Amazon Web Services ブログ
複数の CPU/GPU にかけて並列化して、エッジでの深層学習の推論を高速化する
AWS のお客様は、レイテンシーを最小限に抑えるために、エッジで機械学習 (ML) 推論を実行することを選択することがよくあります。これらの状況の多くでは、ML 推論は多数の入力で個別に実行する必要があります。 たとえば、ビデオの各フレームでオブジェクトの検出モデルを実行する場合です。これらの場合、エッジデバイスで利用可能なすべての CPU/GPU で ML 推論を並列化すると、全体的な推論時間を短縮できる可能性があります。
最近、私のチームはこの最適化の必要性を認識しながら、お客様が産業用異常検出システムを構築するのを支援しました。このユースケースでは、一連のカメラが通過するマシンの画像を取得してアップロードしました (マシンごとに約 3,000 枚の画像)。お客様は、サイトのエッジデバイスにデプロイした深層学習ベースのオブジェクト検出モデルに各画像を入力する必要がありました。各サイトのエッジハードウェアは、2 つの GPU と複数の CPU を搭載していました。最初に、AWS IoT Greengrass コアにデプロイされた長期実行 Lambda 関数 (これについては記事の後半で詳しく説明します) を実装しました。この設定では、各イメージをエッジデバイスで順次処理します。
ただし、この設定では、エッジデバイスの単一の CPU および単一の GPU コアで深層学習推論が実行されます。推論時間を短縮するために、利用可能なハードウェアの全容量を活用する方法を検討しました。調査をいくらか行った後、(さまざまな深層学習フレームワークに対して) 複数の CPU/GPU (TensorFlow、MXNet、PyTorchなど) にトレーニングを分散させる多くの方法に関するドキュメントを見つけました。ただし、特定のホストで並列化を行う方法に関する資料は見つかりませんでした。
この投稿では、推論を並列化する方法をいくつか示し、コードスニペットの例とパフォーマンスベンチマークの結果を提供します。
この投稿では、データの並列処理のみに焦点を当てます。これは、入力データのリストを均等な部分に分割し、各 CPU/GPU コアがそのような部分 1 つを処理することを意味します。このアプローチはモデルの並列処理とは異なり、ML モデルを異なる部分に分割し、各部分を異なるプロセッサにロードする必要があります。データの並列処理は、その単純さにより、はるかに一般的で実用的です。
単一のマシンで ML 推論を並列化するのにどの点が難しいのでしょうか?
マルチスレッドコードの記述に精通しているソフトウェアエンジニアであれば、上記の内容を読んで疑問に思うかもしれません。単一のマシンで ML 推論を並列化するのに、何が課題なんだろうかと。 これをよりよく理解するために、デバイスに少なくとも 1 つの GPU があると仮定して、単一の ML 推論をエンドツーエンドで実行するプロセスを手短に確認しましょう。

複数の CPU/GPU を搭載したマシンで推論パフォーマンスを最適化する場合の考慮事項を以下に示します。
- 初期化の負荷が高い: 図に示したプロセスのステップ 1 (ニューラルネットの読み込み) では、多くの場合、かなりの時間がかかります。読み込み時間は数百ミリ秒または数秒であるのが一般的です。タイミングを考えると、プロセス/スレッドごとに 1 回初期化を実行し、推論を実行するためにプロセス/スレッドを再利用することをお勧めします。
- CPU または GPU がボトルネックになる可能性がある: ステップ 2 (データ変換) とステップ 4 (ニューラルネットでのフォワードパス) は、最も計算量の多い 2 つの手順です。コードの複雑さと利用可能なハードウェアによっては、GPU を十分に活用せずに 1 つのユースケースで CPU コアを 100% 使用し、別のユースケースでその逆を行う場合があります。
- GPU をプロセス/スレッドに明示的に割り当てる: GPU の推論に深層学習フレームワークを使用する場合、コードでモデルをロードする GPU ID を指定する必要があります。たとえば、マシンに 2 つの GPU があり、推論を並列に実行する 2 つのプロセスがある場合、コードは 1 つのプロセス GPU-0 と他の GPU-1 を明示的に割り当てる必要があります。
- 出力の順序付け: ダウンストリーム処理で消費される前に出力を順序付けする必要がありますか? 異なるスレッドによる同時処理のために異なる入力を並列化すると、先入れ先出しの保証は適用されなくなります。たとえば、リアルタイムオブジェクト追跡システムでは、追跡アルゴリズムは、次のフレームの予測を処理する前に、前のビデオフレームの予測を処理する必要があります。このような場合、並列化された推論が行われた後に、追加のインデックス付けと並べ替えを実行する必要があります。他のユースケースでは、順不同の結果は問題にならない可能性があります。
並列化アプローチの概要
この記事では、単一のマシンで推論を並列化するための 3 つのオプションを紹介します。次にそれらの長所と短所を簡単に説明します。
| オプション | 長所 | 短所 | 推奨? |
| 1A: AWS IoT Greengrass で複数の長期間有効な AWS Lambda 関数を使用する |
|
|
はい |
| 1B: AWS IoT Greengrass でオンデマンド Lambda 関数を使用する |
|
|
いいえ |
| 2: Python マルチプロセッシングを使用する |
|
|
はい |
並列化オプション 1: AWS IoT Greengrass で複数の Lambda コンテナを使用する
AWS IoT Greengrass は、ML 推論をエッジで実行するための優れたオプションです。これにより、デバイスはエッジデバイスで Lambda 関数をローカルで実行し、クラウド接続が中断しているときでもイベントに応答できます。デバイスがインターネットに再接続すると、AWS IoT Greengrass ソフトウェアは、クラウドにアップロードするデータをシームレスに同期して、さらなる分析と耐久性のあるストレージを実現できます。その結果、ML 推論をエッジでローカルに実行する利点 (つまり、低レイテンシー、ネットワーク帯域幅の節約、潜在的に低コスト) と、持続する必要のあるデータのクラウドのスケーラブルな分析およびストレージ機能の両方の利点を享受できます。
AWS IoT Greengrass には、エッジで ML 推論をデプロイしながら機械学習リソースを管理するのに役立つ機能も含まれています。この機能を使用して、ML モデルパラメータファイルを Amazon S3 のどこに保存するかを指定します。AWS IoT Greengrass は、デプロイ中にエッジデバイス上の指定された場所にファイルをダウンロードして抽出します。この機能により、ML モデルの更新が簡単になります。新しい ML モデルを作成したら、ML リソースを新しいアーティファクトの S3 ロケーションにポイントし、Greengrass グループの新しいデプロイをトリガーします。S3 のソース ML アーティファクトに対する変更は、エッジデバイスに自動的にリデプロイされます。
AWS IoT Greengrass で推論コードを実行する場合、複数の推論 Lambda 関数インスタンスを並行して実行することにより、推論を並列化することもできます。AWS IoT Greengrass では、長期間有効な Lambda 関数を使用するか、オンデマンド Lambda を使用する 2 つの方法でこれを実行できます。
オプション 1A: 複数の長期間有効な Greengrass Lambda 関数を使用する (推奨)
長期間有効な (または固定) Greengrass Lambda 関数は、デーモンプロセスに似ています。クラウド内の AWS Lambda 関数とは異なり、長期間有効な Greengrass Lambda 関数は、関数ごとに 1 つのコンテナを作成します。同じコンテナが Lambda 関数へのリクエストを 1 つずつキューに入れて処理します。
ML に長期間有効な Greengrass Lambda 関数を使用すると、初期化遅延の影響が最小限に抑えられます。長期間有効な Greengrass Lambda 関数内で、初期化中に ML モデルを一度ロードします。後続のリクエストは、ML モデルを再度ロードすることなく同じコンテナを再利用します。
このパラダイムでは、同じソースコードを実行する複数の長期間有効な Greengrass Lambda 関数を定義することにより、推論を並列化できます。1 つの AWS IoT Greengrass コアで 2 つの長期間有効な Greengrass Lambda 関数を設定すると、ML モデルが初期化され、推論を同時に実行する準備ができた 2 つの長期実行コンテナが作成されます。このアプローチの長所と短所:
長期間有効な Greengrass Lambda 関数を使用することの長所
- 推論コードが複雑にならない。シングルスレッドの推論コードを変更する必要がない。
- 異なる環境変数を指定することで、それぞれの Greengrass Lambda 関数に異なる GPU を割り当てられます。
- AWS IoT Greengrass を使用して、必要な数の同時推論コンテナを維持できます。未処理の例外が原因で 1 つのコンテナがクラッシュした場合でも、AWS IoT Greengrass コアソフトウェアが新しい代替コンテナを起動します。
- また、Greengrass コンストラクトに依存して、CPU 集約型の入力変換計算と GPU 集約型のフォワードパス部分を個別の Lambda 関数に分離し、リソースの使用をさらに最適化できます。たとえば、データ変換コードが推論のボトルネックであり、マシンに 4 つの CPU コアと 2 つの GPU コアがあると仮定します。その場合、データ変換用の 4 つの長時間実行 Lambda 関数 (各 CPU コアに 1 つ) を使用し、結果を 2 つの長時間実行 Lambda 関数 (各 GPU コアに 1 つ) に渡すことができます。
長期間有効な Greengrass Lambda 関数を使用することの短所
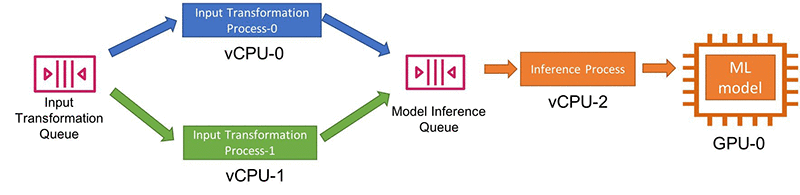
- 長期間有効な各 Lambda 関数は、入力を 1 つずつ処理する。そのため、負荷分散ロジックを実装して、各 Lambda 関数がサブスクライブする別個のトピックに入力を分割する必要があります。たとえば、2 つの同時推論 Lambda 関数がある場合、入力を半分に分割し、AWS IoT Greengrass の個別の IoT トピックに各半分を割り当てる前処理 Lambda 関数を作成できます。次の図は、このワークフローを示しています。

- 2019 年 5 月の時点で、AWS IoT Greengrass は、同時に実行できる Lambda コンテナの数を 20 に制限している。AWS IoT Greengrass コアデバイス上のすべての Lambda 関数は、オンデマンドコンテナを含むこの厳しい制限を共有しています。同じデバイスで処理タスクを実行する他の Lambda 関数がある場合、この制限により、推論タスクごとに複数の Lambda インスタンスを実行できない可能性があります。
- このアプローチでは、AWS IoT Greengrass デプロイのハードコーディング設定 (長時間実行される推論 Lambda 関数の数、それらが割り当てられる GPU ID、対応する入力サブスクリプションなど) が必要。デプロイする前に、使用する予定の各デバイスのハードウェア仕様を知っておく必要があります。コア数が異なる異種のデバイス群を運用する場合は、各デバイスモデルの CPU/GPU リソースにマッピングする特定の AWS IoT Greengrass 設定を行う必要があります。
オプション 1B: オンデマンドの Greengrass Lambda 関数を使用する (非推奨)
オンデマンド Greengrass Lambda 関数は、クラウドの AWS Lambda 関数と同様に機能します。複数のリクエストが着信すると、AWS IoT Greengrass は複数のコンテナ (またはサンドボックス) を動的にスピンアップできます。どのコンテナもあらゆる呼び出しを処理でき、並行して実行できます。
実行するタスクが残っていない場合、コンテナ (またはサンドボックス) が保持され、将来の呼び出しでそれらを再利用できます。または、他の Lambda 関数を実行するスペースを空けるために、それらを終了することができます。スピンアップするコンテナの数や、保持するコンテナの数を制御することはできません。AWS IoT Greengrass の内部的なヒューリスティックは、キューサイズに基づいてコンテナの数を決定します。つまり、AWS IoT Greengrass は、オンデマンドの Lambda 設定を使用して、トラフィックに基づいてコードを実行するコンテナの数を動的にスケーリングします。
この設定は、初期化のオーバーヘッドが低いデータ処理ユースケースに適合します。ただし、深層学習の推論コードにオンデマンド設定を使用する場合、いくつかの短所があります。
- 「コールドスタート」レイテンシー: 前述したように、深層学習モデルはメモリにロードするのに時間がかかります。AWS IoT Greengrass は動的にスピンアップしてコンテナを破棄しますが、着信リクエストには新しいコンテナの作成が必要であり、初期化のレイテンシーが発生する場合があります。このような遅延は、並列化によるパフォーマンスの向上を打ち消してしまう可能性があります。
- 同時コンテナ数の制御不足: 同時推論 Lambda 関数の実行数を制御すると、リソースの使用を最適化できます。たとえば、2 つの GPU があり、ML モデルの各フォワードパスプロセスが GPU の 100% を使用するとします。そのシナリオでは、2 つの並行する Greengrass Lambda コンテナがリソースの理想的な使用を表します。3 つ以上のコンテナを作成すると、CPU/GPU リソースのコンテキスト切り替えとキューが増えます。オンデマンドの Lambda 設定では、同時実行の数を制御できません。
- 同時 Lambda コンテナ間の調整の難しさ: 通常、オンデマンドモデルは、並行する各 Lambda コンテナインスタンスが独立しており、同じ方法で設定されていることを前提としています。ただし、複数の GPU を使用する場合、各 Lambda コンテナに異なる GPU を使用するよう明示的に割り当てる必要があります。これらの GPU の割り当てには、AWS IoT Greengrass がコンテナを動的にスピンアップして破棄するため、コンテナ間の調整が必要です。
並列化オプション 2: Python マルチプロセッシングの使用 (推奨)
前述のオプション 1A は、次に該当するユーザーには適さない可能性があります。
- AWS IoT Greengrass を使用したくない
- 多くの Lambda 関数を実行する必要があり、それぞれのインスタンスが複数あると、Greengrass の同時コンテナ制限を超えてしまいます。
- 利用可能なハードウェアリソースに基づいて、実行時の並列化レベルを柔軟に決定したい
これらのユーザーの代替手段は、複数のコアを活用するために推論コードを変更することです。このオプションについては、ML とデータサイエンスの分野での Python の比類のない人気を考えて、次のセクションでは Python に焦点を当てて説明します。
Python マルチプロセッシング
Java や C ++などのプログラミング言語では、複数のスレッドを使用して複数の CPU コアを利用できます。残念ながら、Python のグローバルインタプリタロック (GIL) により、この方法で推論を並列化できません。ただし、Python のマルチプロセッシングモジュールを使用して、複数の CPU および GPU で ML 推論を同時に実行することで並列処理を実現できます。Python 2 と Python 3 の両方でサポートされている Python マルチプロセッシングモジュールを使用すると、複数のプロセッサコアで同時に実行される複数のプロセスを生成できます。
プロセスプールを使用して推論を並列化する
Python マルチプロセッシングモジュールは、プロセスプールを提供します。プロセスプールを使用すると、複数の長期間有効なプロセスを生成し、初期化中に各プロセスで ML モデルのコピーをロードできます。その後、pool.Map () 関数を使用して、プールが処理する入力のリストを送信できます。次のコードスニペットの例をご覧ください。
parallelize-ml-inference GitHub リポジトリで残りの推論スクリプトを読むことができます。 このマルチプロセッシングコードは、単一の Greengrass Lambda 関数内でも実行できます。
Python マルチプロセッシングプロセスプールを使用したベンチマークの例
この並列化によりパフォーマンスはどの程度向上するでしょうか? 上記のマルチプロセッシングプールコードを使用して、p3.8xlarge インスタンス (4 つの NVIDIA Tesla V100 GPU を搭載) でオブジェクト検出 MXNet モデルを実行し、プロセスプールサイズの違いが 3000 の画像の処理に必要な合計時間にどのように影響するかを確認しました。使用したオブジェクト検出モデル (Amazon SageMaker が組み込まれた SSD アルゴリズムでトレーニングしたモデル) は、次の結果を生成しました。

この実験で次のいくつかの観察結果が得られました。
- この入力変換コード、推論コード、データセット、およびハードウェア仕様の組み合わせでは、複数のプロセスの CPU/GPUS でタスクを並列化することで、単一のプロセスを使用した 153 秒から約 40 秒に合計推論時間が改善されました (時間にしてほぼ 1/4)。
- この実験では、ボトルネックは CPU と入力変換にあるように見えます。GPU は、メモリと処理の両方の観点から十分に活用されていません。スクリプトを 2 つのワーカープロセスで実行した場合の GPU 使用率の次のスナップショットをご覧ください。(p3.8xlarge インスタンスには 4 つの GPU があります。したがって、2 つのプロセスのみでスクリプトを実行したときに、そのうち 2 つがアイドル状態になっていることがわかります)。
上記の使用率メトリクスが示すように、1 つのロードされた ML モデルは、各 GPU で使用可能な 16 GB から約 1 GB のメモリを使用しました。したがって、この場合、GPU ごとに複数のモデルを実際に読み込むことができ、それぞれが個別の入力セットで独立して推論を実行します。上記のスクリプトは、各プロセスに GPU ID のループリストを割り当てることにより、GPU の数よりも多くのプロセスをサポートします。
したがって、8 つのプロセスでテストしたとき、スクリプトはリスト [0、1、2、3、0、1、2、3] から 1 つの GPU ID を割り当てて、各モデルに ML モデルをロードします。同じ GPU にロードされた 2 つの ML モデルは、同じモデルの独立したコピーであることに注意してください。各モデルは、個々の入力で独立して推論を実行できます。GPU メモリが対応できる数以上のモデルコピーをロードしようとすると、メモリ不足エラーが発生します。
CPU 側では、p3.8xlarge インスタンスに 32 個の vCPU が含まれており、32 個未満のプロセスを実行したため、各プロセスは専用の vCPU で実行できました。htop を実行すると、実験中の CPU 使用率を確認できます。これがプロセッサーでどのように機能したかについては、次の図をご覧ください。

htop および nvidia-smi コマンドからの出力を使用して、この特定の実験のボトルネックが CPU の入力変換ステップであることが確認できました(使用中の CPU は 100% 使用されていましたが、GPU は使用されていませんでした)。
単一の入力を処理する時間を測定することにより、並列化の影響に関する追加の洞察を得ることができます。次のグラフは、ワーカープロセスが記録した 2 つの処理ステップの p50 (中央値) のタイミングを比較しています。グラフが示すように、複数の ML モデルを各 GPU にパックしたため、GPU の推論時間はわずかしか増加しません。ただし、より多くのワーカープロセス (vCPU) が使用されるにつれて、イメージごとの入力変換時間は増加し続け、コードの最適化がさらに必要となる競合を発生させることを示唆しています。
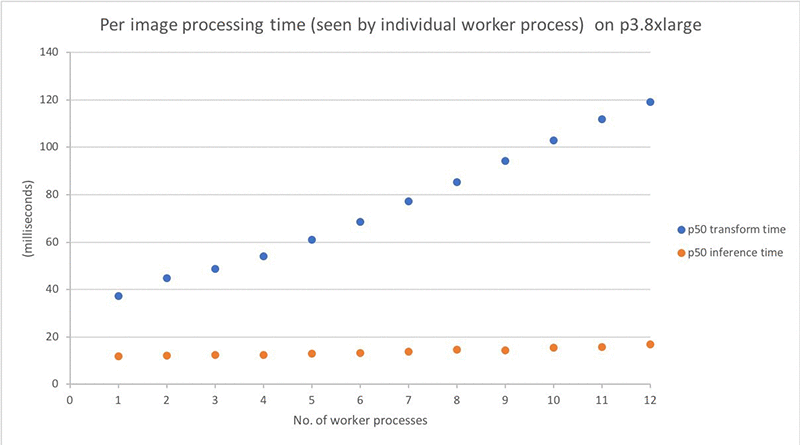
処理時間のグラフを見ると、プロセスごとの各画像の処理時間は増加するのに、合計処理時間は減少する理由を不思議に思われるかもしれません。覚えておいてください。上記のイメージごとのタイミンググラフは、各ワーカープロセスが並行して実行されるときに測定されています。合計処理時間はおおよそ次のとおりです。
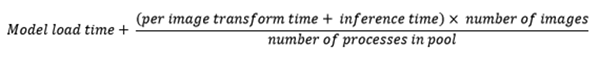
一般的な学習事項と考慮事項
説明した実験に加えて、異なるフレームワーク、モデル、ハードウェアで同様のテストを試行しました。この実験から得られたいくつかのポイントは次のとおりです。
すべての深層学習フレームワークがマルチプロセッシング推論を均等にサポートしているわけではない。プロセスプールスクリプトは MXNet モデルでスムーズに実行されます。対照的に、2 番目のモデルを 2 番目のプロセスにロードしようとすると、Caffe2 フレームワークがクラッシュします。他のモデルでも、Caffe2 の GitHub に関する同様の問題を報告しています。 主要なフレームワークからのマルチスレッド/マルチプロセッシングの推論サポートに関するドキュメントはほとんどまたはまったく見つかりませんでした。したがって、選択したフレームワークでこれを自分でテストする必要があります。
異なるハードウェアと推論コードには、異なるマルチプロセッシング戦略を要する。 この実験では、モデルは GPU の容量に比べて比較的小さいです。複数の ML モデルを読み込んで、単一の GPU で同時に推論を実行できます。
対照的に、力強さで劣るデバイスとより重いモデルでは、単一の推論タスクが GPU を 100% 使用することでで、GPU ごとに 1 つのモデルに制限される可能性があります。モデル変換と比較して入力変換が遅い場合、および GPU よりも CPU が多い場合は、Python マルチプロセッシングキューを使用して、それらを分離し、各ステップで異なる数のプロセスを使用することもできます。
提供されたベンチマークコードでは、コードを簡単にするためにプロセスプールと pool.map () を使用しました。対照的に、プロセス間にキューがあるパブリッシャー/コンシューマーモデルでは、柔軟性が大幅に向上します (コードの複雑さが増した場合)。
推論パフォーマンスを改善する方法は他にもある。改善された推論パフォーマンスを提供するアプローチが他にも数多くあり、それらを利用することもできます。たとえば、Amazon SageMaker Neo を使用して、基盤となるハードウェアに最適化された効率的な形式にトレーニング済みモデルを変換し、メモリフットプリントを抑えながらパフォーマンスを向上できます。
他にもバッチ処理のアプローチがあります。引用されたテストでは、一度に 1 つの画像に対してオブジェクト検出推論を実行します。同時処理のために複数の画像をバッチ処理すると、基礎となるライブラリおよびハードウェア最適化によって実現する行列計算効率により、全体の推論を高速化できます。ただし、リアルタイムで結果を取得しようとする場合、バッチ処理を常に選択できるとは限りません。
NVIDIA Multi-Process Service (MPS) を有効にしてみてください。NVIDIA GPU デバイスを使用する場合、各 GPU で Multi-Process Service (MPS) を有効にできます。MPS は、単一の GPU で複数の CPU プロセスから同時に送信された複数の ML モデルの実行をサポートする代替 GPU 設定を提供します。MPS を有効または無効にして、AWS IoT Greengrass または純粋な Python アプローチのいずれかを使用できます。
MPS を有効にせずに、p3.8xlarge インスタンスで前述したベンチマーク結果の例を完成させました。p3.8xlarge の GPU は、複数の独立した ML モデルをそのまま実行することをサポートすることがわかりました。MPS を有効にして同じセットアップをテストした結果、パフォーマンスはほとんど無視できるほどの向上しかありませんでした (つまり、画像あたり 0.2 ミリ秒)。けれども、特定のハードウェアおよびユースケースで MPS を有効にすることをお勧めします。パフォーマンスが大幅に向上する場合があるかもしれません。
結論
この投稿では、複数の CPU/GPU のエッジで単一デバイスの推論を並列化するための次の 2 つのアプローチについて説明しました。
- AWS IoT Greengrass コア内で複数の Lambda コンテナ (長期またはオンデマンド) を実行するアプローチ
- Python マルチプロセッシングを使用するアプローチ
前者はコードがシンプルになり、後者は Greengrass 内またはなしで実行でき、最大限の柔軟性を提供します。また、推論に複数の CPU/GPU を使用して得られるパフォーマンスの向上を強調するベンチマークテストの例を示しました。推論ハードウェアが十分に活用されていない場合は、これらのオプションを試してみてください!
AWS IoT Greengrass の使用を開始するには、ここをクリックしてください。SageMaker Neo の使用を開始するには、ここをクリックしてください。 この投稿で使用されているコードは、parallelize-ml-inference GitHub リポジトリで見つかります。
著者について
 Angela Wang は、ニューヨークに拠点を置く AWS ソリューションアーキテクチャチームの R&D エンジニアです。彼女は、AWS プラットフォームを使用したラピッドプロトタイピングにより、AWS のお客様が革新的なアイデアを構築するのをサポートしています。仕事以外では、読書、登山、山中のスキー、旅行が大好きです。
Angela Wang は、ニューヨークに拠点を置く AWS ソリューションアーキテクチャチームの R&D エンジニアです。彼女は、AWS プラットフォームを使用したラピッドプロトタイピングにより、AWS のお客様が革新的なアイデアを構築するのをサポートしています。仕事以外では、読書、登山、山中のスキー、旅行が大好きです。