Amazon Web Services ブログ
AWS Glue と Amazon S3 を使用してデータレイクの基礎を構築する
データレイクは、大量の様々なデータを扱うという課題に対処するため、データを分析および保存するための方法としてますます一般的になっています。データレイクを使うと、組織は全ての構造化データおよび非構造化データを1つの中央リポジトリに格納できます。データはそのまま保存できるため、あらかじめ定義されたスキーマに変換する必要はありません。
多くの組織は AWS をデータレイクとして使う価値を理解しています。例えば Amazon S3 は高い耐久性があり、コンピューティングとストレージの分離をしながら、オープンデータフォーマットをサポートする費用対効果の高いオブジェクトの開始ができ、全てのAWS 分析サービスと連携します。Amazon S3 はデータレイクの基礎を提供しますが、他のサービスを追加してビジネスニーズに合わせることができます。AWS のデータレイク構築の詳細については What is a Data Lake? を参照してください。
データレイクを使う主な課題は、データの検索とスキーマやデータフォーマットの理解であるため、Amazonは AWS Glue をリリースしました。AWS Glue は Amazon S3 データレイクからデータ構造と形式を発見することで、迅速にビジネスの洞察を導き出すために要する時間と労力を大幅に削減します。AWS Glue は Amazon S3 上のデータを自動的にクロールし、データフォーマットを特定し、他の AWS 分析サービスで使用するためのスキーマを提案します。
この記事では、AWS Glue を使って Amazon S3 上のデータをクロールする方法と他のAWSサービスで使用できるメタデータストアを構築するプロセスを説明します。
AWS Glue の特徴
AWS Glue はフルマネージドのデータカタログとETL(抽出、変換、ロード)サービスで、データの発見、変換、およびジョブスケジューリングなどの困難で時間のかかる作業を簡素化し自動化します。AWS Glue はデータソースをクロールし、CSV, Apache Parquet, JSON などの一般的なデータフォーマットとデータタイプ用に事前作成された Classifire を使用してデータカタログを構築します。
AWS Glue はモダンなデータアークテクチャーのコンポーネントである S3, Amazon RDS, Amazon Athena, Amazon Redshift, Amazon Redshift Spectrum と統合されているため、データの移動と管理をシームレスに調整します。
AWS Glue データカタログは Apache Hive メタストアと互換性があり、Hive, Presto, Apache Spark, Apache Pig などの一般的なツールをサポートしています。 Amazon Athena, Amazon EMR, Amazon Redshift Spectrum とも直接統合されています。
さらに AWS Glue データカタログには、使いやすさとデータ管理のための以下の機能があります。
- 検索でデータを発見する
- 分類されたファイルの識別と解析
- スキーマの変更をバージョン管理
詳細は AWS Glue 製品の詳細 を参照してください。
Amazon S3 データレイク
AWS Glue は S3 データレイクの必須コンポーネントで、モダンなデータ分析にデータカタログとデータ変換サービスを提供します。

上の図では様々な分析ユースケースに対してデータがステージングされています。最初にデータは生の形式で不変のコピーとして取り込まれます。次にデータは変換され各ユースケースに対してより価値あるものになります。この例では、生の CSV ファイルは Amazon Athena がパフォーマンスを向上しコストを削減するために使用する Apache Parquet に変換されています。
データはさらなる洞察を得るために他のデータセットとブレンドすることができます。AWS Glue クローラは、ジョブトリガーまたは事前定義されたスケジュールに基いてデータベースの各ステージごとにテーブルを作成します。この例では、S3 に新しいファイルが追加されるたびに AWS Lambda 関数を使って ETL プロセスを実行しています。このテーブルは、Amazon Athena, Amazon Redshift Spectrum, および Amazon EMR が標準 SQL または Apache Hive を使用して任意の段階でデータを照会するために使用できます。この構成は、さまざまなデータからビジネス価値を迅速かつ容易に導き出すためのアジャイルビジネスインテリジェンスを提供する一般的な設計パターンです。
チュートリアル
このチュートリアルでは、データベースを定義し、Amazon S3 バケットのデータを探索するクローラを設定し、テーブルを作成し、CSV ファイルを Parquet に変換し、Parquet データのテーブルを作成し、Amazon Athena でデータを照会します。
データを発見する
AWS マネージメントコンソールにサインインし AWS Glue コンソールを開きます。AWS Glue は分析のセクションにあります。対応リージョンは米国東部(バージニア北部)、米国東部(オハイオ)、米国西部(オレゴン)で今後も対応リージョンは頻繁に追加していきます。
データの発見の第一歩はデータベースを追加することです。データベースはテーブルの集まりです。
- コンソールで Add database を選択し、Database name に nycitytaxi と入力し Create をクリックします。

- 左側のメニューの Tables をクリックし、テーブルは列の名前、データ型の定義、およびその他のデータセットに関するメタデータで構成されています。

- データベース nycitytaxi にテーブルを追加します。手動またはクローラを使ってテーブルを追加できます。 クローラは、データストアに接続し、順位付けされた Classifier を使用してデータのスキーマを決定するプログラムです。 AWS Glue はCSV, JSON, Avro などの一般的なファイルタイプの Classifier を提供します。grok パターンを使用してカスタム Classifier を作成することもできます。

- クローラを追加します。Data store に S3 、Include path に s3://aws-bigdata-blog/artifacts/glue-data-lake/data/ を選びます。この S3 バケットには2017年1月のグリーンタクシーの全ての乗車データがあります。

- Next をクリックします。

- IAM role でドロップダウンから AWSGlueServiceRoleDefault を選択します。

- Frequency で Run on demand を選択します。クローラはオンデマンド実行やスケジュール実行が可能です。

- Database は nycitytaxi を選んでください。スキーマの変更をAWS Glueがどのように処理するのかを理解することが重要で、適切な処理方法を選択することが可能です。この例ではいかなる更新でも(データカタログ上)のテーブルが更新されます。 スキーマ変更の詳細については Cataloging Tables with a Crawler を参照ください。

- 手順を確認して、Finish をクリックし、クローラは実行準備ができているので Run it now を選択します。

- クローラが終了すると、テーブルが1つ追加されます。

- 左側のメニューの Tables をクリックし data を選択します。この画面ではテーブルのスキーマ、プロパティ、およびその他の重要な情報を説明します。


データを CSV 形式から Parquet 形式に変換する
これでデータを CSV から Parquet に変換するジョブを設定して実行することができます。Parquet は Amazon Athena や Amazon Redshift Spectrum などの AWS 分析サービスに適したカラムナフォーマットです。
- 左側のメニューの ETL の下の Jobs をクリックし、Add job をクリックします。

- Name に nytaxi-csv-parquet を入力します。
- IAM role で AWSGlueServiceRoleDefault を選択します。
- This job runs で A proposed script generated by AWS Glue を選択します。
- スクリプトを保存する任意の S3 パスを入力します。
- 一時ディレクトリ用のS3パスを入力します。
- Next をクリックします。

- データソースとして data を選択します。

- Create tables in your data target にチェックを入れる。
- Formatで Parquet を選択します。
- 結果を保存する新しい場所(既存オブジェクトがない新しいプレフィックス場所)を選択します。

- スキーマのマッピングを確認し、Finish をクリックします。

- ジョブを表示します。この画面では完全なジョブの表示を提供し、ジョブを編集、保存、実行することができます。AWS Glue がこのスクリプトを作成しましたが、必要に応じて自分で作成することもできます。

- Save をクリックし、Run job をクリックします。
Parquet テーブルとクローラを追加する
ジョブ終了したら、クローラを使って Parquet データ用の新しいテーブルを追加します。
- Crawler name で nytaxiparquet を入力します。

- Data store で S3 を選択します。
- Include path で ETL で選択したS3パスを入力します。

- IAM role で AWSGlueServiceRoleDefault を選択します。

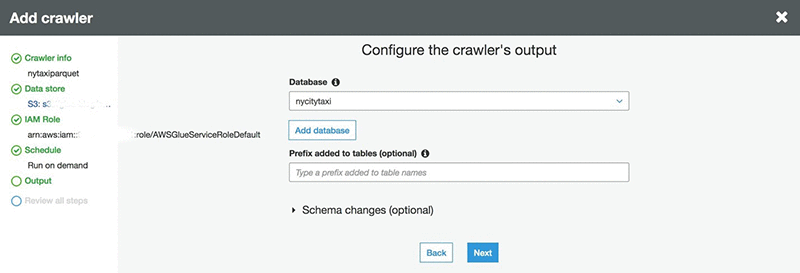
- Frequency で Run on demand を選択します。

- Database で nycitytaxi を選択します。
クローラが終了した後、nycitytaxi データベースには、CSVデータ用テーブルと変換された Parquet データ用テーブルの2つのテーブルがあります。
Amazon Athena でデータ分析する
Amazon Athena は、標準 SQL を使って Amazon S3 のデータを簡単に分析できるインタラクティブなクエリサービスです。Athena は CSVデータを照会することができますが Parquet のファイルフォーマットにするとデータクエリの時間を大幅に削減できます。詳細については Analyzing Data in Amazon S3 using Amazon Athena を参照してください。
Amazon Athena で AWS Glue を使用するには、Athena データカタログを AWS Glue Data Catalog にアップグレードする必要があります。Athena データカタログのアップグレード詳細については、この step-by-step guide を参照してください。
- マネージメントコンソール で Athena を開きます。 クエリエディタのデータベース nycitytaxi に2つテーブルが表示されています。

標準SQLを使ってクエリできます。
- nytaxigreenparquet を選択します。
- Select * From “nycitytaxi”.”data” limit 10; を入力します。
- Run Query をクリックします。

まとめ
この記事は AWS Glue と Amazon S3 を使ってデータレイクの基礎を構築することがどれほど簡単かを示しています。 AWS Glue を使って S3のデータをクロールし、Apache Hive と互換性のあるメタストアを構築することで、AWS のアナリティクスサービスと一般的な Hadoop エコシステムでこのメタデータを使うことができます。この組み合わせは強力で使いやすいため、より早くビジネスの洞察を得ることができます。
追加情報
詳細については次のブログを参照してください。
- Build a Schema-On-Read Analytics Pipeline Using Amazon Athena
- Harmonize, Query, and Visualize Data from Various Providers using AWS Glue, Amazon Athena, and Amazon QuickSight
翻訳は上原が担当しました。(原文はこちら)