Amazon Web Services ブログ
Amazon SageMaker で主成分分析を実行する
主成分分析 (PCA) は、主に株式市場の予測から医用画像分類に至るまで数多くのアプリケーションの次元削減のために、データ科学者が使用する非常に一般的な手法です。PCA のその他の用途としては、ノイズ除去および特徴抽出があります。また、PCA は、探索的データ解析ツールとしても使用されます。
PCA をよりよく理解するために、トラックのプロパティで構成されるデータセットの例を考えてみましょう。これらのプロパティは、色、サイズ、コンパクトさ、座席数、ドア数、トランクのサイズなどによってそれぞれのトラックを記述します。測定されるこれらの特徴の多くは重複しているため、こうした重複を取り除き、より少ないプロパティでそれぞれのトラックを説明する必要があります。これが、まさに PCA が目指すものです。
このブログ記事では、カリフォルニア大学アーバイン校のアイリス (あやめ) 標準データセットで実行されている PCA を使用して、Jupyter ノートブックのコードの簡単な例で PCA の基本を紹介し、次に Amazon SageMaker 環境で動作する PCA を紹介します。Amazon SageMaker を使用するメリットのいくつかを指摘します。
PCA とは?
PCA は、できるだけ多くの情報を保持しながら、d 個の特徴を p << d 個の特徴に圧縮する技術です。PCA のための古典的なデモンストレーションは、画像で行われます。白黒画像は、各ピクセルのグレースケールを決定する整数の n X d の行列として表すことができます。PCA は、圧縮された画像が元の画像とほぼ同じに見えるように、nd 個ではなく、(n+d) p 個で保存できるマトリックスによる低ランクの表現を提供します。機械学習 (ML) の文脈では、PCA は次元削減技術ということになります。特徴の数が多い場合、ML アルゴリズムには過剰適合のリスクがあるか、トレーニングに時間がかかりすぎることになります。そのために、PCA は入力の次元を減らすことができます。PCA が次元を減らす方法は、相関関係に基づいています。2 つの特徴が相関していて、一方の値が与えられると、もう一方の値について知識を使って推測することができます。p をターゲットの次元とする PCA は、これらの線形関数が元の d 個の特徴を最も正確に予測するような p 個の特徴を見つけます。この種の情報を保持するという目的が、PCA の出力を下流の作業にとって有益なものにします。
シンプルな例での PCA のユースケース
次の Python コードは、前処理による特徴の抽出や次元の削減で、PCA がいかに強力であり、シンプルであるかを示しています。「アイリス (あやめ)」のデータセットは、データ科学者が PCA の内部作業を研究するために使用する標準データベースです。このデータセットは、UCI Machine Learning Repository (https://archive.ics.uci.edu/ml/datasets/Iris) で公開されており、3 つの異なる種に由来する 150 のアイリス (あやめ) の花の測定値を含んでいます。3 つの種は、1) アイリスセトサ、2) アイリスバージカラー、3) アイリスバージニカです。1) がく片の長さ、2) がく片の幅、3) 花びらの長さ、4) 花びらの幅、という 4 つの特徴は、センチメートル単位の次元です。このデータセットで、固有値分割と特異値分解 (SVD) という 2 つの一般的なアプローチを使用して PCA を作成する手順を説明します。どちらのアプローチを用いても結果は同じであることがわかります。SVD は、共分散行列を計算する必要なしで PC を非常に高速で得る方法なので、最も一般的なアプローチですただし、データの次元が本当に大きくなると、ランダム化 SVD などの高速技法が使用されます。
それでは、アイリスのデータセットをロードしましょう。
次のコードは、正規化された共分散行列を使用して固有値分解から固有ベクトルと固有値を取得する方法を示しています。固有ベクトルは、特性ベクトル、固有ベクトル、または潜在ベクトルとも呼ばれる、線型方程式系に関連するベクトルの特殊なセットです。
スカラー λ は、Ax = λx の自明解 x が存在するため、n × n 行列 A の固有値と呼ばれます。このような x は、固有値 λ に対応する固有ベクトルと呼ばれます。
主成分 (PC) の値 (V の転置、下の pca() 関数を参照) は、SVD 法を用いて代わりに計算されます。これの出力は、最初と中間のベクトルについて符号が逆になることを除いて、前の方法 (固有値分割) から得られる固有ベクトルまたは PC に一致します。これは大丈夫です。基底ベクトルの符号反転です。
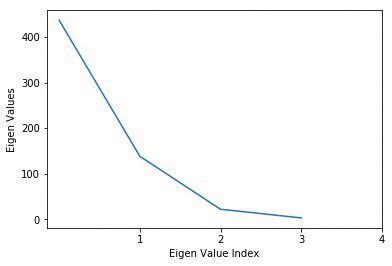
ここで、プロットされた取得済み PC を選択し、重要な値だけを考慮します。対応する固有ベクトルまたは PC は、より低い次元の部分空間に投影するためにだけ考慮します。プロットに基づいて、最初の 2 つの成分だけを選択します。
PC を取得するための主なステップは以下のとおりです。
- データをゼロ平均および単位分散形式に正規化します。
- 正規化したデータの共分散行列を取得します。
- 固有値分割アプローチを使用して結果の共分散行列を固有値分割するか、SVD を使用して直接 PC と固有値を取得することによって、固有値と固有ベクトル (PC) を取得します。
- PC をプロットすることで、重要な PC を把握します。
以下のコードは、これらの主なステップを経て、再サンプリングされた (eig_vecs_reshape) データで正規化された入力行列 X_std に対してドット積演算を実行することによって、投影データの 2 次元空間へのプロットの結果を示します。
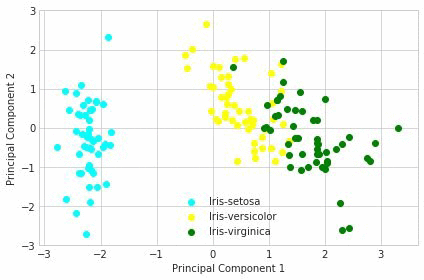
この散布図から、部分空間内のデータはクラスターの形であり、これらのクラスターを分離するために K 平均のような他の技術を使用してさらに処理できることが分かります。
Amazon SageMaker PCA のハイライト
私たちの実装ではシングルパスしか必要でないため、データセットとデータストリームの両方を処理できる必要があります。このアルゴリズムはミニバッチで動作し、それぞれのミニバッチにはマトリクスからの行が一定量含まれます。PCA モデルは、その行列の右上の特異ベクトルを含みます。 前のセクションで説明した Iris データセットでの PCA のネイティブな実装と比較すると、以下のセクションで論じる MNIST データセットでの PCA の実装は、特に大量のデータが含まれている場合には、ML 計算のためのはるかに合理化され最適化されたアプローチです。 ネイティブなアプローチでは、効率的な計算ができない形式でローカルメモリにデータを保存してから計算を実行します。これは、キャッシュに多くのゴミがたまり、パフォーマンスが頭打ちになります。 この問題は、大量のデータを Amazon S3 に保存することで軽減されます。 その後、データは、アルゴリズムの計算に適した形式 (RecordIO 形式) に変換されます。
アルゴリズム
Amazon SageMaker PCA は、基本アルゴリズムとランダム化アルゴリズムの 2 つのアルゴリズムをサポートしています。
基本アルゴリズム: 基本バージョンは、中程度の入力次元に合わせて調整されています。平均行と完全な dXd 共分散行列の両方を維持します。ここで、d は入力次元です。これは正確な解を提供しますが、d^2 メモリと、入力行当たり d^2 の更新時間を必要とします。
ランダム化アルゴリズ: 入力次元が大きい入力の場合、トップの特異ベクトルの近似値を計算する近似アルゴリズムを提供します。このバージョンでは、3つの重要なパラメータがあります。d は入力次元、k は必要な特異ベクトルの数、p は精度パラメータです。このアルゴリズムでは、O((k+p)d) のメモリと、入力行あたり O((k+p)d) の処理時間が必要です。p の値が大きければ、より正確な近似が得られますが、メモリと実行時間の点ではより多くのコストがかかります。この実装は、行列の列の投影を維持する点で、ランダム投影に基づいています。
主要なプロパティ
GPU サポート: どちらのアルゴリズムも (マルチ) GPU マシンでサポートされているため、実行時間が大幅に短縮されます。
シングルパス: 私たちの実装ではシングルパスしか必要でないため、モデルの増分更新が可能です。たとえば、毎日増加するデータセットがある場合、データセット全体を再トレーニングするのではなく、新しいデータサイズに比例した新しいデータを含むように PCA モデルを更新することができます。
シームレスな並列性: Amazon SageMaker PCA は、分散トレーニング用に最適化されており、複数のノードでトレーニングする場合には、ほぼリニアなスケーラビリティを得ることができます。
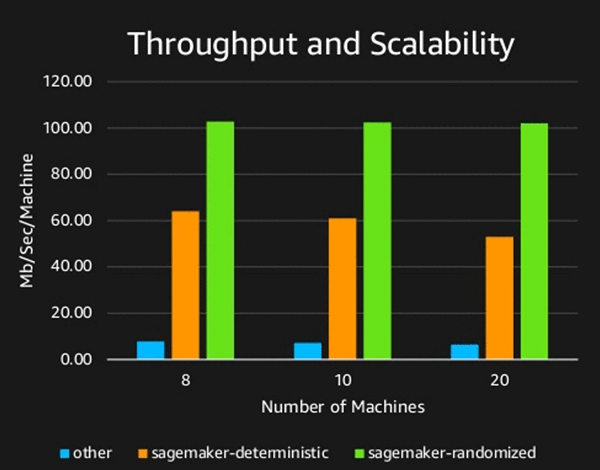
Amazon SageMaker PCA のスピードとスケーラビリティを実証するため、次のイメージを提示して、両方のバージョンと一般的な代替方法のスループットを測定します。表示されるスループットはマシン毎です。つまり、100 MB/秒/マシンが 10 台で 1 秒あたり 1GB のデータが処理されます。マシンを増やしても MB/秒/マシンが減少しないという事実から、効率的な並列処理であることが明らかです。GPU を使用する速度とメリットは、Amazon SageMaker バージョンと代替方法の間でのスループットの違いによって実証されます。さらに、優れたスループットを考慮すると、入力次元に対するランダム化バージョンの線形 (対平方) 依存性もここで確認することができます。
この実験は、上位 100 の主成分を抽出する目的で、5,000 次元のデータセットに対して実行されました。
入門ガイド/例
Amazon SageMaker PCA を使い始める最良の方法は、サンプルノートブック「Introduction to PCA with MNIST」をチェックすることです。このノートブックは、新しく作成された Amazon SageMaker ノートブックインスタンスの「Introduction to Amazon Algorithms」ディレクトリにあります。ノートブックインスタンスをまだ作成していない場合は、AWS アカウントにサインインして、 Amazon SageMaker コンソールに移動し、[Create notebook instance] リンクを選択します。
ここでノートブックインスタンスの名前を指定し、EC2 インスタンスタイプを選択し、IAM ロールを選びます。残りのフィールドはオプションであり、デフォルト値のままにすることができます。
ノートブックインスタンスを作成すると、「Notebook instances」ページの [Status] 列の下に緑色のマークが表示されます。
[Actions] 列の下で [Open] リンクを選択して、インスタンスでホストされている Jupyter ノートブックのリストを開きます。
[sample-notebooks] > [introduction_to_amazon_algorithms] ディレクトリへ移動し、pca_mnist ノートブックを開きます。
このノートブックでの私たちのタスクは、MNIST データセットにある手書き数字の固有ベクトルを計算することです。これを行うために、各行が画像を表している、50K × 728 の行列からなる MNIST データセットを取得します。「固有値」とも呼ばれる固有ベクトルは、728 次元のベクトルであり、すべての画像をそれらの線形結合として記述することができます。728 個ではなく 10 個の浮動小数点を使用して、各画像の近似表現を作成するために使用できる上位 10 個の固有ベクトルを取得します。
ノートブックを実行する前の重要な前提条件の 1 つは、トレーニングデータと出力モデルを保存する Amazon S3 バケットの名前を指定することです。 S3 バケットはノートブックインスタンスと同じリージョン内になければならないことに注意してください。トレーニングジョブはノートブックインスタンスと同じリージョンに制限されますが、推論に使用するエンドポイントはどのリージョンにでも設定できます。
データの取り込みおよび検査のステップでは、公開されている MNIST データセットを deeplearning.net からダウンロードします。 デモンストレーションの目的で、トレーニングセットの最初の入力を検査します。Python カーネルと共にホストされている Jupyter ノートブックを使って、希望する任意のタイプの検査を実行することができます。
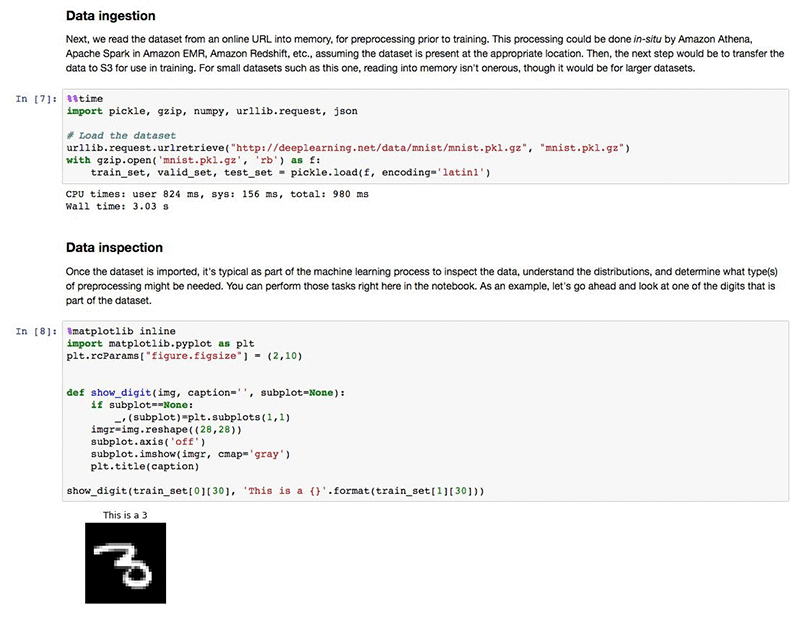
Amazon SageMaker PCA のアルゴリズムは、トレーニングのデータセットが protobuf recordIO 形式であることを期待しています。この形式は、大規模なデータセットと高速の読み込みのために最適化されています。Amazon SageMaker Python SDK を使用することで、numpy 配列を期待される形式に簡単に変換することができます。

データを転置したことに注意してください。n 行および d 列の入力行列に PCA モデルを適用すると、 結果の行列は n 行および k 列になります。ここで、k は選択した主成分の数です。これは、すべての行が、トップの主成分によってその表現に投影されるからです。行の投影ではなく主成分に関心があるので、行列の転置について作業します。基本的なチェックとして、次元が意味をなすことを確認します。私たちが関心があるのは、728 次元の画像に関連する上位 10 の主成分です。これは、728 行と 50,000 列の転置行列に PCA モデルを適用して、求められる列が 10 の主成分である、必要な 728 × 10 の行列を取得することを意味します。
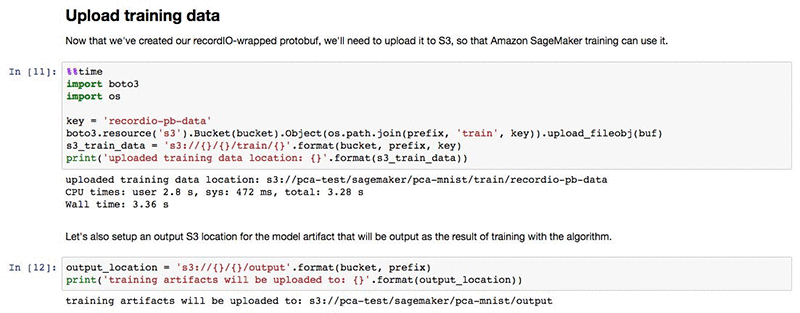
トレーニングジョブを始めるには、変換後のデータセットをノートブックの冒頭で指定した Amazon S3 バケットにアップロードする必要があります。
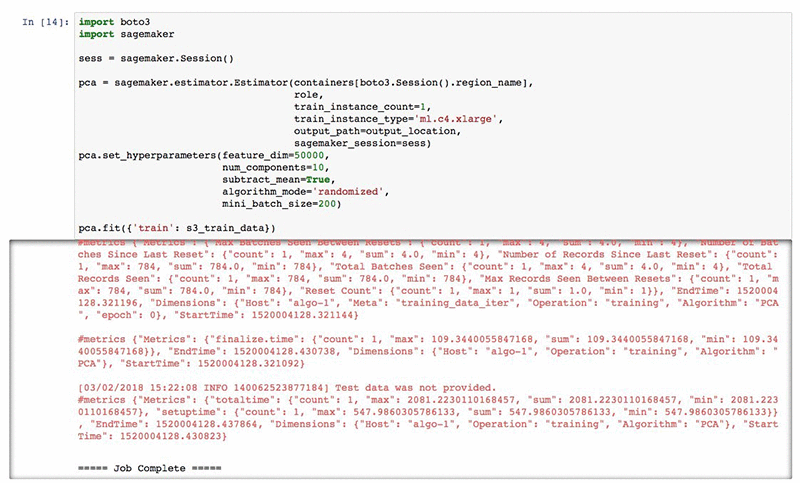
これで、トレーニングジョブを始める準備が整いました。PCA のアルゴリズムは、少数のハイパーパラメータを受け入れます。最も重要なハイパーパラメータは、トレーニングの最後までにモデルが持っていなければならない主成分の数を定義する num_components です。現在のデータセットでは、num_components を 10 に設定し、ランダム化されたアルゴリズムの変形を使用するように指定します。有効なハイパーパラメータの完全なリストについては、公式ドキュメントで確認してください。
それでは、トレーニングジョブを送信し、完了するのを待ちましょう。
セル出力の最後の行は、ジョブが正常に完了したことを示しています。つまり、私たちの新しい PCA モデルは、指定した Amazon S3 バケットに保存されます。ダウンロードしたい場合は、バケットへ移動し、[SageMaker] > [pca-mnist] > [output] > [pca-<execution_id>] > [output] と選択します。この場所にある model.tar.gz ファイルに、モデルが含まれています。モデルファイルの内容については、このウォークスルーの後の次のセクションで説明します。
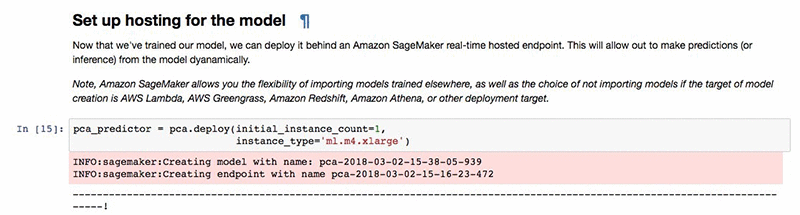
最後のステップとして、私たちの PCA モデルを使って、(転置された) トレーニングデータセットを「Eigen digits」という名前の固有ベクトルに投影しましょう。そのために、まずホスティングエンドポイントを作成する必要があります。
次に、エンドポイントを呼び出してモデルを適用します。
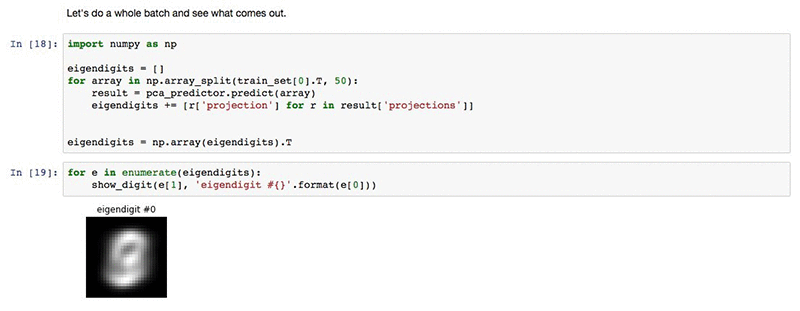
見える画像は、トップの固有ベクトルの表現です。一般的な固有ベクトルの場合と同様に非常に有益というわけではありませんが、他の固有ベクトルとともに、728 ではなく 10 の次元を持つデータセットの数字を表す役割を果たします。
注意: モデルを終了した後、エンドポイントを削除して、インスタンスが残っていることによる課金を避けることができます。S3 に保存されているモデルを使用して、いつでも別のホスティングエンドポイントを作成することができます。

モデル
PCA トレーニングジョブによって作成されるモデルはシンプルです。Amazon SageMaker エンドポイントでホストされるだけでなく、Apache MXNet にロードすることもできますし、必要であれば numpy 配列などの異なるデータ型に変換して、全く異なる環境で使用することもできます。
まず、ウォークスルーで作成されたモデルをダウンロードして抽出しましょう。 copy コマンドで S3 バケットとトレーニングジョブの名前を変更することを忘れないでください。どちらも、設定と一致している必要があります。

これで、抽出されたファイル「model_algo-1」を Apache MXNet にネイティブにロードできるようになりました。
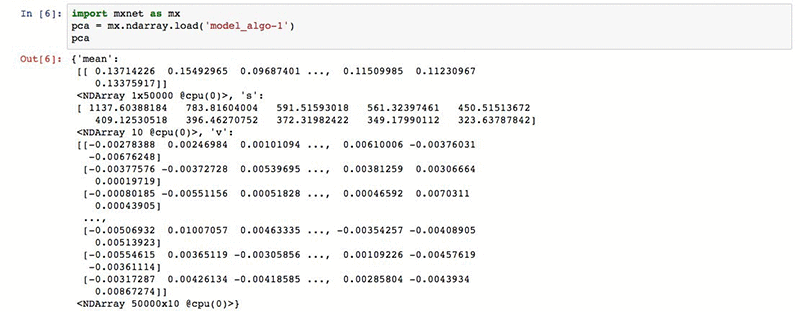
ロードされるデータ構造は、MXNet ndarrays の辞書です。この辞書には、3 つの配列が含まれています。
- 「mean」: データセットの平均の行。この値は、subtract_mean ハイパーパラメーターが true に設定されている場合にのみ表示され、モデルは PCA 投影を適用する前にデータが平均ゼロの行になるようにシフトします。
- 「v」: 各行が固有ベクトルである主成分。最も重要でないものから、最も重要なものへという順序になります。
- 「s」: 特異値。昇順に並べ替えられます。これらが、各固有ベクトルの重要性を決定します。
モデルのパラメーターを numpy 配列に変換するのは、MXNet ndarray で「asnumpy」メソッドを呼び出すのと同じくらい簡単です。

このスクリーンショットでは、ベクトルの特異値が表示され、それらのそれぞれが mnist データセット内の画像を表現する上での重要性が示されています。
まとめ
Amazon SageMaker PCA のアルゴリズムを提示し、それをトレーニングする手順をレビューしました。トレーニングのプロセスは、便利で高速であり、サンプル数と入力ディメンションの両方でスケーラブルであり、シームレスに並列化でき、異なるハードウェアタイプで動作させることができます。トレーニングのプロセスに加えて、トレーニングしたモデルを使用する 2 つの方法をレビューしました。最初の方法は、Amazon SageMaker エンドポイントを使用することです。この方法には、伸縮自在なスケーリングと使用の利便性というメリットがあります。もう 1 つの方法は、モデルをダウンロードし、MXNet または numpy Ndarray としてロードする方法であり、ローカルで実行できるというメリットがあります。
今回のブログ投稿者について
 Harsha Viswanath は Amazon AI のサイエンティストであり、深層学習および機械学習に関して顧客が抱えている最先端の問題を解決しています。この仕事の前は、Harsha は Amazon Go および Lab126 で働き、CV および ML の最先端の問題を解決していました。 Harsha は、この業界で 25 年以上働いており、フェイエットビルのアーカンソー大学で EE の博士号を取得しています。
Harsha Viswanath は Amazon AI のサイエンティストであり、深層学習および機械学習に関して顧客が抱えている最先端の問題を解決しています。この仕事の前は、Harsha は Amazon Go および Lab126 で働き、CV および ML の最先端の問題を解決していました。 Harsha は、この業界で 25 年以上働いており、フェイエットビルのアーカンソー大学で EE の博士号を取得しています。
 Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野としては、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野としては、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
 Can Balioglu は AWS AI アルゴリズムチームのソフトウェア開発エンジニアで、高性能コンピューターの活用を専門にしています。休みの時は、彼は自作の GPU クラスターで遊ぶのが大好きです。
Can Balioglu は AWS AI アルゴリズムチームのソフトウェア開発エンジニアで、高性能コンピューターの活用を専門にしています。休みの時は、彼は自作の GPU クラスターで遊ぶのが大好きです。