセクションは、ポートフォリオのドル建てのリターンに焦点を当てることから、パーセンテージリターンにシフトします。次の一連のグラフは、自動モデルチューニング実行の 200 のトレーニングジョブのそれぞれに関連付けられたポートフォリオの純収益をプロットすることを除いて、前のセットと似ています。オレンジ色の縦線も最適なしきい値であり、ポートフォリオのリターンではなく、ポートフォリオ値を最大化するという意味で最適であり、X 軸がしきい値です。y 軸はポートフォリオのリターンです。

これらのグラフは、左から右に、200 件すべてのトレーニングジョブの結果、上位 100 件の結果 (ポートフォリオ値に基づく)、および上位 50 件の結果 (ポートフォリオ値に基づく) をプロットしています。これらのリターン曲線は、前のグラフセットのポートフォリオ値曲線よりもはるかに平坦です。これは、貸し手が融資する各ローンに積極的に金利を設定し、ポートフォリオ全体のリターンが約 5% になると予想されるためです。さらに、最適なしきい値はポートフォリオリターンのピークをマークしないことに注意してください。これは、ポートフォリオ値を最大化するときに、ローンを追加することでポートフォリオの収益率が上がるかどうかは関係なく、ローンを追加するだけでポートフォリオのドル建てのリターンが増えるためです。より低い割合のリターンローンをポートフォリオに追加し、それでもドル単位でプラスの値を追加することができます。それが私たちが最大化しようとしていることです。
次の出力は、リターンの計算結果を示しています。
同様に、最適化されたしきい値を持つランダムフォレストモデルのポートフォリオリターンは、2 つのランダムフォレストモデルから生成されたリターンは類似していますが、単純なモデルによって生成されたものよりもはるかに高くなります。これは、これらのモデルの両方で、貸し手が借り手固有の金利を設定して、借り手固有の信用リスクを補うことができるためです。しきい値が高くなり、リスクの高いローンがポートフォリオに入ると、貸し手はそれらのローンに高い金利を設定し、平均して同じリターンを維持できます。
追加のビジネス上の考慮事項に基づいて最適なしきい値を調整する
次に、最適なしきい値をわずかに調整する必要があるかどうかを判断する方法を詳しく見ます。以前に計算した最適なしきい値を調整する必要があるのはなぜでしょうか? 貸し手が達成したい特定の特異な目標があるかもしれませんが、それは一般的なポートフォリオ値計算では捉えられません。たとえば、貸し手は、ポートフォリオ値を最大化すると同時に、経済の特定のセクターまたは人口全体のサブグループへの貸し出しに力を入れたい場合があるかもしれません。ポートフォリオ値の計算自体にこの追加の制約を追加することは、不可能ではないにしても難しいかもしれません。これらの問題に 2 つのステップで取り組む — 一般的な最適値を見つけてから、特異な好みに基づいてその最適値を調整することは、計算がはるかに簡単で直感的です。
例として、貸し手は経済の建設部門により多くの信用を拡大したいと考えています。この目標を達成するために最適なしきい値を上げるべきかどうかを判断したいと考えています。基本的に、ポートフォリオにもう 1 つの建設部門ローンを含めるために支払う意思のある価格と、そのローンを含めることのポートフォリオ値への影響を決定する必要があります。価格がコストより大きい場合、彼女はしきい値を上げる必要があります。
より具体的には、貸し手がしきい値を 0.01 (この場合の最小の増分) だけ増やすべきかどうかの質問に答えるために、次のことを行う必要があります。
- 追加の建設ローンごとに支払う意思のある価格 P を決定します。
- しきい値を 0.01 増やした結果生じるポートフォリオ値の減少を計算します。
- しきい値が増加したときにポートフォリオに追加される建設部門のローンの数を計算します。
- ポートフォリオ値の変化を追加された建設ローンの数で割ることにより、追加の各建設ローンの平均コストを計算します。これは、ドル単位での追加の各建設ローンの平均コスト C です。
- 貸し手が建設工事の追加ごとに支払う意思のある価格 P と、追加の建設ローンごとに実際に支払わなければならないコスト C を比較します。
- 支払意思額がコストよりも大きい場合 (P >= -C)、しきい値を 0.01 増やします。
- それ以外の場合は、しきい値をそのままにします。
- しきい値を上げるのが有利でなくなるまで、手順 2~5 を繰り返します。
以下の計算の詳細については、この記事に関連するノートブックをご覧ください。
ステップ 1: 貸し手の支払い意思の決定
貸し手は、最初に追加の建設部門ローンごとに放棄するポートフォリオ値の額を決定する必要があります。この例の貸し手の支払い意思額 P は 75,000 USD であると仮定します。
ステップ 2: ポートフォリオ値の減少を決定する
貸し手は、最適なしきい値と次に高いしきい値でポートフォリオの値を計算し、次に差を計算して、最小単位でしきい値を上げるとポートフォリオの値がどれだけ減少するかを判断する必要があります。これは次のように計算されます。
ステップ 3: 建設ローンの増加数の決定
次に、しきい値が 0.01 増加したときにポートフォリオに追加される建設部門ローンの数を計算します。結果は次のとおりです。
ステップ 4: 各建設ローンの費用の決定
コストは、次の式に従って計算されます。
ステップ 5: 支払い意思とコストの比較
価格 P がコスト C x -1 以上の場合 (コストが負であるため)、しきい値を移動します。この例では、63,084 USD のコストは貸し手の支払意思額 75,000 USDよりも低いため、貸し手はしきい値を移動し、26 の追加ローンを作成する必要があります。
貸し手はこの一歩で止まらないでしょう。しきい値をさらに 0.01 増やすかどうかを尋ね続け、しきい値を上げないことを選択するポイントに達するまで、前のステップを繰り返します。
支払意思額が建設部門の追加ローンの費用よりも大きい場合、貸し手は常に必要な資本にアクセスできると仮定します。必要に応じて、貸し手の資本予算 W も含めることができます。この変更により最終ステップが変更され、P >= -C であるかと、追加のローンの元本の合計をカバーするのに十分な量の資本が W に残っているかを、貸し手がチェックします。
その他のモデル指標
0.5 のしきい値の単純なランダムフォレストと最適なしきい値モデルのランダムフォレストは、正確性、精度、再現率などの従来のパフォーマンスメトリクスに従ってどのように比較されるでしょうか?
次の表は、3 つのモデルすべての正確性、精度、再現率を示しています。
| Accuracy | Precision_0 | Precision_1 | Recall_0 | Recall_1 | |
| 単純なモデル | 0.822721 | 0.822721 | NaN | 1.000000 | 0.000000 |
| ランダムフォレストモデル (0.5 しきい値) | 0.935302 | 0.944246 | 0.883336 | 0.979177 | 0.731683 |
| ランダムフォレストモデル (最適なしきい値) | 0.934975 | 0.960350 | 0.817026 | 0.960626 | 0.815937 |
このテーブルによると、どのモデルが最適でしょうか? 混同マトリクスの各セルに関連する貸し手への利益とコスト、つまり、真陽性と真陰性に関連する利益、および偽陽性と偽陰性に関連するコストを知らない限り、その質問に真に答えることはできません。
前のテーブルから、両方のランダムフォレストモデルが単純なモデルを厳密に支配していることが明らかです (偽陽性のコストが偽陰性のコストよりも大幅に大きくないと仮定)。さらに、2 つのランダムフォレストモデルの間に明確な勝者はありません。答えは、貸し手の誤分類の相対的なコストに依存します。冒頭で説明した問題のビジネスコンテキストから、偽陽性よりも偽陰性に関連するコストが大幅に高いことがわかります。その情報を考えると、貸し手が偽陰性を最小限に抑えることがより価値があり、そのため、Recall_1 または Precision_0 が最も顕著なメトリクスです。
この議論は、いわゆる最適モデルを決定するには、この ML モデルが扱うビジネスユースケースの知識と、潜在的な各分類結果に関連する利点とコストが必要であることを示しています。そうして初めて、ビジネスにとって成功が意味するものを最もよく捉えるメトリクスを決定できます。さらに、精度と再現率には、混同マトリクスの 4 つのセルのうち 2 つのセルに関する情報のみが含まれますが、貸し手は 4 つのセルすべてに関連する純利益を重視します。これらの典型的な指標を使用すると、貸し手が気にする結果の半分が無視され、すべての結果に関連する特定のコストと利点も無視されます。このため、これらのメトリクスは不足しており、混同マトリクスのすべてのセルに関連する特定のコストと利点を組み込んだ単一の問題固有のメトリクスを計算して、最適なしきい値を決定する必要があります。この記事では、このメトリクスはポートフォリオ値です。
この最適化アプローチをより一般的に使用して、問題と手元のデータにしきい値が最適かどうかをテストできます。
クリーンアップ
コードを実行するために新しい Amazon SageMaker ノートブックインスタンスを作成した場合は、コストを最小限に抑えるために、必ずインスタンスを停止または削除してください。
まとめ
この記事では、バイナリ分類問題で最適なしきい値を見つける方法を示しました。具体的には、Amazon SageMaker の自動モデルチューニングを使用して、借り手のサブセットを選択して信用を供与する際に、貸し手のポートフォリオ値を最大化する分類しきい値を決定する方法について説明しました。より一般的には、ここで説明した最適なしきい値を選択する方法は、複数のしきい値を選択する必要がある状況に適用できます。必要な主な変更は、複数のしきい値を問題固有のしきい値ベースのメトリクスに組み込むことです。その後、Amazon SageMaker 自動モデルチューニングを使用して、単一のしきい値ではなく、メトリクスを最大化するしきい値のベクトルを見つけることができます。
ここで説明したしきい値決定アプローチには、いくつかの重要な利点があります。まず、しきい値を決定する際に使用する論理と理論的根拠を明示的にします。第二に、モデルの予測とそれに関連する利点とコストを実行するための具体的なアクションに基づいて、コストマトリクスを明確に記述することがビジネスに求められます。ロジックとコスト構造を明確にすることで、ビジネスにおける難しい議論を促し、オープンな議論と合意のためにさまざまな暗黙の決定と評価をテーブルに押し込むことができます。さらに、説明可能な ML はこの記事の範囲を超えていますが、このアプローチによって推奨されるしきい値決定のロジックとコスト構造の明示的なステートメントは、その研究ラインの目標によく適合しています。
最後に、このアプローチは、不均衡なデータの問題に対処するために潜在的に使用することもできます。不均衡なデータの問題は、多くの場合、1 つのターゲットクラスが別のターゲットクラスよりもはるかに大きいデータ表現を持っていることではなく、誤分類コスト (つまり、偽陽性対偽陰性のコスト) がお互い劇的に異なることにあります。サンプリングを使用してトレーニングデータのバランスをとる代わりに、問題固有のメトリクスで誤分類コストを明確に定義し、そのメトリクスを使用して最適なしきい値を見つけることができます。このアプローチにより、データの分布に対して、より多くのビジネスに問題のコスト構造を明確に指定する変更を行うトリックを使用するという問題が、それほど技術的な問題ではなくなります。これにより、不均衡なデータの真の問題、つまり不均衡な誤分類コストの問題に直接対処できます。
分類のしきい値を設定する必要があるビジネスユースケースの場合、Amazon SageMaker 自動モデルチューニングとこの記事で説明した方法の使用を検討してみてください。開始するには、Amazon SageMaker コンソールと、この記事で結果を生成した GitHub repo のコードを開きます。この方法を適用できるビジネスユースケースについてのご意見やご質問がある場合は、コメント欄に残してください。非対称分類コストのあるトレーニングモデルの詳細については、「Amazon SageMaker を使用して、エラーの経済的コストが不均等なモデルをトレーニングする」を参照してください。
ソースと参考文献:
Friedman, Milton, and L. J.Savage.“The Utility Analysis of Choices Involving Risk. (リスクを伴う選択肢の効用分析)” Journal of Political Economy 56, no. 4 (1948): 279–304.
データソース: Li, Min, Amy Mickel, and Stanley Taylor. “‘Should This Loan Be Approved or Denied?’: A Large Dataset with Class Assignment Guidelines. (このローンは承認するべきか、拒否するべきか? クラス割り当てガイドライン付きの大規模なデータセット)” Journal of Statistics Education 26, no. 1 (January 2, 2018): 55–66. https://doi.org/10.1080/10691898.2018.1434342.
Metz, Charles E.“Basic Principles of ROC Analysis. (ROC 分析の基本原則)” Seminars in Nuclear Medicine 8, no. 4 (October 1978): 283–98. https://doi.org/10.1016/S0001-2998(78)80014-2
Wu, Yirong, Craig K. Abbey, Xianqiao Chen, Jie Liu, David C. Page, Oguzhan Alagoz, Peggy Peissig, Adedayo A. Onitilo, and Elizabeth S. Burnside.“Developing a Utility Decision Framework to Evaluate Predictive Models in Breast Cancer Risk Estimation. (乳がんリスク推定における予測モデルを評価するためのユーティリティ決定フレームワークの開発)” Journal of Medical Imaging 2, no. 4 (October 2015). https://doi.org/10.1117/1.JMI.2.4.041005.
Zadrozny, Bianca, and Charles Elkan.“Learning and Making Decisions When Costs and Probabilities Are Both Unknown, (コストと確率の両方が不明な場合の学習と意思決定)” 204–13.ACM Press, 2001. https://doi.org/10.1145/502512.502540.
Veronika Megler and Scott Gregoire.“Training models with unequal economic error costs using Amazon SageMaker (Amazon SageMaker を使用して、エラーの経済的コストが不均等なモデルをトレーニングする),“ AWS Machine Learning Blog, 18 Sept 2018.
著者について
 Scott Gregoireは、AWS プロフェッショナルサービスのデータサイエンティストです。彼は、テキサス大学オースティン校で経済学博士号を取得し、国際金融から小売までの分野のクライアントにアドバイスをしてきました。現在、彼は顧客と協力して、AWS で革新的な機械学習ソリューションを開発しています。
Scott Gregoireは、AWS プロフェッショナルサービスのデータサイエンティストです。彼は、テキサス大学オースティン校で経済学博士号を取得し、国際金融から小売までの分野のクライアントにアドバイスをしてきました。現在、彼は顧客と協力して、AWS で革新的な機械学習ソリューションを開発しています。
 Veronika Megler (PhD) は、AWS プロフェッショナルサービスのシニアコンサルタントです。彼女は、革新的なビッグデータ、AI および ML のテクノロジーを適用して、顧客が新しい問題を解決し、古い問題をより効率的かつ効果的に解決することを助けています。
Veronika Megler (PhD) は、AWS プロフェッショナルサービスのシニアコンサルタントです。彼女は、革新的なビッグデータ、AI および ML のテクノロジーを適用して、顧客が新しい問題を解決し、古い問題をより効率的かつ効果的に解決することを助けています。