AWS Big Data Blog
Build a Schema-On-Read Analytics Pipeline Using Amazon Athena
A robust analytics platform is critical for an organization’s success. However, an analytical system is only as good as the data that is used to power it. Wrong or incomplete data can derail analytical projects completely. Moreover, with varied data types and sources being added to the analytical platform, it’s important that the platform is able to keep up. This means the system has to be flexible enough to adapt to changing data types and volumes.
For a platform based on relational databases, this would mean countless data model updates, code changes, and regression testing, all of which can take a very long time. For a decision support system, it’s imperative to provide the correct answers quickly. Architects must design analytical platforms with the following criteria:
- Help ingest data easily from multiple sources
- Analyze it for completeness and accuracy
- Use it for metrics computations
- Store the data assets and scale as they grow rapidly without causing disruptions
- Adapt to changes as they happen
- Have a relatively short development cycle that is repeatable and easy to implement.
Schema-on-read is a unique approach for storing and querying datasets. It reverses the order of things when compared to schema-on-write in that the data can be stored as is and you apply a schema at the time that you read it. This approach has changed the time to value for analytical projects. It means you can immediately load data and can query it to do exploratory activities.
In this post, I show how to build a schema-on-read analytical pipeline, similar to the one used with relational databases, using Amazon Athena. The approach is completely serverless, which allows the analytical platform to scale as more data is stored and processed via the pipeline.
The data integration challenge
Part of the reason why it’s so difficult to build analytical platforms are the challenges associated with data integration. This is usually done as a series of Extract Transform Load (ETL) jobs that pull data from multiple varied sources and integrate them into a central repository. The multiple steps of ETL can be viewed as a pipeline where raw data is fed in one end and integrated data accumulates at the other.
Two major hurdles complicate the development of ETL pipelines:
- The sheer volume of data needing to be integrated makes it very difficult to scale these jobs.
- There are an immense variety of data formats from where information needs to be gathered.
Put this in context by looking at the healthcare industry. Building an analytical pipeline for healthcare usually involves working with multiple datasets that cover care quality, provider operations, patient clinical records, and patient claims data. Customers are now looking for even more data sources that may contain valuable information that can be analyzed. Examples include social media data, data from devices and sensors, and biometric and human-generated data such as notes from doctors. These new data sources do not rely on fixed schemas, so integrating them by conventional ETL jobs is much more difficult.
The volume of data available for analysis is growing as well. According to an article published by NCBI, the US healthcare system reached a collective data volume of 150 exabytes in 2011. With the current rate of growth, it is expected to quickly reach zettabyte scale, and soon grow into the yottabytes.
Why schema-on-read?
The traditional data warehouses of the early 2000s, like the one shown in the following diagram, were based on a standard four-layer approach of ingest, stage, store, and report. This involved building and maintaining huge data models that suited certain sources and analytical queries. This type of design is based on a schema-on-write approach, where you write data into a predefined schema and read data by querying it.

As we progressed to more varied datasets and analytical requirements, the predefined schemas were not able to keep up. Moreover, by the time the models were built and put into production, the requirements had changed.
Schema-on-read provides much needed flexibility to an analytical project. Not having to rely on physical schemas improves the overall performance when it comes to high volume data loads. Because there are no physical constraints for the data, it works well with datasets with undefined data structures. It gives customers the power to experiment and try out different options.
How can Athena help?
Athena is a serverless analytical query engine that allows you to start querying data stored in Amazon S3 instantly. It supports standard formats like CSV and Parquet and integrates with Amazon QuickSight, which allows you to build interactive business intelligence reports.
The Amazon Athena User Guide provides multiple best practices that should be considered when using Athena for analytical pipelines at production scale. There are various performance tuning techniques that you can apply to speed up query performance. For more information, see Top 10 Performance Tuning Tips for Amazon Athena.
Solution architecture
To demonstrate this solution, I use the healthcare dataset from the Centers for Disease Control (CDC) Behavioral Risk Factor Surveillance system (BRFSS). It gathers data via telephone surveys for health-related risk behaviors and conditions, and the use of preventive services. The dataset is available as zip files from the CDC FTP portal for general download and analysis. There is also a user guide with comprehensive details about the program and the process of collecting data.
The following diagram shows the schema-on-read pipeline that demonstrates this solution.

In this architecture, S3 is the central data repository for the CSV files, which are divided by behavioral risk factors like smoking, drinking, obesity, and high blood pressure.
Athena is used to collectively query the CSV files in S3. It uses the AWS Glue Data Catalog to maintain the schema details and applies it at the time of querying the data.
The dataset is further filtered and transformed into a subset that is specifically used for reporting with Amazon QuickSight.
As new data files become available, they are incrementally added to the S3 bucket and the subset query automatically appends them to the end of the table. The dashboards in Amazon QuickSight are refreshed with the new values of calculated metrics.
Walkthrough
To use Athena in an analytical pipeline, you have to consider how to design it for initial data ingestion and the subsequent incremental ingestions. Moreover, you also have to decide on the mechanism to trigger a particular stage in the pipeline, which can either be scheduled or event-based.
For the purposes of this post, you build a simple pipeline where the data is:
- Ingested into a staging area in S3
- Filtered and transformed for reporting into a different S3 location
- Transformed into a reporting table in Athena
- Included into a dashboard created using Amazon QuickSight
- Incrementally ingested for updates
This approach is highly customizable and can be used for building more complex pipelines with many more steps.
Data staging in S3
The data ingestion into S3 is fairly straightforward. The files can be ingested via the S3 command line interface (CLI), API, or the AWS Management Console. The data files are in CSV format and already divided by the behavioral condition. To improve performance, I recommend that you use partitioned data with Athena, especially when dealing with large volumes. You can use pre-partitioned data in S3 or build partitions later in the process. The example you are working with has a total of 247 CSV files storing about 205 MB of data across them, but typical production scale deployment would be much larger.
To automate the pipeline, you can make it either event-based or schedule-based. If you take the event-based approach, you can make use of S3 events to trigger an action when the files are uploaded. The event triggers an action, using an AWS Lambda function that corresponds to another step in the pipeline. Traditional ETL jobs have to rely on mechanisms like database triggers to enable this, which can cause additional performance overhead.
If you choose to go with a scheduled-based approach, you can use Lambda with scheduled events. The schedule is managed via a cron expression and the Lambda function is used to run the next step of the pipeline. This is suitable for workloads similar to a scheduled batch ETL job.
Filter and data transformation
To filter and transform the dataset, first look at the overall counts and structure of the data. This allows you to choose the columns that are important for a given report and use the filter clause to extract a subset of the data. Transforming the data as you progress through the pipeline ensures that you are only exposing relevant data to the reporting layer, to optimize performance.
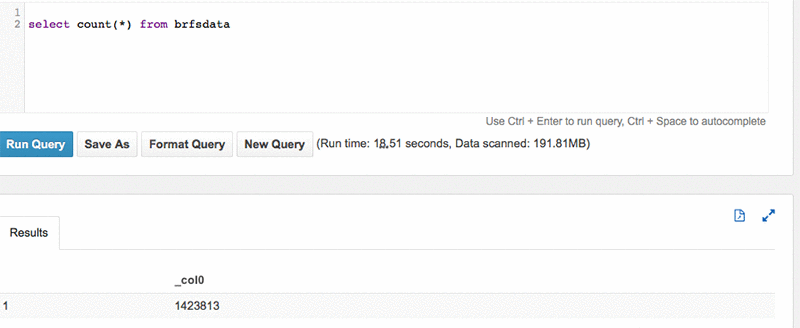
To look at the entire dataset, create a table in Athena to go across the entire data volume. This can be done using the following query:
Replace YourBucket and YourPrefix with your corresponding values.
In this case, there are a total of ~1.4 million records, which you get by running a simple COUNT(*) query on the table.
From here, you can run multiple analysis queries on the dataset. For example, you can find the number of records that fall into a certain behavioral risk, or the state that has the highest number of diabetic patients recorded. These metrics provide data points that help to determine the attributes that would be needed from a reporting perspective.
As you can see, this is much simpler compared to a schema-on-write approach where the analysis of the source dataset is much more difficult. This solution allows you to design the reporting platform in accordance with the questions you are looking to answer from your data. The source data analysis is the first step to design a good analytical platform and this approach allows customers to do that much earlier in the project lifecycle.
Reporting table
After you have completed the source data analysis, the next step is to filter out the required data and transform it to create a reporting database. This is synonymous to the data mart in a standard analytical pipeline. Based on the analysis carried out in the previous step, you might notice some mismatches with the data headers. You might also identify the filter clauses to apply to the dataset to get to your reporting data.
Athena automatically saves query results in S3 for every run. The default bucket for this is created in the following format:
aws-athena-query-results-<AWS Account ID>-<AWS Region>
Athena creates a prefix for each saved query and stores the result set as CSV files organized by dates. You can use this feature to filter out result datasets and store them in an S3 bucket for reporting.
To enable this, create queries that can filter out and transform the subset of data on which to report. For this use case, create three separate queries to filter out unwanted data and fix the column headers:
Query 1:
Query 2:
Query 3:
You can save these queries in Athena so that you can get to the query results easily every time they are executed. The following screenshot is an example of the results when query 1 is executed four times.

The next step is to copy these results over to a new bucket for creating your reporting table. This can be done by running an S3 CP command from the CLI or API, as shown below. Replace YourReportingBucket, YourReportingPrefix and Account ID with your corresponding values.
Note the prefix structure in which Athena stores query results. It creates a separate prefix for each day in which the query is executed, and stores the corresponding CSV and metadata file for each run. Copy the result set over to a new prefix on S3 for Reporting Data. Use the “exclude” and “include” option of S3 CP to only copy the CSV files and use “recursive” to copy all the files from the run.
You can replace the value of the saved query name from “Query1” to “Query2” or “Query3” to copy all data resulting from those queries to the same target prefix. For pipelines that require more complicated transformations, divide the query transformation into multiple steps and execute them based on events or schedule them, as described in the earlier data staging step.
Amazon QuickSight dashboard
After the filtered results sets are copied as CSV files into the new Reporting Data prefix, create a new table in Athena that is used specifically for BI reporting. This can be done using a create table statement similar to the one below. Replace YourReportingBucket and YourReportingPrefix with your corresponding values.
This table can now act as a source for a dashboard on Amazon QuickSight, which is a straightforward process to enable. When you choose a new data source, Athena shows up as an option and Amazon QuickSight automatically detects the tables in Athena that are exposed for querying. Here are the data sources supported by Athena at the time of this post:

After choosing Athena, give a name to the data source and choose the database. The tables available for querying automatically show up in the list.

If you choose “BRFSS_REPORTING”, you can create custom metrics using the columns in the reporting table, which can then be used in reports and dashboards.
For more information about features and visualizations, see the Amazon QuickSight User Guide.
Incremental data ingestion
To build a complete pipeline, think about ingesting data incrementally for new records as they become available. To enable this, make sure that the data can be incrementally ingested into the reporting schema and that the reporting metrics are refreshed on each run of the report. To demonstrate this, look at a scenario where the new dataset is ingested in a periodic basis into S3, and which has to be included into the reporting schema when calculating the metrics.
Look at the number of records in the reporting table before the incremental ingestion.
The results are as follows:
| _col0 | |
| 1 | 713123 |
Use Query1 as an example transformation query that can isolate the incremental load. Here is a view of the query result bucket before Query1 runs.

After the incremental data is ingested in S3, trigger an event (or pre-schedule) an execution of Query1 in Athena, which results in the csv result set and the metadata file as shown below.

Next, trigger (or schedule) the copy command to copy the incremental records file into the reporting prefix. This is easily automated by using the predefined structure in which Athena saves the query results on S3. On checking the records count in the reporting table after copying, you get an increased count.
| _col0 | |
| 1 | 810042 |
This shows that 96,919 records were added to our reporting table that can be used in metric calculations.
This process can be implemented programmatically to add incremental records into the reporting table every time new records are ingested into the staging area. As a result, you can simulate an end-to-end analytical pipeline that runs based on events or is scheduled to run as a batch workload.
Conclusion
Using Athena, you can benefit from the advantages of a schema-on-read analytical application. You can combine other AWS services like Lambda and Amazon QuickSight to build an end-to-end analytical pipeline.
However, it’s important to note that a schema-on-read analytical pipeline may not be the answer for all use cases. Carefully consider the choices between schema-on-read and schema-on-write. The source systems you are working with play a critical role in making that decision. For example:
- Some systems have defined data structures and the chances of variation is very rare. These systems can work with a fixed relational target schema.
- If the target queries mostly involve joining across normalized tables, they work better with a relational database. For this use case, schema-on-write is a good choice.
- The query performance in a schema-on-write application is faster as the data is pre-structured. For fixed dashboards with little to no changes, a schema-on-write is a good choice.
You can also choose to go hybrid. Offload a part of the pipeline that deals with unstructured flat datasets into a schema-on-read architecture, and integrate the output into the main schema-on-write pipeline at a later stage. AWS provides multiple options to build analytical pipelines that suit various use cases. For more information, read about the AWS big data and analytics services.
If you have questions or suggestions, please comment below.
Additional Reading
Don’t forget to check out the top 10 tips for Amazon Athena that can improve query performance.

About the Author
 Ujjwal Ratan is a healthcare and life sciences Solutions Architect at AWS. He has worked with organizations ranging from large enterprises to smaller startups on problems related to distributed computing, analytics and machine learning. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.
Ujjwal Ratan is a healthcare and life sciences Solutions Architect at AWS. He has worked with organizations ranging from large enterprises to smaller startups on problems related to distributed computing, analytics and machine learning. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.