Amazon Web Services ブログ
Apache Spark および Hadoop を Amazon EMR に移行してコストを削減
Apache Spark および Hadoop は、分析用のデータ処理向けのフレームワークとして広く普及しています。レガシーアプローチと比較すれば、コストもほんのわずかな額で済みますが、それでもそのスケーリングとなると、依然として高くつくケースがあります。本記事では、TCO を削減し、かつ同時にスタッフの生産性を引き上げる方法について考察します。その実現を可能にするのは、オンプレミスのワークロードの Amazon EMR への移行、良いアーキテクチャの選択、リソースの消費量を削減するよう設計された機能の活用です。今回のアドバイスは、お客様との多数の事例から得た知見に基づいており、主な論点の多くは IDC の Carl Olofson および Harsh Singh が実施したビジネス価値の研究結果によっても検証されています。当該研究はアマゾン ウェブ サービス (AWS) が資金提供しており、IDC ホワイトペーパー「The Economic Benefits of Migrating Apache Spark and Hadoop to Amazon EMR」(2018 年 11 月) としてご覧いただけます。
それではまず、ヘッドラインとして統計データをいくつかご紹介して、Amazon EMR への移行が生むコスト面のプラスのインパクトをご説明します。IDC が調査した Amazon EMR のお客様 9 社では TCO が平均 57% 削減されました。同時に、5 年間の投資利益率の 342% 増しで、8 か月で投資を回収しました。この 9 社の Spark および Hadoop のデプロイ規模は大きく異なり、その効果も当然のことながら一様ではありません。それでも、ビッグデータ処理の長期戦略を考えている IT 部門や財務部門のマネージャーであれば関心を持たざるを得ない数字であるはずです。
では、Amazon EMR が Spark および Hadoop のオンプレミスのデプロイよりもコストを削減できるのは、どの程度確かなのか。 IDC ホワイトペーパーはその答えを 3 つ用意していますので、今からご説明します。
インフラストラクチャの物理的コストの削減
オンプレミスのデプロイではハードウェアをフル活用するわけではありません。いくつか理由があります。理由の 1 つは、将来のニーズを見越したサーバーの選定、発注、インストールというプロビジョニングのサイクルにあります。どれだけリソースを需要予測していても、このサイクルではオーバープロビジョニングになりがちです。つまり、すぐに活用されない資産に資本を投資しているということです。また、このサイクルはリソースのキャパシティーの限界に達して終わることもあります。その結果、求められるビッグデータ処理のタイムリーな遂行能力が制限されることになります。
独自リソースがサーバー内に定率でプロビジョニングされる Spark および Hadoop のアーキテクチャが、この問題にさらに拍車をかけます。サーバーはそれぞれ所定数のプロセッサーとメモリ (コンピューティング) を搭載し、一定のストレージ容量を持っています。なかにはストレージ集約型のワークロードもあるでしょう。そうなると、巨大なデータ量が将来のユースケースの備えてサーバー内に保持されることになります。その一方で、せっかく購入したコンピューティングリソースは、データが実際に処理され分析に回されるその日までアイドリング状態で遊んでいることになります。また、あるワークロードが複雑なオペレーション用に大量のメモリや多数のプロセッサーを必要としても、それ以外では比較的小容量のデータに対して実行されることもあるでしょう。いずれのケースでも、ローカルストレージはフルには活用されないかもしれません。
オンプレミスで HDFS に耐久性を持たせるには、データの複製が複数必要になり、それがハードウェアの要件を押し上げます。Amazon S3 にはすでに組み込まれていますが、コンピューティングとストレージを切り離すことで、耐久性目的のレプリケーションがなくなり、ハードウェアのフットプリントを削減します。Spark と Hadoop は従来のデータウェアハウスアプライアンスよりもコスト効率がはるかに上回るコモディティハードウェアを使用していますが、オンプレミス手法は経時的な需要変動に対応するには本質的に無駄が多く、柔軟性とアジリティが欠如しています。
AWS ソリューションアーキテクト Bruno Faria は先月の re:Invent 2018 の「Lower Costs on Amazon EMR: Auto Scaling, Spot Pricing, and Expert Strategies」で高度な手法をご紹介しました。要点を復習しましょう。
Amazon EMR には、オンプレミス環境が持つ弱点を克服する、持って生まれた強みがあります。料金は、お客様は実際に使用した分だけを負担する従量制です。オンデマンドのリソースが、オーバープロビジョニングおよびアンダープロビジョニングの問題を軽減します。さらに進んだお客様になると、コンピューティングリソースとストレージリソースをデカップリングできます。Amazon S3 で必要なデータ量を保存し、データ量が増えた分だけのコストをその都度加算していくのです。
さらに、作業中の仕事に適したサイズのコンピューティングインスタンスが選択して実装できます。オンデマンド課金システムでもあり、「秒単位」で細かく計算されます。これによりコストが削減され、俊敏性も向上します。Amazon EMR を使用せず、オンプレミスのワークロードを AWS に「リフトアンドシフト」して Amazon EC2 で実行するお客様もいらっしゃいます。ただし、これはデカップリング効果を活用できないため、移行途中段階にのみ推奨されます。
Spark と Hadoop を AWS で一度起動してしまえば、コンピューティングコストをさらに削減できます。リザーブドインスタンスから選択でき、最低料金のベースを大幅にさげることができます。いつでも利用可能で秒単位で課金されるオンデマンドインスタンスや、スポットインスタンスで補完できます。スポットインスタンスは、機密性の低いワークロードに対して割り込みリソースを、大幅な割引価格で提供します。インスタンスフリートでは、以下の機能も指定できます。
- スポットインスタンスの実行を続ける定義済みの継続時間 (スポットブロック)。
- スポット料金の最大希望料金。
- スポットインスタンスをプロビジョニングするためのタイムアウト時間。
これらの購入オプションを組み合わせてお客様がベストな結果を得るためには、以下の点をご確認ください。
- 予測される SLA およびニーズを伴う需要のベースライン。
- 定期的または突発的ピークにより、割引料金で SLA を超えることがあること。
- ジョブの性質。短期的か長期的か。
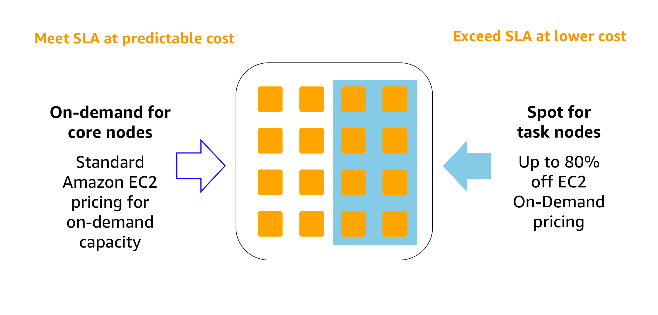
インスタンス購入オプションの詳細については、インスタンス購入オプションを参照してください。
EMRの Auto Scaling 機能が 2016 年以降から利用可能になり、さらに効率的に実装できるようになりました。ユーザーの実際に使ったリソースと使いたいリソースの比率は時間とともに変化しますが、このサービスが自動的に管理してくれます。詳細については、自動スケーリングのベストプラクティスを参照してください。
ストレージコストをさらに削減することもできます。Amazon S3 とストレージをデカップリングする EMRFS は、ストレージ容量とは無関係にクラスタのコンピューティングリソースを拡張する機能を提供します。言い換えれば、EMRFS だけで既にコスト削減に役立つのです。ストレージコストを節約するもう一つの方法は、データを分割して処理と分析のためのスキャンの量を減らすことです。これは「ゴルディロックス」の原理を受けたものです。不要なデータの読み込みを避けられると同時に、必要なデータを見つけるための過度なオーバーヘッドも避けられるサイズのパーティションを、ユーザーは必要としています。
Apache Hiveに外部テーブルを自動で分割するにはこちらに一例があります。 ファイルサイズを最適化することで Amazon S3 リクエストが削減され、データを圧縮することでデータをコンピューティングインスタンスに読み込むために必要な帯域幅を最小限に抑えることができます。特に、データ保存のためのカラム型フォーマットは、行ベースのレイアウトよりも、大きなデータ処理と解析に関して通常より効率的です。
これらの推奨された方法を適用することで、前述のように TCO を 57% 削減できました。
これらのアイデアで成功した事例は IDC ホワイトペーパーに掲載されています。Amazon EMR ユーザーの声をご紹介しましょう。
「Amazon EMRは、コストに見合う最高の価値があります。主な要因の 1 つは、当社のデータが明らかに増えていることです。[Amazon] EMR でビッグデータの操作を実行することで、信頼性が向上します。膨大な量のデータを低価格で保管できるのは、実によいことです。2 つめに、当社が必要とする計算が大きく変動することがあります。データベース内の一部のデータは、ビジネスアナリストやデータアナリストによって時々使用されるだけです。EMR を選択する理由は、費用対効果の最も高いソリューションであり、ニーズに基づく計算拡張を備えているからです。」
IT スタッフの生産性向上の推進
インフラストラクチャの節約は、Apache Spark や Amazon EMR をパブリッククラウドに移行する最も分かりやすい動機ですが、IT スタッフの生産性にとっても大きな利点となります。Amazon EMR はマネージド型サービスのため、スタッフがハードウェアインフラストラクチャの評価、購入、インストール、プロビジョニング、統合、維持、サポートなどに時間を費やす必要がありません。急速に革新しているオープンソースソフトウェアの世界では、ソフトウェアインフラストラクチャの評価、インストール、パッチ、アップグレード、トラブルシューティングは終わりのない仕事となり得ますが、それらを行う必要もありません。
Amazon EMR の環境は管理され、顧客に合わせて最新の状態に保たれているので、そのようなすべての労力や、関連する「ソフト」のコストがなくなります。IT スタッフは、インフラストラクチャ管理を行う代わりに、データエンジニア、データ科学者、ビジネスアナリストの戦略的な取り組みのサポートに集中して時間をかけることができます。IDC ホワイトペーパーでは、これらの利点から、年間の従業員時間のコストを、対オンプレミスで 62% 削減するとともに、ビッグデータ環境管理者の人件費を 54% 削減することができました。回答者は、より機敏になり、品質を向上させ、より速く発展するのに役立つとも話していました。
IDC よりインタビューを受けた別の顧客は、次のように述べてこれを要約しています。
「Amazon EMR の既製の統合サイトを利用しました。統合に時間を費やす必要はないのです。別の Hadoop テクノロジーを選んだとして、研究者はそれをきちんと機能させなければなりませんが、うまくいかなかった場合、身をもって失敗を知ることになります。Amazon EMR がなかったらおそらく、より多くのテストを重ね、そのために 3 人余計に雇って統合作業を実施しなければならなかったでしょう」
より強固な可用性のビッグデータ環境を提供
言及されている 3 番目の主要な節約の領域は、リスク軽減の向上です。AWS のサービスは長年にわたる効率的で柔軟な運用の教訓に基づいて構築されているため、AWS は 99.99% 以上の可用性および耐障害性という約束に応えます。しばしばもっと多くの 9 がついたパーセンテージで。IDC の調査では、不測のダウンタイムを回避すれば、IT スタッフおよび分析スタッフが失う生産性を 99% 削減できるとされています。
あるお客様は言います。「システムの耐障害性をさらに向上させました。すべてはパフォーマンスと耐障害性なのです」
Amazon EMR への移行には、このほか多くの経済的メリットがあります。それらメリットはしばしばスタッフの生産性向上につながり、コストの節約のみならず、パフォーマンスの向上や、分析においては測定可能な ROI を提供します。しかしながら IDC ホワイトペーパー の全文をなおざりにしてはいけません。ご自身でもぜひお読みになってください。
著者について
 Nikki Rouda は AWS でデータレイクおよびビッグデータ向け製品マーケティング主任マネージャーを務めています。Nikki は20 年以上にわたり 40 か国以上で企業の分析および IT インフラストラクチャの課題に対して、ソリューションを開発および実装するのをサポートしてきました。Nikki はケンブリッジ大学で経営管理学修士号を、ブラウン大学で地球物理学と数学の理学士号を取得しています。
Nikki Rouda は AWS でデータレイクおよびビッグデータ向け製品マーケティング主任マネージャーを務めています。Nikki は20 年以上にわたり 40 か国以上で企業の分析および IT インフラストラクチャの課題に対して、ソリューションを開発および実装するのをサポートしてきました。Nikki はケンブリッジ大学で経営管理学修士号を、ブラウン大学で地球物理学と数学の理学士号を取得しています。