AWS Big Data Blog
Tag: Amazon Quicksight

Build a multi-Region analytics solution with Amazon Redshift, Amazon S3, and Amazon QuickSight
This post explores how to effectively architect a solution that addresses this specific challenge: enabling comprehensive analytics capabilities for global teams while making sure that your data remains in the AWS Regions required by your compliance framework. We use a variety of AWS services, including Amazon Redshift, Amazon Simple Storage Service (Amazon S3), and Amazon QuickSight.
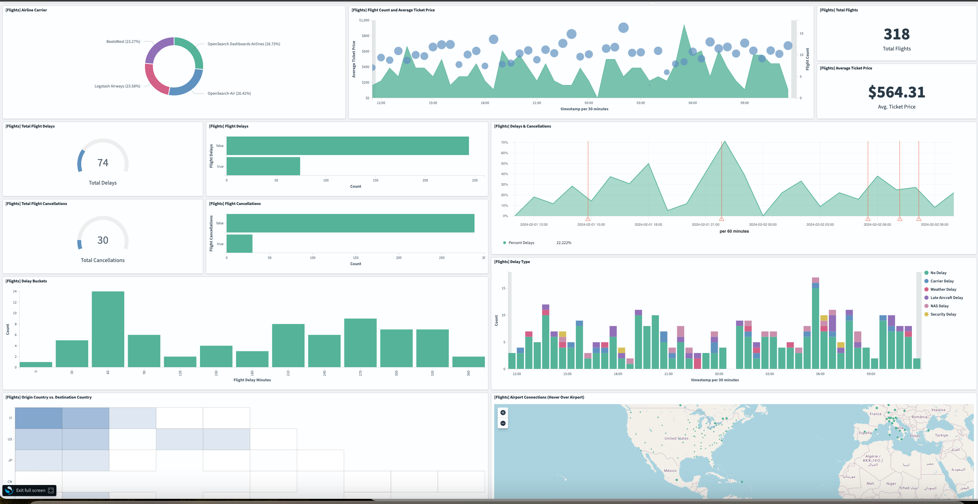
Building a scalable streaming data platform that enables real-time and batch analytics of electric vehicles on AWS
The automobile industry has undergone a remarkable transformation because of the increasing adoption of electric vehicles (EVs). EVs, known for their sustainability and eco-friendliness, are paving the way for a new era in transportation. As environmental concerns and the push for greener technologies have gained momentum, the adoption of EVs has surged, promising to reshape […]

Level up your React app with Amazon QuickSight: How to embed your dashboard for anonymous access
Using embedded analytics from Amazon QuickSight can simplify the process of equipping your application with functional visualizations without any complex development. There are multiple ways to embed QuickSight dashboards into application. In this post, we look at how it can be done using React and the Amazon QuickSight Embedding SDK. Dashboard consumers often don’t have […]

Chargeback Gurus empowers eCommerce merchants with advanced chargeback intelligence to recover millions using Amazon QuickSight
This is a guest post by Suresh Dakshina and Damodharan Sampathkumar from Chargeback Gurus. Chargeback Gurus, a global financial technology company helps businesses fight, prevent, and win chargebacks. To date, we have helped businesses worldwide recover over $2 billion in lost revenue. As trusted advisors to card networks and Fortune 500 companies, we are known […]

Diligent enhances customer governance with automated data-driven insights using Amazon QuickSight
This post is co-written with Vidya Kotamraju and Tallis Hobbs, from Diligent. Diligent is the global leader in modern governance, providing software as a service (SaaS) services across governance, risk, compliance, and audit, helping companies meet their environmental, social, and governance (ESG) commitments. Serving more than 1 million users from over 25,000 customers around the […]

Green Flag uses Amazon QuickSight to democratize data and enable self-serve insights to all employees
This is a guest post by Jeremy Bristow, Head of Product at Green Flag. In the US, there’s a saying: “Sooner or later, you’ll break down and call Triple A.” In the UK, that same saying might be “Sooner or later, you’ll break down and call Green Flag.” Green Flag has been assisting stranded motorists […]
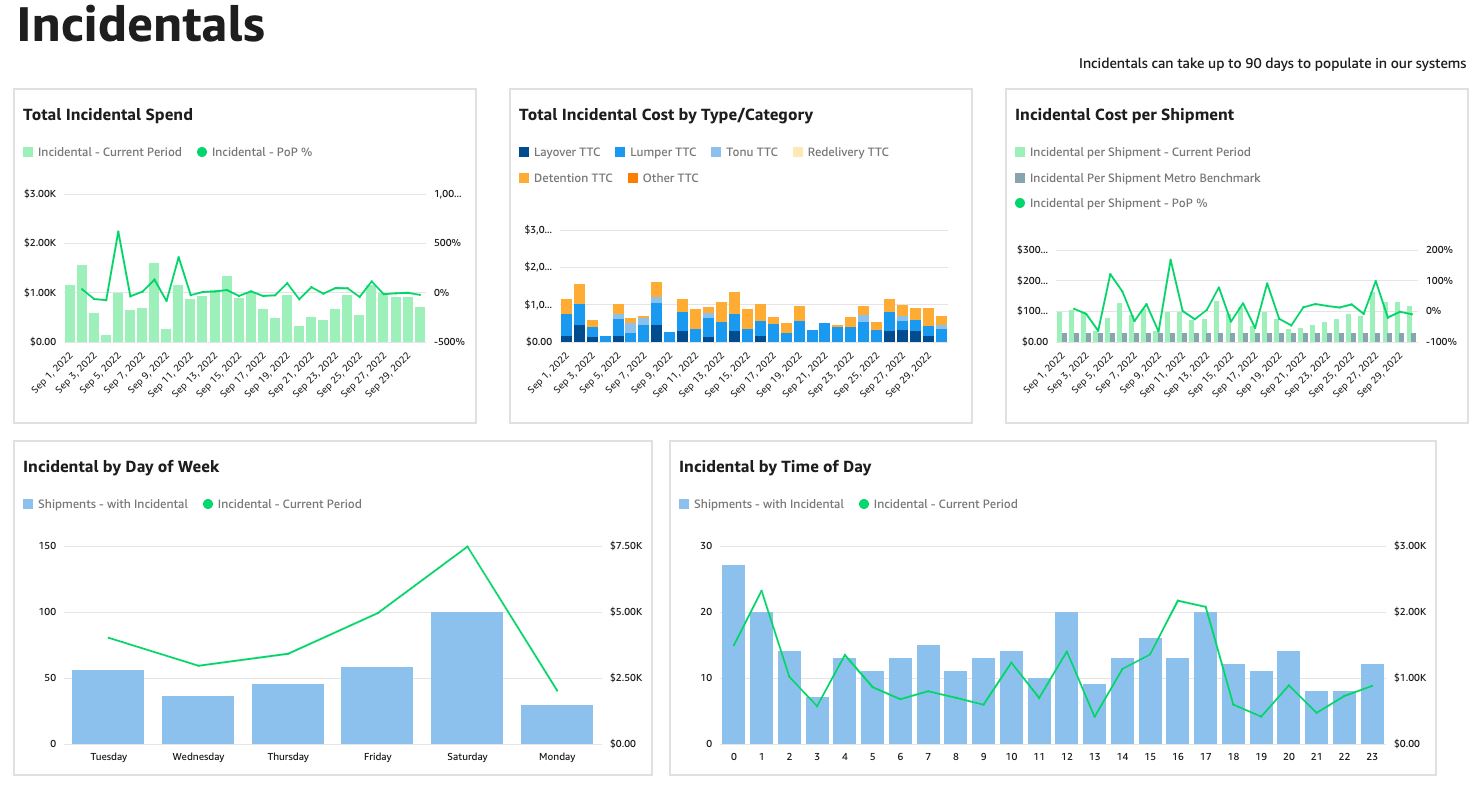
Convoy uses Amazon QuickSight to help shippers and carriers improve efficiency and save money with data-driven decisions
Convoy is the leading digital freight network in the United States. We move millions of truckloads around the country through our connected network of carriers, saving money for shippers, increasing earnings for drivers, and eliminating carbon waste for our planet. In 2015, Convoy started a movement toward efficient freight. We build technology to find smarter […]

Amazon Identity Services uses Amazon QuickSight to empower partners with self-serve data discovery
Amazon Identity Services is responsible for the way Amazon customers—buyers, sellers, developers—identify themselves on Amazon. Our team also manages customers’ core account information, such as names and delivery addresses. Our mission is to deliver the most intuitive, convenient, and secure authentication experience. We’re in charge of account security for Amazon, worldwide, on all device surfaces. […]

Clickedu uses Amazon QuickSight Embedded to empower school administrators with key educational institution health insights
This is a guest post by Ignasi Nogués and Georgina Valls from Clickedu. With more than 1.5 million unique users across 700 schools and core values that include connectivity, reliability, and innovation, Clickedu is the leading educational platform in Spain. Offering both a school administration system and a digital learning environment, Clickedu is one of […]

AWS Specialist Insights Team uses Amazon QuickSight to provide operational insights across the AWS Worldwide Specialist Organization
The AWS Worldwide Specialist Organization (WWSO) is a team of go-to-market experts that support strategic services, customer segments, and verticals at AWS. Working together, the Specialist Insights Team (SIT) and the Finance, Analytics, Science, and Technology team (FAST) support WWSO in acquiring, securing, and delivering information and business insights at scale by working with the […]