Amazon Web Services ブログ
SAP HANAを使用したAWSデータレイクに対するフェデレーテッドクエリの実行
この記事は、Amazon Web Services (AWS)でソリューション アーキテクトを務めるHarpreet Singhによるものです。
アバディーンの調査によると、データレイクを導入している組織は、類似企業に比べて有機的収益成長率が9%上回ることが明らかになっています。 データレイクは、これらの企業がデータから有意義な洞察をする能力を得て、競合他社と差別化を図るための行動を促進します。
耐久性とコスト効率を備えたAmazon Simple Storage Service (Amazon S3)は、AWSデータレイクのストレージ層として使用する魅力的な理由があります。これらのお客様の多くは、SAP HANAベースのアプリケーションをAWS上で導入しており、SAP HANAとAmazon S3ベースのデータレイクにあるデータを使用した分析基盤を構築して、分析実行には主にSAP HANAを使用したいと考えています。
SAP HANAからAWSデータレイクへのクエリをフェデレーションするシナリオは数多くあります。具体的な例をいくつか挙げてみます。
- ユーティリティ産業: AWSデータレイクに電力消費に関連するデータを保管し、SAP HANAのクエリをフェデレートして将来のエネルギー消費量を予測できます。
- 小売業界: AWSデータレイクに会社のソーシャルメディア活動を保管し、SAP CRMの顧客チケットと照らし合わせて分析することで、顧客満足度を向上できます。小売業界のもう1つの例は、電子商取引のウェブサイトとSAPシステムにある資材在庫や商品在庫のデータ分析です。
- 医薬品業界: AWSデータレイクにあるアーカイブされた在庫データとSAPシステムにある現在の在庫データを使用して、リコールの分析を実行できます。
このブログでは、Amazon Athenaを使用してAmazon S3ベースのデータレイクにフェデレーテッドクエリを実行するためのSAP HANAの設定手順を紹介します。
最初にアーキテクチャを見てみましょう。データレイクのストレージとしてAmazon S3を使用し、様々なデータソース (例えば、ウェブアプリケーション、その他のデータベース、ストリーミングデータ、その他のSAP以外のシステムなど)から生データを受け取るAmazon S3 バケットがあります。生データはAWS Glueを介して変換され、Athenaがサポートしている形式で別のAmazon S3 バケットに保管されます。AWS Glue クローラは変換されたデータをカタログ化します。AWS Glueを使ったデータカタログの構築方法については、このブログ記事を参照してください。
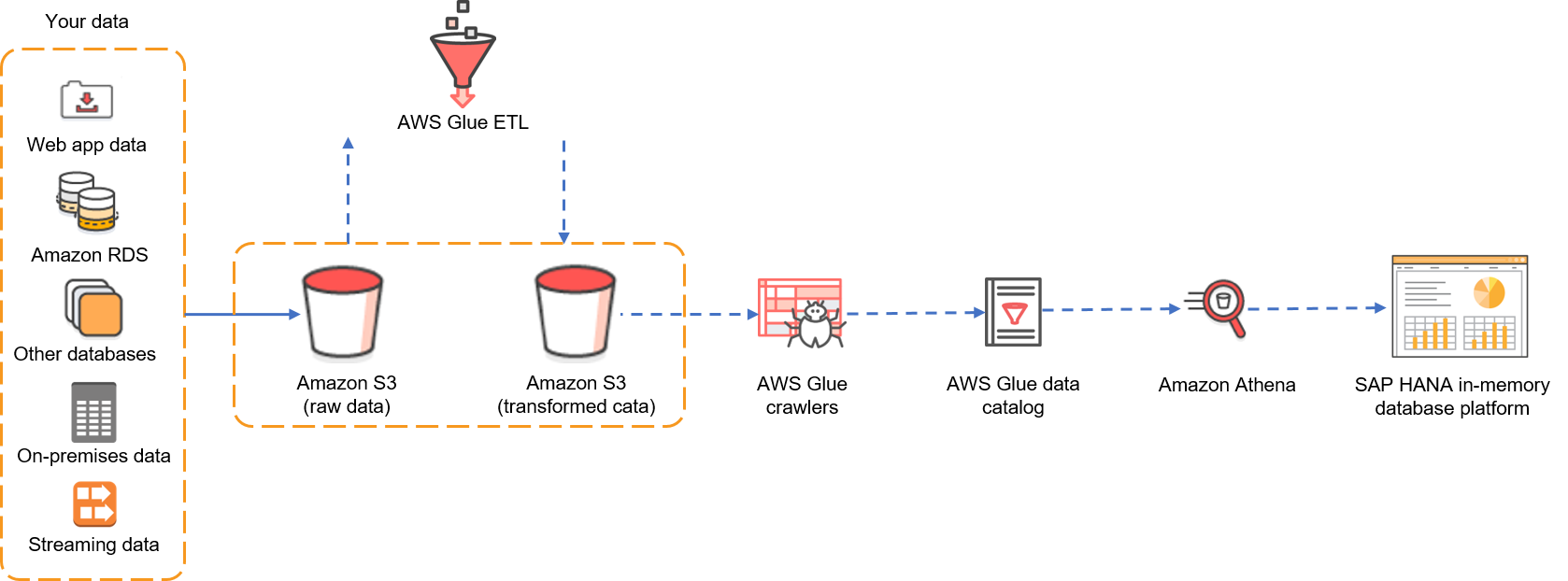 図 1: 複数ソースからのデータがS3に格納され、Athenaを使用してSAP HANAのフェデレーテッドクエリが返る
図 1: 複数ソースからのデータがS3に格納され、Athenaを使用してSAP HANAのフェデレーテッドクエリが返る
この例では、Athenaを使用してSAP HANAからクエリをフェデレーションすることに焦点を当てます。私は既にオープンソースの電子商取引データを含むテーブルをクロールしてカタログ化しています。以下が詳細です。
- 電子商取引サイトの販売記録のサンプルを含むCSVファイル、eCommerce-Data.csvは、S3 バケット内の変換データに利用できます。このCSVには、様々な顧客の販売記録が含まれています。

- AWS Glueは、S3 バケット内の変換データをクロールしてカタログ化し、AWS Glueのecommerce-databaseというデータベースのecommerce_dataテーブルに保存します。

- データベースとテーブルはAthenaから利用でき、Athena クエリエディタを使用することで、このテーブルに対してSQLクエリを実行することができます。

私たちの目的は、SAP HANAからecommerce-databaseにあるecommerce_dataテーブルにクエリをフェデレーションすることです。
筋道が立ったので、このセットアップに必要な技術的な内容に少し焦点を当てましょう。
- SAP HANA 1.0 SP6以降で利用可能になった強力な機能であるSAP HANA Smart Data Access (SDA)により、外部データソースにデータ操作言語 (DML) ステートメントを実行できます。リモートデータソースのテーブルを示す仮想テーブルをSAP HANA上に作成することができます。
- Athenaは、JDBCとODBCの両方のドライバーを提供しており、他のアプリケーションがAthenaのテーブルをクエリするために使用できます。SAP HANA SDAはODBCドライバーだけをサポートしているため、このブログ記事ではODBCドライバーを使用します。
SAP HANAシステムでAthena ODBCドライバーのインストールと構成
まず、SAP HANAシステムにODBCマネージャーとAthena ODBCドライバーをインストールする必要があります。 (AWSでのSAP HANAの導入については、SAP HANAクイックスタートのデプロイメントガイドを参照してください。)
以下の手順では、オペレーティングシステムはSUSE Linuxと仮定します (RHELの場合も手順は同様です)。ODBCドライバーのインストールの詳細手順については、Symba Technologies ODBCドライバーのインストールと構成ガイドを参照してください。
1. ODBCマネージャーのインストール
iODBC (version 3.52.7以上)、あるいはunixODBC (version 2.3.0以上)をインストールします。ここでは、unixODBCを使用します。
SAP HANAシステムにunixODBCをインストールするために、rootとして次のコマンドを実行します。
zypper install -y unixODBC

2. Athena ODBCドライバーのインストール
最新のRPMパッケージのURLについては、ODBCを使用したAmazon Athenaへの接続を参照してください。次に、SAP HANAインスタンス上で、wgetコマンドのURLとzypperコマンドのファイル名を置き換えて、rootとして次のコマンドを実行します。
mkdir AthenaODBC cd AthenaODBC wget https://s3.amazonaws.com/athena-downloads/drivers/ODBC/Linux/simbaathena-1.0.2.1003-1.x86_64.rpm zypper --no-gpg-checks install -y simbaathena-1.0.2.1003-1.x86_64.rpm

3. SAP HANAインスタンスにIAMポリシーをアタッチ
SAP HANAインスタンスに割り当てられたIAMロールに管理ポリシーAmazonAthenaFullAccessをアタッチします。詳細は、Athenaのドキュメントを参照してください。
ポリシーをコピーして、特定のニーズに合うようにカスタマイズすることも可能です。

4. Athena ODBCドライバーの構成
SAP HANAインスタンスで、<sid>admとしてログインし、ホームディレクトリに移動します。.odbc.iniを次の内容で作成し、強調表示された値を特定の設定に置き換えます。MyDSNはデータソースの名前です。(好きな名前に変更できます。)
[Data Sources] MyDSN=Simba Athena ODBC Driver 64-bit [MyDSN] Driver=/opt/simba/athenaodbc/lib/64/libathenaodbc_sb64.so AuthenticationType=Instance Profile AwsRegion=<AWS Region where you want to use Athena> S3OutputLocation=s3://<tempbucket>/<folder>/
以下に例を示します。

私はAWSシドニーリージョンを使用していますので、AwsRegionは、ap-southeast-2にしました。S3OutputLocationは、既に作成していたTempForSAPAthenaIntegrationフォルダを含むAmazon S3 バケットにしました。これらの値を変更し、設定を反映してください。
5. 環境変数を設定
<sid>admとして、次の内容の.customer.shを作成し、このファイルのアクセス許可を700に変更します。
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/opt/simba/athenaodbc/lib/64/
export ODBCINI=$HOME/.odbc.ini

<sid>admを終了し、再度ログインして、.customer.shで設定された環境変数が有効であることを確認します。(つまり、ODBCINI変数が表示され、LD_LIBRARY_PATHが変更されています。)

Amazon Athena ODBCドライバーのテスト
今度は、前述の手順でインストールしたODBCドライバーを使用してAthenaへの接続をテストします。SAP HANAインスタンスで、<sid>admとして、強調表示されたテキストをデータソース名に置き換えて、次のコマンドを実行します。
isql <Data Source Name> -c -d,
この例では、データソース名をodbc.iniのMyDSNとして定義しました。ここではそれをデータソース名として使用します。

エラーなしでSQLプロンプトが表示されれば、ODBCドライバーは正常に構成されています。続いて、自分の環境にあるecommerce_dataテーブルに対してクエリを実行し、Athenaでクエリを実行できて、結果を取得できることを確認しましょう。

素晴らしい。すべて上手くいきました。
SAP HANAの設定
前述のとおり、SAP HANA SDAを使用してAthenaのリモートデータソースに接続します。この接続用にSAP HANA SDA Generic ODBCアダプターを構成します。
1. Athena プロパティファイルの作成
SAP HANA SDA Generic ODBCアダプターには、リモートデータソースの機能をリストする構成ファイルが必要です。このプロパティファイルは、rootユーザーで/usr/sap/<SID>/ SYS/exe/hdb/config配下に作成する必要があります。このファイルはProperty_Athena.ini (この名前は変更できます)と呼び、次の内容で作成します。
CAP_SUBQUERY : true CAP_ORDERBY : true CAP_JOINS : true CAP_GROUPBY : true CAP_AND : true CAP_OR : true CAP_TOP : false CAP_LIMIT : true CAP_SUBQUERY : true CAP_SUBQUERY_GROUPBY : true FUNC_ABS : true FUNC_ADD : true FUNC_ADD_DAYS : DATE_ADD(DAY,$2,$1) FUNC_ADD_MONTHS : DATE_ADD(MONTH,$2,$1) FUNC_ADD_SECONDS : DATE_ADD(SECOND,$2,$1) FUNC_ADD_YEARS : DATE_ADD(YEAR,$2,$1) FUNC_ASCII : true FUNC_ACOS : true FUNC_ASIN : true FUNC_ATAN : true FUNC_TO_VARBINARY : false FUNC_TO_VARCHAR : false FUNC_TRIM_BOTH : TRIM($1) FUNC_TRIM_LEADING : LTRIM($1) FUNC_TRIM_TRAILING : RTRIM($1) FUNC_UMINUS : false FUNC_UPPER : true FUNC_WEEKDAY : false TYPE_TINYINT : TINYINT TYPE_LONGBINARY : VARBINARY TYPE_LONGCHAR : VARBINARY TYPE_DATE : DATE TYPE_TIME : TIME TYPE_DATETIME : TIMESTAMP TYPE_REAL : REAL TYPE_SMALLINT : SMALLINT TYPE_INT : INTEGER TYPE_INTEGER : INTEGER TYPE_FLOAT : DOUBLE TYPE_CHAR : CHAR($PRECISION) TYPE_BIGINT : DECIMAL(19,0) TYPE_DECIMAL : DECIMAL($PRECISION,$SCALE) TYPE_VARCHAR : VARCHAR($PRECISION) TYPE_BINARY : VARBINARY TYPE_VARBINARY : VARBINARY PROP_USE_UNIX_DRIVER_MANAGER : true
2. Proprty_Athena.iniのプロパティの変更
ファイルを作成したら、所有者を<sid>adm:sapsysに更新し、権限を444に変更します。

3. SAP HANAの再起動
先に.customer.shで設定した環境変数で起動するように、SAP HANAを再起動する必要があります。
4. リモートデータソースの作成
SAP HANA Studioを使用してSAP HANAにログインし、メニューパスに従ってリモートデータソースを登録します。

5. リモートソースのプロパティを定義
ソース名、アダプター名、接続モード、構成ファイル、データソース名、DMLモード、およびユーザー名とパスワードの値を入力します。ユーザー名とパスワードは、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスに割り当てられているAthena ロールに基づいてアクセスするため、関係のないダミーの値を入力します。構成ファイルの値があなたが作成した構成ファイルの名前 (私たちの例では、Property_Athena.ini)と、データソースの値があなたがodbc.iniで定義した名前 (私たちの例では、MyDSN)と一致することを確認します。
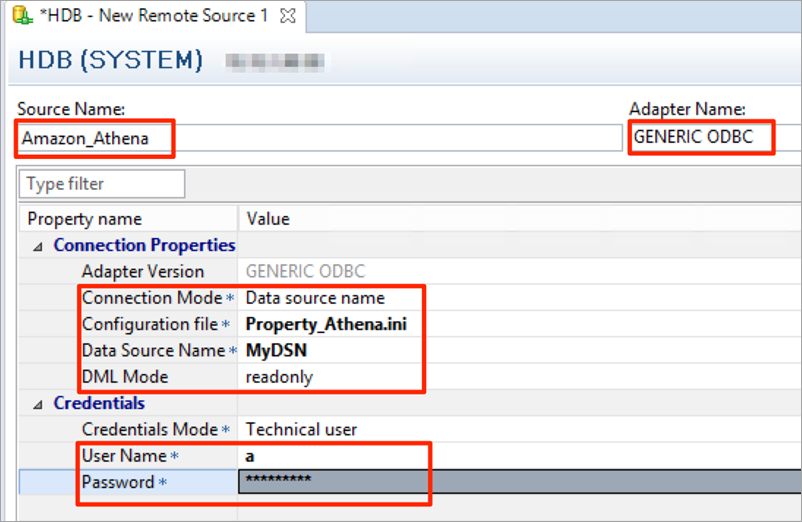
次に、(Ctrl + S)で保存して、接続テストが正常に完了したことを確認します。
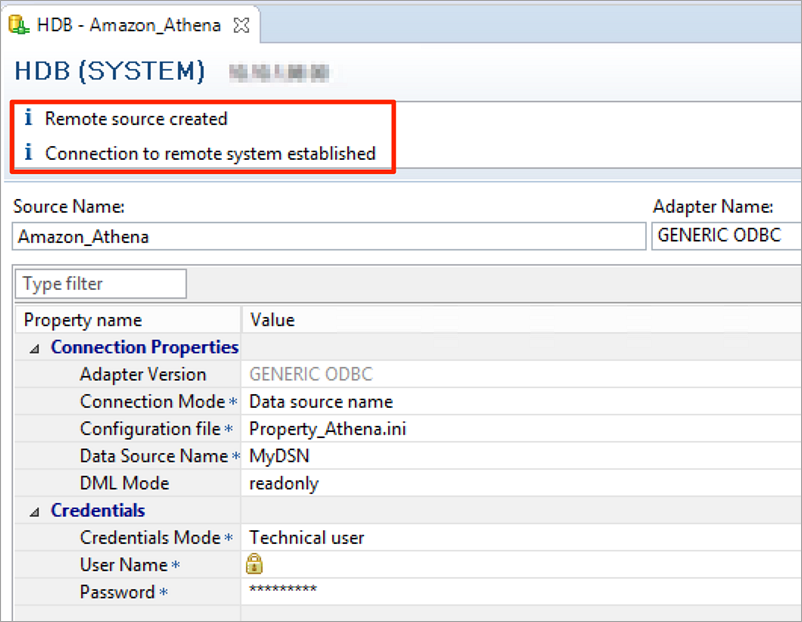
リモートデータソースAmazon_AthenaがSAP HANA上に作成されており、データベースとテーブルを拡張して (私の例では、ecommerc-databaseとecommerce_dataを)表示できています。

6. 仮想テーブルの作成
次のステップでは、リモートデータソースのテーブルを示す仮想テーブルをSAP HANA上に作成します。リモートソースのテーブル名を(右クリック)してメニューを開き、仮想テーブルとして追加を選択します。
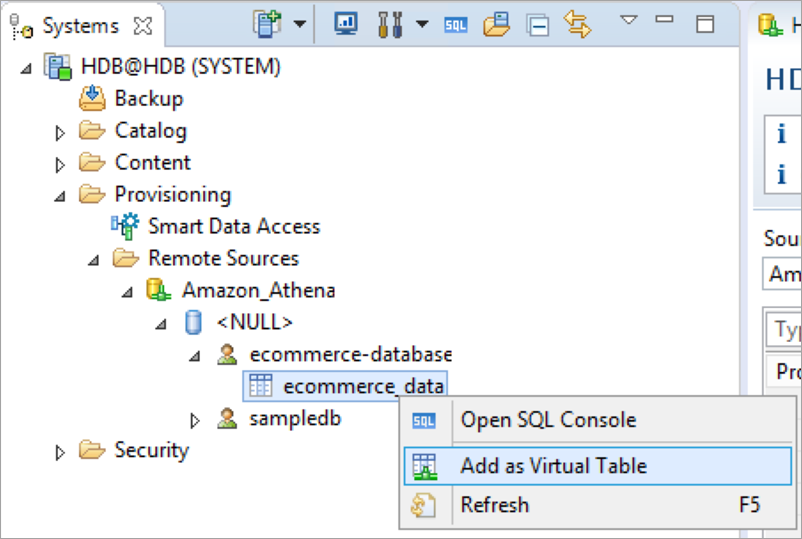
仮想テーブルを定義する必要があるテーブルとスキーマの名前を入力します。例えば、私はSYSTEMスキーマにvir_ecommerce_dataという仮想テーブルを作成しています。

SYSTEMスキーマの仮想テーブルを確認できます。
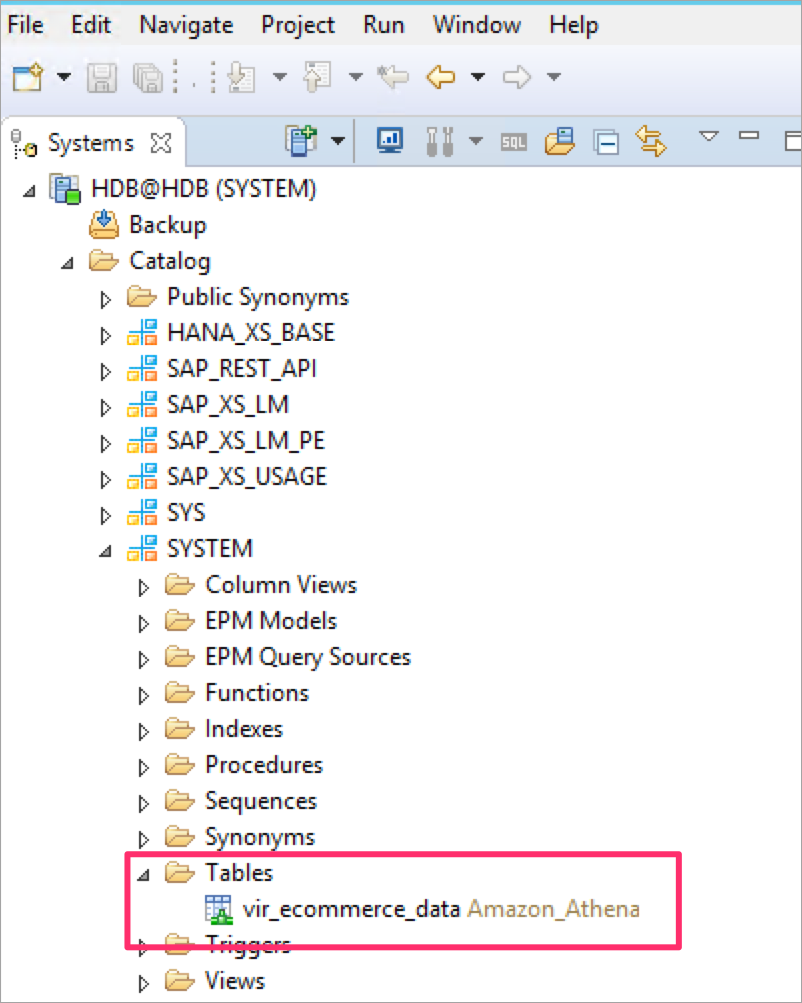
7. 仮想テーブルでクエリを実行
SQLコンソールを開き、仮想テーブルでSQLクエリを実行します。結果が返ってくるはずです。

8. ローカルテーブルと仮想テーブルでクエリを実行
SAP HANAで、得意先の詳細を含むCUSTOMERMASTERという名称でローカルテーブルを作成しました。

CUSTOMERMASTERテーブルにリストされているCustomerIDで、仮想テーブルから行のリストをフィルタリングします。
select distinct C."FNAME", C."LNAME",V."customerid", V."country" from "CUSTOMERMASTER" as C, "vir_ecommerce_data" as "V" where V."customerid" = C."CUSTOMERID"
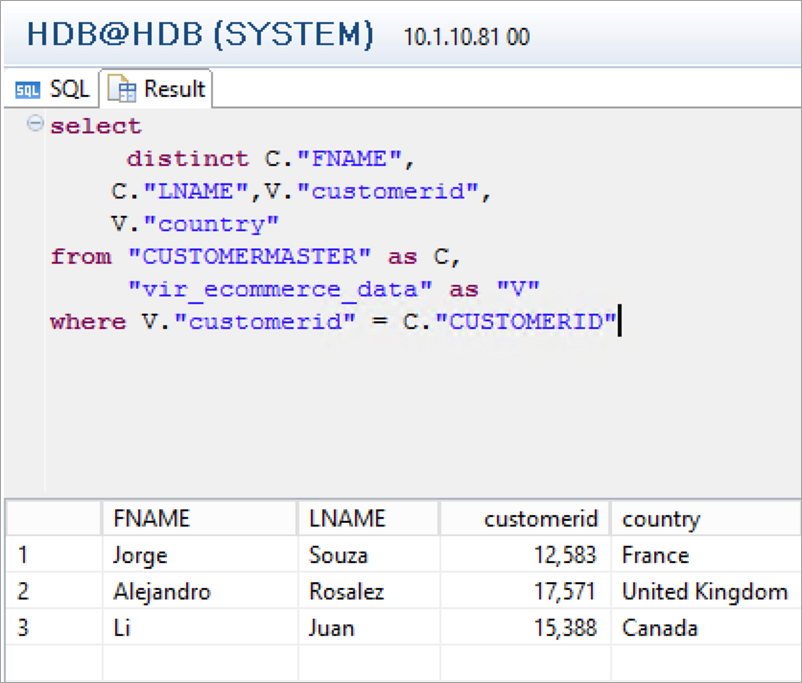
Athenaを使用することで、SAP HANAからAmazon S3ベースのデータレイクに対して正常にフェデレーテッドクエリを実行できました。
サマリー
SAP HANA SDA機能とAmazon AthenaのODBCドライバーを使用して、SAP HANAからAthenaへのクエリをフェデレーションしました。SAP HANAにデータをコピーすることなく、SAP HANAのデータとAmazon S3のデータレイクで利用可能なデータを組み合わせることができます。クエリはAthenaによって実行され、結果はSAP HANAに送信されます。
お客様がSAP HANAとAthenaをどのように使用したか私たちに教えてください。また、質問があればご連絡ください。SAPシステムをAWSに移行するために、AWSプロモーションクレジットを使用することができます。クレジットの申請と適用方法を知りたい場合は、お問い合わせください。
翻訳はPartner SA 河原が担当しました。原文はこちらです。